BART的使用
使用模型
复旦nlp——fnlp_bart_large_Chinese
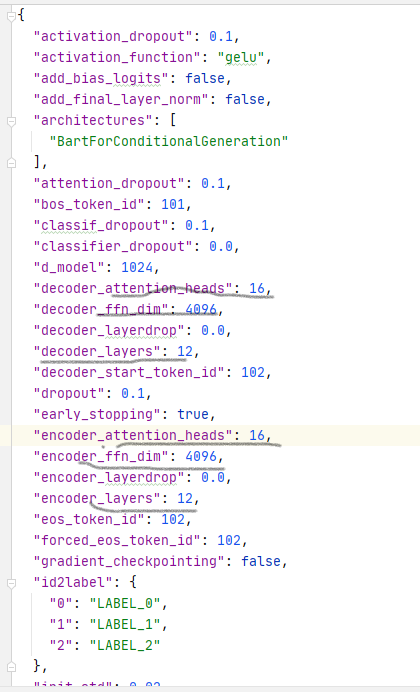
| 注意力头 | encoder/decoder层数 | 词嵌入表示 |
|---|---|---|
| 16 | 12 | 1024 |
词典使用BertTokenizer, vocab_size: 51271
在nlpcc数据集上微调模型
原fnlp_bart_large_Chinese是一个通用的文本生成任务的模型,在nlpcc数据集上微调,使之适用于摘要任务。
nlpcc数据集:

使用在nlpcc数据集上训练好的模型,评估模型性能
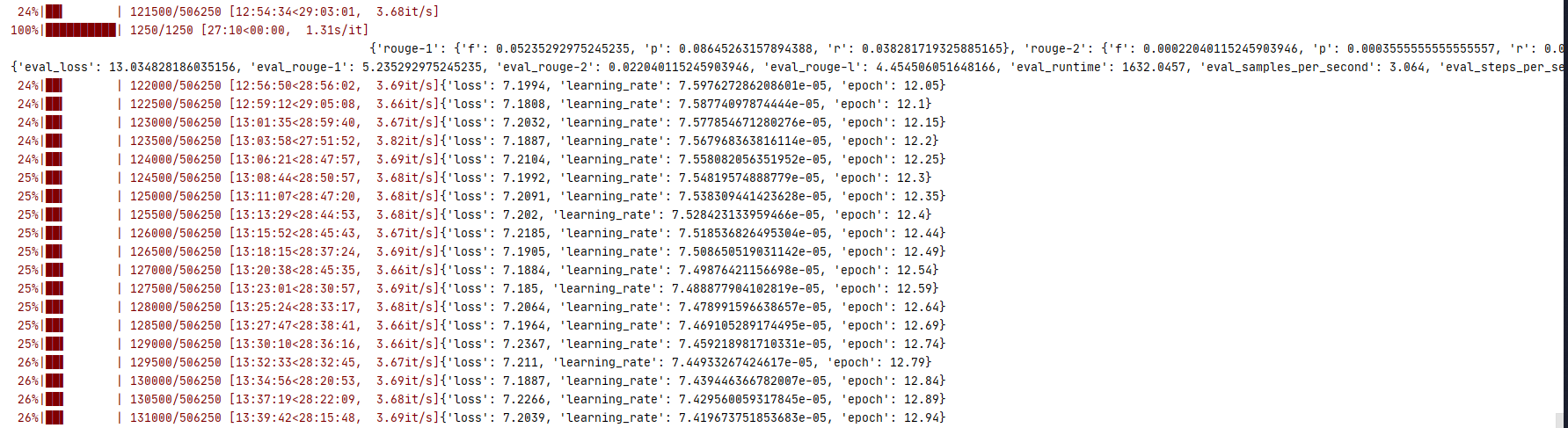
{
'rouge-1': {'f': 0.05235292975245235, 'p': 0.08645263157894388, 'r': 0.038281719325885165},
'rouge-2': {'f': 0.00022040115245903946, 'p': 0.0003555555555555557, 'r': 0.00016269035604260447},
'rouge-l': {'f': 0.04454506051648166, 'p': 0.07328421052631329, 'r': 0.032644400904541925}}
{'eval_loss': 13.034828186035156, 'eval_rouge-1': 5.235292975245235, 'eval_rouge-2': 0.022040115245903946, 'eval_rouge-l': 4.454506051648166, 'eval_runtime': 1632.0457, 'eval_samples_per_second': 3.064, 'eval_steps_per_second': 0.766, 'epoch': 12.0}
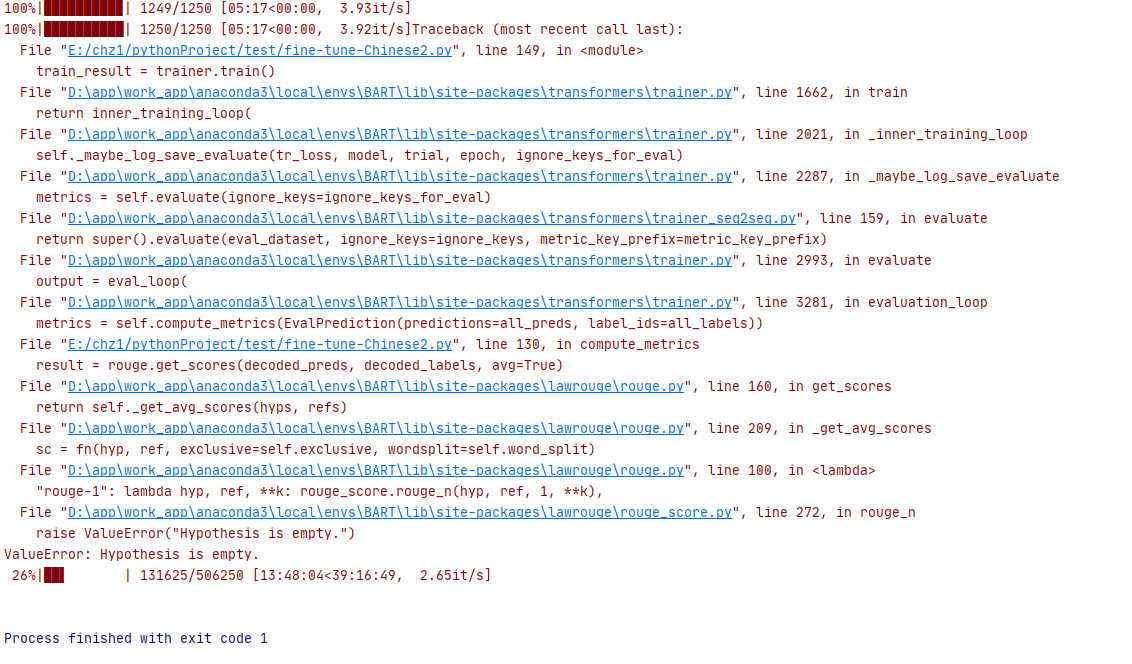
训练12个小时后,出错退出。原因:训练某个句子时输出摘要为空
接着13轮checkpoint继续训练,两小时后中断报错
接着两小时后的checkpoint继续训练
rouge分数太低
100%|██████████| 1249/1249 [05:29<00:00, 3.94it/s]
{'rouge-1': {'f': 0.02423567171951327, 'p': 0.14174174174174173, 'r': 0.013327544017225463}, 'rouge-2': {'f': 1.540001496466882e-05, 'p': 0.0001334668001334668, 'r': 8.171436742865314e-06}, 'rouge-l': {'f': 0.022295796621793585, 'p': 0.13013013013013014, 'r': 0.012263030905985522}}
{'eval_loss': 9.410301208496094, 'eval_rouge-1': 2.4235671719513268, 'eval_rouge-2': 0.0015400014964668818, 'eval_rouge-l': 2.2295796621793587, 'eval_runtime': 329.7013, 'eval_samples_per_second': 15.15, 'eval_steps_per_second': 3.788, 'epoch': 35.0}
70%|███████ | 354000/505700 [33:57:46<178:37:44, 4.24s/it]{'loss': 7.1713, 'learning_rate': 3.0027711797308e-05, 'epoch': 35.0}
100%|██████████| 505700/505700 [48:00:27<00:00, 4.45it/s]
100%|██████████| 1249/1249 [12:21<00:00, 1.71it/s]
100%|██████████| 505700/505700 [48:00:27<00:00, 2.93it/s]
{'rouge-1': {'f': 0.037102342546312554, 'p': 0.05711425711425618, 'r': 0.028008389214295278}, 'rouge-2': {'f': 0.0002714673266212396, 'p': 0.0004304304304304305, 'r': 0.00020164252957521005}, 'rouge-l': {'f': 0.030826718698070632, 'p': 0.04722818056151336, 'r': 0.02334709127146834}}
{'eval_loss': 10.560613632202148, 'eval_rouge-1': 3.7102342546312554, 'eval_rouge-2': 0.02714673266212396, 'eval_rouge-l': 3.082671869807063, 'eval_runtime': 741.8018, 'eval_samples_per_second': 6.734, 'eval_steps_per_second': 1.684, 'epoch': 50.0}
{'train_runtime': 172827.6268, 'train_samples_per_second': 11.704, 'train_steps_per_second': 2.926, 'train_loss': 7.197417623660582, 'epoch': 50.0}
TrainOutput(global_step=505700, training_loss=7.197417623660582, metrics={'train_runtime': 172827.6268, 'train_samples_per_second': 11.704, 'train_steps_per_second': 2.926, 'train_loss': 7.197417623660582, 'epoch': 50.0})
***** train metrics *****
epoch = 50.0
train_loss = 7.1974
train_runtime = 2 days, 0:00:27.62
train_samples_per_second = 11.704
train_steps_per_second = 2.926
tensor([[ 102, 101, 101, 2571, 101, 101, 101, 704, 101, 101,
4912, 101, 101, 6421, 101, 101, 791, 101, 101, 8409,
101, 101, 4390, 101, 101, 4636, 101, 101, 1055, 101,
101, 3189, 101, 101, 678, 101, 101, 2836, 101, 101,
7390, 101, 101, 677, 101, 101, 2824, 101, 101, 116,
101, 101, 1744, 101, 101, 7946, 101, 101, 2454, 101,
101, 2945, 101, 101, 6574, 101, 101, 1488, 101, 101,
2875, 101, 101, 3187, 101, 101, 2476, 101, 101, 2054,
101, 101, 13174, 101, 101, 1912, 101, 101, 6821, 101,
101, 1724, 101, 101, 1152, 101, 101, 7931, 101, 101,
5858, 101, 101, 5018, 101, 101, 6395, 101, 101, 129,
101, 101, 3193, 101, 101, 2139, 101, 101, 100, 101,
101, 3845, 101, 101, 8443, 101, 101, 102]],
device='cuda:0')
['快 中 秦 该 今 78 玻 百 兜 日 下 抚 随 上 承 + 国 黑 延 据 质 咪 招 无 张 媒 438 外 这 四 刑 麦 萱 第 证 8 早 宜 济 1500']
85
100%|██████████| 1249/1249 [12:24<00:00, 1.68it/s]
{'rouge-1': {'f': 0.037102342546312554, 'p': 0.05711425711425618, 'r': 0.028008389214295278}, 'rouge-2': {'f': 0.0002714673266212396, 'p': 0.0004304304304304305, 'r': 0.00020164252957521005}, 'rouge-l': {'f': 0.030826718698070632, 'p': 0.04722818056151336, 'r': 0.02334709127146834}}
{'eval_loss': 10.560613632202148, 'eval_rouge-1': 3.7102342546312554, 'eval_rouge-2': 0.02714673266212396, 'eval_rouge-l': 3.082671869807063, 'eval_runtime': 745.2962, 'eval_samples_per_second': 6.702, 'eval_steps_per_second': 1.676, 'epoch': 50.0}
Process finished with exit code 0

使用现有关于中文摘要的BART
IDEA-CCNL/Randeng-BART-139M-SUMMARY模型
基于Randeng-BART-139M,在收集的1个中文领域的文本摘要数据集(LCSTS)上微调了它,得到了summary版本。
测试数据:nlpcc数据集
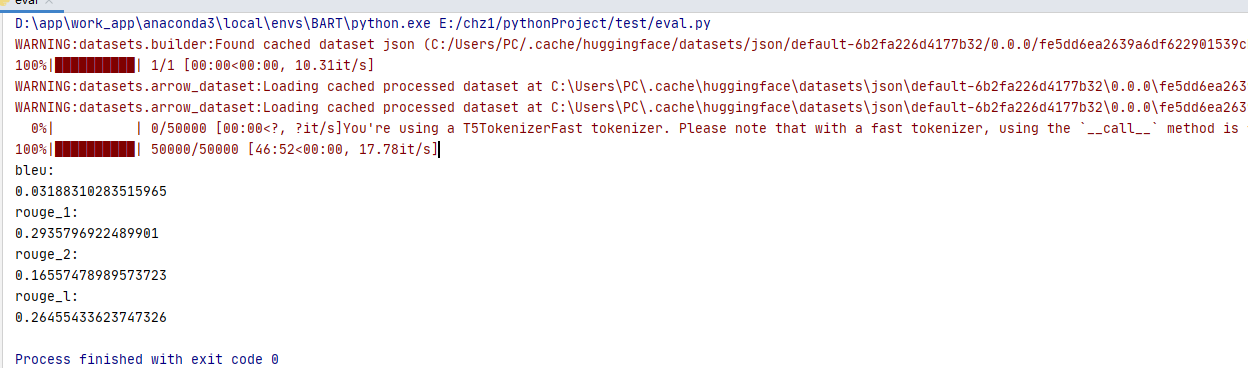

IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
基于Randeng-Pegasus-238M-Chinese,我们在收集的7个中文领域的文本摘要数据集(约4M个样本)上微调了它,得到了summary版本。这7个数据集为:education, new2016zh, nlpcc, shence, sohu, thucnews和weibo。
测试数据:nlpcc数据集


fnlp/bart-large-chinese
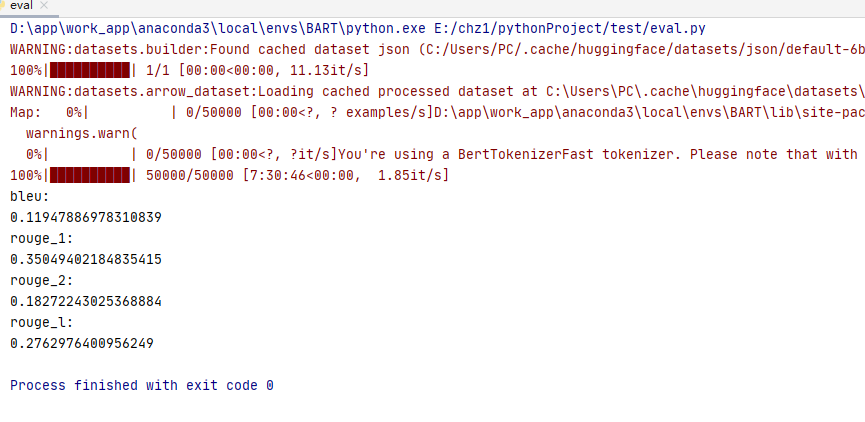

在nlpcc_cleaned微调:

在fnlp/BART-Chinese-large训练nlpcc数据集,50epoch
{'rouge-1': {'f': 0.02385148984622614, 'p': 0.029509509509508675, 'r': 0.020603066810449957}, 'rouge-2': {'f': 0.000177169615237493, 'p': 0.00022091056573815185, 'r': 0.0001519806049402622}, 'rouge-l': {'f': 0.020880164317725436, 'p': 0.02577243910577168, 'r': 0.01807193339007763}}
{'eval_loss': 7.140810966491699, 'eval_rouge-1': 2.385148984622614, 'eval_rouge-2': 0.0177169615237493, 'eval_rouge-l': 2.0880164317725436, 'eval_runtime': 470.3561, 'eval_samples_per_second': 10.62, 'eval_steps_per_second': 2.655, 'epoch': 35.0}
70%|███████ | 354000/505700 [36:48:50<250:34:37, 5.95s/it]{'loss': 1.838, 'learning_rate': 3.0027711797308e-05, 'epoch': 35.0}
{'rouge-1': {'f': 0.08561078406912385, 'p': 0.07919617730938643, 'r': 0.0957755845160025}, 'rouge-2': {'f': 0.0026396491707611136, 'p': 0.0024370524370524583, 'r': 0.002984247584272382}, 'rouge-l': {'f': 0.06062043620718075, 'p': 0.05592007101441241, 'r': 0.06809730821738538}}
{'eval_loss': 6.02243709564209, 'eval_rouge-1': 8.561078406912385, 'eval_rouge-2': 0.26396491707611136, 'eval_rouge-l': 6.062043620718075, 'eval_runtime': 676.5253, 'eval_samples_per_second': 7.383, 'eval_steps_per_second': 1.846, 'epoch': 36.0}
72%|███████▏ | 364500/505700 [37:45:48<9:51:22, 3.98it/s]{'loss': 1.7989, 'learning_rate': 2.7949326999208235e-05, 'epoch': 36.04}
{'rouge-1': {'f': 0.015079213137145636, 'p': 0.031831831831831824, 'r': 0.010087489636655993}, 'rouge-2': {'f': 0.0002209801050622089, 'p': 0.00045045045045045035, 'r': 0.00014948422315676742}, 'rouge-l': {'f': 0.01499220478128153, 'p': 0.03164703164703167, 'r': 0.010029635559137063}}
{'eval_loss': 5.223594665527344, 'eval_rouge-1': 1.5079213137145637, 'eval_rouge-2': 0.02209801050622089, 'eval_rouge-l': 1.4992204781281528, 'eval_runtime': 299.8166, 'eval_samples_per_second': 16.66, 'eval_steps_per_second': 4.166, 'epoch': 37.0}
74%|███████▍ | 374500/505700 [38:34:21<9:09:52, 3.98it/s]{'loss': 1.795, 'learning_rate': 2.5969912905779893e-05, 'epoch': 37.03}
{'rouge-1': {'f': 0.04768464358570707, 'p': 0.053036369703033166, 'r': 0.04438755496796147}, 'rouge-2': {'f': 0.0014606636699821861, 'p': 0.0015215215215215179, 'r': 0.0014558352988711654}, 'rouge-l': {'f': 0.041652264960747386, 'p': 0.046307418529637205, 'r': 0.038794520939990404}}
{'eval_loss': 5.6932878494262695, 'eval_rouge-1': 4.768464358570707, 'eval_rouge-2': 0.14606636699821862, 'eval_rouge-l': 4.165226496074738, 'eval_runtime': 500.1912, 'eval_samples_per_second': 9.986, 'eval_steps_per_second': 2.497, 'epoch': 38.0}
76%|███████▌ | 384500/505700 [39:26:16<8:29:32, 3.96it/s]{'loss': 1.7872, 'learning_rate': 2.3990498812351544e-05, 'epoch': 38.02}
{'rouge-1': {'f': 0.08816031326509807, 'p': 0.0941659608326291, 'r': 0.08492633832204297}, 'rouge-2': {'f': 0.002768986498030548, 'p': 0.002850218639692338, 'r': 0.0027908256760378566}, 'rouge-l': {'f': 0.07013963540952643, 'p': 0.0747516747516755, 'r': 0.06778029135052166}}
{'eval_loss': 5.316232681274414, 'eval_rouge-1': 8.816031326509806, 'eval_rouge-2': 0.2768986498030548, 'eval_rouge-l': 7.013963540952643, 'eval_runtime': 496.9726, 'eval_samples_per_second': 10.051, 'eval_steps_per_second': 2.513, 'epoch': 39.0}
78%|███████▊ | 394500/505700 [40:18:04<7:46:34, 3.97it/s]{'loss': 1.7932, 'learning_rate': 2.20110847189232e-05, 'epoch': 39.01}
{'rouge-1': {'f': 0.07024533095498423, 'p': 0.06610924650140577, 'r': 0.07692154372117986}, 'rouge-2': {'f': 0.0016735183809453616, 'p': 0.0016016016016015876, 'r': 0.0018013460012315595}, 'rouge-l': {'f': 0.057899826910181425, 'p': 0.05433668963080906, 'r': 0.06369218601431641}}
{'eval_loss': 6.119311809539795, 'eval_rouge-1': 7.024533095498422, 'eval_rouge-2': 0.16735183809453616, 'eval_rouge-l': 5.7899826910181424, 'eval_runtime': 1377.0294, 'eval_samples_per_second': 3.627, 'eval_steps_per_second': 0.907, 'epoch': 40.0}
80%|████████ | 404560/505700 [41:27:27<6:57:26, 4.04it/s]
100%|██████████| 1249/1249 [22:55<00:00, 1.07s/it]
80%|████████ | 405000/505700 [41:29:25<7:30:54, 3.72it/s]{'loss': 1.7575, 'learning_rate': 1.9932699920823436e-05, 'epoch': 40.04}
{'rouge-1': {'f': 0.05332369873680843, 'p': 0.05184759227312716, 'r': 0.0564984479612354}, 'rouge-2': {'f': 0.0019986195690730626, 'p': 0.0018714366540453472, 'r': 0.0022330129371342885}, 'rouge-l': {'f': 0.0449711982688417, 'p': 0.04368197985219514, 'r': 0.047714752238434924}}
{'eval_loss': 9.401895523071289, 'eval_rouge-1': 5.332369873680843, 'eval_rouge-2': 0.19986195690730627, 'eval_rouge-l': 4.497119826884171, 'eval_runtime': 1355.3611, 'eval_samples_per_second': 3.685, 'eval_steps_per_second': 0.922, 'epoch': 41.0}
82%|████████▏ | 415000/505700 [42:38:45<6:44:11, 3.74it/s]{'loss': 1.7584, 'learning_rate': 1.795328582739509e-05, 'epoch': 41.03}
{'rouge-1': {'f': 0.07615607154879703, 'p': 0.07761715203575272, 'r': 0.07658700823322474}, 'rouge-2': {'f': 0.0012130817096099218, 'p': 0.001210734544067874, 'r': 0.0012575126815461905}, 'rouge-l': {'f': 0.0613453587746684, 'p': 0.06238331354610218, 'r': 0.06188706882050375}}
{'eval_loss': 5.499425888061523, 'eval_rouge-1': 7.615607154879703, 'eval_rouge-2': 0.12130817096099218, 'eval_rouge-l': 6.13453587746684, 'eval_runtime': 1199.3007, 'eval_samples_per_second': 4.165, 'eval_steps_per_second': 1.041, 'epoch': 42.0}
84%|████████▍ | 425000/505700 [43:45:08<5:57:38, 3.76it/s]{'loss': 1.7549, 'learning_rate': 1.5973871733966748e-05, 'epoch': 42.02}
{'rouge-1': {'f': 0.06094888957522243, 'p': 0.0534941721382391, 'r': 0.07313292274013286}, 'rouge-2': {'f': 0.0026978795155684016, 'p': 0.002260881571226412, 'r': 0.0035267015400277228}, 'rouge-l': {'f': 0.048026754356455606, 'p': 0.04204204204204071, 'r': 0.0578855257951677}}
{'eval_loss': 7.880467891693115, 'eval_rouge-1': 6.094888957522243, 'eval_rouge-2': 0.26978795155684016, 'eval_rouge-l': 4.80267543564556, 'eval_runtime': 1532.2933, 'eval_samples_per_second': 3.26, 'eval_steps_per_second': 0.815, 'epoch': 43.0}
86%|████████▌ | 435000/505700 [44:57:16<5:15:32, 3.73it/s]{'loss': 1.7531, 'learning_rate': 1.3994457640538402e-05, 'epoch': 43.01}
{'rouge-1': {'f': 0.03950283596669141, 'p': 0.03878661269965458, 'r': 0.041331409792127086}, 'rouge-2': {'f': 0.00047312948085755346, 'p': 0.0004626849071293508, 'r': 0.0004974084617572479}, 'rouge-l': {'f': 0.0353845173748737, 'p': 0.03473038255646804, 'r': 0.037054239673240626}}
{'eval_loss': 5.7315144538879395, 'eval_rouge-1': 3.9502835966691405, 'eval_rouge-2': 0.04731294808575535, 'eval_rouge-l': 3.53845173748737, 'eval_runtime': 1325.4952, 'eval_samples_per_second': 3.768, 'eval_steps_per_second': 0.942, 'epoch': 44.0}
88%|████████▊ | 445500/505700 [46:08:15<4:29:53, 3.72it/s]{'loss': 1.7323, 'learning_rate': 1.1916072842438638e-05, 'epoch': 44.05}
{'rouge-1': {'f': 0.051710454593875375, 'p': 0.06843139435731802, 'r': 0.04239033787003719}, 'rouge-2': {'f': 0.00039128931520903467, 'p': 0.0005313005313005313, 'r': 0.00031421046952671876}, 'rouge-l': {'f': 0.04576166571784653, 'p': 0.060430801171540934, 'r': 0.037582203830987315}}
{'eval_loss': 5.324497699737549, 'eval_rouge-1': 5.171045459387537, 'eval_rouge-2': 0.039128931520903465, 'eval_rouge-l': 4.576166571784653, 'eval_runtime': 467.0733, 'eval_samples_per_second': 10.694, 'eval_steps_per_second': 2.674, 'epoch': 45.0}
90%|█████████ | 455500/505700 [47:02:09<3:32:23, 3.94it/s]{'loss': 1.7299, 'learning_rate': 9.936658749010293e-06, 'epoch': 45.04}
{'rouge-1': {'f': 0.050809815897966036, 'p': 0.06726726726726519, 'r': 0.04163924088526707}, 'rouge-2': {'f': 0.00039128931520903467, 'p': 0.0005313005313005313, 'r': 0.00031421046952671876}, 'rouge-l': {'f': 0.045152258195585285, 'p': 0.0596596596596588, 'r': 0.037064930971027615}}
{'eval_loss': 6.4137349128723145, 'eval_rouge-1': 5.080981589796604, 'eval_rouge-2': 0.039128931520903465, 'eval_rouge-l': 4.515225819558529, 'eval_runtime': 439.7664, 'eval_samples_per_second': 11.358, 'eval_steps_per_second': 2.84, 'epoch': 46.0}
92%|█████████▏| 465500/505700 [47:53:23<2:48:27, 3.98it/s]{'loss': 1.7292, 'learning_rate': 7.957244655581949e-06, 'epoch': 46.03}
{'rouge-1': {'f': 0.012283244791941083, 'p': 0.016385616385616416, 'r': 0.010064171737957128}, 'rouge-2': {'f': 0.0001386487124817449, 'p': 0.00019219219219219225, 'r': 0.0001116932395705655}, 'rouge-l': {'f': 0.011631391746208235, 'p': 0.015523215523215613, 'r': 0.00952716720586409}}
{'eval_loss': 8.960765838623047, 'eval_rouge-1': 1.2283244791941084, 'eval_rouge-2': 0.01386487124817449, 'eval_rouge-l': 1.1631391746208235, 'eval_runtime': 455.3793, 'eval_samples_per_second': 10.969, 'eval_steps_per_second': 2.743, 'epoch': 47.0}
94%|█████████▍| 475500/505700 [48:44:26<2:06:18, 3.98it/s]{'loss': 1.7269, 'learning_rate': 5.977830562153603e-06, 'epoch': 47.01}
{'rouge-1': {'f': 0.052457828460058725, 'p': 0.07106337106337399, 'r': 0.04239033787003719}, 'rouge-2': {'f': 0.0003969905088391347, 'p': 0.0005525525525525529, 'r': 0.00031421046952671876}, 'rouge-l': {'f': 0.04642474109030364, 'p': 0.06275506275506483, 'r': 0.037582203830987315}}
{'eval_loss': 5.379085540771484, 'eval_rouge-1': 5.245782846005873, 'eval_rouge-2': 0.03969905088391347, 'eval_rouge-l': 4.642474109030363, 'eval_runtime': 424.1732, 'eval_samples_per_second': 11.776, 'eval_steps_per_second': 2.945, 'epoch': 48.0}
96%|█████████▌| 485500/505700 [49:34:59<1:26:36, 3.89it/s]{'loss': 1.7207, 'learning_rate': 3.998416468725257e-06, 'epoch': 48.0}
{'rouge-1': {'f': 0.07647148664264566, 'p': 0.08236441569775016, 'r': 0.07300613327062662}, 'rouge-2': {'f': 0.0010752368429412867, 'p': 0.001169590643274851, 'r': 0.0010145558755459921}, 'rouge-l': {'f': 0.062442168063776095, 'p': 0.06701060034393393, 'r': 0.05985120945779945}}
{'eval_loss': 6.688559532165527, 'eval_rouge-1': 7.6471486642645665, 'eval_rouge-2': 0.10752368429412867, 'eval_rouge-l': 6.24421680637761, 'eval_runtime': 519.953, 'eval_samples_per_second': 9.607, 'eval_steps_per_second': 2.402, 'epoch': 49.0}
98%|█████████▊| 496000/505700 [50:29:19<40:35, 3.98it/s]{'loss': 1.7117, 'learning_rate': 1.920031670625495e-06, 'epoch': 49.04}
{'rouge-1': {'f': 0.052457828460058725, 'p': 0.07106337106337399, 'r': 0.04239033787003719}, 'rouge-2': {'f': 0.0003969905088391347, 'p': 0.0005525525525525529, 'r': 0.00031421046952671876}, 'rouge-l': {'f': 0.04642474109030364, 'p': 0.06275506275506483, 'r': 0.037582203830987315}}
{'eval_loss': 5.766626358032227, 'eval_rouge-1': 5.245782846005873, 'eval_rouge-2': 0.03969905088391347, 'eval_rouge-l': 4.642474109030363, 'eval_runtime': 429.4195, 'eval_samples_per_second': 11.632, 'eval_steps_per_second': 2.909, 'epoch': 50.0}
{'train_runtime': 184723.0609, 'train_samples_per_second': 10.95, 'train_steps_per_second': 2.738, 'train_loss': 2.2197743133671652, 'epoch': 50.0}
TrainOutput(global_step=505700, training_loss=2.2197743133671652, metrics={'train_runtime': 184723.0609, 'train_samples_per_second': 10.95, 'train_steps_per_second': 2.738, 'train_loss': 2.2197743133671652, 'epoch': 50.0})
100%|██████████| 505700/505700 [51:18:43<00:00, 4.44it/s]
100%|██████████| 1249/1249 [07:09<00:00, 3.03it/s]
100%|██████████| 505700/505700 [51:18:43<00:00, 2.74it/s]
***** train metrics *****
epoch = 50.0
train_loss = 2.2198
train_runtime = 2 days, 3:18:43.06
train_samples_per_second = 10.95
train_steps_per_second = 2.738
tensor([[ 102, 101, 101, 6375, 6375, 130, 20914, 13998, 16280, 14801,
5373, 8343, 11230, 6559, 8343, 11230, 8429, 24167, 9276, 23531,
116, 21498, 11524, 15284, 15134, 6427, 21538, 6442, 135, 102]],
device='cuda:0')
['叔 叔 : 超 爆 笑 电 信 客 服 和 客 服 对 骂 录 音, 这 样 真 的 合 适 吗?']
49
100%|██████████| 1249/1249 [07:09<00:00, 2.91it/s]
{'rouge-1': {'f': 0.052457828460058725, 'p': 0.07106337106337399, 'r': 0.04239033787003719}, 'rouge-2': {'f': 0.0003969905088391347, 'p': 0.0005525525525525529, 'r': 0.00031421046952671876}, 'rouge-l': {'f': 0.04642474109030364, 'p': 0.06275506275506483, 'r': 0.037582203830987315}}
{'eval_loss': 5.766626358032227, 'eval_rouge-1': 5.245782846005873, 'eval_rouge-2': 0.03969905088391347, 'eval_rouge-l': 4.642474109030363, 'eval_runtime': 429.5947, 'eval_samples_per_second': 11.627, 'eval_steps_per_second': 2.907, 'epoch': 50.0}
Process finished with exit code 0
参考:
Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号