关于字符集和字符编码格式
字符集
Unicode
是世界通用字符集,可以表示世界上所有的字符,长度固定为两个字节,16位
字符编码
ASCLL码
单字节编码,因为一开始计算机编码的需求比较简单,只需要表示出26位英文字母和一些常用字符,不需要用到256位,所以最后一位固定为0,其余七位表示字符。
GB2312
最早制定的汉字编码是GB2312,包括6763个汉字和682个其它符号 95年重新修订了编码,命名GBK1.0,共收录了21886个符号。 之后又推出了GBK18030编码,共收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字,
GBK
GBK编码是对GB2312编码的扩充,容纳的汉字更多,但仅仅是扩充,没有质的变化。保留了所有G B2312编码,在此基础上进行编码范围的扩充。
UTF-8
UTF-8 UTF-8最大的一个特点, 就是它是一种变长的编码方式. 它可以使用1~6个字节表示一个符
号, 根据不同的符号而变化字节长度.
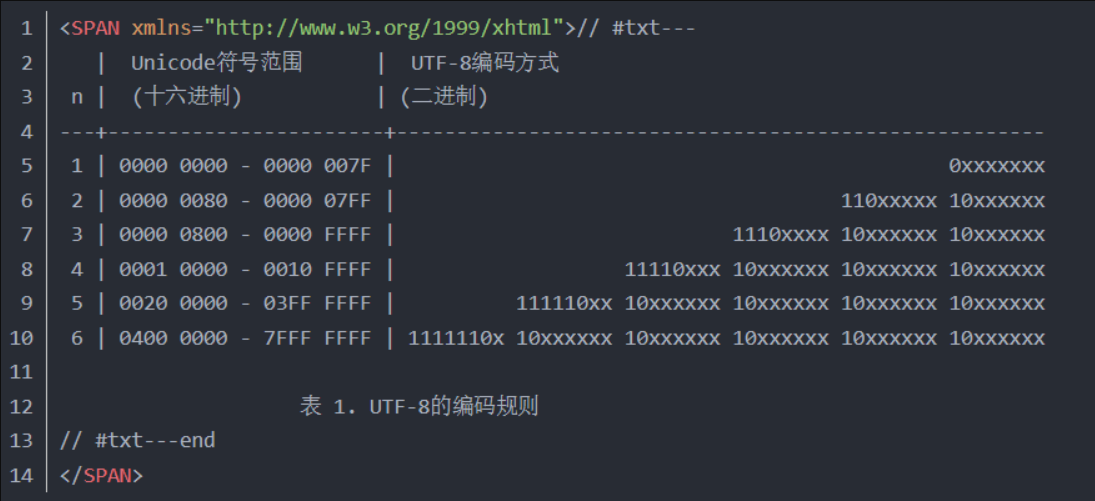
UTF-8的编码规则
- 对于单字节的符号, 字节的第一位设为0, 后面7位为这个符号的unicode码. 因此对于
英语字母, UTF-8编码和ASCII码是相同的. - 对于n字节的符号(n>1), 第一个字节的前n位都设为1, 第n+1位设为0, 后面字节的前
两位一律设为10. 剩下的没有提及的二进制位, 全部为这个符号的unicode码.
其他
Java
在Java中String字符串是直接以Unicode字符集存储的即一个字符占两个字节,不带字符编码,而String.toBytes(charsetName)得到的bytes是带编码格式的,格式就是你传入的charsetName,我们不妨把toBytes的这个过程叫做“编码”;另外,new String(byte[], charsetName)是把一个byte数组(带编码格式)以charsetName指定的编码格式翻译为一个不带编码格式的String对象,我们不妨把这个过程叫“解码”
本文来自博客园,作者:两小无猜,转载请注明原文链接:https://www.cnblogs.com/charlottepl/p/12901463.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号