
PostgreSQL触发器按月分表
前言
设计一张指标表,用于存储大屏上面要展示的各种指标项。指标数据由其他多个第三方通过API调用存入。
① 指标项很多,而且数据需要是增量的,比如:统计类的数值、近n年,月,日的折线图、柱状图和饼图等
② 每项指标又有行政区划的划分,比如:省,市,区县,街道等
所以,这张表的数据量可能会很大,因此考虑PostgreSQL的表划分
环境
| 软件环境 | 版本 |
|---|---|
| 数据库环境 | PostgreSQL 9.6 |
表划分的三种形式
-
范围划分
表被根据一个关键列或一组列划分为"范围",不同的分区的范围之间没有重叠。例如,我们可以根据日期范围划分,或者根据特定业务对象的标识符划分。 -
列表划分
通过显式地列出每一个分区中出现的键值来划分表。 -
哈希划分(11版本才支持)
这里只说范围划分的方式
实现划分
要建立一个划分的表,可以这样做:
-
创建"主"表,所有的分区都将继承它。
这个表将不会包含任何数据。不要在这个表上定义任何检查约束,除非准备将它们应用到所有分区。同样也不需要定义任何索引或者唯一约束。 -
创建一些继承于主表的"子"表。通常,这些表不会在从主表继承的列集中增加任何列。
我们将这些子表认为是分区,尽管它们在各方面来看普通的PostgreSQL表(或者可能是外部表)。 -
为分区表增加表约束以定义每个分区中允许的键值。
如:-- 表名sub_table_y2023m08, 代表这张分区表用于存2023年08月份的数据 CREATE TABLE sub_table_y2023m08 ( CHECK ( logdate >= '2023-08-01' AND logdate < '2023-09-01' ) -- logdate为表中的某个日期字段 )
创建主表
-- 指标表(主表)
create table indicator(
push_time timestamp(6),
pusher varchar(255),
category_path_code varchar(255),
biz_date_time timestamp(6),
org_index_code_path varchar(255),
dimension_code varchar(255) default 'def',
indicator_code varchar(255),
indicator_value varchar(255),
indicator_value2 varchar(255),
create_time timestamp(6)
);
-- 复合主键
alter table indicator add primary key (indicator_code, biz_date_time, org_index_code_path, dimension_code);
-- 字段注释
comment on column indicator.push_time is '数据推送时间';
comment on column indicator.pusher is '推送方';
comment on column indicator.category_path_code is '菜单路径编码';
comment on column indicator.biz_date_time is '业务数据日期时间';
comment on column indicator.org_index_code_path is '组织编码路径(用@隔开,格式: 1.@省编码@; 2.@省编码@市编码@; 3.@省编码@市编码@区县编码@; 4.@省编码@市编码@区县编码@街道编码@)';
comment on column indicator.dimension_code is '维度编码,默认def';
comment on column indicator.indicator_code is '指标编码';
comment on column indicator.indicator_value is '指标值';
comment on column indicator.indicator_value2 is '指标值2';
comment on column indicator.create_time is '创建时间';
触发器自动创建分表
我们希望在向指标表中插入数据时,数据能被重定向到合适的分区表。我们可以通过为主表附加一个合适的触发器函数来实现这一点。
比如:根据
biz_date_time字段,每个月创建一张分区表。
创建触发器函数
-- 创建触发器函数(新增数据时,插入到指定分表中,若分表不存在则创建)
CREATE OR REPLACE FUNCTION auto_insert_sub_indicator_table()
RETURNS trigger AS
$BODY$
DECLARE
time_column_name text ; -- 父表中用于分区的时间字段的名称(推送时间)
curMM varchar(6); -- 'YYYYMM'字串,用做分区子表的后缀
isExist boolean; -- 分区子表,是否已存在
startTime text;
endTime text;
strSQL text;
dimensionCodeDefValue varchar(3); -- (读者可忽略)
-- 如果表名使用很多,也可以声明一个变量表示字表名称
BEGIN
-- 调用前,必须首先初始化(时间字段名):time_column_name [直接从调用参数中获取!!]
-- 没有显示的声明参数,使用TG_ARGV[0]获取参数
time_column_name := TG_ARGV[0];
-- 判断对应分区表 是否已经存在?
EXECUTE 'SELECT $1.'||time_column_name INTO strSQL USING NEW;
curMM := to_char( strSQL::timestamp , 'YYYYMM' );
select count(*) INTO isExist from pg_class where relname = (TG_RELNAME||'_'||curMM);
-- 若不存在, 则插入前需先创建子分区
IF ( isExist = false ) THEN
-- 创建子分区表,写明约束。TG_RELNAME为主表的名字,分表将继承主表的所有字段,但不会继承主键和索引等,需要手动创建。
startTime := curMM||'01 00:00:00.000';
endTime := to_char( startTime::timestamp + interval '1 month', 'YYYY-MM-DD HH24:MI:SS.MS');
strSQL := 'CREATE TABLE IF NOT EXISTS '||TG_RELNAME||'_'||curMM||
' ( CHECK('||time_column_name||'>='''|| startTime ||''' AND '
||time_column_name||'< '''|| endTime ||''' )
) INHERITS ('||TG_RELNAME||') ;';
EXECUTE strSQL;
-- 创建主键,id主键只能保证单个表的唯一,多个子表可能会存在相同的主键。这里为子表创建复合主键
strSQL := 'ALTER TABLE '||TG_RELNAME||'_'||curMM||' ADD PRIMARY KEY(indicator_code, biz_date_time, org_index_code_path, dimension_code) ';
EXECUTE strSQL;
-- 修改dimension_code字段的默认值(读者可忽略)
strSQL := 'ALTER TABLE '||TG_RELNAME||'_'||curMM||' ALTER COLUMN dimension_code set DEFAULT ' || quote_literal('def') || ' ';
EXECUTE strSQL;
-- 创建索引(使用分表的字段),可选。 TODO: 现在先只为业务数据日期时间添加索引,后面有需要再加
strSQL := 'CREATE INDEX '||TG_RELNAME||'_'||curMM||'_INDEX_'||time_column_name||' ON '
||TG_RELNAME||'_'||curMM||' ('||time_column_name||');';
EXECUTE strSQL;
-- 还可自定义其他语句,注意对应表名
END IF;
-- 插入数据到子分区(主键冲突时更新数据,否则新增数据)!
strSQL := 'INSERT INTO '||TG_RELNAME||'_'||curMM||' SELECT $1.*' ||
' on conflict (indicator_code, biz_date_time, org_index_code_path, dimension_code) ' ||
' do update set ' ||
' push_time = EXCLUDED.push_time,' ||
' pusher = EXCLUDED.pusher,' ||
' category_path_code = EXCLUDED.category_path_code,' ||
' biz_date_time = EXCLUDED.biz_date_time,' ||
' org_index_code_path = EXCLUDED.org_index_code_path,' ||
' dimension_code = EXCLUDED.dimension_code,' ||
' indicator_code = EXCLUDED.indicator_code,' ||
' indicator_value = EXCLUDED.indicator_value,' ||
' indicator_value2 = EXCLUDED.indicator_value2';
EXECUTE strSQL USING NEW;
RETURN NULL;
END
$BODY$
LANGUAGE plpgsql;
为主表创建触发器
CREATE TRIGGER insert_indicator_table_trigger BEFORE INSERT ON indicator
FOR EACH ROW
EXECUTE PROCEDURE auto_insert_sub_indicator_table('biz_date_time'); -- 根据业务数据日期时间(每月分组)
批量新增指标数据
新增时只需要插入主表就可以了
<!-- 批量新增(主键重复时修改数据) -->
<insert id="insertBatch" useGeneratedKeys="false" keyProperty="id">
insert into indicator (push_time,pusher,category_path_code,biz_date_time,org_index_code_path,dimension_code,
indicator_code,indicator_value,indicator_value2,create_time) values
<foreach collection="list" item="indicator" index="index" separator=",">
(
#{indicator.pushTime,jdbcType=TIMESTAMP}, #{indicator.pusher,jdbcType=VARCHAR}, #{indicator.categoryPathCode,jdbcType=VARCHAR},
#{indicator.bizDateTime,jdbcType=TIMESTAMP}, #{indicator.orgIndexCodePath,jdbcType=VARCHAR}, #{indicator.dimensionCode,jdbcType=VARCHAR},
#{indicator.indicatorCode,jdbcType=VARCHAR}, #{indicator.indicatorValue,jdbcType=VARCHAR}, #{indicator.indicatorValue2,jdbcType=VARCHAR}, now()
)
</foreach>
on conflict (indicator_code, biz_date_time, org_index_code_path, dimension_code)
do update set
push_time = EXCLUDED.push_time,
pusher = EXCLUDED.pusher,
category_path_code = EXCLUDED.category_path_code,
biz_date_time = EXCLUDED.biz_date_time,
org_index_code_path = EXCLUDED.org_index_code_path,
dimension_code = EXCLUDED.dimension_code,
indicator_code = EXCLUDED.indicator_code,
indicator_value = EXCLUDED.indicator_value,
indicator_value2 = EXCLUDED.indicator_value2
</insert>
新增对应的年月后,自动创建分区表
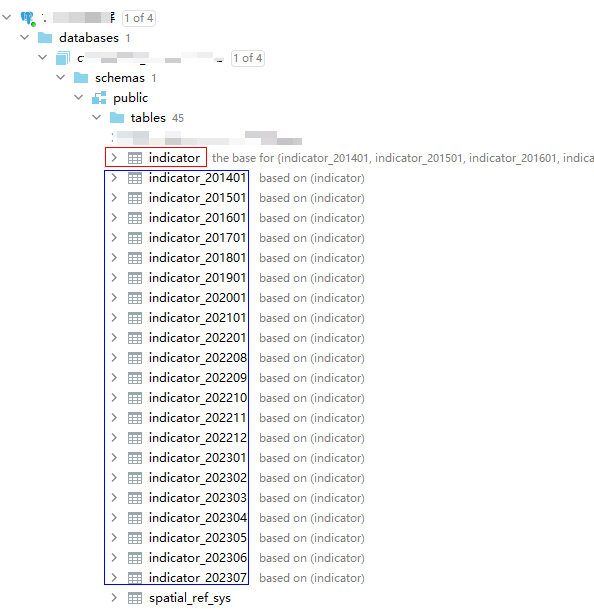
查询
查询时只需要查主表就可以了
例如:
- 查询某个指标最新的数据
<select id="getIndicatorListByCodes" parameterType="com.xx.query.IndicatorDOQuery" resultType="com.xx.entity.Indicator"> select * from ( select <include refid="indicator_base_columns"/>, row_number() over (PARTITION BY indicator_code order by biz_date_time desc) as rn from indicator <trim prefix="where" prefixOverrides="and|or"> category_path_code = #{categoryPathCode} and org_index_code_path = #{orgIndexCodePath} and indicator_code in <foreach collection="indicatorCodeList" separator="," open="(" close=")" index="index" item="indicatorCode"> #{indicatorCode} </foreach> <if test="dimensionCode != null and dimensionCode != ''"> and dimension_code = #{dimensionCode} </if> </trim> ) t where t.rn = 1 </select>
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号