2023.3.16 prompt综述
1.prompt产生
预训练语言模型的研究思路通常是“pre-train, fine-tune”。
但是随着预训练模型的不断增大,对其进行fine-tune的硬件要求、有标注的数据的需求也在不断上涨。
为了缓解这个问题,提出了prompt。
2.prompt怎么解决上述问题
pre-train,fine-tune的模式,通常下游任务和预训练任务的差异较大,模型需要大量数据进行微调才能具有较好的效果。
比如:使用bert模型,判断一句话的情感是消极还是积极这样的一个分类任务。
bert的预训练任务是MLM,本身不具备判断句子消极或积极。下游任务需要在模型中添加一个分类器,训练分类器。
prompt的思路是将下游任务重新调整成类似预训练任务的形式,由于模型本身就具有处理预训练任务的能力,所以只需要很少的训练就可以具备处理下游任务的能力。(作者认为pre-train,prompt,predict是自然语言处理的第四范式)
使用上述的例子:
在分类任务中,对于"I love this movie"这句输入,可以在后面加上prompt "The movie is __"这样的形式,然后让预训练模型用表示情感的答案填空,比如"great"、"fantastic"等,最后再将答案转化成积极或消极的标签。这样,通过选取合适的prompt,可以控制模型预测的输出,从而一个完全无监督训练的预训练模型可以被用来解决各种各样的下游任务。
3.prompt的数学描述,分为三步
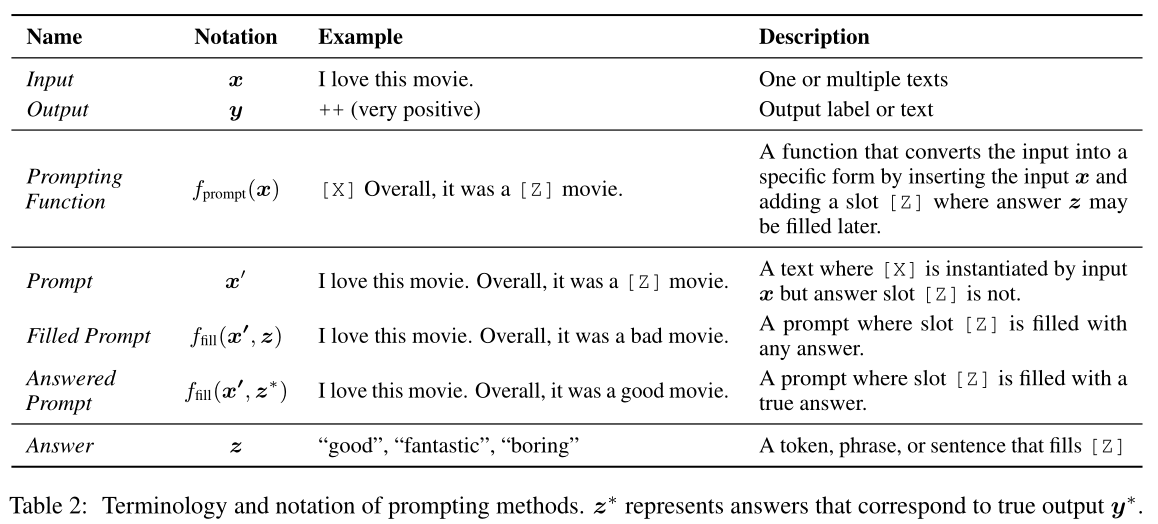
3.1 prompt addition(提示的添加)
在该步骤中,使用一个prompt函数\(f_{prompt}(·)\),把输入\(x\)修改为一个prompt \(x^{'}=f_{prompt}(x)\)。分为两步骤:
- 用一个prompt模板,这个模板有两个槽(slot),一个用于输入x的[x]槽,一个用于生成答案z的[z]槽。
- 把输入x填充到[x]槽。
注意点:
1.
在情感分类例子:"I love this movie. Overall it was a [z] movie"中,[z]处在句子中间,称为完形填空prompt(cloze prompt)。这种适合bert这种完形填空的预训练模型。
在机器翻译例子:"Chinese:[x]English:[z]"中,[z]处在句子末尾,称为前缀prompt(prefix prompt)。这种适合自回归的模型。
在许多情况下,prompt的模板词不一定是自然语言Tokens,也有可能是后来嵌入连续空间的虚拟单词(比如用数字id表示),有一些prompt甚至直接生成连续向量。
3.[x]和[z]的槽的数量可以根据需要灵活更改。
3.2 Answer Search(答案搜索)
首先定义一系列\(z\)的可能值的集合\(Z\)。在生成任务中,\(Z\)可以是整个语言范围内。在分类任务中,\(Z\)是一小部分单词,比如{优秀、好、还行、坏、可怕}。
然后定义一个函数\(f_{fill}(x_{'},z)\),用\(Z\)集合中的答案\(z\)填入[z]中,调用此过程叫filled prompt。如果填入[z]的\(z\)是正确答案,将其称为answered prompt。
最后,通过预训练模型\(P(·;\theta)\)计算相对应的填充提示的概率来搜索潜在答案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号