通过对比学习改进生成式文本摘要
当前在文本摘要领域,利用深度模型的监督学习方式表现的最好,这类方法基本都是将摘要抽取看做seq2seq自回归的生成任务,训练时基于极大似然估计,让模型预测的序列的概率最大近似标注的参考序列。
这类方法存在一个明显的问题就是:模型在预测时候上一个token并不都跟参考序列中的一样,这样造成模型训练与预测时输入不一致性问题,从而使得模型在预测时出现性能衰退的问题。这被称作exposure bias(曝光偏差)。
seq2seq自回归的生成任务使用teacher-forcing,训练时上一个token100%跟参考序列一样,预测时上一个token不一定跟参考序列一样,所以预测时可能会一步错步步皆错。
问题:teacher-forcing导致exposure bias(曝光偏差)
一个输入序列:
英国实施一周四天工作制。
给序列加上起止符号:
[START]英国实施一周四天工作制。[END]
训练过程如下:
NO. | 已经知道的x | 预测的y | teacher-forcing下已经知道的x | teacher-forcing下预测的y | teacher纠正 |
1 | [START] | ?? | [START] | ?? | 英国 |
2 | [START] ?? | xx | [START] 英国 | xx | 实施 |
3 | [START]?? xx | aa | [START] 英国 实施 | aa | 一周 |
... | ... | ... | ... | ... | .. |
在teacher-forcing下,如果一开始预测的"??"为"我",teacher会把"我"纠正为"英国",从而更快地学会生成正确的序列。
不使用teacher-forcing,如果一开始预测的"??"为"我",那么此后的预测是基于先前错误的x继续生成下一个词,从而使得预测的序列偏离正轨。
使用teacher-forcing,在训练的时候能获得较好的效果(因为训练数据有标准答案,可以在训练的过程中随时纠正答案),但是在测试的时候因为没有标准答案,可能生成的答案和训练时有很大的不同,导致模型脆弱。
一个常用的缓解方法是beam search:对词表中每一个单词的预测概率执行搜索,生成多个候选的输出序列。
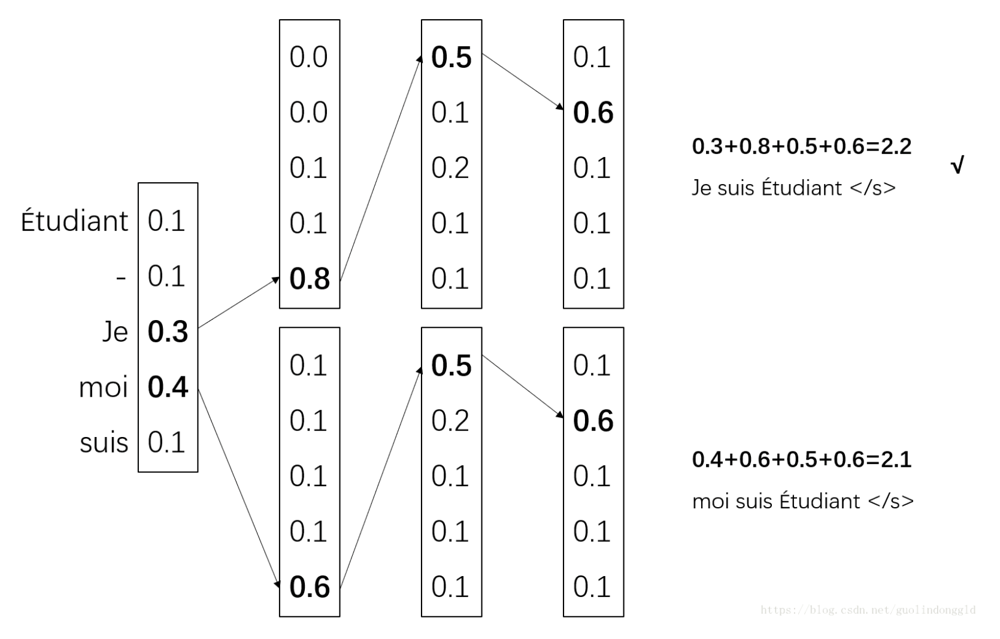
解决方法——对比学习
对比学习的一般思想是构造正样例(与原样例语义相似的样例)和负样例(与原样例语义不相似的样例),通过设计对比损失函数,缩小语义相似样例在表示空间中的距离,增大语义不相似的样例在表示空间中的距离,起到类似聚类的效果。

参考摘要称为“黄金摘要”。预测时由于没有teacher-forcinng,生成的摘要称为“白银摘要”(往往包含虚假事实,其表面形式可能与文本相似,但实际上与其原始含义相反 )。
预测时生成的摘要一定是“白银摘要”吗
作者通过最大似然估计(MLE)增加“黄金摘要”的可能性,同时通过对比学习在训练过程中降低”白银摘要”的可能性。在一定程度上,它有助于防止模型生成白银摘要。这种方法也可以被视为一种特殊的数据增强策略,它使模型能够从正样本(黄金摘要)和负样本(白银摘要)中学习。当推理时生成的银色摘要参与另一轮训练时,训练和推理之间的差异可以减少,从而可以减轻exposure bias。
1.1问题定义
在teacher forcing下,学习目标是在输入文本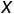 和黄金摘要中先前的Tokens
和黄金摘要中先前的Tokens 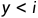 的条件下,最大化黄金摘要
的条件下,最大化黄金摘要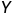 中每个Token
中每个Token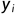 的可能性。损失函数定义为负对数似然 (NLL),如下所示:
的可能性。损失函数定义为负对数似然 (NLL),如下所示:
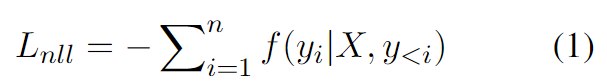
其中 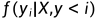 是黄金摘要的第
是黄金摘要的第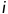 个Token的对数似然。
个Token的对数似然。
在推理时,模型必须使用生成的token  来预测token
来预测token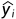 。通常,基于beam search 分数
。通常,基于beam search 分数 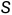 。beam search算法被用于在每个时间步长获取多个备选方案。然后,模型通过beam search一个token一个token地生成候选摘要,并选择beam search得分最高的一个作为输出摘要。具有与输入文本 相关联的m个Tokens的一个备选序列
。beam search算法被用于在每个时间步长获取多个备选方案。然后,模型通过beam search一个token一个token地生成候选摘要,并选择beam search得分最高的一个作为输出摘要。具有与输入文本 相关联的m个Tokens的一个备选序列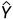 的beam search得分如下计算:
的beam search得分如下计算:

其中,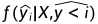 是生成序列的第i个Token的预测对数似然,表示早于Token的Token,
是生成序列的第i个Token的预测对数似然,表示早于Token的Token,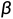 是与序列长度相关的附加指数惩罚。对于文本摘要任务, 小于1.0,以避免生成冗余信息。
是与序列长度相关的附加指数惩罚。对于文本摘要任务, 小于1.0,以避免生成冗余信息。
当通过NLL损失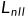 对数据集进行训练时,黄金摘要的分数S预计会上升,因此更有可能将黄金摘要作为候选摘要之一,从而选择黄金摘要作为生成的候选摘要中的最终输出。但是,也可能存在着更高的得分S然而质量却低的候选摘要。当它作为输出摘要时,被称为“白银摘要”。白银摘要的出现可归因于差异问题,因为 seq2seq 模型只能在训练时观测黄金摘要,而模型需要在推理时评估大量看不见的替代方案。
对数据集进行训练时,黄金摘要的分数S预计会上升,因此更有可能将黄金摘要作为候选摘要之一,从而选择黄金摘要作为生成的候选摘要中的最终输出。但是,也可能存在着更高的得分S然而质量却低的候选摘要。当它作为输出摘要时,被称为“白银摘要”。白银摘要的出现可归因于差异问题,因为 seq2seq 模型只能在训练时观测黄金摘要,而模型需要在推理时评估大量看不见的替代方案。
1.2对比学习
为了缓解上述问题,我们建议在训练期间通过对比学习降低白银摘要的分数。
具体来说,对seq2seq模型进行了优化,以确保“pos分数”高于“neg分数”。对于相同的文本X,pos分数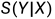 通过公式(2)计算黄金摘要,而neg分数
通过公式(2)计算黄金摘要,而neg分数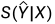 的计算方式相同,但使用白银摘要。margin ranking loss损失被定义为增加pos分数,同时降低neg分数,如下所示:
的计算方式相同,但使用白银摘要。margin ranking loss损失被定义为增加pos分数,同时降低neg分数,如下所示:
其中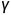 是margin value。
是margin value。
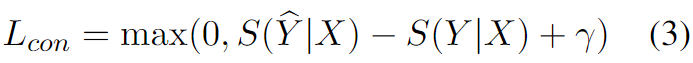
训练时,大于
的值时产生损失。为了减少损失,最小化
,训练使得
-
的值变小,
变小,
变大。
注意,如果pos分数高于超过边缘值的neg分数,则无法优化模型,因为当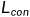 值为零时,梯度也为零。为了最有效地利用训练数据并防止模型欠拟合,我们还将NLL损失包含在整体损失函数中,即:
值为零时,梯度也为零。为了最有效地利用训练数据并防止模型欠拟合,我们还将NLL损失包含在整体损失函数中,即:
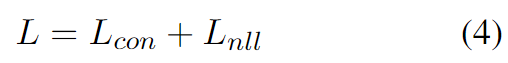
1.3模型训练
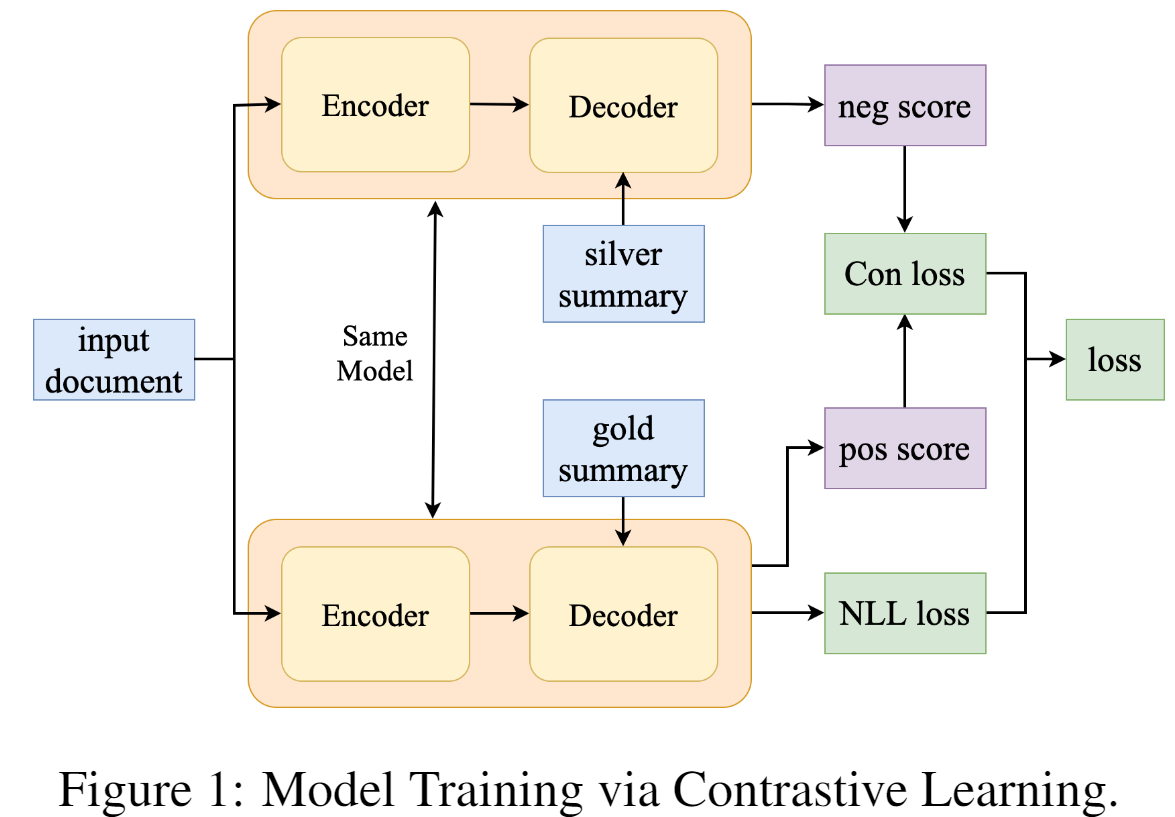
2.SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization(2021ACL会议)

teacher-forcing的方式生成的序列,从概率上说是最高的,但是并不一定是最好的。
因为生成的序列是基于token级别的概率上的预测,然而摘要的好坏的评价指标(通常是ROUGE分数)是比较输出的摘要和参考摘要的整体相似度。这就存在着 目标函数与评价指标不一致的问题。
在文中,作者提出使用一种两阶段的抽象摘要模型:Seq2Seq模型首先通过MLE loss被训练,生成候选摘要,然后用一个参数化的评估模型通过对比学习训练,把生成的候选摘要进行排序。通过监督学习来训练这两个模型,在不同阶段分别优化生成模型和评估模型。
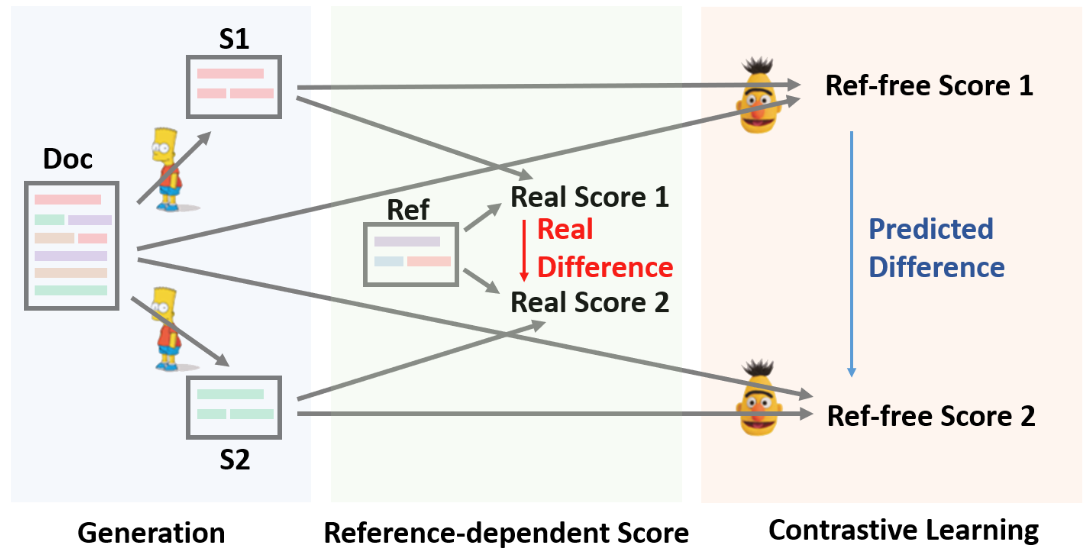

Doc, S, Ref分别表示文档,生成的摘要,参考摘要。第一阶段,Seq2Seq(BART)生成候选摘要。第二阶段,打分模型(RoBERTa)基于源文档预测候选摘要的表现。打分模型通过对比学习训练,训练样本由Seq2Seq模型提供。
2.1阶段一:候选摘要生成
生成模型g是seq2seq模型,基于源文档D,生成多个候选摘要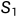 ,...,
,...,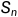 ,抽样策略可以使用beam search。n是被采样的候选摘要的数量。
,抽样策略可以使用beam search。n是被采样的候选摘要的数量。
2.2阶段二:无参考评估
对于源文档D来说,越好的候选摘要 应该得到越高的分数。作者定义了一个评价函数h,旨在根据源文档D和候选摘要的相似度,对候选摘要打分
应该得到越高的分数。作者定义了一个评价函数h,旨在根据源文档D和候选摘要的相似度,对候选摘要打分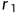 ,...,
,...,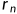 ,
,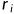 =
=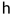 (
(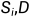 )。最终输出的摘要S是最高分数的候选摘要。
)。最终输出的摘要S是最高分数的候选摘要。
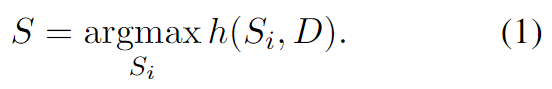
在这里,实例化h为预训练模型Roberta。它分别给候选摘要和源文档D编码,编码器的第一个Token的余弦相似度作为相似度分数。
2.3对比学习
对打分模型h引入一个ranking loss。候选摘要之间进行对比训练,候选摘要和参考摘要进行对比训练。
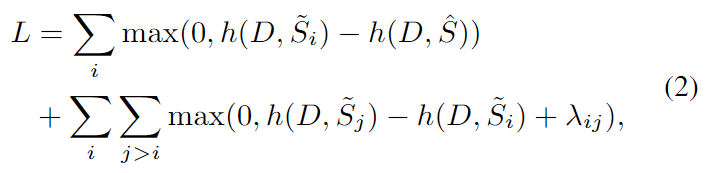
 基于分数
基于分数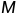 (
(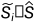 )按降序排列。在这里,
)按降序排列。在这里,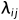 =(
=(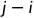 )*
)*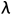 ,是超参数,M可以是任何自动评估指标或者是人为判断,在本文中是ROUGE。
,是超参数,M可以是任何自动评估指标或者是人为判断,在本文中是ROUGE。
前一个部分当候选摘要的评分高于真实参考摘要时会产生损失值,在第二个部分当较差的候选摘要的评分高于较好的候选摘要时会产生损失。
3.Bringing Order to Abstractive Summarization(2022ACL会议)

通过MLE方式训练,使得模型生成参考摘要的概率变高。但这样训练,非参考摘要之间的好坏没有能力辨别。
而且在预测阶段,模型生成的摘要不一定是参考摘要,通过beam search生成多个候选摘要时,模型没有能力区分这些候选摘要的好坏(通过生成的概率来区分候选摘要的好坏是没有信服力的)。
所以论文提出增加一个评分模型来评估生成的候选摘要的质量,从而解决训练时的目标函数和评价指标(ROUGE)不一致的问题。
模型
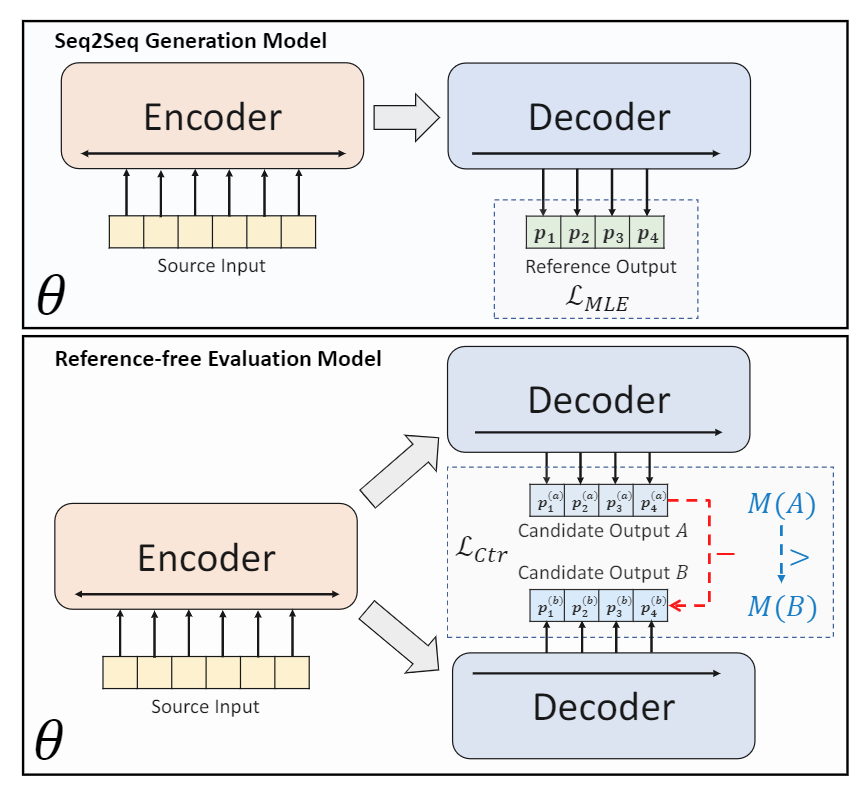
给定一篇文档D,训练一个模型g,使得生成一个合适的摘要序列S。 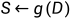
摘要生成模型g应该具备给更好的候选摘要序列分配更高的概率。为了实现这个想法,我们需要训练一个模型使得g生成的摘要的概率的大小和评价指标M(ROUGE分数)一致,通过对生成的候选摘要按评价指标排序,引入对比损失, 将排序后的候选摘要形成对比样本,对模型进行优化。
模型分为两个部分,即Seq2Seq生成模型(Seq2Seq Generation Model)以及无参考评分模型(Reference-fredd Evaluation Model),前者通过自回归的方式和Diverse Beam Search生成候选摘要,后者针对生成的候选摘要进行评分。生成模型和评分模型的结构是一致的,采用的是相同的预训练语言模型BART或PEGASUS,但生成模型的训练是使用的是标准的MLE损失,而评分模型的训练主要使用的是对比损失(contrastive loss),对比损失的计算基于生成模型生成的多个候选摘要。
损失函数
生成模型的训练使用的是MLE损失针对预训练模型进行微调,该过程并没有什么特殊之处。而评分模型的训练是基于一个多任务学习框架,对应的模型称为BRIO-Mul,该框架采用的是一个一个多任务损失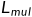 ,分别由对比损失和普通的交叉熵损失和构成,由于对比损失是定义在序列级别的,所以这里token级别的交叉熵损失可以起到标准化的辅助作用,以确保评分模型可以在整个序列上分配相对平衡的概率。实际上,直接去除这里的交叉熵损失也不会产生太大的影响,评分模型的关键只在于这个对比损失。
,分别由对比损失和普通的交叉熵损失和构成,由于对比损失是定义在序列级别的,所以这里token级别的交叉熵损失可以起到标准化的辅助作用,以确保评分模型可以在整个序列上分配相对平衡的概率。实际上,直接去除这里的交叉熵损失也不会产生太大的影响,评分模型的关键只在于这个对比损失。
=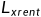 +
+ ,表示普通的交叉熵损失,
,表示普通的交叉熵损失,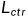 表示对比损失,表示对比损失的权重,通常设置较大的值效果才比较好(比如100)。
表示对比损失,表示对比损失的权重,通常设置较大的值效果才比较好(比如100)。
对比损失被用来训练模型作为无参考评分模型的能力。典型的对比学习中的对比损失需要显式的构造正样本和样本,但这里没有采用这种方式,而是采用排序损失(ranking loss)来实现对比损失,标题中的Bring Order正源于此。也就是说,论文通过引入排序损失这种对比学习方式,来把评价指标M(通常为Rouge)引入到了评分函数,从而让整体模型在训练过程中不再仅仅依赖于token级别的损失,而能够直接拥有感知序列级别的差异的能力。
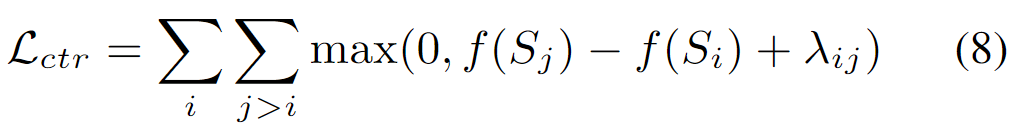
=()*,和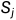 是两个不同的候选摘要,ROUGE(
是两个不同的候选摘要,ROUGE(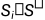 )>ROUGE(
)>ROUGE(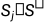 ),对于任意的i,j,i<j。
),对于任意的i,j,i<j。
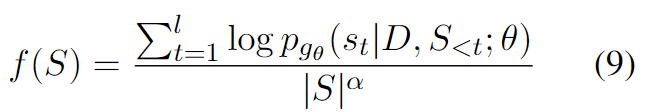
 为候选摘要的长度归一化估计对数概率(实际就是候选摘要的评分)。
为候选摘要的长度归一化估计对数概率(实际就是候选摘要的评分)。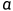 是长度惩罚超参数。
是长度惩罚超参数。
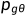 (
(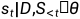 )表示给定先前已经预测出来的序列
)表示给定先前已经预测出来的序列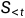 ,预测下一个单词
,预测下一个单词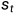 的概率。
的概率。
比较SimCLS和BRIO,它们都是生成多个候选摘要,然后通过对比学习的方式对摘要进行打分,使得模型具有辨别摘要好坏的能力,迫使模型生成高质量的摘要。不同的是,前者的生成候选摘要(BART)和评分模型(Roberta)采用了两个独立的模型,后者使用的是单一模型(BART)进行候选摘要生成和评分。使用单一模型的好处是评分模型和生成模型的参数可以共享,使得训练更加充分?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号