Python编程-文件操作open函数
Python 中,对文件的操作有很多种,常见的操作包括创建、删除、修改权限、读取、写入等,这些操作可大致分为以下 2 类:
删除、修改权限:作用于文件本身,属于系统级操作。
写入、读取:是文件最常用的操作,作用于文件的内容,属于应用级操作。
1、打开文件
在python中,使用open函数可以打开一个已经存在的文件,或者创建一个新的文件
格式:
f = open(‘文件’, 'w',encoding='utf-8')
f = open('文件', 'r',',encoding='utf-8')不同的文件打开方式:
| 模式 | 意义 | 注意事项 |
|---|---|---|
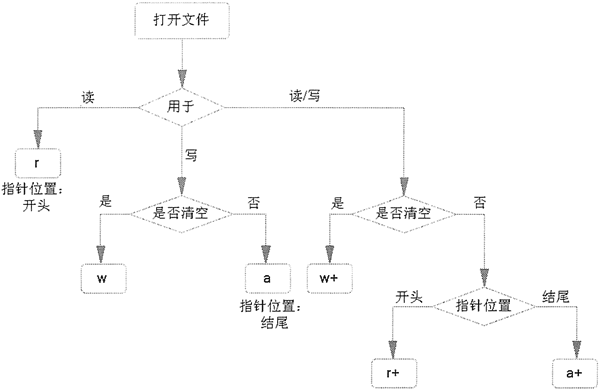
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| rb | 以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件、文件传输等。 | |
| r+ | 打开文件后,既可以从头读取文件内容,可以在文件末尾追加写入内容 | |
| rb+ | 以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 | |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| wb | 以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) | |
| w+ | 打开文件后,会对原有内容进行清空,并对该文件有读写权限。 | |
| wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | |
| ab | 以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| a+ | 以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| ab+ | 以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
2、常用文件操作
f = open("yesterday.txt",'r+',encoding="utf-8")2.1 读取文件的全部内容
print(f.read())2.2 按行读取文件内容
#每次执行打印,都会打印一行,文件指针往后移动一行
print(f.readline)2.3 按行读取全部内容
#将文件中的内容,按行读取成列表
print(f.readlines())
['When I was young\n', '\n', '当我年少时\n', '\n', 'I’d listen to the radio\n', '\n', '我喜欢听收音机\n', '\n']2.4 文件写入
f = open("yesterday.txt",'w',encoding="utf-8")
f.write("hello,world")2.5 文件指针操作
#打印当前文件指针的字节位置
print(f.tell())
#将文件光标移动到指定的位置
print(f.seek(0))
#判断f的文件指针是否是可移动的
print(f.seekable())2.6 文件修改
python中的文件并不能直接修改源文件,更多时候是通过读取源文件内容然后在内存中修改后写入到新的文件中,如:
#先读取文件再修改写入到新文件
f = open("yesterday.txt","r",encoding="utf-8")
f_new =open("yesterday-new.txt","w",encoding="utf-8")
for line in f:
if "收音机" in line:
line = line.replace("收音机","电视机")
f_new.write(line
f.close()
f_new.close()2.7 with open函数
with open语句可以避免由于打开文件后忘记关闭,导致程序在内存中积累了大量的文件句柄从而导致的性能问题,如:
with open('test.txt','r') as f:
for line in f:
print(line)如此方式,在with代码块执行完毕后,语句程序内部会自动关闭并释放相应的文件资源。
在Python 2.7之后,with语句又支持同时对多个文件进行上下文管理,如:
count1 =0
count2 =0
with open("yesterday.txt","r",encoding="utf-8") as f , \
open("yesterday-new.txt","r",encoding="utf-8") as f2:
for line in f:
count1 +=1
for line in f2:
count2 +=1
print(count1)
print(count2)2.8 文件编码转换
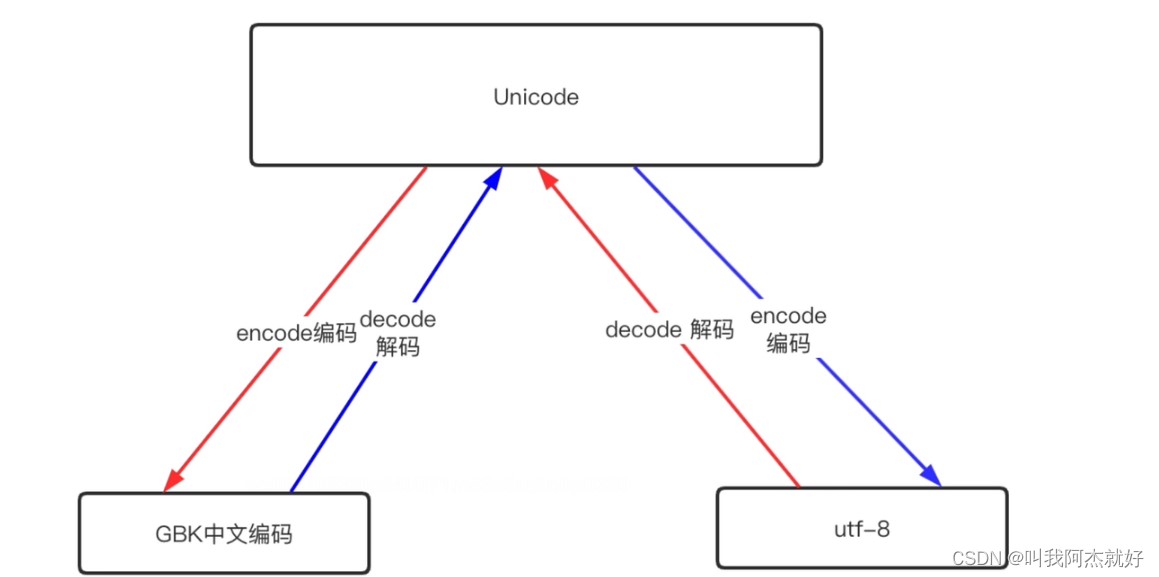
python解释器是用unicode进行解释的,所以需要用解码编码的方式进行一个相互转化,unicode相当于做为一个中间沟通解释的编码,utf-8是unicode的拓展集,可以兼容打印
GBK需要转换为UTF-8的格式流程:
1、首先需要通过解码[decode]转换为Unicode编码
2、然后通过编码[encode]转换为utf-8编码
s_gbk="这是gbk".encode('gbk')
s_utf="这是utf-8".encode('utf-8')
print(f'编码后的s_gbk:{s_gbk},s_utf:{s_utf}')
#编码后的s_gbk:b'\xd5\xe2\xca\xc7gbk',s_utf:b'\xe8\xbf\x99\xe6\x98\xafutf-8'
s_gbk= s_gbk.decode('gbk')
s_utf=s_utf.decode('utf-8')
print(f'编码后的s_gbk:{s_gbk},s_utf:{s_utf}')
#编码后的s_gbk:这是gbk,s_utf:这是utf-8#由于Python3默认是unicode编码,因此可以直接进行encode编码
#!/usr/bin/python3
# -*- encoding:utf-8 -*-
#上面一行改变的只是文件的编码,python3还是以unicode编码运行
import sys
print(sys.getdefaultencoding())
s = "你好"
to_utf = s.encode('utf-8')
to_gbk1= s.encode('gbk')
print(to_utf)
print(to_gbk1)本文来自博客园,作者:酒粒,转载请注明原文链接:https://www.cnblogs.com/charliewch/p/16514548.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号