LLM
ChatGLM-6B
https://github.com/THUDM/ChatGLM-6B
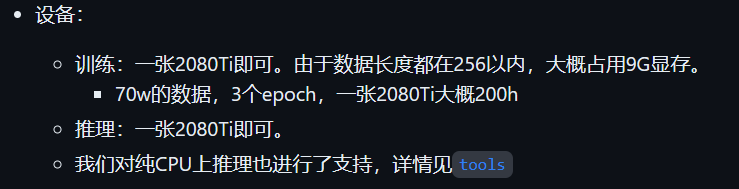
- 支持在单张 2080Ti 上进行推理使用。
- 在 1:1 比例的中英语料上训练了 1T 的 token 量
- ChatGLM-6B 序列长度达 2048
fine-tune
需要Deepspeed
训练需要显存问题https://github.com/THUDM/ChatGLM-6B/issues/556
P-tuning v2(单卡可训练)
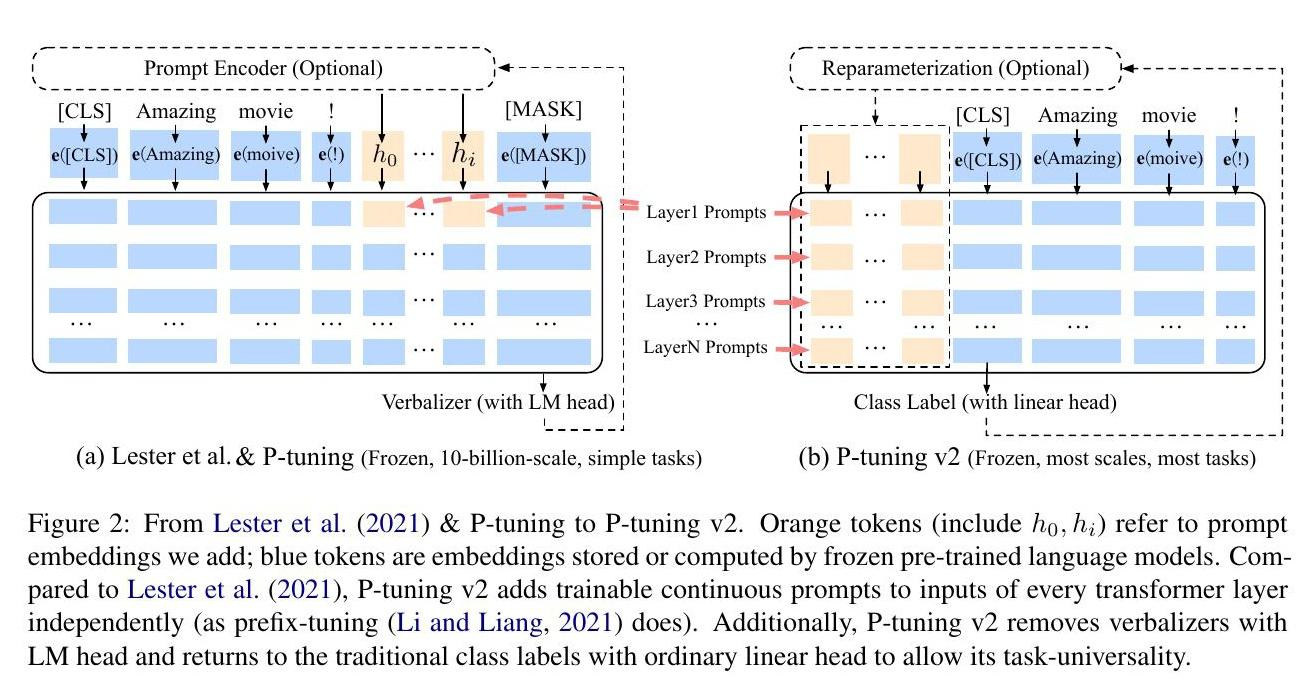
在(Lester等人,2021)和P-tuning中,连续提示只被插入transformer第一层的输入嵌入序列中(参照图2(a))。在接下来的transformer层中,插入连续提示的位置的嵌入是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
-
可调控的参数量有限。大多数语言模型目前只能支持512的最大序列长度(由于注意力的二次计算复杂性的成本)。如果我们另外扣除我们的上下文的长度(例如,要分类的句子),那么我们用连续的提示语来填充的长度是有限的。
-
用很深的transformer进行微调时,稳定性有限。随着transformer的不断深入,由于许多中间层的计算(具有非线性激活函数),来自第一个transformer层的提示的影响可能是意想不到的,这使得我们的优化不是一个非常平稳的。
鉴于这些挑战,P-tuning v2利用多层提示(即深度提示优化),如同前缀优化(Li and Liang, 2021)(参考图2(b)),作为对P-tuning和Lester等人(2021)的重大改进。不同层中的提示作为前缀token加入到输入序列中,并独立于其他层间(而不是由之前的transformer层计算)。一方面,通过这种方式,P-tuning v2有更多的可优化的特定任务参数(从0.01%到0.1%-3%),以允许更多的每个任务容量,而它仍然比完整的预训练语言模型小得多;另一方面,添加到更深层的提示(例如图2中的LayerN Prompts)可以对输出预测产生更直接和重大的影响,而中间的transformer层则更少(参见第4.4节)

MOSS
https://github.com/OpenLMLab/MOSS
- 支持中英双语
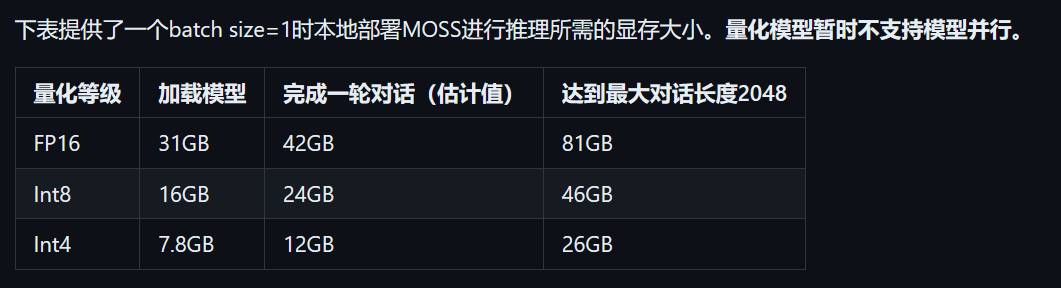
- 在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。
BELLE
https://github.com/LianjiaTech/BELLE
基于 Stanford Alpaca ,实现基于Bloom、LLama的监督微调。Stanford Alpaca 的种子任务都是英语,收集的数据也都是英文,该开源项目是促进中文对话大模型开源社区的发展,针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
Chinese-Vicuna
A Chinese Instruction-following LLaMA-based Model —— 一个中文低资源的llama+lora方案
https://github.com/Facico/Chinese-Vicuna
LMFlow
https://github.com/OptimalScale/LMFlow
该项目由香港科技大学统计和机器学习实验室团队发起,致力于建立一个全开放的大模型研究平台,支持有限机器资源下的各类实验,并且在平台上提升现有的数据利用方式和优化算法效率,让平台发展成一个比之前方法更高效的大模型训练系统。
利用该项目,即便是有限的计算资源,也能让使用者针对专有领域支持个性化训练。例如LLaMA-7B,一张3090耗时 5 个小时即可完成训练,成本大幅降低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号