
redis运维手册
- redis集群资源配置建议
- basic replication
- Redis的配置
- Redis Sentinel
- Redis Cluster
- 持久化
- Security
- Cli
- 监控
- 性能优化
- Tips
redis集群资源配置建议
Production environment
| 分类 | 描述 | 最小要求 | 建议 |
|---|---|---|---|
| 每个集群的节点 | 至少需要3个节点来满足异常处理、节点故障和网络隔离等情况下的可靠性和高可用。 | 3 节点 | >= 3 节点 (节点数必须是奇数) |
| 每个节点的cores | - | 4 cores | >=8 cores |
| 每个节点的内存 | RAM大小应考虑到规划的redis存储容量 | 15GB | >=30GB |
| 临时存储 | 用于保存RDB和集群日志文件 | RAM x 2 | >= RAM x 4 |
| 持久化存储 | 用于保存RDB和AOF文件 | RAM x 3 | In-memory >= RAM x 6 (极端 '写' 场景) 除外 |
| 网络 | 推荐使用多NICs节点,每个NIC >100Mbps | 1G | >=10G |
basic replication
本节描述了redis master-replica的基本复制流程和机制,这也是Sentinel和Cluster的基础。由于这种模式不支持故障转移,因此在master出现故障时,只能通过手动(或脚本)执行FAILOVER进行故障转移。
redis通过leader-follower(master-replica机制)实现高可用。replica实例作为master实例的拷贝。
配置
在replicas的配置文件中增加如下配置即可启用redis replication功能。此外还可以通过调用REPLICAOF命令设置replica的replication配置(192.168.1.1 6379 为master的地址和端口):
replicaof 192.168.1.1 6379
replication的特性
redis 默认使用异步replication,即replica会异步向master确认其周期性接收到的数据,因此master不会在数据发送之后等待replica的确认。这种方式下可能会丢失replica的确认消息,但增加了吞吐量。
在使用replication功能时强烈建议在master和replicas中开启持久化。如果master没有启用持久化,那么在master重启之后其dataset为空,replica会在replication过程中损坏其原先的dataset拷贝。
客户端可以通过WAIT命令实现特定数据的同步replication。
redis的replication有如下特性:
- redis使用异步复制方式,即replica会异步确认master发送的数据。
- 一个master可以有多个replicas
- replicas除了可以连接到master之外,还可以连接到其他replica,呈级联模式(A -> B -> C)。从redis 4.0开始,所有的sub-replicas都会从master接收到相同的replication流。
- replication不会阻塞master,意味着master可以在处理一个或多个replica的初始化同步或部分重同步时的同时继续处理请求。
- replication也不会阻塞replica,即replica在初始化(从master)同步数据的同时,还能使用老的dataset处理请求(redis.conf的
replica-serve-stale-data为yes,设为no则在replication流断开时会返回错误)。但在初始化同步结束之后,必须删除老的dataset并加载新的dataset,在这段时间内,replica会阻塞入站连接(对于较大的dataset,可能会持续数秒)。 - 可以使用replication实现可扩展性,如使用多个replicas处理只读请求。
replication中的网络连接
master和replica的连接有如下情况:
- 如果master和replica之间的链路正常,master会将其dataset的变更(客户端的写入、key的过期和驱逐以及master dataset变更等)通过命令流发送到replica
- 如果master和replica之间的链路出现故障,replica会通过重连尝试执行部分同步,即获取断链期间丢失的命令。
- 如果无法执行部分同步,则replica会请求完整同步,该过程比较复杂,涉及master创建完整的数据快照并将其发送给replica,之后继续通过命令流发送dataset变更。
replication过程
部分同步和完整同步的过程
每个redis master都有一个replication ID,用于标记一个历史dataset。replica和master都有一个offset(字节偏移),master的offset表示其当前dataset的最新字节偏移,replica的offset表示从master复制到的字节偏移。
当replicas连接到master时,会使用 PSYNC(Partial Resynchronization) 命令向master发送其保存的master replication ID和目前处理到的offset,通过这种方式。master可以只向replica发送所需的增量部分(部分重同步)。如果master buffers中没有足够的backlog(repl-backlog-size,repl-backlog-size = 主从最大延迟时间(秒) × 每秒写入量(bytes/s)),或者replica提供了一个master不知道的replication ID,则会执行完整(重)同步。
The backlog is a buffer that accumulates replica data when replicas are disconnected for some time, so that when a replica wants to reconnect again, often a full resync is not needed, but a partial resync is enough, just passing the portion of data the replica missed while disconnected.
The bigger the replication backlog, the longer the replica can endure the disconnect and later be able to perform a partial resynchronization. The backlog is only allocated if there is at least one replica connected.
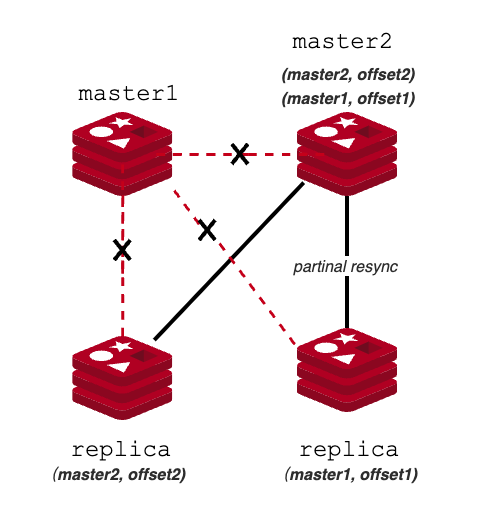
replication的一个例子如下:
- Redis-1:replid和offset为默认值,说明它从未与主节点进行过同步操作,所以是进行全量同步;
- Redis-2:replid主从节点一致,replica_offset>=backlog_off并且replica_offset<offset,说明该从节点丢失的数据可以通过backlog找回,所以可以进行部分同步;
- Redis-3:replid主从节点一致,replica_offset<backlog_off,说明该节点丢失的数据过多,通过复制backlog无法找回,所以是进行全量同步;
- Redis-4:replid主从节点一致,之前不是与当前节点进行主从复制,所以是进行全量同步;

master会启动一个后台进程来创建一个RDB文件,同时缓存从clients新接收到的所有写命令。当后台进程结束后,master会将该RDB文件传送给replica,replica会将其保存到磁盘,再加载到内存中。之后master会通过命令流将所有缓存的命令发送给replica。
通常一个完整(重)同步会要求master在磁盘上创建一个RDB文件,然后从磁盘上加载该文件并将其发送给replicas。但如果磁盘较慢,可能会影响master的操作,从redis 2.8.18 开始,可以通过设置
repl-diskless-sync yes来启用diskless replication功能,此时master会通过网络直接将RDB发送给replicas,而无需在磁盘上创建RDB文件。
数据同步分类
master和slave之间的数据复制可以分为三类:
- 完整同步:当一个新的slave连接到master时,由于缺少replication offset以及ID,会执行完整同步。
- 部分同步:用于slave重连情况下,如果slave使用PSYNC提供的offset在backlog范围内,则会执行部分同步,否则执行完整同步。
- 实时同步(Propagation):master会给已连接(connected)状态的slaves实时同步数据。
redis的replication中有两个容易混淆的buffer概念:client output buffer(client-output-buffer-limit)和backlog(repl-backlog-size,也被称为"Global Replication Buffer")。当master接收到命令之后,会将该命令同时放到backlog以及client output buffer中,client output buffer用于保存需要发送给slaves的实时流数据,每个slave都有一个client output buffer, 而backlog是所有slaves共享的,用于实现slaves的部分同步。
对比如下:
| Feature | Backlog(Global Replication Buffer) | Client Output Buffer |
|---|---|---|
| Scope | Shared across all replicas | Per-client (individual clients) |
| Purpose | Temporary storage for replication data | Temporary storage for client responses |
| Usage | Syncing replicas | Sending data to clients |
| Memory Impact | Fixed-size (global configuration) | Scales with the number of clients |
| When to Adjust | High write workloads, frequent replica disconnects | Slow clients or high Pub/Sub usage |
slave的数据同步和偏移量管理
在master和slave上执行info replication命令会展示如下信息,master_repl_offset表示master的数据偏移量,slave0中的offset表示master的首个slave的数据偏移量:
role:master
slave0:ip=172.22.0.2,port=6379,state=online,offset=135017556,lag=1
...
master_repl_offset:135017556
在slave侧执行info replication命令,会展示如下信息,slave_repl_offset表示该slave从master同步的数据偏移量,而master_repl_offset并不表示其master的偏移量,而是slave此刻的数据偏移量,用于slave级联模式下,表示它作为(级联的slaves的)master的数据偏移量,因此这两个值是相等的。
# Replication
role:slave
...
slave_repl_offset:94215857
master_repl_offset:94215857
...
那么slave是如何同步数据的?下面以redis 7.4代码为例:
-
完整同步和部分同步:redis启动时会调用
replicationCron(每秒调用1次)来发现master。replicationCron中调用syncWithMaster来尝试完整同步或部分同步。syncWithMaster中,slave会通过slaveTryPartialResynchronization向master发送PSYNC命令,master调用masterTryPartialResynchronization尝试部分同步。 -
实时同步:
-
master侧:
propagateNow-->replicationFeedSlaves-->feedReplicationBuffer将实时数据写入(propagate) client output buffer。然后通过IOThreadMain-->writeToClient-->_writeToClient将数据通过网络传输给slaves。 -
slave侧:通过
IOThreadMain-->readQueryFromClient-->processInputBuffer-->processCommandAndResetClient-->processCommand处理接收到的数据,并通过processCommandAndResetClient-->commandProcessed-->replicationFeedStreamFromMasterStream-->feedReplicationBuffer处理命令执行之后的任务,feedReplicationBuffer中会更新master_repl_offset。replicationFeedStreamFromMasterStream用于slave级联模式。
-
slave侧的slave_repl_offset是在commandProcessed过程中更新的。
replication ID
从上面可以知道,如果两个实例具有相同的replication ID和offset,则说明二者具有相同的数据。但实际上一个实例有两个replication ID:main ID和secondary ID,对应当前master ID和上一个master的ID。
一个replication ID表示一个特定的dataset。当一个实例初始化为master或当一个replica被提升为master时会生成一个新的replication ID。连接到一个master的replicas会在握手之后继承master的replication ID。因此相同ID的实例持有相同的数据(可能时间点不同)。
redis 实例有两个replication ID的原因是,在发生故障转移时,一个replica会被提升为master,此时它仍然持有之前master的replication ID(secondary ID)和offset,并将其设置为main ID,这样在其他replicas和新的master进行同步时,仍然可以使用老master的replication ID来尝试部分(重)同步。之后新的master才会生成一个新的main ID,并使用 main ID 和 secondary ID来同时处理replicas的连接,在所有replicas接收到所有老master的数据(offset)之后,会自动切换到新的master id。redis通过这种方式来降低在发生故障转移时执行完整同步的概率。
新的master需要切换replication ID的原因是,在出现网络隔离的情况下,老的master可能仍然在工作,如果使用相同的replication ID,则会违背相同ID和相同offset表示相同dataset的事实。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=10.157.4.110,port=6379,state=online,offset=552352655438,lag=0
master_replid:f50c0dadc1005893c39bd8f3a482aa992df82786 # 本节点(master)的id,mainID
master_replid2:ddcc55eeeca1a1e2e26f858524413bea798b4190 # 上一次同步的master的ID,secondary ID
master_repl_offset:552352659332 # 本节点(master)的数据偏移量
second_repl_offset:329184800015 # 上一次同步的master的偏移量
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:552351610757
repl_backlog_histlen:1048576
上述master对应的replica的replication信息如下:
# Replication
role:slave
master_host:10.157.4.40
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:552357245144
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:f50c0dadc1005893c39bd8f3a482aa992df82786 #当前master的ID
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:552357245144 # 本节点复制到数据偏移量
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:552356196569
repl_backlog_histlen:1048576
重启和故障转移下的部分同步
- 如上面所述,在发生故障转移时,新的master仍然能和现有的replicas进行部分(重)同步。
- 对于redis升级这样的场景,可以通过
SHUTDOWN+SAVE命令来保存replica的RDB文件,方便进行部分(重)同步。需要注意的是如果replica通过AOF文件进行重启,则无法进行部分同步。因此在重启前需要切换到RDB模式,重启之后再切换回AOF。
Read-only replica
从 Redis 2.6开始,默认启用read-only replica模式,可以通过replica-read-only参数进行配置。该模式下,replica会拒绝所有写命令。但该参数同时也意味着可以让replicas支持写命令,但这样可能会导致replica和master数据不一致,因此不建议使用writable replicas。
另外注意,从redis 4.0开始,replica写入的命令只是本地的,不会传递到子replicas中,子replicas会接收与master的直连的replica相同的replication流。例如下面场景,当B写入命令后,C不会看到B写入的命令,其dataset和master A相同。
A ---> B ---> C
replication的可靠性
redis通过如下两个参数来提高replication的可靠性,即当连接的replicas不少于min-replicas-to-write个,且lag小于min-replicas-max-lag秒时,redis master才会接受写请求。默认情况下min-replicas-to-write为0(即禁用该选项),min-replicas-max-lag为10。
min-replicas-to-write 3
min-replicas-max-lag 10
由于replication过程是异步的,因此上述功能只能尽量减小发生数据丢失的时间窗口。
replication expire keys
redis使用如下方式来处理replication中过期的keys:
- replicas不会expire keys,它们等待master来expire keys,即当master expire一个key后,它会向所有的replicas同步一个
DEL命令。 - 有时replicas的内存中会存在逻辑上已过期的keys,但由于master无法及时提供DEL命令,此时replica会使用其逻辑时钟来向读操作上报该key已经过期。
- lua脚本执行过程中不会执行expire keys操作。
- 在一个replica提升为master之后,它会独立expire keys,不会再依赖老的master。
replicas的Maxmemory
默认情况下replicas会忽略maxmemory(replica-ignore-maxmemory yes),即依赖master的DEL命令来expire keys,因此可能导致replica使用的内存大于其设置的maxmemory。因此需要保证replica拥有足够的内存,防止OOM。
replica 和master的认证
在redis.conf中配置replica和master的认证:
masterauth <password>
Redis的配置
静态配置
有两种静态配置reids的方式:
-
一种是通过
redis.conf,生产中建议使用这种方式 -
另一种是通过命令行直接传入的方式,建议在测试环境中使用。其参数的格式与
redis.conf相同,只需要在参数前面加上--前缀./redis-server --port 6380 --replicaof 127.0.0.1 6379
动态配置
可以通过 CONFIG SET 和 CONFIG GET动态修改redis的配置,还可以通过 CONFIG REWRITE将动态配置持久化。
将redis作为一个缓存
如果需要将Redis作为一个缓存,可以使用如下方式
maxmemory 2mb
maxmemory-policy allkeys-lru
这种方式下,无需通过 EXPIRE 命令为keys设置TTL,当数据量达到2M时,会使用LRU算法驱逐keys。
maxmemory-policy有如下几种策略:
- volatile-lru:只对设置了过期时间的keys执行LRU驱逐
- allkeys-lru:使用LRU驱逐所有keys
- volatile-lfu: 只对设置了过期时间的keys执行LFU驱逐
- allkeys-lfu: 使用LFU驱逐所有keys
- volatile-random:随机驱逐一个设置了过期时间的key
- allkeys-random:随机驱逐一个key
- volatile-ttl:随机驱逐一个最接近过期时间的key(最小TTL)
- noeviction:不驱逐任何key,只在写入时抛出错误,该策略作为数据库使用(而非缓存)时的推荐策略
Redis Sentinel
Sentinel会持续监控检查master和replicas是否正常工作。如果一个master出现故障,Sentinel可以启动故障转移流程,将一个replica提升为master,然后将原master的replicas的master字段修改为新的master,并在应用连接到Sentinel时,告知其新的master地址。
启动
有如下两种启动方式,Sentinels的默认端口为26379,另外sentinel会将状态保存在配置文件中,因此需要在启动的时候指定sentinel.conf:
redis-sentinel /path/to/sentinel.conf
redis-server /path/to/sentinel.conf --sentinel
配置
Sentine的状态保存在sentinel的配置文件中(sentinel.conf中的# Generated by CONFIG REWRITE),因此可以安全地停止并重启sentine进程。
主要配置
由于sentinel本身也可能出现问题,因此为了保证系统的鲁棒性(robust),至少要部署3个sentinel实例。在启动sentinel时需要指定一个名为sentinel.conf的配置文件,典型配置如下:
port 26379 #sentinel的端口,默认26379
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5
在配置sentinel时只需指定监控的master即可,无需指定replicas和其他sentinels(自动发现)。上面配置的sentinel监控了两个redis实例组,每一组包含一个master以及不定数目的replicas。一组名为mymaster,另一组名为resque。当故障转移将一个replica提升为master或发现新的sentinel时会自动重写该配置。
配置方式如下:
sentinel monitor <master-name> <ip> <port> <quorum>
quorum指定了至少需要quorum个Sentinels的确认才能认为一个master出现故障(将master状态标记为ODOWN),如果要执行故障转移,则需要将quorum中的一个Sentinel选举为leader,并需要大部分Sentinel来授权该leader Sentinel执行故障转移。
例如有5个Sentinels,quorum设置为2:
- 如果有2个Sentinels认为一个master不可达,则其中一个Sentinel会尝试启动故障转移
- 如果有至少3个Sentinels的授权就可以执行故障转移
可选配置
可选配置的格式为:
sentinel <option_name> <master_name> <option_value>
主要用于如下目的:
down-after-milliseconds:定义一个master多长时间不可达(无法响应PINGs或返回错误)时,认为该master down。parallel-syncs:定义了在故障转移之后,同一时间可以重新配置为新master的replicas的数目,类似滚动升级。数值越小,故障转移流程越长,而数值越大,故障转移后多个replica同时从新master全量同步,可能导致新master压力过大甚至服务降级。如果replicas配置了可以使用老数据响应client的读请求,此时不应该将所有的replicas同时配置为新的master。
使用IP地址和DNS名称
从redis 6.2版本开始,sentinel可以支持主机名(sentinel resolve-hostnames yes),默认禁用。使用时需要注意,不要同时使用IP地址和主机名。
replica-announce-ip <hostname>:配置redis实例的主机名sentinel announce-ip <hostname>:配置sentinel实例的主机名
启用resolve-hostnames,可以:
- 支持在
sentinel monitor命令中使用主机名 - 对于replica,可以在
replica-announce-ip中使用主机名
当client使用TLS连接实例时,使用主机名可以方便匹配证书中的ASN。
该功能可能会与sentinel client不兼容。
认证
ACL认证
从redis 6开始,需要通过ACL来管理用户认证和权限。在配置了ACL之后,为了让Sentinel在连接redis,可以通过如下买了添加一个sentinel使用的用户名和密码:
sentinel auth-user <master-name> <username> #sentinel连接redis所用的用户名,默认用户为 default
sentinel auth-pass <master-name> <password> #sentinel连接redis所用的密码
在指定sentinel访问redis使用的用户名密码之后,还需要在所有redis实例上为Sentinel配置权限,下例中sentinel-user对应上面的<username>,somepassword对于上面的<password>:
127.0.0.1:6379> ACL SETUSER sentinel-user ON >somepassword allchannels +multi +slaveof +ping +exec +subscribe +config|rewrite +role +publish +info +client|setname +client|kill +script|kill
ℹ️使用ACL LIST看到的ACL用户的密码是加密后的密码
sentinel ACL认证例子
首先禁止未授权的访问。禁用默认用户(或创建一个强密码)并创建一个新的,可以访问Pub/Sub channel的用户:
127.0.0.1:5000> ACL SETUSER admin ON >admin-password allchannels +@all
OK
127.0.0.1:5000> ACL SETUSER default off
OK
Sentinel会使用默认用户连接其他实例,使如下方式新建一个超级用户:
sentinel sentinel-user <username>
sentinel sentinel-pass <password>
最后使用ACL为创建的sentinel-user用户配置权限:
127.0.0.1:5000> ACL SETUSER sentinel-user ON >user-password -@all +auth +client|getname +client|id +client|setname +command +hello +ping +role +sentinel|get-master-addr-by-name +sentinel|master +sentinel|myid +sentinel|replicas +sentinel|sentinels +sentinel|masters
Redis只配置密码认证
- 在master配置
requirepass - replica配置master认证所需的密码
masterauth
Sentinel配置连接redis实例的密码即可:
sentinel auth-pass <master-name> <password>
Sentinel只配置密码认证
在所有Sentinel的配置中添加如下参数即可启用仅密码认证:
requirepass "your_password_here"
运行时重配置sentinel
下面命令需要在sentinel实例上执行,需要注意的是,单个sentinel的配置变更并不会传递到其他sentines上,因此在使用如下命令进行配置变更时,需要在所有sentinel上执行一遍。
-
SENTINEL MONITOR
<name><ip><port><quorum>:与sentinel.conf配置文件中的sentinel monitor命令类似。 -
SENTINEL REMOVE
<name>:移除指定的master。 -
SENTINEL SET
<name>[<option><value>...]:类似redis的CONFIG SET命令,可以修改特定master的配置,如SENTINEL SET objects-cache-master down-after-milliseconds 1000它还可以直接修改
quorum配置:SENTINEL SET objects-cache-master quorum 5
增删节点
增删sentinels
添加sentinel比较简单,由于sentinel的自动发现机制,只需要启动新的sentinel并监控当前活动的master即可,10s之内,sentinel会获取到其他sentinels和监控的master的replicas列表。
如果需要添加多个sentinel,建议一个一个添加,可以通过SENTINEL MASTER mastername(num-other-sentinels)或sentinel sentinels mastername校验添加的sentinels是否就绪。
移除一个sentinel相对比较复杂:sentinel不会忘记已经发现的sentinels。可以通过如下步骤移除一个sentinel:
- 停止需要移除的sentinel进程
- 向所有其他sentinel 实例发送
SENTINEL RESET *(如果只需要reset一个master,也可以将*替换为特定的master)。等待30s来移除下一个 - 通过
SENTINEL MASTER mastername来检查当前活动的sentinels。
移除replicas
如果要移除一个replica,可以停止该replica,并向所有的sentinels发送SENTINEL RESET mastername命令,这样sentinels就会在下一个10内刷新replicas列表。
Sentinels和replicas的自动发现
sentinels会通过Redis实例的 Pub/Sub功能来发现监控相同master和replicas的其他sentinels,并相互检查可用性以及交互消息等。该channel名为 __sentinel__:hello。
自动发现功能如下:
- 每个sentinel会定期(每2s)向Pub/Sub channel
__sentinel__发布监控到的每个master和replica消息,包括ip、port和runid - 每个sentinel会订阅Pub/Sub channel
__sentinel__中的每个master和replica,查找与之相关的未知的sentinels。当检测到新的sentinels时,将其添加为该master的sentinels。 - Hello消息包含完整的Master配置。如果sentinel接收到的配置版本号高于已有的配置版本,则立即更新配置。
- 在为一个master添加sentinel之前,需要检查是否已经有相同runid或地址(IP和port对)的sentinel,如果存在,则移除匹配的sentinel,并添加新的sentinel。
SDOWN 和 ODOWN故障状态
Redis Sentinel有两个down概念:
-
一种是Subjectively Down condition (SDOWN),表示一个特定sentinel Instance报告的down状态。当一个master在
down-after-milliseconds内无法响应PING请求时就会产生该状态。有效的响应如下:- PING响应 +PONG.
- PING响应 -LOADING 错误.
- PING响应 -MASTERDOWN 错误.
SDOWN并不足以触发故障转移,若要触发,需要达到ODOWN状态。
-
另一种是Objectively Down condition (ODOWN)。如果在给定时间内,足够多的(不少于
quorum)sentinels报告master不可用(能够通过SENTINEL is-master-down-by-addr接收到其他sentinels的反馈),就会将SDOWN提升为ODOWN。ODOWN状态只适用于master,对于不需要sentinel参与的实例(如replica和其他sentinels),只有SDOWN状态。
Sentinel 日志
sentinel节点会将sentinel交互的事件记录到日志文件中,日志格式为:
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>
下面展示了当停止redis1(master)时,发生故障转移情况下的sentinel日志:
redis1(master)+sentinel1:10.150.208.71redis(slave)2+sentinel2:10.150.208.73Sentinel3:10.150.208.72
下面是授权执行故障转移的sentinel节点的主要事件,其中+表示某种状态被加入,-表示某种状态被移除:
# +sdown master redis-dmp 10.150.208.71 6380 // 本sentinel发现master节点redis1 down
# +odown master redis-dmp 10.150.208.71 6380 #quorum 2/2 // 大部分sentinel发现redis1 down(此处有2个sentinel),触发odown事件
# +new-epoch 20 // 故障转移,更新epoch
# +try-failover master redis-dmp 10.150.208.71 6380 // 尝试故障转移master redis1,等待投票
# +vote-for-leader 9222ece91d05d4c75630fd38b23cb775be91dc4f 20 // 本机投票给执行故障转移的sentinel节点
# 8fb1ca9169ce3541b2f1519a8045c3cd583c607a voted for 9222ece91d05d4c75630fd38b23cb775be91dc4f 20 // 其他节点的投票+1
# 828f926c15d59cdd1ca39bb50fcb51429ebc3ec2 voted for 9222ece91d05d4c75630fd38b23cb775be91dc4f 20 // 其他节点的投票+1
# +elected-leader master redis-dmp 10.150.208.71 6380 // 选择需要故障转移的master redis1
# +failover-state-select-slave master redis-dmp 10.150.208.71 6380 // 尝试从master redis1的slave中选择可以提升为master的slave
# +selected-slave slave 10.150.208.73:6380 10.150.208.73 6380 @ redis-dmp 10.150.208.71 6380 //选择提升为master的节点redis2
* +failover-state-send-slaveof-noone slave 10.150.208.73:6380 10.150.208.73 6380 @ redis-dmp 10.150.208.71 6380 //向被提升的slave redis2发送NO ONE消息
* +failover-state-wait-promotion slave 10.150.208.73:6380 10.150.208.73 6380 @ redis-dmp 10.150.208.71 6380 //等待slave提升为master
# +promoted-slave slave 10.150.208.73:6380 10.150.208.73 6380 @ redis-dmp 10.150.208.71 6380 //slave redis2已经提升为master
# +failover-state-reconf-slaves master redis-dmp 10.150.208.71 6380 //故障转移状态转变为reconf-slaves
# +failover-end master redis-dmp 10.150.208.71 6380 //完成master redis1的故障转移
# +switch-master redis-dmp 10.150.208.71 6380 10.150.208.73 6380 //将master redis切换为被提升的slave redis2
* +slave slave 10.150.208.71:6380 10.150.208.71 6380 @ redis-dmp 10.150.208.73 6380 //将原master redis1切换为新master的slave
# +sdown slave 10.150.208.71:6380 10.150.208.71 6380 @ redis-dmp 10.150.208.73 6380 //由于原master down,因此也会报告该节点down事件
下面是非执行故障转移的节点的事件:
# +new-epoch 20 //更新epoch
# +config-update-from sentinel 9222ece91d05d4c75630fd38b23cb775be91dc4f 10.150.208.72 26380 @ estplatformexts-redis-dmp 10.150.208.71 6380 //从执行故障转移的sentine3节点接收更新的配置
# +switch-master estplatformexts-redis-dmp 10.150.208.71 6380 10.150.208.73 6380
* +convert-to-slave slave 10.150.208.71:6380 10.150.208.71 6380 @ estplatformexts-redis-dmp 10.150.208.73 6380 //将原master转换为slave
Replica的选择和优先级
在故障转移过程中,会根据如下信息选择作为新master的replica:
- 和master的断链时间
- replica优先级
- 处理的replication offset
- Run ID
如果一个replica和master的断链时间超过配置的master超时时间的10倍加sentinel认为master不可用的时间之和,则认为该replica不适合进行故障转移。
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
按照如下顺序从剩下的replicas中进行选择:
- 按照
redis.conf中配置的replica-priority进行排序,越小越好 - 如果优先级相同,则检查replica处理的replication offset,并选择从master接收最多数据的replica
- 如果多个replica具有相同的优先级和replication offset,则按照字典顺序选择一个小的run ID
大多数情况下,无需设置replica-priority。如果replica-priority为0,则表示该replica永远不会被sentinel选择为master。
配置的epochs和传递
当一个sentinel被授权执行故障转移时,它会获得一个与master有关的唯一的configuration epoch ,该值用于在故障转移结束之后标记一个新版本的配置。
在故障转移中有一个规则:如果一个Sentinel授权另一个sentinel执行一个master的故障转移,则该Sentinel会等待一定时间来再次执行相同master的故障转移,该时间为sentinel.conf中定义的failover-timeout的2倍(2 * failover-timeout),这意味着sentinels不会同时对相同的maser进行故障转移,如果第一个被授权的sentinel故障转移失败,则一段时间之后另一个Sentinel会再次尝试故障转移,以此类推。
一旦一个sentinel成功完成一个master的故障转移,它会广播新配置,这样在其他sentinels接收到之后就可以更新与此master相关的配置。
故障转移成功要求Sentine向选择的replica发送
REPLICAOF NO ONE命令,并且在master的INFO输出中看到切换好的master。
每个sentinel都会使用redis的Pub/Sub( __sentinel__:hello Pub/Sub channel)持续广播其版本的master配置,同时所有sentinels都会等待查看其他sentinels宣告的配置。由于不同的配置有不同的版本号(configuration epoch),优先选择较高版本的配置,这样所有的sentinel最终都会使用较高版本的配置。
TILT模式
TILT是一种防护模式。工作原理为:sentinel每秒会调用10次时钟中断,因此两个时钟中断调用之间的时间差应该在100ns左右。sentinel会注册上一个调用时钟中断的时间,并与当前调用作对比,如果时间差为负数或相对较大(如2s或更大)时,就会进入TILT模式。
在TILT模式下,sentinel仍然会继续监控,但完全不起作用,且会对SENTINEL is-master-down-by-addr响应负数。
如果恢复正常状态30s,则会退出TILT模式。
当进入TILT模式后,可以通过sentinel_tilt_since_seconds查看进入TILT模式的时间,如果非TILT模式,则显示-1。
$ redis-cli -p 26379
127.0.0.1:26379> info
(Other information from Sentinel server skipped.)
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=0,sentinels=1
Redis Cluster
通过Redis Cluster可以跨多节点实现数据自动分片和水平扩容。通过Redis Cluster可以实现:
- 在多个节点上切分数据集
- 当一部分节点出现故障或无法通信时仍能够继续操作剩余的集群
在使用Redis Cluster时要注意以下几点:
-
Redis Cluster不像独立的Redis一样支持多DB,它只支持DB 0。
127.0.0.1:6379> info keyspace # Keyspace db0:keys=33880932,expires=24332094,avg_ttl=0 -
Cluster节点并不能将命令转发到正确的节点,因此需要clients在接收到重定向错误(MODE和ASK)之后重定向到正确的节点,因此要求clients能够连接到所有节点。
-
最大节点数推荐1000
-
当需要在一条命令中处理多个keys时,可以通过Hash-tags确保操作的所有keys都位于同一个哈希槽中
配置
Redis Cluster要求最少需要3个master节点,推荐6个节点:3个masters和3个replicas。
启动
使用如下方式启动一个Cluster节点,后续可以添加节点
redis-server ./redis.conf
cluster-config-file:该参数指定了集群配置文件的位置。每个节点在运行过程中,会维护一份集群配置文件;每当集群信息发生变化时(如增减节点),集群内所有节点会将最新信息更新到该配置文件;当节点重启后,会重新读取该配置文件,获取集群信息,可以方便的重新加入到集群中。也就是说,当Redis节点以集群模式启动时,会首先寻找是否有集群配置文件,如果有则使用文件中的配置启动,如果没有,则初始化配置并将配置保存到文件中。集群配置文件由Redis节点维护,不需要人工修改。
编辑好
cluster-config-file文件后,使用redis-server命令启动该节点:redis-server <cluster-config-file>
启动端口
每个Redis Cluster节点需要打开两个TCP连接:一个与clients连接的TCP端口(如6379);以及一个名为cluster bus port的端口,默认的cluster bus port为数据端口加10000(如16379),当然也可以通过redis.conf中的cluster-port覆盖默认配置。
cluster bus是一个节点之间的通信渠道,用于在节点之间交换信息,如节点发现、故障探测、配置更新、故障转移授权等等。为了让一个Redis Cluster正常工作,需要:
- 向所有clients和其他需要使用client port进行key迁移的集群开放client通信端口(通常是6379)
- 向其他节点开放cluster bus port
配置文件参数
Redis Cluster的配置文件名为redis.conf,主要配置项如下:
- cluster-enabled
<yes/no>:是否启用Redis Cluster,如果否,则作为一个独立的redis实例 - cluster-config-file
<filename>:可选,Redis Cluster在集群变更时自动持久化集群配置(状态),用户不可修改。 - cluster-node-timeout
<milliseconds>:如果一个master节点在这段时间内无法连接到大部分master,则说明该节点不可用,该节点将会停止接收请求。该参数用于让master停止接收client请求。 - cluster-slave-validity-factor
<factor>:如果为0,则replica会一直尝试通过故障转移为一个master,而不会考虑master和replica之间的断链时间。如果为正数,且节点为replica,则当它和master节点的断链时间超过cluster-node-timeout *factor时会尝试故障转移为master。注意如果一个master没有replica,且该参数非0,则当一个master故障时会导致Redis Cluster不可用(直到master重新加入集群)。该参数用于启动故障转移。 - cluster-migration-barrier
<count>:定义一个master最少需要连接多少个replicas,这样多余的replica就可以迁移为一个没有任何Working replica的master的replica。参见[replica-migration](#Replica migration)。 - cluster-require-full-coverage
<yes/no>:默认yes,如果为yes,当集群检测到至少有1个哈希槽uncovered(没有该哈希槽对应的节点)时,Redis Cluster将停止接收请求。如果为no,则可以继续为剩余的keys接收请求。对于大多数业务场景,建议设为no,避免少量slot不可用导致整个集群停服。 - cluster-allow-reads-when-down
<yes/no>:默认no,如果为no,即当一个节点无法连接到大部分masters或出现uncovered的哈希槽时,集群将停止接收任何流量。
节点操作
-
增加节点时需要将原有slots均衡到新的节点,可以通过
redis-cli --cluster rebalance <ip:port> --cluster-use-empty-masters实现 -
删除节点时,需要将reshard需要删除的节点的slots,然后
redis-cli --cluster rebalance <ip:port>再均衡slots
参见:Hash Slot Resharding and Rebalancing for Redis Cluster
添加节点
添加master节点
如果要添加一个master,首先添加一个空的节点,然后将数据转移到该节点。
-
假设添加一个新节点127.0.0.1:7006,首先为其创建目录
-
使用
add-node添加节点,127.0.0.1:7000为一个集群已有的节点,redis-cli会通过CLUSTER MEET命令将其加入集群redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 -
使用reshard向该节点迁移数据
添加replica
添加replica的方式有如下三种:
-
当使用如下命令添加一个replica时,由于没有指定master,Redis会随机选择一个具有最少replicas的master:
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave -
使用如下方式可以为特定master添加一个replica:
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e -
还可以先启动一个空的master节点,然后通过
CLUSTER REPLICATE命令将该节点设置为某个master的replica,通常用于将已添加的节点转移到不同的master下:CLUSTER REPLICATE node-id
移除节点
-
如果要移除一个replica节点,只需要使用
del-node命令即可,127.0.0.1:7000为集群的一个已知节点,node-id为需要删除的reolica的id:redis-cli --cluster del-node 127.0.0.1:7000 `<node-id>` -
如果要移除一个master节点,则必须保证master节点为空,因此首先需要将所有数据reshard到其他节点,再执行如上命令。
-
如果要移除一个故障节点,则不能使用
del-node,因为del-node会尝试连接所有的节点,此时会返回connection refused错误,可以调用CLUSTER FORGET来移除该故障节点:redis-cli --cluster call 127.0.0.1:7000 cluster forget `<node-id>`CLUSTER FORGET命令会执行如下操作:- 从node table中移除指定ID的节点
- 在60s内禁止重新添加相同ID的节点。这是为了防止redis通过gossip再次发现需要移除的节点
重置节点
当需要将一个已有节点加入其他集群时可以通过 CLUSTER RESET 命令重置节点,它有如下两种形式:
CLUSTER RESET SOFTCLUSTER RESET HARD
有如下规则:
- soft和hard:如果节点为replica,则将其变为master,并丢弃dataset。如果node是master,且包含keys,则中断reset操作
- soft和hard:释放所有的slots,重置手动故障转移状态
- soft和hard:从node table中移除其他节点,这样该节点将无法被其他节点识别
- 仅hard:将
currentEpoch,configEpoch和lastVoteEpoch设置为0 - 仅hard:将节点ID变为一个新的随机ID
如果master包含非空数据集,则无法被重置。可以通过 FLUSHALL 命令清除数据。
升级节点
升级replica
升级replica节点比较简单,只需要停止该节点,然后使用新版本重启节点即可。如果此时有client通过replica执行读操作,则当该节点不可用时会重新连接到另一个replica。
升级master
升级master比较复杂,建议流程如下:
- 使用
CLUSTER FAILOVER手动触发故障转移,将需要升级的master变为replica(数据安全操作) - 等待master变为replica
- 然后升级该节点
- 在升级结束之后,可以再次手动触发故障转移将升级后的节点变为master
数据分片
概念
Redis Cluster没有使用一致性哈希,而是使用了一种称为哈希槽(hash slot)的分片方式。Redis Cluster 中有16384个哈希槽,通过HASH_SLOT = CRC16(key) mod 16384来计算一个key所在的槽位。
Redis Cluster中的每个节点都负责一部分哈希槽,假如有3个节点:
- 节点A的哈希槽为0~5500
- 节点B的哈希槽为5501~11000
- 节点C的哈希槽为11001~16383
当添加一个节点D时,需要将部分哈希槽从A、B、C转移到D。类似地,如果要移除节点A,则需要将哈希槽从A移到B和C,当A的哈希槽为空时,就可以删除A。注意:此处的A、B、C、D均表示master节点
将哈希槽从一个节点转移到其他节点时并不需要停止任何操作,因此,无论是添加删除节点还是变更一个节点的哈希槽百分比,都不需要停机。
Hash-tags
Redis Cluster中,不同的key可能会落到不同的哈希槽中,如果在一条命令中同时操作不同哈希槽的keys(Multi-keys operations),而这些keys对应的哈希槽又位于不同节点时,会返回重定向错误。更多参见client重定向

[Redis] Multi-key command in cluster mode (feat. CROSS-SLOT)
为此,可以通过hash tags让多个keys分配到相同的哈希槽中。其方法是,如果key包含"{...}",则只会通过大括号内的字符串的计算哈希槽。如果一个key有多个大括号,则只会通过第一个出现的括号内的字符串来计算哈希槽。
- 如key {user1000}.following和key {user1000}.followers会使用user1000计算哈希槽
- key foo{bar}{zap}使用bar进行哈希
- key foo{{bar}}使用bar进行哈希
- key foo{}{bar}由于第一个大括号内没有任何字符,因此会对整个字符串进行哈希。
执行reshard
-
执行如下命令即可启动交互式的reshard,命令中指定一个节点即可,redis-cli会自动发现其他节点:
redis-cli --cluster reshard <ip>:<cport> -
也可通过如下方式执行非交互式的reshard,
--cluster-yes表示非交互式:redis-cli --cluster reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes
在reshard结束之后,可以通过cluster nodes查看哈希槽分配情况。
master-replica模型
Redis Cluster中每个哈希槽有1(master)到N个replicas(N-1个replica节点)。假如有A、B、C三个节点,如果B出现故障,此时将无法为5501~11000的哈希槽提供服务。
但如果在创建集群时为每个master添加了一个replica节点,这样集群中将包含节点A、B、C及其replica节点A1、B1、C1,如果B出现故障,此时B1将作为新的master。但如果B和B1同时出现故障,那么Redis Cluster将无法继续操作。
数据丢失场景
Redis Cluster不保证数据的强一致性(异步复制),即在某些情况下,可能会丢失client写入的数据。Redis有两种数据丢失场景:
- 假设一个client写入master B,master B向client响应OK,然后需要将写入的数据发送给它的replicas B1、B2和B3。由于B在回复client前不会等待B1, B2, B3的应答,因此如果在B向client确认写入数据之后,且还未向replicas发送该数据之前发生了故障,此时会在节点超时之后将其中一个replica提升为master,导致数据丢失。
- 当客户端写入的master出现网络隔离时,且该master属于被隔离出的小部分masters,这样在网络恢复之后会丢失这段时间的写数据
Redis Cluster有一个重要配置cluster-node-timeout,如果一个master节点在这段时间内无法连接到大部分masters(Ping/Pong)就会进入错误状态,它将停止接收写操作,以此来限制数据丢失的窗口。
client可以通过WAIT 命令保证数据不丢失。
可用性
当出现网络隔离时,如果具有大部分masters的一侧网络中包含不可达masters的(至少)1个replica,则会在NODE_TIMEOUT加上replica切换为master的时间(1~2s)之后恢复集群。
通过Replica migration自动将多余的replica迁移到没有replica的master上,以此来提升集群的稳定性。
Replica migration
Redis Cluster中如果master及其replicas同时出现故障,将导致集群不可用。为了提高集群的可用性,最简单的方式是为集群中的每个master增加replica,但该方式也存在成本问题。
另一种方式是通过创建不对称的master和replicas来让集群自动变更布局。如果一个master没有任何Working状态的replica,Replica migration可以自动将一个replica迁移为该master的replica。
例如一个集群有3个master A、B、C,其中A和B各有1个replica,C有2个replica:C1和C2
- Master A故障,A1提升为master
- 由于A1没有任何replica,C2迁移为A1的replica
- 3小时之后A1也出现故障,C2提升为新的master,替换A1
- 集群正常运作
算法
由于migration algorithm操作的是replica,且不涉及configEpoch的变更,因此不需要集群的授权。
在检测到集群中至少存在一个没有Working replica的master时,每个replica都会执行迁移算法,但通常只有一个replica会真正执行迁移:从具有最多replicas的master中选择一个replica,且该replica处于非FAIL状态,具有最小的节点ID。
在集群不稳定时,可能会产生竞争,即同时有多个replica认为其具有最小的节点ID(实际中不大可能发生),导致多个replicas同时迁移到相同的master上。但这种情况并无害,如果竞争导致某个master没有replicas,则在集群稳定之后,会再次执行迁移算法,将replica迁移回去。
cluster-migration-barrier参数控制了一个master至少应该保留多少个replicas,剩余的replicas才能被迁移。
从replica读取数据
通常当client连接到replica节点时,replica节点会将client重定向其master,但可以通过 READONLY 命令让client从replica读取数据。
当client连接的replica的master不包含命令涉及的哈希槽时,会向client发送重定向信息。
可以通过 READWRITE 命令取消readonly模式。
集群拓扑
节点连接
Redis Cluster是一个节点互联的网格,在一个N节点的集群中,每个节点有N-1个出去的(cluster bus port)TCP连接,同时有N-1个进来的(cluster bus port)连接,这些TCP连接为长连接。节点之间通过gossip协议以及一个配置更新机制来避免交换太多信息。
节点握手
集群会通过如下两种方式接纳一个节点:
- 节点通过MEET消息(
CLUSTER MEET)消息宣告本节点。MEET消息类型PING消息,但会强制让接收的节点将其接纳为节点的一部分。MEET消息只能通过系统管理员发送:CLUSTER MEET ip port - 一个节点会接纳已信任的节点所接纳的节点。
心跳检测
Redis Cluster的节点通过Ping和Pong报文来检测心跳。通常一个node每秒会随机Ping固定数目的nodes,且每个节点也会确保Ping那些没有在NODE_TIMEOUT/2时间内发送Ping或接收到Pong的节点。
Ping和Pong报文中包含一个通用的首部:
- Node ID
- 发送节点的currentEpoch和configEpoch
- node flag,即replica、master或其他节点信息
- 发送节点负责的的哈希槽的bitmap
- 发送节点的client port
- 发送节点的Cluster port
- 发送节点视角下的集群状态,down或ok
- 发送节点的master node ID(如果发送节点为replica)
Ping和Pong报文还包含一个 gossip section,该section仅包含发送节点对其他节点的描述信息,用于故障检测和节点发现:
- Node ID.
- 节点的IP和port
- Node flags.
Cluster current epoch和configuration epoch
Cluster current epoch也被称为currentEpoch,configuration epoch也被称为 configEpoch。
currentEpoch
新创建的节点(master/replica)的currentEpoch为0。
当从另一个节点接收到报文时,如果发送的cluster bus消息首部中的epoch高于本地节点的epoch,则将currentEpoch更新为发送者的epoch。最终集群中的所有节点都会更新为最大的currentEpoch。
该值目前仅用于将replica提升为master(将下一节)的场景。
configEpoch
每个master总是会通过Ping和Pong报文来宣告其configEpoch以及负责的哈希槽bitmap,replica也会在Ping和Pong报文中宣告其configEpoch,但该值为最近一次和master交互时master的epoch值。新创建的master节点的configEpoch为0.
replica选举时会生成新的configEpoch。replica会增加故障master的epoch,并尝试获取大部分masters的授权,一旦授权该replica,就会创建一个唯一的configEpoch,之后replica会使用新的configEpoch转换为master。
configEpoch还可以用于解决多个节点宣告有分歧的配置导致的问题(网络隔离情况下)。
ConfigEpoch冲突解决算法
在故障转移中,当一个replica提升为master之后需要确保获得一个唯一的configEpoch值。但在下面两个场景中会以不安全方式创建configEpoch,即在创建时仅增加了本地节点的currentEpoch,有可能导致configEpoch冲突。这两种情况都是系统管理员触发的:
- 使用
CLUSTER FAILOVER TAKEOVER手动将一个replica节点提升为master,此时不需要大部分masters的授权同意,适用于配置多数据中心。 - 迁移slots也会在本地节点中生成一个新的configEpoch,出于性能原因,也无需其他节点的同意。
当手动将一个哈希槽从节点A reshard到节点B时,会强制B将其configEpoch更新为集群最大值,并加1(除非已经是最大的configEpoch),而无需其他节点的同意。实际中,一个reshard通常会涉及上百个哈希槽,如果为每个哈希槽都生成一个新的configEpoch会导致性能下降,为此,只需要在转移第一个哈希槽时生成一个新的configEpoch即可。
除上述两种原因外,软件bug或文件系统问题也可能会导致多个节点具有相同的configEpoch。为了解决该问题,会通过冲突解决算法来保证不同的节点具有不同的configEpoch:
- 如果一个master节点探测到和其他master节点具有相同的configEpoch
- 且相比其他具有相同configEpoch的节点,本节点ID更小
- 则将本节点的currentEpoch加1,作为configEpoch
如果存在多个相同configEpoch的节点,则除ID最大的节点外,其他节点都会通过执行上述步骤增加configEpoch,最终保证所有节点都具有唯一的configEpoch(replica的configEpoch与其master相同)。
在初始化一个集群时,可以通过redis-cli的 CLUSTER SET-CONFIG-EPOCH 命令在加入集群之前为每个节点配置不同的configEpoch。
故障处理
概念理解
Redis Cluster的故障转移涉及两个比较难以理解的点:一是故障转移过程中replica和master存在多个时间区间,另一个是currentEpoch/configEpoch/lastVoteEpoch这几个概念。
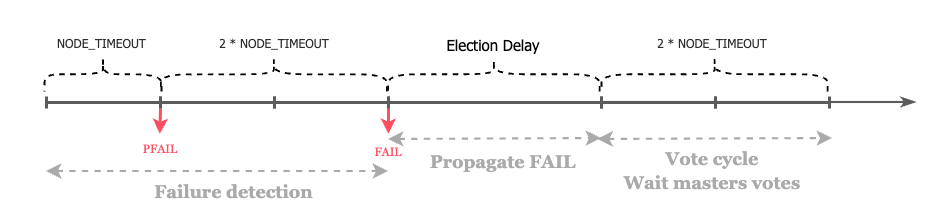
故障处理中的时间点
在故障转移中,一个Replica需要经历如下几个时间段,其中Election Delay为Election Delay = 500 milliseconds + random delay between 0 and 500 milliseconds + REPLICA_RANK * 1000 milliseconds,Voter cycle也可能存在多个(replica投票请求失败的情况下)。
对于master来说,只存在大小为NODE_TIMEOUT * 2的投票周期,在一个周期内,一个master只会给相同master下的一个replica投票。
几个Epoch的用途
lastVoteEpoch:master侧记录的上一次投票周期信息。- 用途:仅用于master校验replica投票请求的有效性。
- 如果请求中的
currentEpoch小于master记录的lastVoteEpoch,说明该请求属于老的投票周期,并没有启动新的投票周期,忽略该请求。
- 如果请求中的
- 更新时机:在master给replica成功投票之后,会将
lastVoteEpoch更新为请求中的currentEpoch。
- 用途:仅用于master校验replica投票请求的有效性。
currentEpoch:集群所有节点都应该具有相同的currentEpoch- 用途:主要用于表示当前正在进行第几个故障转移投票周期。用于防止replica错误计算master的投票次数。
- replica会在投票请求中发送
currentEpoch,如果master发现请求的currentEpoch小于该master的currentEpoch,则master会忽略该请求。 - 如果replica接收到的master的投票中的
currentEpoch小于该replica的currentEpoch,也会忽略此投票结果
- replica会在投票请求中发送
- 更新时机:
- Redis Cluster的节点会通过心跳消息传播
currentEpoch,如果一个节点的currentEpoch消息接收到的心跳消息中的currentEpoch,则更新本地的currentEpoch,最终所有节点都会更新为相同的currentEpoch - Replica 执行投票请求时会将
currentEpoch+ 1
- Redis Cluster的节点会通过心跳消息传播
- 用途:主要用于表示当前正在进行第几个故障转移投票周期。用于防止replica错误计算master的投票次数。
configEpoch:不同的master应该具有不同的值。- 用途:
- 用于表示当前master的配置周期。当多个master宣称对相同哈希槽的所有权时,可以通过
configEpoch解决分歧 - 投票过程中如果请求中的哈希槽的
configEpoch小于master本地记录的对应哈希槽的configEpoch,则忽略该请求
- 用于表示当前master的配置周期。当多个master宣称对相同哈希槽的所有权时,可以通过
- 更新时机:
- 通过心跳消息更新replica的
configEpoch - 通过UPDATE消息更新rejoin节点的
configEpoch - replica在选举成功后会生成新的
configEpoch - ConfigEpoch冲突解决算法自动解决多节点
configEpoch冲突问题 - 执行
CLUSTER FAILOVER TAKEOVER - 执行reshard哈希槽
- 通过心跳消息更新replica的
- 用途:
故障检测
当Redis Cluster检测到一个master或一个replica节点无法被大部分masters连接时,会尝试将一个replica提升为master,如果故障转移失败,则集群会抛出错误并停止接收clients的请求。
Redis Cluster有两个故障状态:PFAIL和FAIL。PFAIL表示没有在NODE_TIMEOUT时间内未接收到对端的Pong消息,认为对端可能出现故障,但还未经确认。FAIL表示在一定时间内(NODE_TIMEOUT),大部分masters都确认了该节点故障。
当一个节点(无论master还是replica)无法在NODE_TIMEOUT时间内连接时,就会被标记为PFAIL。但PFAIL只是每个节点对其他节点状态的本地描述,如果要触发故障转移,还需要将其提升到FAIL状态。
Redis Cluster中,每个节点都会通过心跳消息(gossip消息)向其他节点传递节点状态信息,这样每个节点都会接收到其他每个节点的node flag集(多份)。以此来向其他节点通知其发现的故障节点。过程如下:
- 假设A节点将B节点标记为PFAIL
- A节点会通过gossip向集群广播上述消息
- 在NODE_TIMEOUT * FAIL_REPORT_VALIDITY_MULT时间内(当前实现中 validity factor为2),大部分master将该节点标记为PFAIL或FAIL
之后,A节点会将B节点标记为FAIL,然后向所有可达的节点发送心跳消息(state为FAIL)。在其他节点接收到FAIL消息之后,会强制将B节点设置为FAIL。
PFAIL->FAIL是单向的,但在如下场景(节点恢复)中可以清除FAIL标记:
- 节点可达,作为replica。此时replica不会执行故障转移
- 节点可达,作为master,但不包含任何哈希槽。由于空的master并不会真正参与到集群中,需要配置才能加入集群。
- 节点可达,作为master,但过去很长时间(N倍的
NODE_TIMEOUT),且没有检测到任何被提升的replica。
需要注意的是,PFAIL->FAIL的转变是基于约定的,但该约定比较弱:
- 节点需要一定时间来采集其他节点的报告,这些报告来自不同节点的不同时间点,因此可能存在老的故障报告。为此需要丢弃那些不在时间窗口内的报告
- 每个检测到FAIL条件的节点都会强制其他节点应用FAIL消息,但不能保证该消息到达所有的节点。
在发生脑裂(网络隔离)的情况下可能会出现两种情况:大部分节点认为一个节点处于FAIL状态;少部分节点认为该节点处于非FAIL状态:
- 场景1:如果大部分masters都将一个节点标记为FAIL,则最终其他节点都会将该节点设置为FAIL
- 场景2:如果只有小部分master将一个节点标记为FAIL,那么将不会把replica提升为master,每个节点会按照上面的规则清除FAIL状态。
PFAIL标记的目的只是为了触发故障转移。
故障转移
可以通过CLUSTER FAILOVER命令手动执行故障转移,这种情况下由于replica会等待和master的数据一致时才进行切换,因此不会丢失数据。
replica选举
为了将一个replica提升为master,首先要经过选举,并赢得选举。如果master为FAIL状态,则该master下的所有replicas都会启动选举。但最后只有一个会赢得选举并提升为master。
当满足如下条件时会,replica会开始选举:
- 该replica的master状态为FAIL
- master包含非空的slots
- replica和master的replication断开的连接没有超过一定时间,以此确保被提升的replica的数据相对新。
为了被选中,replica首先会增加其currentEpoch计数器,然后通过广播FAILOVER_AUTH_REQUEST报文向所有masters发起请求投票。然后等待(NODE_TIMEOUT * 2,至少2s)master的响应。
一旦一个master响应了一个replica 的FAILOVER_AUTH_ACK请求,就不会在NODE_TIMEOUT * 2时间内为相同master下的replica投票,也不会响应相同master的授权请求。
replica会丢弃小于currentEpoch的AUTH_ACK应答,避免将上一次选举的投票计算入内。
如果replica获得了大部分masters的ACKs,则赢得选举;否则中断选举,并在NODE_TIMEOUT * 4之后重新尝试选举(至少4s)。
replica排名
一旦master变为FAIL状态,replica会在选举前等待一段时间,该延迟计算如下:
DELAY = 500 milliseconds + random delay between 0 and 500 milliseconds +
REPLICA_RANK * 1000 milliseconds.
replica延迟等待的原因是为了让FAIL传递到集群中,否则如果master没有感知到该FAIL状态可能会导致拒绝投票。另外由于不同排名的replica具有不同的REPLICA_RANK,因此也可以防止所有replica同时启动选举。
REPLICA_RANK会根据replica从master复制的数据量来对replica进行排名:具有最新replication offset的replica为0,第二新的为1,以此类推。这样具有最新数据的replica会被优先选举。如果一个排名较高的replica选举失败,则其他replica会在短时间内尝试选举。
一旦一个replica赢得选举,它会得到唯一且递增的configEpoch(大于其他已有master),并通过Ping和Pong宣告其master角色以及所拥有的哈希槽。如果老master重新加入集群,它会发现已经存在一个更高的configEpoch,此时会更新配置,并从新master复制消息。
master的投票流程
在master接收到replicas的FAILOVER_AUTH_REQUEST请求时,当满足如下条件时,会给replica投票:
-
在一个epoch中,一个master只会进行一次投票,且不会处理老的投票周期(epoch)。每个master都有一个
lastVoteEpoch字段,如果请求中的currentEpoch小于lastVoteEpoch,则拒绝投票。当一个master为一个请求投票之后,会更新相应的lastVoteEpoch。 -
只有当replica的master标记为FAIL,master才会给其master的replica投票
-
如果请求中的
currentEpoch小于master的currentEpoch,则忽略该请求。master只会给相同currentEpoch的replica投票。如果该replica再次发起投票请求,则会增加currentEpoch。这是为了防止replica在新的投票中接收到因为延迟导致的老的投票信息。如果没有规则3,将会出现如下情况:
- master的
currentEpoch为5,lastVoteEpoch为1(表示只出现了少数故障选举) - replica的
currentEpoch为3 - replica尝试使用epoch 4(3+1)进行选举,master返回了ok(
currentEpoch5),但该响应被延迟了 - replica没有接收到请求,再次尝试使用epoch 5(4+1)选举,此时接收到了延迟的master响应(
currentEpoch5),replica认为该响应有效。这样就错误计算了投票的master的个数。
- master的
-
在给一个master的replica投票之后,masters不会在之后的
NODE_TIMEOUT * 2时间内再次给相同master下的replica投票。由于一个epoch内不会同时选举出2个replicas,因此该值在实际中主要是为了让当选的replica有足够的时间来通知其他replicas,避免其他replica再次当选,启动不必要的故障转移流程。 -
masters不会尝试选择最佳的replica。由于master不会在同一个epoch内对已经投过票的master下的replicas再次投票,因此最佳replica更有可能最先启动选举并赢得选举。
-
如果master拒绝为一个replica投票,会直接忽略投票请求
-
如果一个replica发送的
configEpoch,小于master 哈希槽映射表中记录的任何一个与replica宣告的slots的configEpoch,则master拒绝为其投票,说明replica的配置不是最新的,后续会通过UPDATE消息更新配置。参见哈希槽配置的传递
UPDATE消息
哈希槽配置的传递
Redis Cluster的一个关键功能是如何传递节点的哈希槽信息。这对于启动一个新的集群、故障转移和节点重新加入集群等场景至关重要。
有两种传递slot配置的途径:
- 心跳消息:发送者的Ping或Pong报文中会包含其拥有的哈希槽信息
- UPDATE消息:由于心跳报文中包含了发送者的configEpoch和哈希槽,如果心跳消息接收者发现发送者的信息不是最新的,则会向它发送一个包含最新信息的报文,强制更新其信息。
在创建一个新的Redis Cluster节点时,其哈希槽为空,值为NULL,表示哈希槽没有绑定到任何节点:
0 -> NULL
1 -> NULL
2 -> NULL
...
16383 -> NULL
哈希槽的传递需要满足如下规则:
规则1:如果一个哈希槽为NULL,当一个已知节点宣告该哈希槽所有权时,本节点会修改本地的哈希槽表,将其关联到它们所在的节点。下面表示节点A负责哈希槽1和2,configEpoch为3:
0 -> NULL
1 -> A [3]
2 -> A [3]
...
16383 -> NULL
但这种映射不是固定的,在故障转移和手动reshard时都会改变哈希槽的映射关系。
规则2:如果一个哈希槽已经被分配,且一个已知节点使用大于与该哈希槽关联的master 的configEpoch的configEpoch宣告该哈希槽的所有权时,则会将该哈希槽查询绑定到新的节点。由于该规则的存在,集群中的所有节点最终会同意具有最大configEpoch的节点对哈希槽的所有权。
B为A的replica,在故障转移之后,它会通过心跳消息广播其配置信息,接收者在接收到节点B宣告的configEpoch 4和哈希槽1和2的所有权的心跳信息时,接收者会更新各自的本地哈希槽映射表:
0 -> NULL
1 -> B [4]
2 -> B [4]
...
16383 -> NULL
节点重新加入集群
当一个节点A重新加入集群之后,它会通过心跳消息,并使用老的epoch宣告其所拥有的哈希槽,消息接收者会发现与节点A相关的哈希槽已经关联了一个更高的configEpoch时,会向节点A发送包含这些哈希槽最新配置的UPDATE消息,随后A会根据上述规则2来更新其配置。
实际中可能会更加复杂,如果节点A在很长时间之后才重新加入集群,则其原来拥有的哈希槽可能已经被多个节点所有。在重新加入集群后,节点A会按照如下规则来转换角色:
master作为偷取它最后一个哈希槽的节点的replica
大部分情况下,重新加入集群的节点会作为故障转移中新master的replica。
Client连接
client重定向
Redis的client可以连接到集群的任一节点(包括replica),节点会分析请求中的keys对应的哈希槽所在的节点,并处理属于该节点的哈希槽,否则会检查其内部的哈希槽到节点的映射表,给client返回MOVED错误:
GET x
-MOVED 3999 127.0.0.1:6381
上述错误表示key(3999)对应的哈希槽所在的endpoint:port,之后client需要向该节点的endpoint:port重新发送请求。
好的Redis client应该能够记录哈希槽和节点的映射关系,可以通过 CLUSTER SHARDS或CLUSTER SLOTS获取集群布局。
MOVED重定向
ASK重定向
TODO
持久化
Redis支持如下持久化模式:
- RDB(redis database): 用于周期性地持久化一个时间点的dataset快照
- AOF(append only file):AOF会持久化所有server接收到的写操作。可以在server启动的时候通过replay这些操作来重建原始的dataset。
- No persistence:禁用持久化。
- RDB+AOF:在相同的实例上同时启用AOF和RDB
RDB
RDB是一个非常紧凑的,可以代表某个时间点的redis数据的二进制快照文件,文件名为dump.rdb(dbfilename dump.rdb),可以通过SAVE 或 BGSAVE 设置Snapshotting的生成条件。如下面表示每60s检查一次,如果至少有1000个keys发生变更,则dump dataset:
save 60 1000
推荐使用
BGSAVE非阻塞模式,SAVE执行同步命令,会阻塞Redis。
在创建RDB文件的过程中,redis首先会将dataset写入一个临时的RDB文件中,当写入结束后,移除掉旧的RDB文件(rename操作)。
可以使用如下两种方式获取dump.rdb文件的位置:
redis.conf中定义的dir参数- 通过
redis-cli -p 6379 CONFIG GET dir命令获取
优点
- 可以通过RDB实现周期性备份
- 非常适合容灾。可以将RDB文件传输到数据中心,如Amazon S3,
- RDB是在子进程中创建的,不会影响主进程的性能。
- 对于较大的dataset,RDB的重启速度要快于AOF
- RDB支持replication中的部分同步
缺点
- RDB不能保证在redis停机的情况下最小化数据丢失。
- RDB需要fork()子进程来持久化到磁盘,如果dateset比较大,fork()可能会花费较长时间,导致redis在一定毫秒甚至1秒之内无法处理clients请求。而AOF虽然也需要执行fork(),但其fork()操作并没有RDB那么频繁。
禁用RDB
config set save ""
AOF
通过如下配置启用AOF,这样在redis重启之后就可以通过AOF恢复状态:
appendonly yes
优点
- AOF有不同的fsync策略:不执行fsync(
appendfsync no,依赖操作系统刷新)、每秒执行一次fsync(appendfsync everysec)、每个请求都执行fsync(appendfsync always)。默认每秒执行一次fsync,即最多会丢失1秒的写数据 - AOF是一个只追加的log文件,即使发生断电故障也不会造成损坏问题。如果由于某些原因导致log中最后一条命令不完整,也可以通过redis-check-aof工具进行修复
- AOF会在文件变大时在后台执行rewrite。
- AOF的格式易于理解和解析
缺点
- 对于相同的dataset,AOF文件通常要大于RDB文件
- 根据具体的fsync策略(如
appendfsync always),AOF可能会比RDB慢。
Log rewriting
随着写操作的执行,AOF会变得越来越大,例如,如果对一个counter增加100次,会在dataset中得到一个最终的值,但在AOF文件中则会有100条操作记录,在恢复redis状态时,其中的99条并没有任何作用。rewrite的目的就是移除多余的操作记录,仅保留最终值。
rewrite的过程是安全的,在执行rewrite时,redis可以继续在旧的文件中追加数据。rewrite时会使用全新的文件并写入创建当前dataset所需的最小操作集,之后redis会切换到新文件,并开始在新文件中追加命令。
从Redis 7.0.0开始,当执行AOF rewrite时,主进程会打开一个新的incremental AOF文件继续执行写操作,子进程则会执行rewrite逻辑生成一个新的base AOF。redis会使用一个临时的清单文件来追踪incremental AOF和base AOF。当这两个文件就绪后,就可以通过清单文件来执行原子替换操作。在rewrite生效后,redis会删除老的base文件和无用的incremental文件。
如果rewrite失败,还可以使用老的base和increment文件(如果存在),以及新创建的increment文件来表示完整的更新后的dataset。
可以使用如下两个redis.conf参数调试rewrite的执行策略,
auto-aof-rewrite-percentage:如果当前AOF文件比上一次rewrite之后的AOF文件大百分之auto-aof-rewrite-percentage,且AOF文件不小于auto-aof-rewrite-min-size,则执行rewrite操作。auto-aof-rewrite-min-size:只有当AOF文件不小于该值时,才允许根据auto-aof-rewrite-percentage执行rewrite。这是为了防止不必要的rewrite。
AOF和RDB持久化的交互
Redis >= 2.4中,为了避免高磁盘I/O,会避免同时进行AOF rewrite和RDB snapshot操作。如果正在进行snapshoting,且此时用户通过BGREWRITEAOF命令启动了AOF rewrite,服务器会通过ok状态码来告诉用户该操作已经被调度,待snapshotting结束之后会开始rewrite。
如果同时启用了AOF和RDB,则在redis重启之后会优先使用AOF文件来重建原始的dataset(AOF具有完整的信息)。
备份和恢复
备份RDB数据
RDB文件在生成之后就不会再变,因此可以直接将RDB文件拷贝到安全的地方。
备份AOF数据
从Redis 7.0.0开始,AOF文件被切分为appenddirname(redis.conf)目录中的多个文件,可以使用copy/tar命令来创建目录备份。但如果此时正在进行rewrite,则可能会得到一个无效的备份,因此在备份时需要禁用AOF rewrite功能:
- 禁用AOF rewrite:
CONFIG SETauto-aof-rewrite-percentage 0 - 确保没有正在执行的rewrite:命令
INFOpersistence的输出中aof_rewrite_in_progress为0。 - 拷贝
appenddirname目录 - 在备份结束后,重新启用AOF rewrite:
CONFIG SETauto-aof-rewrite-percentage <prev-value>
在小于7.0.0版本的redis中,可以直接拷贝AOF文件。
Security
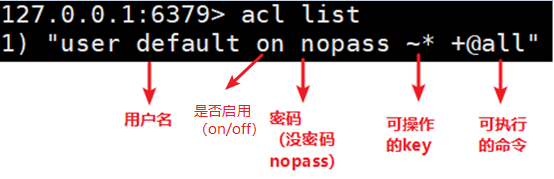
ACL
ACL有很多配置规则,参见acl-rules。创建ACL的方式有两种:使用ACL SETUSER 命令;使用ACL LOAD加载ACL文件。
下面创建了创建了一个名为alice的用户,这里没有使用SETUSER指定规则:
> ACL SETUSER alice
OK
此时alice的权限如下:
- 在关闭ACL的情况下,无法使用AUTH配置
alice - 该用户没有设置密码
- 无法访问任何命令。默认创建的用户的command权限为
-@all - 无法访问任何key
- 无法访问任何Pub/Sub channels
下面为alice配置了一个密码,且只允许使用 GET 命令获取以cached:开头的key。
> ACL SETUSER alice on >p1pp0 ~cached:* +get
OK
使用 ACL GETUSER可以查看用户的权限:
> ACL GETUSER alice
1) "flags"
2) 1) "on"
3) "passwords"
4) 1) "2d9c75..."
5) "commands"
6) "-@all +get"
7) "keys"
8) "~cached:*"
9) "channels"
10) ""
11) "selectors"
12) (empty array)
可以继续使用SETUSER为用户添加权限,SETUSER可以为用户追加新的权限:
> ACL SETUSER alice ~objects:* ~items:* ~public:*
OK
> ACL LIST
1) "user alice on #2d9c75... ~cached:* ~objects:* ~items:* ~public:* resetchannels -@all +get"
2) "user default on nopass ~* &* +@all"
Command categories
为用户一个个添加目录比较繁琐,可以通过categories直接给用户添加多个命令的权限。
使用下面命令可以查看支持的categories,以及各个categories下面包含的命令。注意一个命令可能位于多个categories中:
ACL CAT -- Will just list all the categories available
ACL CAT <category-name> -- Will list all the commands inside the category
使用categories添加ACL的方式例如下:
> ACL SETUSER antirez on +@all -@dangerous >42a979... ~*
TLS
证书配置
tls-cert-file /path/to/redis.crt
tls-key-file /path/to/redis.key
tls-ca-cert-file /path/to/ca.crt
tls-dh-params-file /path/to/redis.dh
端口配置
port 0表示禁用非TLS端口
port 0
tls-port 6379
客户端认证
可以通过tls-auth-clients no禁用客户端认证
Replication
master上需要配置tls-port 和 tls-auth-clients。
replica侧需要设置tls-replication yes来启用和master连接的TLS。
Cluster
设置tls-cluster yes来为cluster bus 启用TLS。
Sentinel
Sentinel也会通过 tls-replication来确定到master的连接是否启用TLS,该参数还用于决定接受的来自其他Sentinel的连接是否启用TLS。只有在启用tls-replication的情况下,才能启用tls-port。
Cli
General
-
info memory:
used_memory_human:表示Redis分配器分配的总内存,包含所有数据和内部开销。table_used_memory:哈希表内存。Redis 的哈希表在扩容后不会自动缩容,在sentinel模式下,如果主备内存(used_memory)差距比较大,可能是某个redis被重启之后使用了更紧凑的哈希表大小
注:8.x版本中移除了该字段,并新增了字段used_memory_overhead,可以使用MEMORY STATS命令查看具体内容。used_memory_overhead包含了两个内容:keyspace.main.hashtable.overhead:主字典表开销,等同于table_used_memory,存储所有 Key 和 Value 指针的表,如SET key value的结果。keyspace.expires.hashtable.overhead:过期字典表开销,专门存储设置了 TTL 的 Key 和其过期时间的表,如EXPIRE key 60的结果。
prime_capacity:哈希表槽位数expire_capacity:过期哈希表槽位数
-
memory stats:以数组格式展示服务的内存使用情况
-
memory doctor:内存诊断工具
-
FAILOVER:与
CLUSTER FAILOVER类似,适用于非Cluster的redis -
info commandstats:展示不同类型的命令的详细信息,包括执行的命令总数(非rejected),命令执行的总CPU时间,每条命令消耗的平均CPU时间,reject的调用总数,失败的调用总数:
cmdstat_XXX: calls=XXX,usec=XXX,usec_per_call=XXX,rejected_calls=XXX,failed_calls=XXX
配置变更
-
CONFIG GET:
CONFIG GET parameter [parameter ...]。获取redis配置(redis.conf)。可以通过CONFIG get *查看当前redis的所有配置 -
CONFIG SET:在运行时设置redis的配置,无需重启Redis
-
CONFIG REWRITE:该命令会将redis正在使用的配置持久化到
redis.conf文件中,如果使用了CONFIG SET命令,则生成的配置文件可能会与原始文件不一致。CONFIG REWRITE写入规则- 尽量保留原始 redis.conf 的注释和整体结构:不会破坏格式,注释行保持不变。
- 已存在的选项,在原位置(行号)更新:不会把配置移到文件末尾,原地覆盖。
- 未显式配置、且当前值等于默认值的选项(如被使用
CONFIG SET配置的值正好等于默认直),不写入文件 - 未显式配置、但当前值不等于默认值的选项,追加到文件末尾
- 原有但现在不再使用的行,清空(变为空行)
DB
-
CONFIG GET databases:查看redis的database数目,默认有16个DB
-
INFO keyspace:展示了各个db的主目录,格式如下。其中
keys表示该DB中的keys总数,expires表示设置了过期时间的keys总数,avg_ttl表示随机采样得到的平均ttl,单位毫秒,该值为0表示所有采样的keys都没有设置过期时间。dbXXX: keys=XXX,expires=XXX,avg_ttl=XXX,subexpiry=XXX -
FLUSHALL [ASYNC | SYNC]:删除所有DB的keys。
切换db
-
select <db_num>
交换两个DB的数据
- SWAPDB index1 index2:交换两个DB的数据,这样连接到一个特定db的clients会立马看到另一个db的数据。如
SWAPDB 0 1会交换db0和db1的数据,所有连接到db0的client会立即看到交换过来的db1数据,同样连接到db1的clients会看到原来属于db0数据。
获取一个key的剩余ttl
-
TTL <key_name>
使用scan命令
- 获取database中的一部分keys:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type],如SCAN 0 COUNT 100 MATCH NEW_MD*表示获取以NEW_MD开头的第0~100个数据。 - 获取特定类型的keys:
SCAN 0 type <type>,如scan 0 type hash。可以使用type命令查看key的类型
在使用scan时也可以不指定count,scan会返回两个值:第一个值(17)为下次调用scan的起始位置,第二个为匹配的内容。如果scan返回的第一个值为0,则表示scan结束,即完全迭代。
redis 127.0.0.1:6379> scan 0
1) "17"
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
为hash设置过期时间
HSET命令是没有直接设置过期时间的参数的,有如下两种方式设置过期时间:
-
一种是将过期时间放到hash数值中,通过程序控制的方式删除,但这种方式依赖程序的执行,可能会导致redis内存泄露
-
另一种方式如下,即在配置一个hash之后,再调用EXPIRE命令设置其TTL,推荐这种方式:
redis> HSET myhash field1 "helloworld" (integer) 0 redis> EXPIRE myhash 60 (integer) 1
replication
-
Info replication:查看replication信息。在master上查看其replicas的状态,
connected_slaves表示连接的replicas的数目。slave0:ip=10.150.208.73,port=6380,state=online,offset=455191,lag=0中注意state和lag(lag表示时间差,而非数据之差)两个字段:# Replication role:master connected_slaves:1 slave0:ip=10.150.208.73,port=6380,state=online,offset=455191,lag=0 #offset为slave的当前偏移量 master_replid:d550cc0b17bba2e43d5fe6caa57bb74ea23dc755 master_replid2:8c561bcd6cf98616cf802f646cbb5d87dba0a452 master_repl_offset:455191 #master当前的offset second_repl_offset:2792 repl_backlog_active:1 repl_backlog_size:1048576 #backlog的长度,默认1mb,即1024*1024 repl_backlog_first_byte_offset:660 #backlog中的第一个字节的offset repl_backlog_histlen:454532 #backlog中的实际数据量有如下关系:
repl_backlog_first_byte_offset=master_repl_offset-repl_backlog_histlen+ 1 -
role:显示当前实例的角色:
master、slave还是sentinel,以及replication offset。master上还可以看到其数据offset以及slave的数据offset信息。127.0.0.1:6379> role 1) "master" 2) (integer) 11483751172473 3) 1) 1) "10.157.4.26" 2) "6379" 3) "11483751172187" -
REPLICAOF:REPLICAOF <host port | NO ONE>
- 如果一个实例已经是某个master的replica,
REPLICAOF host port会停止从老的master复制数据,并丢弃老的dataset,开始从新的master复制数据。 REPLICAOF NO ONE会停止replication,并将该实例提升为master,但不会丢弃dataset。
- 如果一个实例已经是某个master的replica,
-
PSYNC:PSYNC replicationid
。在replica 节点上执行该命令,向 master 节点请求replication流。 replicationid表示master的id;offset表示replica最后接收到的偏移量。用于执行部分(重)同步- 可以通过
PSYNC ? -1执行完整(重)同步。
-
WAIT:WAIT numreplicas
。客户端使用。该命令会阻塞当前client,直到接收到至少 numreplicas个replicas的确认消息或timeout(ms)。timeout为0表示永远阻塞。WAIT命令总会在达到
numreplicas的确认数或超时之后返回已确认的replicas数目。需要注意的是WAIT并不能让redis成为一个强一致存储,仍然存在数据丢失的可能性。例如在master给replicas发送完一个写命令之后就发生了故障,但replicas由于某种原因(如网络)没能接收到这条命令,后续在某个relica提升为mater之后将会丢失掉这条消息。但WAIT在一定程度上提升了数据的安全性。
-
SHUTDOWN:SHUTDOWN [NOSAVE | SAVE] [NOW] [FORCE] [ABORT]。关闭redis服务,过程如下:
- 如果replication中存在lag
- 通过
CLIENT PAUSE暂停clients的写操作 - 等待shutdown命令超时(默认10s),便于replicas追上replication offset
- 通过
- 停止所有clients
- 如果配置了save点,则执行一次阻塞SAVE
- 如果启用AOF,则刷新AOF文件
- 退出服务
参数如下:
- SAVE:如果没有配置save点,则强制执行一次DB save操作(RDB)
- NOSAVE:即使配置了save点,也不会执行DB save操作
- NOW:无需等待延迟的replicas,即跳过shutdown的第一步
- FORCE:忽略所有阻止服务退出的错误,如无法保存RDB文件。
- ABORT:取消正在进行的shutdown操作
如果需要尽快关闭redis实例,可以使用
SHUTDOWN NOW NOSAVE FORCE命令。7.0之前,可以使用CONFIG appendonly no和SHUTDOWN NOSAVE来关闭AOF并退出Resis。Redis 7.0之后,在shutdown时,默认会等待10s来让replicas尽可能追上master的offset,以此来减小在没有配置save点和禁用AOF的情况下丢失的数据量。redis 7.0之前,在shutdown一个master节点之前可以通过
FAILOVER(或CLUSTER FAILOVER) 使用当前master降级,并将另一个replica提升为master。 - 如果replication中存在lag
persistent
-
info persistence: 查看rdb和aof信息
127.0.0.1:6379> info persistence # Persistence loading:0 rdb_changes_since_last_save:58287 rdb_bgsave_in_progress:1 #bgsave,后台正在保存dump.rdb文件 rdb_last_save_time:1723595190 rdb_last_bgsave_status:ok #上一次bgsave的执行状态 rdb_last_bgsave_time_sec:215 rdb_current_bgsave_time_sec:137 rdb_last_cow_size:56147968 aof_enabled:0 #标记是否启用AOF aof_rewrite_in_progress:0 #标记是否正在进行AOF rewrite aof_rewrite_scheduled:0 #标记是否待执行AOF rewrite,调度之后需要考虑是否正在执行RDB dump等,并不会立即执行 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok #上一次AOF rewrite的执行状态 aof_last_cow_size:0 module_fork_in_progress:0 module_fork_last_cow_size:0 -
BGREWRITEAOF :后台启动AOF rewrite流程
-
BGSAVE:后台生成rdb dump文件。
Sentinel
-
info sentinel:显示Redis Sentinel模式的信息:
sentinel_masters: 该Sentinel实例monitor的master数sentinel_tilt: 值为1时表示该Sentinel进入TILT模式sentinel_tilt_since_seconds: 当前TILT的持续时间sentinel_running_scripts: 该sentinels当前执行的scripts数目sentinel_scripts_queue_length: 等待执行的用户脚本队列的长度sentinel_simulate_failure_flags:SENTINELSIMULATE-FAILURE命令的标记
-
SENTINEL CKQUORUM
<master name>: 检测当前的sentinel配置是否能够满足执行master故障转移的条件127.0.0.1:26380> sentinel CKQUORUM my-redis OK 3 usable Sentinels. Quorum and failover authorization can be reached -
SENTINEL MASTER
:展示特定master的状态,主要注意点如下: num-other-sentinels:表示还有几个sentinel实例flags:正常情况下只显示master,如果master down,可能会显示s_down或o_down(参见[SDOWN 和 ODOWN故障状态](#SDOWN 和 ODOWN故障状态))num-slaves:表示隶属于该master的replica的数目
可以通过如下两条命令查看更多详情:
- SENTINEL REPLICAS
<master name>(>= 5.0):展示特定master的replicas的信息,通过flag可以查看当前状态 - SENTINEL SENTINELS
<master name>:展示特定master的sentinels的信息,通过flag可以查看当前状态
-
SENTINEL MASTERS:展示所有masters的状态
-
SENTINEL FAILOVER
:如果master不可达,强制执行故障转移,无需自他sentinels的同意。通常用于维护场景。 failover时会选择合适的slave并将其提升为master:
- 非
S_DOWN,O_DOWN,DISCONNECTED状态 - 距离上一次响应ping的时间不超过5倍的PING周期
master_link_down_time时间不超过(now - master->s_down_since_time) + (master->down_after_period * 10)- slave的优先级不为0
并按照如下顺序选择slave:
* - lower slave_priority. * - bigger processed replication offset. * - lexicographically smaller runid. - 非
-
SENTINEL RESET
<pattern>:用于重置匹配名称的masters。重置过程会清除一个master之前的所有状态(包括正在进行的故障转移),并移除与该master有关的replica和sentinel。用于移除sentinel和移除replica。
ACL
- ACL LIST
- ACL GETUSER
- ACL CAT : 查看ACL category
Cluster
cluster中的几个有用的命令
redis-cli --cluster check <ip:port> -a <password>检查Cluster状态:
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
localhost:6379 (891a4f01...) -> 33773876 keys | 5462 slots | 1 slaves.
10.157.4.111:6379 (66fb9464...) -> 33783136 keys | 5461 slots | 1 slaves.
10.157.4.41:6379 (0107b5fb...) -> 33775733 keys | 5461 slots | 1 slaves.
[OK] 101332745 keys in 3 masters.
6184.86 keys per slot on average.
>>> Performing Cluster Check (using node localhost:6379)
M: 891a4f01875f855e0a3b13ce2121128270ef4e38 localhost:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 66fb9464ff92d2373e72655da4fa54c96487f120 10.157.4.111:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 0107b5fb8b5e1325aec42404753b7884061cb496 10.157.4.41:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 825faec7fc7c6bdc0ef6b7ede81477ea58d0e1c9 10.157.4.109:6379
slots: (0 slots) slave
replicates 0107b5fb8b5e1325aec42404753b7884061cb496
S: 463d0bda350bb5b1ceddb2318aed5e06e3162ff5 10.157.4.42:6379
slots: (0 slots) slave
replicates 66fb9464ff92d2373e72655da4fa54c96487f120
S: 6f0e1ad522a0bb9021b4ee6be2acb7e04e767b45 10.157.4.110:6379
slots: (0 slots) slave
replicates 891a4f01875f855e0a3b13ce2121128270ef4e38
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
-
redis-cli --cluster reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes:重分配slots如:
redis-cli --cluster reshard 192.168.11.132:6379 --cluster-from 92385b2ea26a1a27c786cbea34a75f155f87f762 --cluster-to a987d7a94052c6e9426c96ebcd896c2003923eb4 --cluster-slots 3276 --cluster-yesreshard host:port #指定集群的任意一节点进行迁移slot,重新分slots。host不能是127.0.0.1(实际发现可能会出现问题) --cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入 --cluster-to <arg> #需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入 --cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。redis会自动计算迁移的slot --cluster-yes #指定迁移时的确认输入 --cluster-timeout <arg> #设置migrate命令的超时时间 --cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10 --cluster-replace #是否直接replace到目标节点 -
redis-cli --cluster rebalance <ip:port>:在非空的master节点上均衡slots,如果需要在空节点(如新加的节点)上均衡slots,需要使用参数--cluster-use-empty-masters。rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量 --cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重 --cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许 --cluster-timeout <arg> #设置migrate命令的超时时间 --cluster-simulate #模拟rebalance操作,不会真正执行迁移操作 --cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10 --cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作 --cluster-replace #是否直接replace到目标节点 -
redis-cli --cluster fix <ip:port>":用于修复集群,可以修复如下两种情况:--cluster-search-multiple-owners: 修复槽的重复分配问题。当集群中的槽位在迁移过程中出现被重复分片的槽时(可以通过redis-cli --cluster check检查),可以通过该参数修复此问题--cluster-fix-with-unreachable-masters: 修复不可达的主节点上的槽位。例如,集群中某个主节点出现故障了,且故障转移失败。此时可以使用该参数将该主节点上的所有槽位恢复到存活的主节点上(之前的数据会丢失,仅仅是恢复了槽位)。
其他命令
-
info cluster:显示Redis Cluster模式的信息
-
CLUSTER SET-CONFIG-EPOCH:在初始化一个集群时,可以通过该命令在加入集群之前为每个节点配置不同的configEpoch。
-
CLUSTER NODES :管理员视角,展示Redis Cluster的集群状态,格式如下:
<id> <ip:port@cport[,hostname]> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>id:节点IDip:port@cport:节点IP:client_port@cluster_porthostname:cluster-annouce-hostname设置的主机名flags:myself: 表示本节点master: master节点slave: replica节点fail?:PFAIL状态的节点,表示当前节点无法连接到的节点fail:FAIL状态的节点。多个节点无法连接时,将PFAIL状态提升到FAILhandshake: 握手阶段中不可信的节点noaddr: 位置地址的节点nofailover: 不会执行故障转移的replicanoflags: 无flag
master:如果节点为replica,且知道其master,则使用master的节点ID,否则使用"-"ping-sent:当前活动的ping的发送Unix时间,0表示没有pending的ping,单位毫秒pong-recv:上一次接收到pong的Unix时间,单位毫秒config-epoch:configuration epoch,表示该节点的currentEpochlink-state:节点到cluster bus的连接状态,connected或disconnectedslot:哈希槽号或范围,表示一个节点负责的哈希槽。
-
CLUSTER SLOTS :client视角,
CLUSTER NODES的子集。Redis 7.0.0之后废弃。每个元素的前两行表示slot的开始和结尾:127.0.0.1:6379> cluster slots 1) 1) (integer) 10923 # slots 10923-16383 2) (integer) 16383 3) 1) "10.157.4.111" 2) (integer) 6379 3) "66fb9464ff92d2373e72655da4fa54c96487f120" 4) 1) "10.157.4.42" 2) (integer) 6379 3) "463d0bda350bb5b1ceddb2318aed5e06e3162ff5" 2) 1) (integer) 0 # slots 0-5460 2) (integer) 5460 3) 1) "10.157.4.41" 2) (integer) 6379 3) "0107b5fb8b5e1325aec42404753b7884061cb496" 4) 1) "10.157.4.109" 2) (integer) 6379 3) "825faec7fc7c6bdc0ef6b7ede81477ea58d0e1c9" -
CLUSTER SHARDS:Redis 7.0.0引入。用于替代
CLUSTER SLOTS命令。一个shard表示一组具有相同哈希槽的master-replicas节点,每个shard只有一个master,以及0或多个replicas。该命令的会返回两部分内容:"slots"和"nodes"。前者表示该shard中的slot,后者表示该shard中的节点。"nodes"中的
endpoint字段表示请求特定槽时应该连接的位置。 -
CLUSTER FAILOVER:
CLUSTER FAILOVER [FORCE | TAKEOVER]。手动执行故障转移,必须在需要执行故障转移的master对应的某个replica上执行,该操作不会导致数据丢失。流程如下:- replica通知master停止处理clients请求
- master使用当前的replication offset回应此replica
- replica等待本地replication offset和master相匹配,确保数据同步
- replica启动故障转移,从大部分masters中获得一个新的configuration epoch,并广播此configuration epoch
- 老master在接收到配置更新后会取消阻塞clients,并开始响应重定向消息。
FORCE选项:此时不会与master进行握手(master可能已经不可达),直接从第4步开始进行故障转移。FORCE仍然需要大部分masters的授权来进行故障转移,并为该replica生成新的configuration epochTAKEOVER选项:有时候需要将一个replica提升为master,而无需集群的授权同意(如数据中心切换),它会单方面生成一个新的configuration epoch。如果其configuration epoch不是该master实例组中的最大值,则需要增加其configuration epoch,然后将master的所有哈希槽分配给自己,并向其他节点传递新的配置。由于TAKEOVER无法保证一个replica的配置是最新的,因此要谨慎使用。 -
CLUSTER REPLICATE:
CLUSTER REPLICATE node-id。将一个节点设置为指定master的replica。如果该节点非replica,则需要满足如下条件:- 节点没有任何哈希槽
- 节点为空,其keyspace中没有任何keys
-
CLUSTER FORGET :用于移除一个故障节点,参见移除节点
-
READONLY:支持client从replicas读取数据。可以用
READWRITE取消该模式。
诊断命令
Slow log
通过Slow log可以查看超过一定执行时间的命令。注意该执行时间不包括I/O操作,如与client交互的时间,只包含命令执行时间。
slowlog-log-slower-than:当命令执行时间超过该值时,将其记录到slow log中slowlog-max-len:指定了slow log中记录的最大数目。
查看slow log的命令如下:
- SLOWLOG GET:
SLOWLOG GET [count]。默认会展示最新的10条log,可以通过count调整显示的log数。其显示的字段如下:- 每条log的标识符(每次+1)
- 记录的执行命令的unix时间戳
- 执行命令花费的时间,单位微秒
- 命令的参数
- client的IP和地址
- 通过CLIENT SETNAME设置的client的名称
Latency monitor
Latency monitoring包含如下概念:
- 采集不同时延敏感的代码路径的延迟钩子
- 记录不同时间延迟峰值的时间序列
- 从时间序列拉取原始数据的报告引擎
- 可以根据测量来提供可读性的报告和提示的分析引擎
事件和时间序列
时延峰值是指一个事件的运行时间超过了配置的时延阈值(latency-monitor-threshold)。
监控的不同的代码路径有不同的名称,成为事件(events)。如command就是一个用于衡量可能的慢命令执行时延峰值的事件,fast-command则是监控O(1) 和 O(log N)命令的事件名称。其他命令则用于监控redis执行的特点操作,如fork事件。
每个被监控到的时间会关联一个独立的时间序列。时间序列的工作方式如下:
- 每当产生时延峰值时,就会将其记录到合适的时间序列中
- 每个时间序列包含160个元素
- 每个元素由包含一个Unix时间戳表示的时延峰值和一个使用毫秒表示的事件执行时间。
- 同一秒内如果产生了多个时延峰值,则选择最大时延。
- 记录每个元素的最大延迟时间。
支持的event如下:
command: regular commands.fast-command: O(1) and O(log N) commands.fork: the fork(2) system call.rdb-unlink-temp-file: the unlink(2) system call.aof-fsync-always: the fsync(2) system call when invoked by the appendfsync allways policy.aof-write: writing to the AOF - a catchall event for write(2) system calls.aof-write-pending-fsync: the write(2) system call when there is a pending fsync.aof-write-active-child: the write(2) system call when there are active child processes.aof-write-alone: the write(2) system call when no pending fsync and no active child process.aof-fstat: the fstat(2) system call.aof-rename: the rename(2) system call for renaming the temporary file after completing BGREWRITEAOF.aof-rewrite-diff-write: writing the differences accumulated while performing BGREWRITEAOF.active-defrag-cycle: the active defragmentation cycle.expire-cycle: the expiration cycle.eviction-cycle: the eviction cycle.eviction-del: deletes during the eviction cycle.
启用latency monitoring
使用如下命令启用latency monitoring,表示延迟阈值为100ms。默认值为0,表示关闭latency monitoring。
CONFIG SET latency-monitor-threshold 100
查看latency monitoring:
- LATENCY LATEST :从所有事件返回最新的延迟样本。报告内容如下:
- 事件名称
- 最新延迟事件发生的Unix时间戳
- 最新延迟事件的执行时间,单位毫秒
- redis实例启动以来的最大最新延迟
- LATENCY HISTORY
:返回一个特定时间的时延时间序列 - LATENCY RESET:重置一个或多个事件的时延时间序列
- LATENCY GRAPH
:使用ASCII图渲染一个事件的时延样本 - LATENCY DOCTOR:返回一个人类可读的时延分析报告
监控
redis exporter的监控数据来自redis的info命令,大部分metrics名称就是在redis原始指标的基础上加上redis_前缀。主要分为如下几类:
server: redis server的一般信息clients: Client连接信息memory: 内存占用相关的信息persistence: RDB 和 AOF 信息stats: 一般状态信息replication: Master/replica复制信息cpu: CPU占用信息commandstats: Redis 命令状态latencystats: Redis 命令延迟百分比分布统计sentinel: Redis Sentinel信息cluster: Redis Cluster 信息modules: Modules 信息keyspace: Database相关统计信息errorstats: Redis错误统计信息
下面给出各个部分重要的指标:
Server
- redis_uptime_in_seconds: Redis server 启动后的秒数
- io_threads_active:表示是否启用I/O多线程。通过配置的
io-threads参数启用该功能,默认禁用。
Sentinel && Cluster
- redis_sentinel_masters :该Sentinel实例监控的redis master的数目
- redis_cluster_enabled:是否启用redis Cluster
Client
- redis_connected_clients:连接的客户端数(不包括来自replicas的连接)
- redis_blocked_clients:pending在阻塞调用(
BLPOP,BRPOP,BRPOPLPUSH,BLMOVE,BZPOPMIN,BZPOPMAX)上的客户端数目 - redis_clients_in_timeout_table:client timeout 表中的clients数目
Mem
-
redis_memory_max_bytes:对应container设置的memory limit,如果没有设置,则为0。
-
redis_memory_used_bytes:redis使用的总内存
-
redis_memory_used_peak_bytes:redis的内存使用峰值
-
redis_memory_used_rss_bytes:redis申请的物理内存
-
redis_memory_used_startup_bytes:redis启动时消费的内存 -
redis_memory_used_overhead_bytes:redis管理其内部数据结构占用的内存 -
redis_memory_used_dataset_bytes:dataset的大小。redis_memory_used_bytes-redis_memory_used_overhead_bytes -
used_memory_dataset_perc:used_memory_dataset占净内存使用的百分比。
碎片整理
理想情况下,used_memory_rss应该稍微大于used_memory,如果rss远大于used,说明可能存在(external)内存碎片,可以通过allocator_frag_ratio和allocator_frag_byte查看评估。如果used远大于rss,说明redis进行了内存交换,可能会导致严重的延迟。当redis释放内存时,会将内存返回到allocator,而allocator可能会或不会将内存返回给系统,因此操作系统报告的内存使用和redis实际使用的内存可能存在偏差,可以通过used_memory_peak检查这一点。
-
redis_active_defrag_running:是否正在进行内存碎片整理
-
redis_mem_fragmentation_ratio:等于
redis_memory_used_rss_bytes/redis_memory_used_bytes,数值在1 ~ 1.5之间是比较健康的,超过该值,说明内存碎片比较多,需要进行内存碎片整理。包含allocator_*指标的内存 -
redis_mem_fragmentation_bytes:
redis_memory_used_rss_bytes和redis_memory_used_bytes之间的增量,如果redis_mem_fragmentation_bytes较小(几MB),则redis_mem_fragmentation_ratio大于1.5也并不是问题 -
redis_allocator_frag_ratio:等于
allocator_active/allocator_allocated。表示外部(external)内存碎片指标 -
redis_allocator_frag_bytes:等于
allocator_active-allocator_allocated -
redis_defrag_hits: 碎片整理过程中reallocations的值的数目
-
redis_defrag_misses: 碎片整理过程中未reallocations的值的数目
-
redis_defrag_key_hits: 碎片整理中处理的keys的数目
-
redis_defrag_key_misses: 碎片整理中跳过的keys的数目
CPU
- redis_cpu_sys_seconds_total: Redis server占用的System CPU,包含所有Server进程中的线程占用的user CPU总数 (主线程和后台线程)
- redis_cpu_user_seconds_total: Redis server占用的User CPU,包含所有Server进程中的线程占用的user CPU总数 (主线程和后台线程)
redis_cpu_sys_children_seconds_total: 后台进程占用的System CPUredis_cpu_user_children_seconds_total: 后台进程占用的User CPUredis_cpu_sys_main_thread_seconds_total: Redis server 主进程占用的System CPUredis_cpu_user_main_thread_seconds_total: Redis server 主进程进程占用的User CPU
Persistence
- redis_loading_dump_file:表示是否在加载一个dump文件
如果正在加载文件,则还有如下指标(仅限Cli命令行):
loading_start_time:文件加载的开始时间loading_total_bytes:加载的文件大小
rdb
- redis_rdb_bgsave_in_progress:是否正在进行RDB save操作
- redis_rdb_last_bgsave_status:上一次bgsave的状态
- redis_rdb_last_bgsave_duration_sec:上一次bgsave的持续时间
- redis_rdb_current_bgsave_duration_sec:正在进行的RDB save操作的持续时间
redis_rdb_last_cow_size_bytes:上一次RDB save操作中COW使用的内存大小redis_rdb_changes_since_last_save:自上一次dump之后的变动数目
aof
- redis_aof_enabled:是否启用AOF
- redis_aof_rewrite_in_progress:是否正在进行AOF rewrite操作
- redis_aof_last_rewrite_duration_sec:上一次AOF rewrite操作的持续时间
- redis_aof_current_rewrite_duration_sec:目前正在进行的AOF rewrite操作的持续时间
- redis_aof_last_write_status:上一次AOF rewrite的操作状态
redis_aof_last_cow_size_bytes:上一次AOF rewrite操作中COW使用的内存大小
Stats
-
redis_connections_received_total:Server接收的连接总数
-
redis_commands_processed_total:Server处理的命令总数
-
redis_net_input_bytes_total:从网络读取的字节总数
-
redis_net_output_bytes_total:发送到网络的字节总数
-
redis_rejected_connections_total:达到
maxclients限制而拒绝的连接总数 -
redis_total_reads_processed:处理的读事件总数
-
redis_total_writes_processed:处理的写事件总数
-
redis_replica_resyncs_full:full resync的replicas的数目
-
redis_replica_partial_resync_accepted:接收的部分重同步的请求数
-
redis_replica_partial_resync_denied:拒绝的部分重同步的请求数
-
redis_expired_keys_total:key expiration事件总数
-
redis_expired_stale_percentage:里面过期的keys的百分比
-
redis_evicted_keys_total:达到maxmemory而被驱逐的keys的总数
-
evicted_clients:Redis 7.0引入,由于达到maxmemory-clients配置而被驱逐的clients -
redis_keyspace_hits_total:在主目录中成功找到keys的数目
-
redis_keyspace_misses_total:无法在主目录中成功找到keys的数目
-
redis_latest_fork_usec:上一次fork操作所用的时间,微秒
-
total_forks:forks总数 -
acl_access_denied_auth:认证失败总数
replication
- redis_instance_info:展示redis实例状态,如redis版本,模式,role等。
master_failover_state:是否正在进行故障转移
replica
redis_master_sync_in_progress:表示master正在给replica同步数据master_link_status:到master的链路状态- redis_connected_slaves:连接的replica数
如果正在执行SYNC操作,则还会出现如下信息(Cli):
master_sync_total_bytes:master需要传输的数据大小,如果大小未知,可能为0master_sync_read_bytes:已经传输的数据大小master_sync_left_bytes:同步完成前未读取的数据(如果master_sync_total_bytes为0,可能为负数)
如果master和replica之前的链路断开,还会出现如下字段(cli):
master_link_down_since_seconds:链路断开的时间
性能优化
Benchmark
使用redis-benchmark校验redis的性能
性能参数
io-threads:redis大部分是单线程的,但有一个特定的操作,如UNLINK、慢I/O访问等操作可以在其他线程上执行。默认禁用多线程,建议在4 cores以上的机器上启用该功能,且建议只有真正遇到性能问题时才启用该功能,该功能可以使redis的性能提升2倍。由于redis会占用大分部CPU时间,因此建议,如果机器有4core,建议将该参数设置为2或3,如果机器有8 core,建议将该参数设置为6。io-threads-do-reads:当启用I/O threads时,只会用线程处理写操作,可以使用该参数来让线程支持读操作。
注意:通常线程读对性能的提升并不大。无法再运行时通过CONFIG SET设置该参数,且在启用SSL时,不能设置改参数,可能会导致redis崩溃。
诊断延迟问题
checklist
若遇到延迟问题,可以先尝试如下方式:
- 使用Slog Log查看慢命令
- 禁用透明大页功能:
echo never > /sys/kernel/mm/transparent_hugepage/enabled - 如果使用了虚拟机,则其本身可能存在延迟因素,使用
./redis-cli --intrinsic-latency 100测试 - 启用Latency monitor 功能
测试系统的内存延迟
当redis运行在虚拟机上时,可能因为虚拟机带来一定的延迟。下面命令中的"100"参数表示测试的时长。可以看到其内在延迟为0.115 milliseconds (或115 microseconds),比较好。
$ ./redis-cli --intrinsic-latency 100
Max latency so far: 1 microseconds.
Max latency so far: 16 microseconds.
Max latency so far: 50 microseconds.
Max latency so far: 53 microseconds.
Max latency so far: 83 microseconds.
Max latency so far: 115 microseconds.
Redis的单线程本质
Redis 使用的大部分是单线程设计,它使用单个线程来处理所有的client请求,即Redis会在一定时间内处理一个请求,然后依次处理其他请求。
上面说大部分的原因是,从Redis2.4开始可以使用多线程来在后台处理一些慢I/O操作(主要与磁盘I/O相关),但这不会改变Redis使用单线程处理所有请求的事实。
慢命令造成的延迟
由于单线程的性质,如果Redis无法及时处理一个请求,其他clients就必须等待该请求处理结束。redis可以在很短时间内处理像GET、SET、LPUSH 这样的命令,但像 SORT, LREM, SUNION 这样的命令可能会操作很多元素,导致操作时间过长。
可以通[slow log](#Slow log)监控慢命令。
重要:一个常见的导致慢命令的原因是使用了KEYS命令。
fork造成的延迟
为了在后台生成RDB文件,或在启用AOF时重写AOF文件,redis需要fork后台进程,而fork操作(主线程)会导致延迟。可以通过info命令的latest_fork_usec查看最近依次fork使用的时间。
透明大页造成的延迟
当一个Linux内核启用透明大页时,redis会在fork调用之后产生较大的延迟(为了持久化到磁盘)。大页会导致如下问题:
- 调用fork时,会创建两个共享大页的进程
- 在一个繁忙的实例中,运行一些事件循环将导致命令关联上千个页,导致COW整个进程内存
- 这会导致较大的延迟和内存使用
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swaping造成的延迟
查看redis进程的swap信息的方式如下:
- 获取redis实例PID:
redis-cli info | grep process_id - 进入进程的
/proc文件系统:$ cd /proc/<redis_pid> - 查看文件中Swap字段的值:
$ cat smaps | grep 'Swap:'。如果全部为0kB或偶尔出现4k,则表示一切正常。 - 如果Swap字段值大于4k,则需要对比实际大小和交换的大小:
$ cat smaps | egrep '^(Swap|Size)',如果实际值远大于交换大值,则也没问题。
AOF和磁盘I/O导致的延迟
AOF使用两个系统调用来完成其工作:一个是write(2),应用将数据写入AOF文件,另一个是fdatasync(2),用于将内核文件缓冲刷新到磁盘。
如果系统正在进行sync或在输出缓冲满,且内核需要刷入磁盘来接收新的写入时会导致write(2)阻塞。
fdatasync(2)带来的延迟更加严重,很多内核和文件系统在调用该方法时,可能会花费数毫秒到几秒的时间(特别是当其他进程正在进程I/O操作时)。为此,从Redis 2.4开始,会在不同线程中调用 fdatasync(2) 。
AOF的appendfsync配置选项对性能的影响如下:
- 当设置为always,则会在每次write操作之后(向client响应ok之前)执行一次fsync,该模式性能很低,通常建议使用高速磁盘。
- 如果设置为everysec,redis每秒会执行一次fsync。redis会使用不同的线程来执行fsync,如果正在执行fsync,则redis会通过缓冲来推迟执行write(2)(最大2s)。但如果fysnc执行时间过长,会导致在fysnc的同时执行write(2),造成延迟
- 当设置为no时,redis不会执行fsync操作,只有write(2)会带来延迟。此模式不常用。
可以使用如下方式查看redis中fsync和wirte的延迟。
sudo strace -p $(pidof redis-server) -T -e trace=fdatasync,write -f
由于write(2)包含很多与磁盘I/O无关的数据(如向client sockets写入的数据),可以使用如下命令仅展示慢的系统调用:
sudo strace -f -p $(pidof redis-server) -T -e trace=fdatasync,write 2>&1 | grep -v '0.0' | grep -v unfinished
Redis的内存
-
从Redis 2.2 开始,为了优化内存空间,redis将很多数据类型的最大数目设置为固定值。如果数据超过定义的上限,则redis会将其转换为普通编码。如:
#Redis <= 6.2 hash-max-ziplist-entries 512 hash-max-ziplist-value 64 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 set-max-intset-entries 512 -
在移除掉一些keys时,Redis并不总是会将这部分内存释放到OS。在为redis配置内存时,应该根据峰值内存,而不是平均内存。
-
如果不设置
maxmemory,则redis会持续申请其看到的内存,直至内存全部分redis占用。因此建议配置maxmemory。建议将maxmemory设置为系统内存的80%
Tips
redis启动失败
如果redis启动失败,且没有有用的日志,可以直接执行redis启动命令,查看执行结果:
$ /usr/bin/redis-server /etc/redis/sentinel.conf --daemonize no --supervised systemd
*** FATAL CONFIG FILE ERROR (Redis 6.0.10) ***
Reading the configuration file, at line 8
>>> 'sentinel myid 922e4ec063ea8d860811f575f08e5ac696073f52'
sentinel directive while not in sentinel mode
Redis down
如果遇到redis down的情况,可以在sentinel.log中查看主从切换的日志,如果主从切换成功,说明集群已经正常。否则可能会出现如下错误日志,即某个节点一直无法up:
# -sdown slave 10.157.4.31:6380 10.157.4.31 6380 @ redis-platform 10.157.4.29 6380
# +sdown slave 10.157.4.31:6380 10.157.4.31 6380 @ redis-platform 10.157.4.29 6380
# -sdown slave 10.157.4.31:6380 10.157.4.31 6380 @ redis-platform 10.157.4.29 6380
# +sdown slave 10.157.4.31:6380 10.157.4.31 6380 @ redis-platform 10.157.4.29 6380
# -sdown slave 10.157.4.31:6380 10.157.4.31 6380 @ redis-platform 10.157.4.29 6380
# +sdown slave 10.157.4.31:6380 10.157.4.31 6380 @ redis-platform 10.157.4.29 6380
此时可以在出问题的redis节点上查看info replication信息,以下面为例,master_sync_in_progress为1,说明正在进行主从同步,同时要注意到master_link_status为down并非当前master的状态,而slave_repl_offset为1说明正在进行全量同步:
# Replication
role:slave
master_host:10.157.4.29
master_port:6380
master_link_status:down #master节点状态为down
master_last_io_seconds_ago:-1
master_sync_in_progress:1 #正在进行同步
slave_repl_offset:1 #slave的offset为1
master_sync_left_bytes:-570920554
master_sync_last_io_seconds_ago:0
master_link_down_since_seconds:1730183730
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:2c508782f6926583cdaa105afb8043f0767c546b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:9196469713
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:9195421138
repl_backlog_histlen:1048576
redis 起不来的原因有可能是因为启用了RDB或AOF,而磁盘不足,在server.log中会有如下日志:
# Write error saving DB on disk: No space left on device
Redis升级
为支持部分重同步,参见重启和故障转移下的部分同步
Redis的replication周期
redis的源码中有如下描述,如果redis正在进行故障转移,则每100ms调用一次replication,非故障转移时,则每1s执行一次replication。replicationCron可以重新连接master、探测传输故障、启动后台来回RDB传输等。master和slave之间的同步就发生在replicationCron的周期中:
/* Replication cron function -- used to reconnect to master,
* detect transfer failures, start background RDB transfers and so forth.
*
* If Redis is trying to failover then run the replication cron faster so
* progress on the handshake happens more quickly. */
if (server.failover_state != NO_FAILOVER) {
run_with_period(100) replicationCron();
} else {
run_with_period(1000) replicationCron();
}
调用链: main --> initServer --> serverCron --> replicationCron
如何判断master/slave同步是否稳定
建议阅读slave的master的offset同步理解master和slave侧的master_repl_offset的区别。
由于master和slave之间是流数据传输方式,因此很难通过offset判断二者的数据偏差。master_link_status:up 表示slave已经完成了完整同步,且处于连接状态,粗略情况下,可以使用master_link_status:up作为主备同步的参考状态。
Dragonfly源码中给出了判断master和slave同步稳定的代码:
- 若
master_sync_in_progress存在,则为0 - 若
master_link_status存在,则为up - 若
master_last_io_seconds_ago存在,则为非-1 info persistence- 若
loading存在,则为空或0 - 若
load_state存在,则为空或done
- 若
func (dfi *DragonflyInstance) isReplicaStable(ctx context.Context, pod *corev1.Pod) (bool, error) {
redisClient := dfi.getRedisClient(pod.Status.PodIP)
_, err := redisClient.Ping(ctx).Result()
if err != nil {
return false, err
}
info, err := redisClient.Info(ctx, "replication").Result()
if err != nil {
return false, err
}
if info == "" {
return false, fmt.Errorf("empty info")
}
replicationData := parseInfoToMap(info)
if val, ok := replicationData["master_sync_in_progress"]; ok && val == "1" {
return false, nil
}
if val, ok := replicationData["master_link_status"]; ok && val != "up" {
return false, nil
}
if val, ok := replicationData["master_last_io_seconds_ago"]; ok && val == "-1" {
return false, nil
}
persistenceInfo, err := redisClient.Info(ctx, "persistence").Result()
if err != nil {
return false, err
}
persistenceData := parseInfoToMap(persistenceInfo)
if val, ok := persistenceData["loading"]; ok && val != "0" && val != "" {
return false, nil
}
if val, ok := persistenceData["load_state"]; ok && val != "" && val != "done" {
return false, nil
}
return true, nil
}
手动执行故障转移
非sentinel非cluster模式
-
首先断开replicas和master的连接:
redis-cli -h <replica_host> -p <replica_port> replicaof no one -
校验该replica是否被提升为master。使用
info replication命令查看:redis-cli -h <new_master_host> -p <new_master_port> info replication -
在每个replica上执行
replicaof <new_master_host> <new_master_port>命令,使其连接到新的master上:redis-cli -h <slave_host> -p <slave_port> replicaof <new_master_host> <new_master_port>
Sentinel模式
可以通过SENTINEL FAILOVER <master name>,实现故障转移,其执行的就是"非sentinel非cluster模式"的步骤,只不过是由sentinel代理执行的。
CLuster模式
使用如下命令,描述参见cluster cli:
CLUSTER FAILOVER [FORCE | TAKEOVER]
AOF文件截断错误
如果服务器在写AOF文件时崩溃,有可能导致最后一条命令被截断,这样在redis加载AOF文件时会出现如下错误:
* Reading RDB preamble from AOF file...
* Reading the remaining AOF tail...
# !!! Warning: short read while loading the AOF file !!!
# !!! Truncating the AOF at offset 439 !!!
# AOF loaded anyway because aof-load-truncated is enabled
可以使用如下命令修复并重启redis:
$ redis-check-aof --fix <filename>
使用RDB进行备份和恢复
-
备份:调用
BGSAVE创建RDB备份文件,通过info persistence中的rdb_bgsave_in_progress和rdb_last_bgsave_status查看BGSAVE的状态 -
恢复:
-
恢复前需要确保redis server down,这样就会在第一台启动的节点(master)上进行恢复
redis-cli shutdown -
在配置文件中禁用redis的AOF功能
appendonly no -
通过
CONFIG get dir获取redis存放备份文件的目录。停止redis,将备份文件放到该目录下,修改备份文件权限:chmod 660 /home/redis/dump.rdb -
重启redis。如果启用了AOF,则重新启用AOF功能
-
如何在使用dump.rdb snapshot的同时启用AOF
Redis >= 2.2
- 备份最新的
dump.rdb文件 - 启用AOF:
redis-cli config set appendonly yes - 如果要禁用rdb:
redis-cli config set save "" - 确保写命令追加到了AOF文件
- 重要:更新
redis.conf文件,匹配上述操作,否则重启redis会导致配置丢失,进而导致数据丢失。 - 通过
INFO persistence命令等待AOF结束:aof_rewrite_in_progress和aof_rewrite_scheduled为0,且aof_last_bgrewrite_status为ok。若一切正常,重启redis服务 - 重启redis之后,校验数据库内存是否与之前的匹配
sentinel中的网络隔离
对于如下场景(M: master,S: sentinel,R: replica,C:client)
+----+
| M1 |
| S1 |
+----+
|
+----+ | +----+
| R2 |----+----| R3 |
| S2 | | S3 |
+----+ +----+
Configuration: quorum = 2
如果老的master出现网络隔离,此时可能会导致出现2个master节点,此时由于client(C1)仍然向M1写数据,当网络恢复之后,老的master会变为新master的replica,导致数据丢失。
+----+
| M1 |
| S1 | <- C1 (writes will be lost)
+----+
|
/
/
+------+ | +----+
| [M2] |----+----| R3 |
| S2 | | S3 |
+------+ +----+
可以通过在master中配置如下参数缓解上述问题,即如果在10s之内,master无法向至少1个replica写数据,就会变为unavailable状态,待网络恢复之后,client就可以获取到有效的配置。但这种方式意味着,如果两个replicas down,将导致master无法处理写请求
min-replicas-to-write 1
min-replicas-max-lag 10
Redis迁移到k8s
redis是单线程的,它倾向于使用具有较大缓存的CPU,而不是具有更多cores的CPU。而k8s一般使用的是CPU share方式,从多个CPU上获取的CPU执行时间,因此会引入进程上下文切换的问题。
Python client
Redis Cluster check错误 **[WARNING] Node localhost:6379 has slots in importing state**
使用 redis-cli --cluster fix localhost:6379即可。
Redis-sentinel测试环境
容器测试环境
version: '3.8'
services:
redis-master:
container_name: redis-master
image: 'bitnami/redis:7.4'
environment:
- REDIS_REPLICATION_MODE=master
- REDIS_PASSWORD=redispassword
ports:
- "6379:6379"
redis-slave:
container_name: slave-redis
image: 'bitnami/redis:7.4'
environment:
- REDIS_REPLICATION_MODE=slave
- REDIS_MASTER_HOST=redis-master
- REDIS_MASTER_PASSWORD=redispassword
- REDIS_PASSWORD=redispassword
ports:
- "7000:6379"
depends_on:
- redis-master
redis-sentinel-1:
image: 'bitnami/redis-sentinel:7.4'
container_name: sentinel-1
environment:
- REDIS_MASTER_SET=mymaster
- REDIS_MASTER_HOST=redis-master
- REDIS_MASTER_PASSWORD=redispassword
- REDIS_SENTINEL_DOWN_AFTER_MILLISECONDS=10000
depends_on:
- redis-master
- redis-slave
ports:
- "26379:26379"
redis-sentinel-2:
image: 'bitnami/redis-sentinel:7.4'
container_name: sentinel-2
environment:
- REDIS_MASTER_SET=mymaster
- REDIS_MASTER_HOST=redis-master
- REDIS_MASTER_PASSWORD=redispassword
- REDIS_SENTINEL_DOWN_AFTER_MILLISECONDS=10000
depends_on:
- redis-master
- redis-slave
ports:
- "26380:26379"
redis-sentinel-3:
image: 'bitnami/redis-sentinel:7.4'
container_name: sentinel-3
environment:
- REDIS_MASTER_SET=mymaster
- REDIS_MASTER_HOST=redis-master
- REDIS_MASTER_PASSWORD=redispassword
- REDIS_SENTINEL_DOWN_AFTER_MILLISECONDS=10000
depends_on:
- redis-master
- redis-slave
ports:
- "26381:26379"
虚机测试环境
sentinel.conf:
dir "/Users/charlie.liu/home/redis"
sentinel auth-pass mymaster wpPcahGLWdZz6tvG
sentinel auth-user mymaster sentinel_user
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 127.0.0.1 6380 1
sentinel down-after-milliseconds mymaster 5000
port 26379
redis.conf:
masterauth "password"
requirepass "password"
-
启动一台redis:
redis-server redis.conf --port 6380 -
启动另一台redis:
redis-server redis.conf --port 6379 --slaveof 127.0.0.1 6380 -
在所有redis节点上执行
ACL SETUSER sentinel_user on >wpPcahGLWdZz6tvG ~* &* +@all -
启动单节点sentinel:
redis-sentinel ./sentinel.conf
启用TLS
-
sentinel.conf:dir "/Users/charlie.liu/home/redis" sentinel auth-pass mymaster wpPcahGLWdZz6tvG sentinel auth-user mymaster sentinel_user sentinel deny-scripts-reconfig yes sentinel monitor mymaster 127.0.0.1 6380 1 sentinel down-after-milliseconds mymaster 5000 port 0 tls-auth-clients no tls-replication yes tls-cert-file /Users/charlie.liu/home/redis/certs/tests/tls/redis.crt tls-key-file /Users/charlie.liu/home/redis/certs/tests/tls/redis.key tls-ca-cert-file /Users/charlie.liu/home/redis/certs/tests/tls/ca.crtredis.conf:dir "/Users/charlie.liu/home/redis" masterauth "password" requirepass "password" port 0 tls-auth-clients no tls-replication yes tls-prefer-server-ciphers yes tls-protocols "TLSv1.2" tls-cert-file /Users/charlie.liu/home/redis/certs/tests/tls/redis.crt tls-key-file /Users/charlie.liu/home/redis/certs/tests/tls/redis.key tls-ca-cert-file /Users/charlie.liu/home/redis/certs/tests/tls/ca.crt tls-dh-params-file /Users/charlie.liu/home/redis/certs/tests/tls/redis.dh -
启动一台redis:
redis-server redis.conf-tls --tls-port 6380 -
启动另一台redis:
redis-server redis.conf-tls --tls-port 6379 --slaveof 127.0.0.1 6380 -
在所有redis节点上执行
ACL SETUSER sentinel_user on >wpPcahGLWdZz6tvG ~* &* +@all -
为不同的sentinels节点创建不同的配置文件,然后启动3台sentinel:
redis-sentinel ./sentinel.conf-1 --tls-port 26381,redis-sentinel ./sentinel.conf-2 --tls-port 26382,redis-sentinel ./sentinel.conf-3 --tls-port 26383
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/18382822

 浙公网安备 33010602011771号
浙公网安备 33010602011771号