

Rabbitmq集群搭建
1、什么是Rabbitmq集群?
Rabbitmq集群的目的就是为了实现Rabbitmq的高可用,可分为两种,普通集群和镜像集群。
普通集群:主备架构,备用节点拥有跟主节点相同的元数据,但是并不会同步相应的消息数据(一个节点上能看到所有队列,当不一定有全部的队列消息)。当消息进入主节点的Queue后,consumer从备节点消费时,RabbitMQ会临时在主备节点间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。这种方式实现的只是Rabbitmq服务的高可用,并不是队列的高可用,可靠性低。
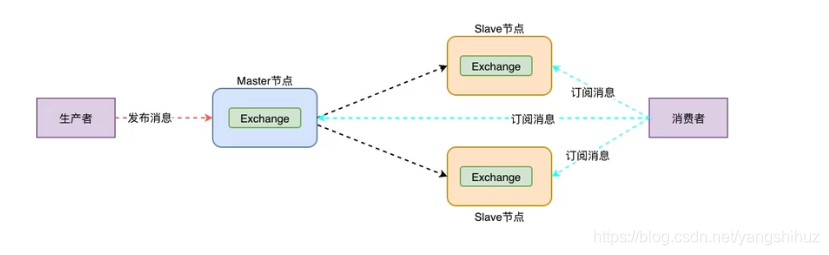
镜像集群:即在普通集群的基础上,针对所有队列或者特定队列开启了镜像的集群。其实本质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
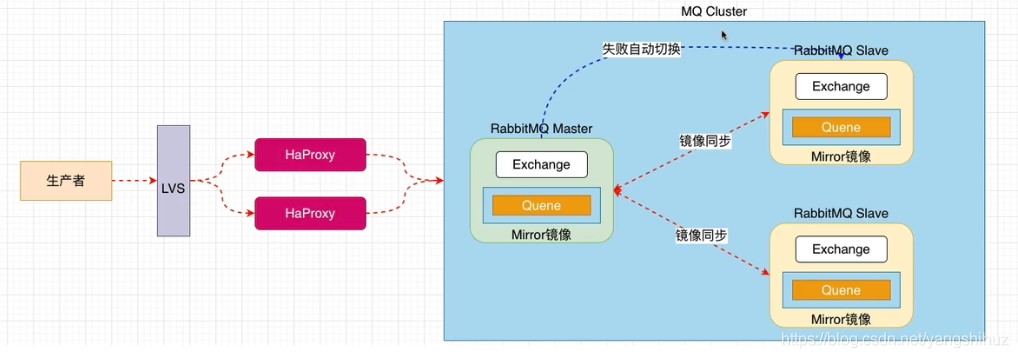
2、部署环境
事先准备三台机器,并配置相应的hosts解析文件,如下所示:
vim /etc/hosts
192.168.0.108 node1
192.168.0.105 node2
192.168.0.107 node3(可选)修改rabbitmq集群的存储配置
vim /etc/rabbitmq/rabbitmq-env.conf
NODENAME=rabbit@rabbitmq-01
RABBITMQ_MNESIA_BASE=/data/rabbitmq/mnesia
RABBITMQ_LOG_BASE=/data/rabbitmq/logs/rabbitmq3、安装并启动rabbitmq
分别在三台服务器上安装并启动rabbitmq-server
yum install -y epel-release
yum install -y erlang
yum install -y rabbitmq-server
systemctl start rabbitmq-server
systemctl status rabbitmq-server4、配置并启动集群
将node1的erlang.cookie文件同步复制到其他两台节点(该文件是rabbitmq服务启动时自动生成),因为节点之间需要通过此文件来判断是否允许交流(判断是否属于集群内部节点),如果三台机器的此文件内容不一致则集群无法启动成功。
scp /var/lib/rabbitmq/.erlang.cookie node2:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie node3:/var/lib/rabbitmq/同步完后,分别在node2和node3上执行下述命令,加入集群
#先停止服务(注:这里的参数stop_app和stop是不一样的,stop是停掉服务,stop_app是停掉这个节点,但是并没有停止rabbitmq依赖的erlang进程)
rabbitmqctl stop_app
#重置rabbitmq状态(注意这里会将该节点下的所有数据全部清除,包括队列、交换器、虚拟主机和用户等)
rabbitmqctl reset
#加入集群
rabbitmqctl join_cluster rabbit@node1
#启动服务
rabbitmqctl start_app
#查询集群状态
rabbitmqctl cluster_status5、管理集群
重启节点
systemctl restart rabbitmq-server重置节点
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node3
rabbitmqctl start_app拆分/删除集群节点,在对应节点上执行
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app创建内存节点
rabbitmqctl join_cluster --ram rabbit@node3改变节点类型
rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type disc
# disc是磁盘节点,ram是内存节点
rabbitmqctl start_app6、其他常用操作
#修改集群名称
rabbitmqctl set_cluster_name rabbitmq_test_cluster
#配置镜像队列同步
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
#配置镜像队列的副本数
rabbitmqctl set_policy ha-two "^" ‘{"ha-mode":"exactly","ha-params":"2","ha-sync-mode":"automatic"}’
#指定ha开头的队列开启镜像复制
rabbitmqctl set_policy ha-all "^ha." ‘{"ha-mode":"all"}’7、备份Rabbitmq数据
RabbitMQ定义和消息存储在位于节点数据目录中的内部数据库中,要获取目录路径,请针对正在运行的RabbitMQ节点运行以下命令:
rabbitmqctl eval 'rabbit_mnesia:dir().'
输出示例:
/var/lib/rabbitmq/mnesia/rabbit@rabbitmq-server01在从3.7.0开始的RabbitMQ版本中,所有消息数据都组合在msg_stores/vhosts目录中,并存储在每个vhost的子目录中,每个vhost目录都使用散列命名,并包含带有vhost名称的.vhost文件,因此可以单独备份特定的vhost消息集。
要做RabbitMQ定义和消息数据备份,复制或归档此目录及其内容,但先需要停止RabbitMQ服务:
sudo systemctl stop rabbitmq-server.service以下示例将创建一个存档:
tar cvf rabbitmq-backup.tgz /var/lib/rabbitmq/mnesia/rabbit@rabbitmq-server01恢复RabbitMQ数据
要从备份中还原,请将文件从备份提取到数据目录。
内部节点数据库在某些记录中存储节点的名称,如果节点名称发生更改,则必须首先使用以下rabbitmqctl命令更新数据库以便更改:
rabbitmqctl rename_cluster_node <oldnode> <newnode>当新节点以备份目录和匹配的节点名称启动时,它会根据需要执行升级步骤并继续引导。
参考:
https://blog.csdn.net/yangshihuz/article/details/114120589
https://www.cnblogs.com/knowledgesea/p/6535766.html
https://ywnz.com/linuxyffq/4005.html
本文来自博客园,作者:酒粒,转载请注明原文链接:https://www.cnblogs.com/charliewch/p/16297578.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构