
理解kubernetes环境的iptables
node节点的iptables是由kube-proxy生成的,具体实现可以参见kube-proxy的代码
kube-proxy只修改了filter和nat表,它对iptables的链进行了扩充,自定义了KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP五个链,并主要通过为 KUBE-SERVICES链(附着在PREROUTING和OUTPUT)增加rule来配制traffic routing 规则,官方定义如下:
// the services chain
kubeServicesChain utiliptables.Chain = "KUBE-SERVICES"
// the external services chain
kubeExternalServicesChain utiliptables.Chain = "KUBE-EXTERNAL-SERVICES"
// the nodeports chain
kubeNodePortsChain utiliptables.Chain = "KUBE-NODEPORTS"
// the kubernetes postrouting chain
kubePostroutingChain utiliptables.Chain = "KUBE-POSTROUTING"
// the mark-for-masquerade chain
KubeMarkMasqChain utiliptables.Chain = "KUBE-MARK-MASQ" /*对于未能匹配到跳转规则的traffic set mark 0x8000,有此标记的数据包会在filter表drop掉*/
// the mark-for-drop chain
KubeMarkDropChain utiliptables.Chain = "KUBE-MARK-DROP" /*对于符合条件的包 set mark 0x4000, 有此标记的数据包会在KUBE-POSTROUTING chain中统一做MASQUERADE*/
// the kubernetes forward chain
kubeForwardChain utiliptables.Chain = "KUBE-FORWARD"
KUBE-MARK-MASQ和KUBE-MARK-DROP
这两个规则主要用来对经过的报文打标签,打上标签的报文可能会做相应处理,打标签处理如下:
(注:iptables set mark的用法可以参见
https://unix.stackexchange.com/questions/282993/how-to-add-marks-together-in-iptables-targets-mark-and-connmark
http://ipset.netfilter.org/iptables-extensions.man.html)
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000 -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
KUBE-MARK-DROP和KUBE-MARK-MASQ本质上就是使用了iptables的MARK命令
Chain KUBE-MARK-DROP (6 references)
pkts bytes target prot opt in out source destination
0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x8000
Chain KUBE-MARK-MASQ (89 references)
pkts bytes target prot opt in out source destination
88 5280 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000
对于KUBE-MARK-MASQ链中所有规则设置了kubernetes独有MARK标记,在KUBE-POSTROUTING链中对NODE节点上匹配kubernetes独有MARK标记的数据包,当报文离开node节点时进行SNAT,MASQUERADE源IP
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
而对于KUBE-MARK-DROP设置标记的报文则会在KUBE_FIREWALL中全部丢弃
-A KUBE-FIREWALL -m comment --comment "kubernetes firewall for dropping marked packets" -m mark --mark 0x8000/0x8000 -j DROP
KUBE_SVC和KUBE-SEP
Kube-proxy接着对每个服务创建“KUBE-SVC-”链,并在nat表中将KUBE-SERVICES链中每个目标地址是service的数据包导入这个“KUBE-SVC-”链,如果endpoint尚未创建,KUBE-SVC-链中没有规则,任何incomming packets在规则匹配失败后会被KUBE-MARK-DROP。在iptables的filter中有如下处理,如果KUBE-SVC处理失败会通过KUBE_FIREWALL丢弃
Chain INPUT (policy ACCEPT 209 packets, 378K bytes) pkts bytes target prot opt in out source destination 540K 1370M KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */ 540K 1370M KUBE-FIREWALL all -- * * 0.0.0.0/0 0.0.0.0/0
KUBE_FIREWALL内容如下,就是直接丢弃所有报文:
Chain KUBE-FIREWALL (2 references)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes firewall for dropping marked packets */ mark match 0x8000/0x8000
下面是对nexus的service的处理,可以看到该规对目的IP为172.21.12.49(Cluster IP)且目的端口为8080的报文作了特殊处理:KUBE-SVC-HVYO5BWEF5HC7MD7
-A KUBE-SERVICES -d 172.21.12.49/32 -p tcp -m comment --comment "default/sonatype-nexus: cluster IP" -m tcp --dport 8080 -j KUBE-SVC-HVYO5BWEF5HC7MD7
KUBE-SEP表示的是KUBE-SVC对应的endpoint,当接收到的 serviceInfo中包含endpoint信息时,为endpoint创建跳转规则,如上述的KUBE-SVC-HVYO5BWEF5HC7MD7有endpoint,其iptables规则如下:
-A KUBE-SVC-HVYO5BWEF5HC7MD7 -m comment --comment "oqton-backoffice/sonatype-nexus:" -j KUBE-SEP-ESZGVIJJ5GN2KKU
KUBE-SEP-ESZGVIJJ5GN2KKU中的处理为将经过该链的所有tcp报文,DNAT为container 内部暴露的访问方式172.20.5.141:8080。结合对KUBE-SVC的处理可可知,这种访问方式就是cluster IP的访问方式,即将目的IP是cluster IP且目的端口是service暴露的端口的报文DNAT为目的IP是container且目的端口是container暴露的端口的报文,
-A KUBE-SEP-ESZGVIJJ5GN2KKUR -p tcp -m comment --comment "oqton-backoffice/sonatype-nexus:" -m tcp -j DNAT --to-destination 172.20.5.141:8080
如果service类型为nodePort,(从LB转发至node的数据包均属此类)那么将KUBE-NODEPORTS链中每个目的地址是NODE节点端口的数据包导入这个“KUBE-SVC-”链;KUBE-NODEPORTS必须位于KUBE-SERVICE链的最后一个,可以看到iptables在处理报文时会优先处理目的IP为cluster IP的报文,匹配失败之后再去使用NodePort方式。如下规则表明,NodePort方式下会将目的ip为node节点且端口为node节点暴露的端口的报文进行KUBE-SVC-HVYO5BWEF5HC7MD7处理,KUBE-SVC-HVYO5BWEF5HC7MD7中会对报文进行DNAT转换。因此Custer IP和NodePort方式的唯一不同点就是KUBE-SERVICE中是根据cluster IP还是根据node port进行匹配
"-m addrtype --dst-type LOCAL"表示对目的地址是本机地址的报文执行KUBE-NODEPORTS链的操作
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m comment --comment "oqton-backoffice/sonatype-nexus:" -m tcp --dport 32257 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "oqton-backoffice/sonatype-nexus:" -m tcp --dport 32257 -j KUBE-SVC-HVYO5BWEF5HC7MD7
如果服务用到了loadblance,此时报文是从LB inbound的,报文的outbound处理则是通过KUBE-FW实现outbound报文的负载均衡。如下对目的IP是50.1.1.1(LB公网IP)且目的端口是443(一般是https)的报文作了KUBE-FW-J4ENLV444DNEMLR3处理。(参考kubernetes ingress到pod的数据流)
-A KUBE-SERVICES -d 50.1.1.1/32 -p tcp -m comment --comment "kube-system/nginx-ingress-lb:https loadbalancer IP" -m tcp --dport 443 -j KUBE-FW-J4ENLV444DNEMLR3
如下在KUBE-FW-J4ENLV444DNEMLR3中显示的是LB的3个endpoint(该endpoint可能是service),使用比率对报文进行了负载均衡控制
Chain KUBE-SVC-J4ENLV444DNEMLR3 (3 references)
10 600 KUBE-SEP-ZVUNFBS77WHMPNFT all -- * * 0.0.0.0/0 0.0.0.0/0 /* kube-system/nginx-ingress-lb:https */ statistic mode random probability 0.33332999982
18 1080 KUBE-SEP-Y47C2UBHCAA5SP4C all -- * * 0.0.0.0/0 0.0.0.0/0 /* kube-system/nginx-ingress-lb:https */ statistic mode random probability 0.50000000000
16 960 KUBE-SEP-QGNNICTBV4CXTTZM all -- * * 0.0.0.0/0 0.0.0.0/0 /* kube-system/nginx-ingress-lb:https */
而上述3条链对应的处理如下,可以看到上述的每条链都作了DNAT,将目的IP由LB公网IP转换为LB的container IP
-A KUBE-SEP-ZVUNFBS77WHMPNFT -s 172.20.1.231/32 -m comment --comment "kube-system/nginx-ingress-lb:https" -j KUBE-MARK-MASQ -A KUBE-SEP-ZVUNFBS77WHMPNFT -p tcp -m comment --comment "kube-system/nginx-ingress-lb:https" -m tcp -j DNAT --to-destination 172.20.1.231:443 -A KUBE-SEP-Y47C2UBHCAA5SP4C -s 172.20.2.191/32 -m comment --comment "kube-system/nginx-ingress-lb:https" -j KUBE-MARK-MASQ -A KUBE-SEP-Y47C2UBHCAA5SP4C -p tcp -m comment --comment "kube-system/nginx-ingress-lb:https" -m tcp -j DNAT --to-destination 172.20.2.191:443 -A KUBE-SEP-QGNNICTBV4CXTTZM -s 172.20.2.3/32 -m comment --comment "kube-system/nginx-ingress-lb:https" -j KUBE-MARK-MASQ -A KUBE-SEP-QGNNICTBV4CXTTZM -p tcp -m comment --comment "kube-system/nginx-ingress-lb:https" -m tcp -j DNAT --to-destination 172.20.2.3:443
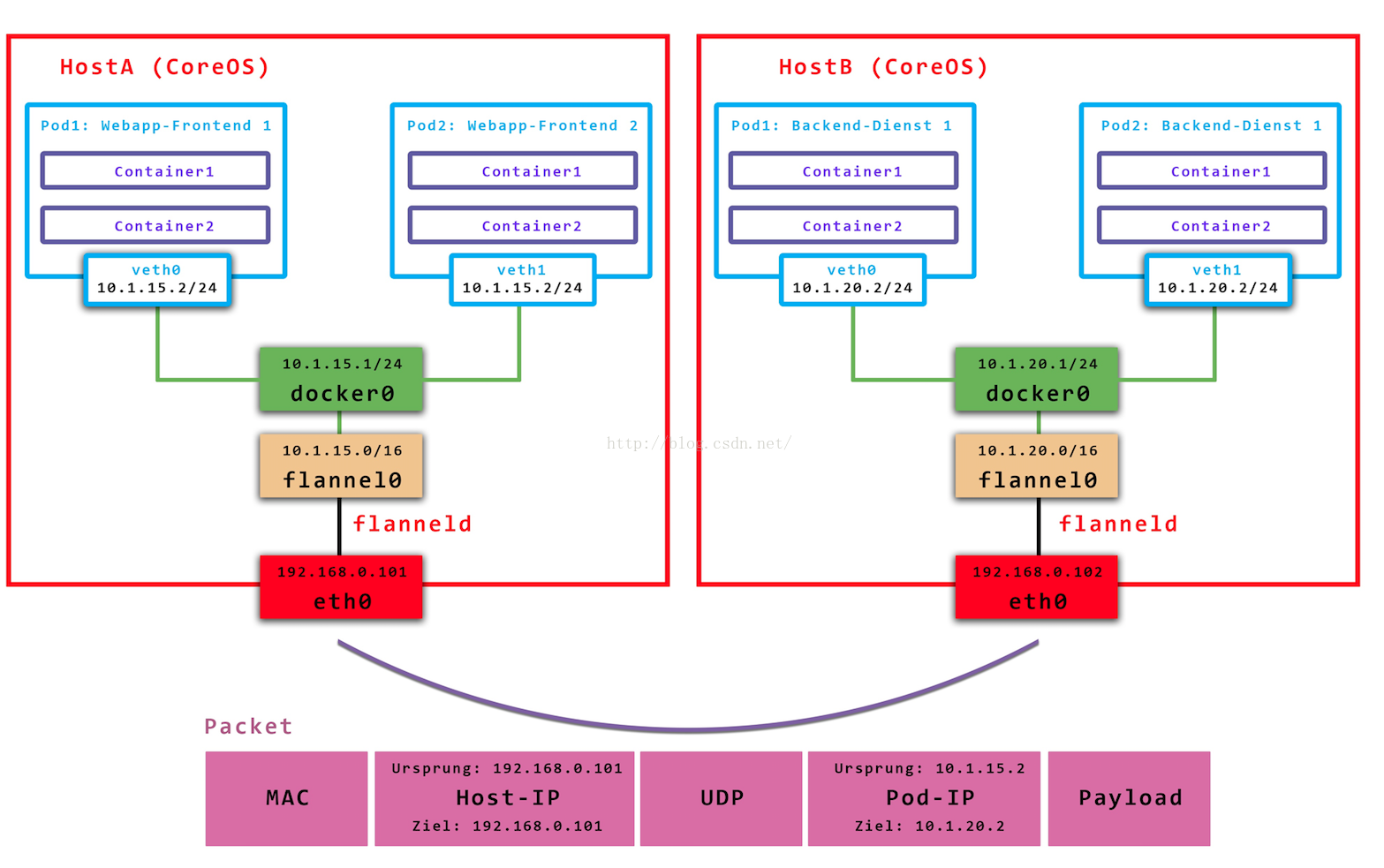
从上面可以看出,node节点上的iptables中有到达所有service的规则,service 的cluster IP并不是一个实际的IP,它的存在只是为了找出实际的endpoint地址,对达到cluster IP的报文都要进行DNAT为Pod IP(+port),不同node上的报文实际上是通过POD IP传输的,cluster IP只是本node节点的一个概念,用于查找并DNAT,即目的地址为clutter IP的报文只是本node发送的,其他节点不会发送(也没有路由支持),即默认下cluster ip仅支持本node节点的service访问,如果需要跨node节点访问,可以使用插件实现,如flannel,它将pod ip进行了封装
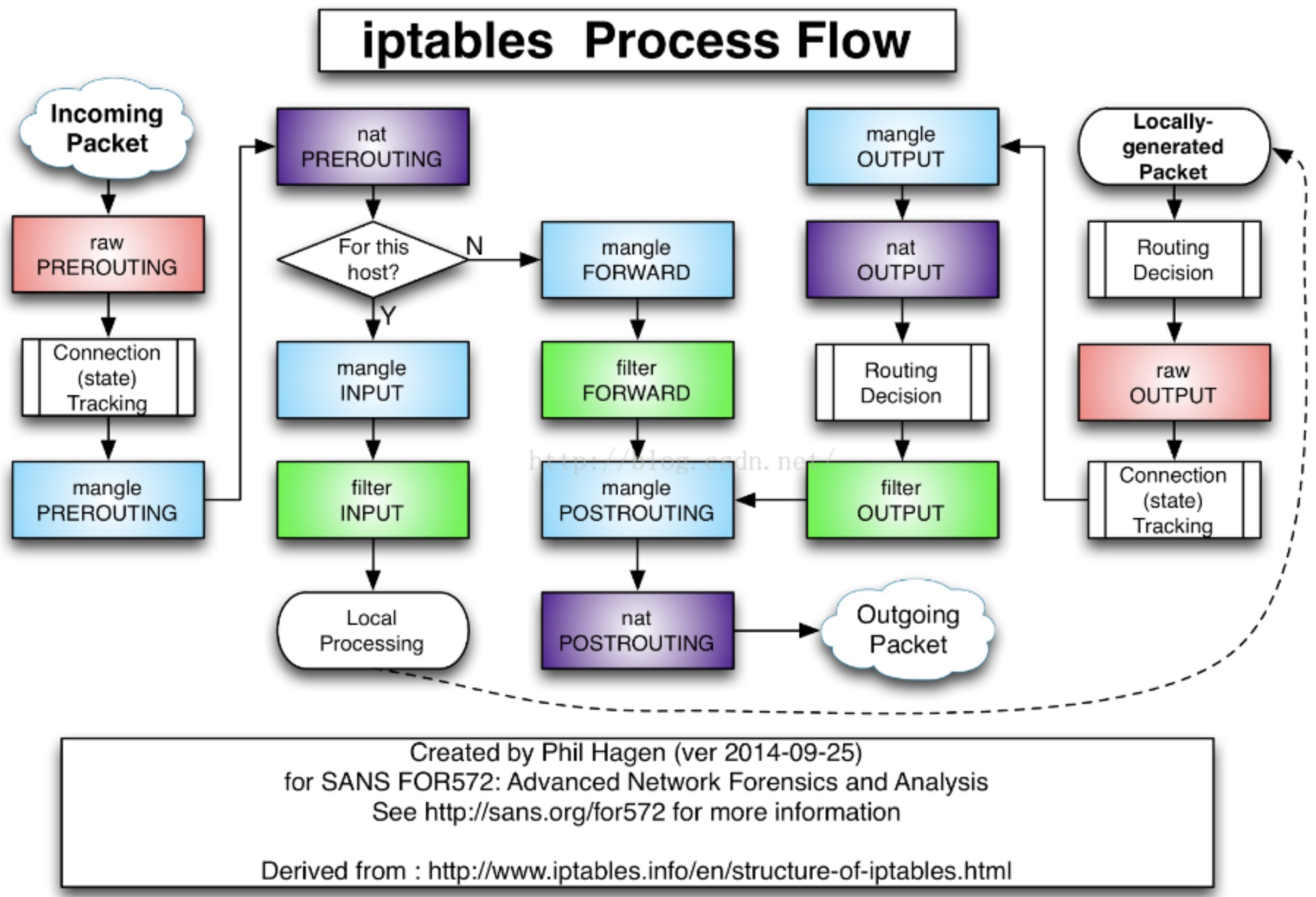
- 至此已经讲完了kubernetes的容器中iptables的基本访问方式,在分析一个应用的iptables规则时,可以从KUBE-SERVICE入手,并结合该应用关联的服务(如ingress LB等)进行分析。
- 查看iptables表项最好结合iptables-save以及如iptables -t nat -nvL的方式,前者给出了iptables的具体内容,但比较杂乱;后者给出了iptables的结构,可以方便地看出表中的内容,但是没有详细信息,二者结合起来才能比较好地分析。链接状态可以查看/proc/net/nf_conntrack
TIPs:
- openshift下使用如下配置创建nodeport类型的service。"nodeport"表示通过nodeport方式访问的端口;"port"表示通过service方式访问的端口;"targetPort"表示后端服务"app"暴露的pod端口。通过nodeport访问集群的流程为: {dstNodeIP:dstNodePort}-->(iptables)DNAT-->{dstPodIP:dstPodPort}。创建nodeport类型的service时会在每个node上开启一个端口号为{nodePort}的监听socket(单独使用docker run -p启动nodeport进程为docker-proxy),其中一个作用方便给应用通过loopback地址访问容器服务,删除该进程后将无法通过host的loopback接口访问容器服务,更多参见docker-proxy。
同时也可以通过:{service:servicePort}-->(iptables)DNAT-->{dstPodIP:dstPodPort}的方式在集群内部访问后端服务。
apiVersion: v1 kind: Service metadata: annotations: name: app-test namespace: openshift-monitoring spec: externalTrafficPolicy: Cluster ports: - name: cluster nodePort: 33333 port: 44444 protocol: TCP targetPort: 55555 selector: app: app sessionAffinity: None type: NodePort
主要参考:https://blog.csdn.net/ebay/article/details/52798074
kube-proxy的转发规则查看:http://www.lijiaocn.com/%E9%A1%B9%E7%9B%AE/2017/03/27/Kubernetes-kube-proxy.html
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/9588019.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号