
Linux调试
Linux debugging, profiling and tracing training
Debugging, Profiling, Tracing
Debugging
▶ 查找和修复软件/系统中存在的问题
▶ 可能会用到不同的工具和方法:
- 交互式调试(如GDB)
- 事后分析(如coredump)
- 控制流分析(使用tracing工具)
- 测试(集成测试)
▶ 大部分调试都是在开发环境中完成的
▶ 通常是侵入式的,允许暂停和恢复程序运行
Profiling
▶ 通过分析程序的运行时来帮助优化性能
▶ 通常会采集程序运行中的计数器
▶ 使用特定的工具、库和操作系统特性来衡量性能,如perf,OProfile
▶ 首先会聚合查询执行过程中的数据,如程序调用次数、内存使用、CPU负载、缓存miss等,然后从这些数据中抽取有意义的信息,并以此来优化程序
Tracing
▶ 通过跟踪应用的执行流来了解瓶颈和问题
▶ 在编译或运行时执行检测代码。可以使用特定的tracer,如LTTng、trace-cmd、SystemTap等来查看用户空间到内核空间的函数调用
▶ 允许查看应用执行时使用的函数和值
▶ 通常会在运行时记录跟踪数据,并在运行结束后展示这些数据
- 在tracing结束之后会生成大量tracing数据
- 通常要远大于profiling的数据
▶ 由于可以通过tracepoints抽取数据,因此也可以用于调试目的
Linux Application Stack
User/Kernel mode
▶ 用户模式和内核模式通常指代执行的特权级别(privilege level)
▶ 这种模式实际上是指处理器执行模式,即硬件模式
▶ 内核可以控制完整的处理器状态(异常处理、MMU等),而用户空间只能在内核监督下做一些基本控制和执行。
Processes and Threads
▶ 进程是为执行一个程序而分配的资源组,如内存、线程、文件描述符等。
▶ 一个PID表示一个进程,该进程所有的信息都暴露在/proc/
/proc/self会展示访问该目录的进程的信息
▶ 当启动一个进程时,它会初始化一个struct task_struct结构,表示一个可以被调度的执行线程
- 一个进程在内核中体现为一个关联到多个资源的线程
▶ 线程是个独立的执行单元,共享进程内部的资源,如地址空间,文件描述符等
▶ 可以使用fork()系统调用创建一个新的进程,使用pthread_create() 创建一个新的线程
▶ 任何时候,一个CPU core只能执行一个任务(使用get_current()函数查看当前执行的任务),而一个任务也只能在一个CPU core上执行
▶ 不同的CPU core可以执行不同的任务
MMU and memory management
▶ 在Linux内核中(配置了CONFIG_MMU=y),CPU访问的所有地址都是虚拟地址
▶ 内存管理单元(MMU)可以将这些虚拟内存映射到物理内存上(RAM或IO)
▶ MMU的基本映射单元成为页(page),页的大小是固定的(具体取决于架构/内核配置)
▶ 地址映射信息会被插入到MMU硬件的页表中,用于将CPU访问的虚拟地址转换为物理地址
▶ MMU可以通过某些属性来限制页映射访问,如No Execute, Writable, Readable bits, Privileged/User bit, cacheability等
Userspace/Kernel memory layout
▶ 每个进程都有自己的虚拟地址空间(struct task_struct中的mm字段)以及页表(但共享相同的内核映射)
▶ 默认情况下,为了减少攻击,所有用户映射地址(base of heap, stack, text, data等)都是随机的。可以通过norandmaps参数禁用该功能
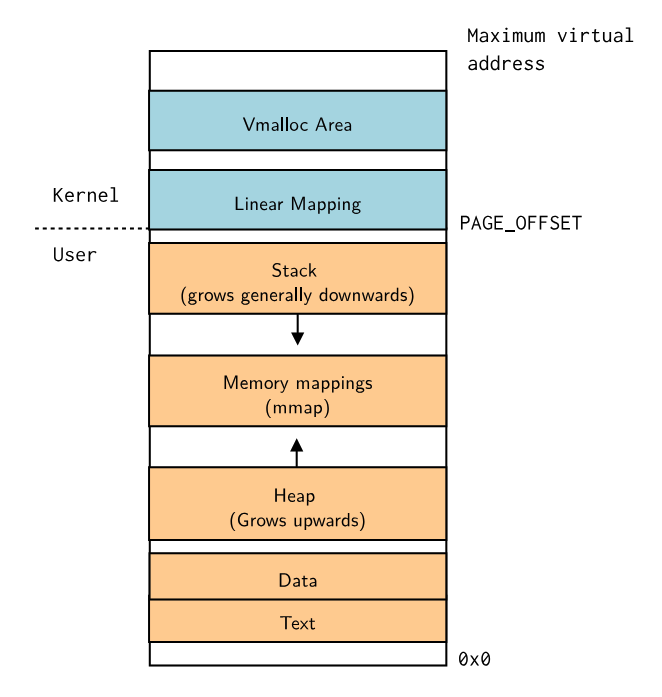
不同的进程有不同的用户内存空间:
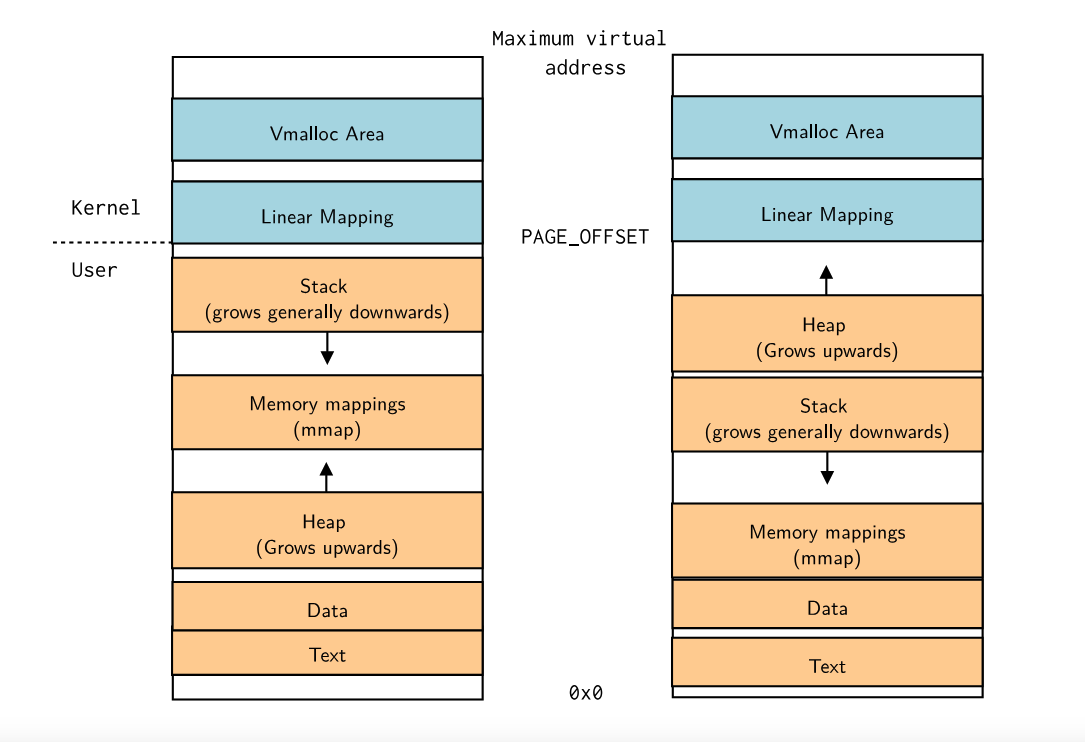
Kernel memory map
▶ 内核有其特定的内存映射
▶ 内核启动时会通过插入所有内核初始页表中的元素来配置Linear mapping
▶ 通过位置来划分不同的内存区域
▶ 支持随机配置内核地址空间布局,可以通过nokaslr命令禁用该功能
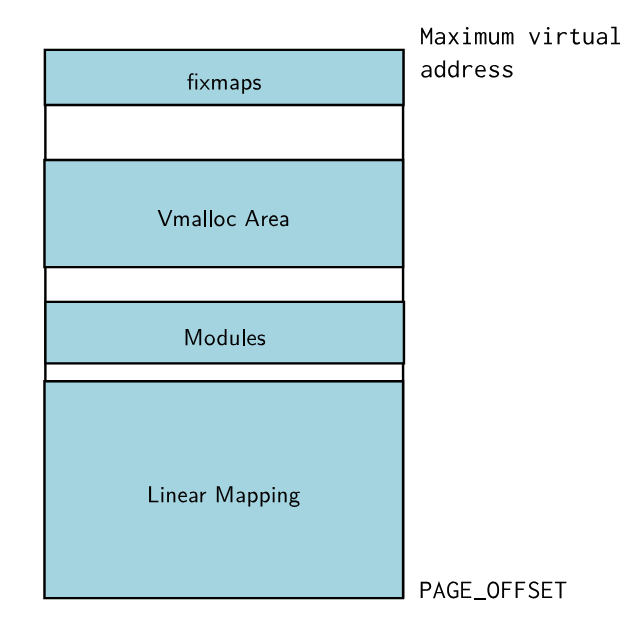
Userspace memory segments
▶ 当启动一个进程时,内核会设置一些虚拟内存区域(由struct vm_area_struct管理的Virtual Memory Areas (VMA)),并配置不同的属性。
▶ VMA内存域会映射到特定的属性(R/W/X)
▶ 当一个程序试图访问未映射的内存域或映射到不允许访问的内存域时会发生段错误,如
- 向一个只读的内存段写数据
- 尝试执行一个不可执行的内存段
▶ 可以通过mmap()创建新的内存域
▶ 通过/proc/
7f1855b2a000-7f1855b2c000 rw-p 00030000 103:01 3408650 ld-2.33.so
7ffc01625000-7ffc01646000 rw-p 00000000 00:00 0 [stack]
7ffc016e5000-7ffc016e9000 r--p 00000000 00:00 0 [vvar]
7ffc016e9000-7ffc016eb000 r-xp 00000000 00:00 0 [vdso]
Userspace memory types
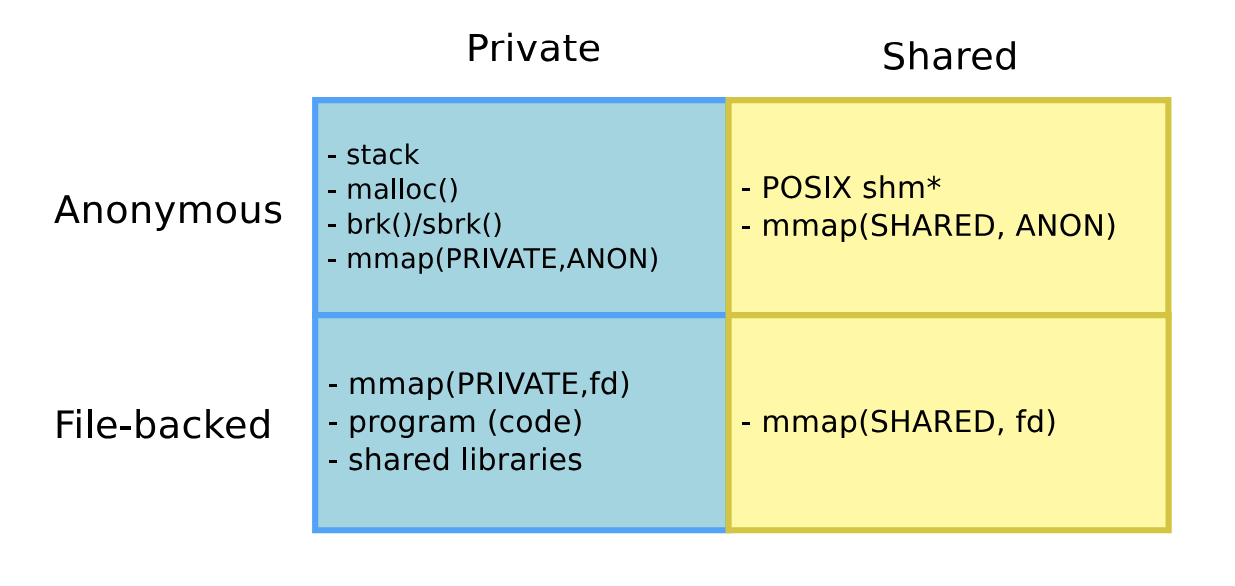
Terms for memory in Linux tools
▶ 当使用Linux工具时,会使用如下4个术语来描述内存:
- VSS/VSZ: Virtual Set Size (虚拟内存大小,包含共享libraries)
- RSS: Resident Set Size (使用的总物理内存,包含共享libraries)
- PSS: Proportional Set Size (指与其他进程共享的内存大小,如果一个进行独占了10MB内存,并确和另外一个进程共享了10MB内存,则PSS为15MB)
- USS: Unique Set Size (进程占用的物理内存,不包含共享映射内存)
▶ VSS >= RSS >= PSS >= USS.
Process context
▶ 进程上下文可以看作是与一个进程有关系的CPU寄存器中的内容:execution register, stack register
▶ 进程上下文还指定了一个执行状态,并允许在内核模式中休眠
▶ 进程上下文中执行的进程可以被抢占
▶ 当在这类上下文中执行进程时,可以通过get_current()访问ss struct task_struct

Scheduling
▶ 有多种原因可以唤醒调度器
- 中断HZ引起的周期性tick(时钟中断)
- 由非时钟系统导致的程序中断(CONFIG_NO_HZ=y)
- 代码中主动调用schedule()
- 隐式调用可以休眠的函数(如kmalloc(),wait_event()等阻塞操作)
▶ 当进入调度函数后,调度器会选择一个运行一个新的struct task_struct,最后调用switch_to()宏
▶ switch_to()会保存当前任务的进程上下文,并在设置新的当前任务运行时恢复下一个任务的进程上下文
The Linux Kernel Scheduler
▶ Linux内核调度器是实现实时行为的一个关键组件
▶ 它负责决定执行哪些可运行的任务
▶ 还负责选择任务运行的CPU,并且和CPUidle和CPUFreq紧密耦合
▶ 同时负责内核空间和用户空间的任务调度
▶ 每个任务会被分配一个调度类型(scheduling class)或策略
▶ 调度算法会根据类型来选择执行的任务
▶ 系统中可以存在不同调度类型的任务
Non-Realtime Scheduling Classes
有如下3种非实时调度类:
▶ SCHED_OTHER: 默认策略,使用时间片算法
▶ SCHED_BATCH: 类似SCHED_OTHER,但主要用于执行CPU密集型任务
▶ SCHED_IDLE: 优先级很低。
▶ SCHED_OTHER 和 SCHED_BATCH都可以使用nice值来增加或减少其调度频率
- 较高的nice值意味着较低的调度频率
Realtime Scheduling Classes
有如下3种实时调度类型:
▶ 可运行的任务会抢占其他低优先级的任务
▶ SCHED_FIFO: 具有相同优先级的任务会依照先进先出的原则调度
▶ SCHED_RR: 类似SCHED_FIFO,但相同优先级的任务间会使用时间片轮询
▶ SCHED_FIFO 和 SCHED_RR 可以分配的优先级为1到99
▶ SCHED_DEADLINE: 用于执行重复jobs,任务会附加额外的属性:
- computation time,表示完成一个job所需的时间
- deadline,允许一个job运行的最大时间
- period,在该时间周期内只能运行一个job
▶ 仅定义任务类型并不足以实现实时行为
Changing the Scheduling Class
▶ 每个任务都有一个调度类(Scheduling Class),默认为SCHED_OTHER
▶ man 2 sched_setscheduler 系统调用可以修改一个任务的调度类型
▶ chrt工具:
-
修改一个正在运行的任务的调度类型:
chrt -f/-b/-o/-r/-d -p PRIO PID -
还可以使用
chrt拉起一个特定调度类型的程序:chrt -f/-b/-o/-r/-d PRIO CMD -
展示当前进程的调度类型和优先级:
chrt -p PID
▶ 如果使用 man 2 sched_setscheduler设置了SCHED_RESET_ON_FORK标记,则新的进程会继承父进程的调度类型
Context switching
▶ 上下文切换是一种改变处理器执行模式的行为(Kernel ↔ User):
- 明确执行系统调用指令(从用户模式同步请求到内核)
- 隐式接收到的异常(MMU异常、中断、断点等)
▶ 这种状态变更最终将体现到一个内核入口(通常是调用向量)中,该入口将执行必要的代码,并为内核模式执行设置正确的状态。
▶ 内核会处理如寄存器保存、切换到内核栈等行为:
- 为了安全,内核栈的大小是固定的
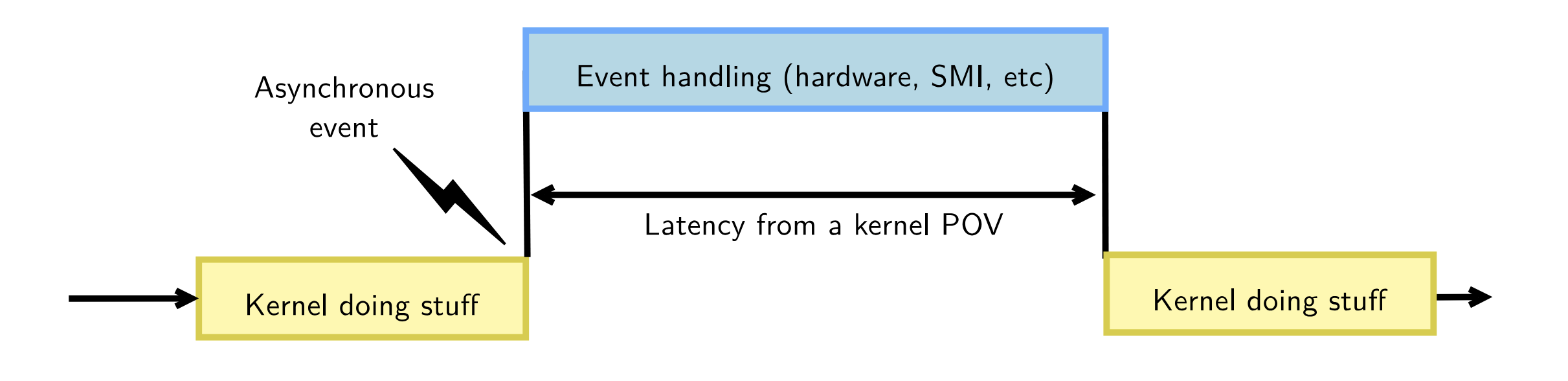
Exceptions
▶ 异常为表示导致CPU进入异常模式(处理异常)的events
▶ 主要有两种异常:同步和异步
- 通常在执行MMU、总线中断或接收到软硬件的中断时会产生异步异常
- 当执行特定的指令,如断点、系统调用等会产生同步异常
▶ 当触发此类异常后,处理器会跳转到异常向量中,并执该异常代码
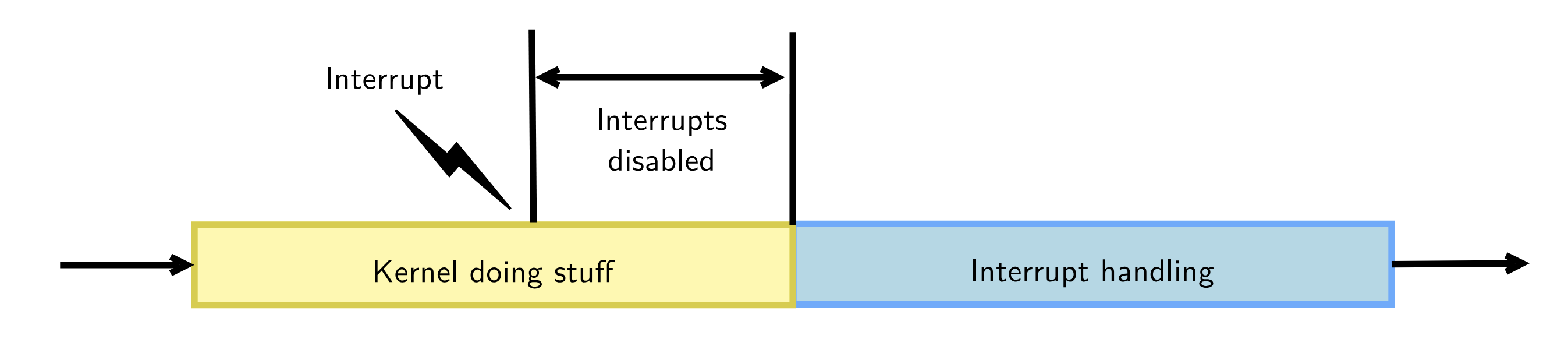
Interrupts
▶ 中断是由硬件周边设备生成的异步信号
- 也可以是由特定指令生成的同步信号(如(Inter Processor Interrupts )
▶ 当接收到一个中断时,CPU会改变其执行模式,跳转到一个特定向量并切换到内核模式来处理该中断
▶ 当存在多个CPU(cores)时,中断通常会定向到某个core
▶ 可以通过"IRQ affinity"来控制每个CPU的中断负载
▶ 当处理一个中断时,内核会运行一个称为中断上下文(interrupt context)的特殊上下文
▶ 该上下文不会进入用户空间,且不应该使用get_current()
▶ 根据不同的架构,可能会使用一个IRQ栈
▶ 禁用中断(不支持嵌套中断) !

System Calls
▶ 系统调用允许用户空间通过向内核请求服务来执行特定的指令(man 2 syscall)
- 执行
libc提供的函数(如read(),write()等)时,通常会执行一个系统调用
▶ 通过寄存器传入的数字标识符来辨别不同的系统调用:
-
内核通过(
unistd.h中)__NR_<sycall>来定义系统调用标识符,如:#define __NR_read 63 #define __NR_write 64
▶ 内核持有指向这些标识符的函数指针表,在完成系统调用的有效性验证之后会通过这些指针来调用正确的处理函数
▶ 通过寄存器传递系统调用参数(最大6个参数)
▶ 当执行系统调用时,CPU会改变其执行状态并切换到内核模式
▶ 每个架构都有一个特定的硬件机制(man 2 syscall)
mov w8, #__NR_getpid
svc #0
tstne x0, x1
Kernel execution contexts
▶ 内核会根据处理的event,在不同的上下文中执行代码
▶ 可能包括禁止中断(通过禁止中断,可以确保某个中断处理程序不会抢占当前的代码)、特定的栈等
Kernel threads
▶ 内核线程(kthreads)是一个特殊类型的struct task_struct,没有关联任何用户资源(mm == NULL)
▶ 可以从kthreadd进程clone内核进程,也可以使用kthread_create创建内核进程
▶ 与用户进程类似,可以在进程上下文中调度以及休眠内核线程
▶ 通过ps命令可以查看内核线程的名称(方括号表示):
$ ps --ppid 2 -p 2 -o uname,pid,ppid,cmd,cls
USER PID PPID CMD CLS
root 2 0 [kthreadd] TS
root 3 2 [rcu_gp] TS
root 4 2 [rcu_par_gp] TS
root 5 2 [netns] TS
root 7 2 [kworker/0:0H-events_highpr TS
root 10 2 [mm_percpu_wq] TS
root 11 2 [rcu_tasks_kthread] TS
Workqueues
▶ Workqueues允许在未来的某个时间点调度执行work
▶ Workqueues在内核线程中执行work函数:
- 允许在执行延迟工作时休眠。
- 执行时可以启用中断
▶ 可以在特定的workqueue或多用户共享的全局workqueue中执行work。
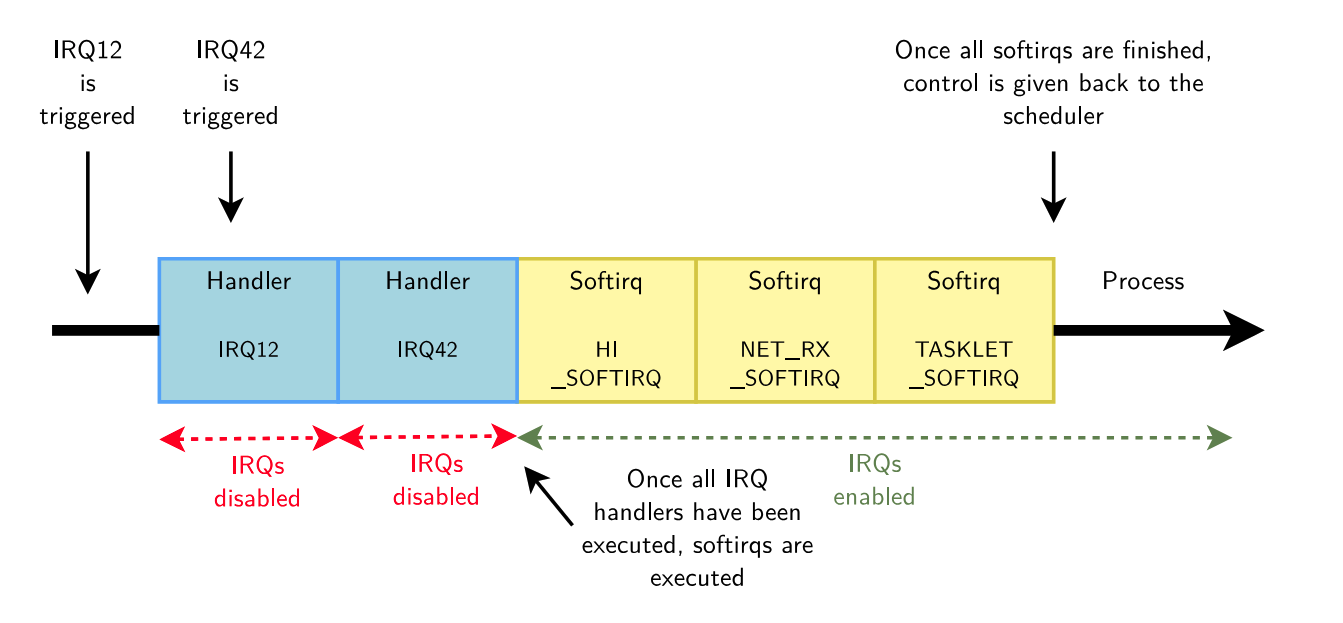
softirq
▶ SoftIRQs是一种运行在软件中断上下文中的内核机制
▶ 可以执行需要在中断处理后,且需要低延迟的代码。执行时机如下:
- 在中断上下文处理完硬中断之后执行
- 在和执行中断处理的相同上下文中执行,因此不允许休眠。
▶ 如果需要在软中断上下文中执行代码,则应该使用现有的软中断实现,如tasklet,和BH workqueues(6.9之后用于替代tasklets),无需自行实现:
Threaded interrupts
▶ 线程中断是一种允许使用一个硬中断处理器(IRQ handler)和一个线程中断处理器处理中断的机制
▶ 一个线程中断处理器可以执行可能会在kthread中休眠的work
▶ 内核会为每个请求线程中断的中断行创建一个kthread
- kthread名为
irq/<irq>-<name>,可以使用ps命令查看
Allocations and context
▶ 可以使用下面函数在内核中申请内存:
void *kmalloc(size_t size, gfp_t gfp_mask);
void *kzalloc(size_t size, gfp_t gfp_mask);
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
▶ 所有内存申请函数都有一个gfp_mask参数,用于指定内存类型:
GFP_KERNEL:正常分配,可以在分配内存时休眠(不能在中断上下文中使用)GFP_ATOMIC:自动分片,不会在分配数据时休眠
Linux Common Analysis & Observability Tools
Pseudo Filesystems
▶ 内核会暴露一些虚拟文件系统来提供系统信息
▶ procfs 包含进程和系统信息
- 挂载位置为
/proc - 通常会通过工具解析,以一种更友好的方式来展示原始数据
▶ sysfs提供了与设备和驱动有关的硬件/逻辑信息。挂载位置为/sys
▶ debugfs展示了与调试有关的信息
- 通常挂载在
/sys/kernel/debug/目录下 mount -t debugfs none /sys/kernel/debug
procfs
▶ procfs暴露了进程和系统相关的信息(man 5 proc)
/proc/cpuinfo展示了CPU信息/proc/meminfo展示了内存信息 (used, free, total等)/proc/sys/包含可调节的系统参数。通过admin-guide/sysctl/index可以查看能够修改的参数列表/proc/interrupts:统计了各个CPU的中断计数/proc/irq中的每个中断行都展示了一个中断的特定配置/状态
/proc/<pid>/展示了进程相关的信息/proc/<pid>/status展示了进程的基本信息/proc/<pid>/maps展示了内存映射信息/proc/<pid>/fd展示了进程的文件描述符/proc/<pid>/task展示了属于该进程的线程的描述符
/proc/self/会展示访问该文件的进程信息
▶ 可以在filesystems/proc 和 man 5 proc 中查看可用的procfs文件和相关内容
sysfs
▶ sysfs文件系统暴露了关于各种内核子系统、硬件设备和与驱动有关的信息(man 5 sysfs)
▶ 可以通过表示内核内部设备树的文件层级来查看驱动和设备之间的联系
▶ /sys/kernel包含内核调试的文件:
irq:包含了中断相关的信息(映射、计数等)tracing:用于tracing控制
debugfs
▶ debugfs是一个简单的基于RAM的文件系统,暴露了调试信息
▶ 某些子系统(clk, block, dma, gpio等)会使用它来暴露内部调试信息
▶ 通常挂载到/sys/kernel/debug
- 可以通过
/sys/kernel/debug/dynamic_debug实现动态调试 /sys/kernel/debug/clk/clk_summary暴露了时钟树
ELF files analysis
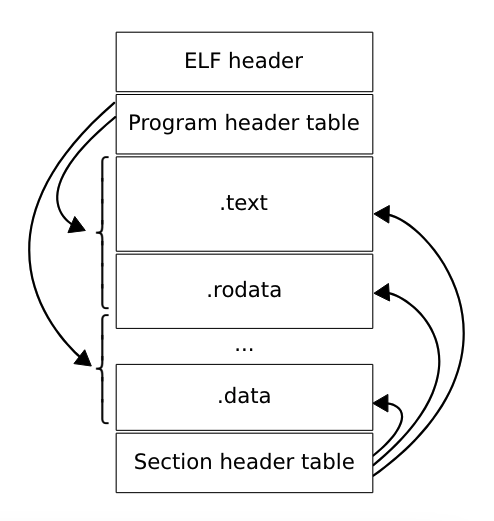
ELF files
ELF表示Executable and Linkable Format
▶ 文件包含一个定义文件的二进制结构的首部
▶ 一系列包含数据的segments和sections:
.textsection: 代码.datasection: 数据.rodatasection: 只读数据.debug_infosection: 包含调试信息
▶ Sections是segment的一部分,可以被加载到内存中
▶ 内核支持的所有架构都采用相同的格式,vmlinux格式也是如此
- 很多其他操作系统也使用ELF作为标准的可执行文件格式
binutils for ELF analysis
▶ binutils用于处理二进制文件(对象文件或可执行文件)
- 包括
ld、as以及其他有用的工具
▶ readelf可以展示ELF文件的信息(header, section, segments等)
▶ objdump可以展示和反汇编ELF文件
▶ objcopy可以将转换ELF文件或抽取/翻译部分EKF文件
▶ nm可以展示嵌入在ELF文件中的符号列表
▶ addr2line可以根据ELF文件中的地址查找源文件行/文件
binutils example
▶ 使用nm查找ksys_read()内核函数的地址
$ nm vmlinux | grep ksys_read
c02c7040 T ksys_read
▶ 使用addr2line来查找内核OOPS地址或符号名称对应的源码:
$ addr2line -s -f -e vmlinux ffffffff8145a8b0
queue_wc_show
blk-sysfs.c:516
▶ 使用readelf展示一个ELF首部:
$ readelf -h binary
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Position-Independent Executable file)
Machine: Advanced Micro Devices X86-64
...
▶ 使用objcopy将一个ELF文件转换为一个扁平二进制文件(flat binary file):
$ objcopy -O binary file.elf file.bin
ldd
▶ 可以使用ldd展示一个ELF中使用的共享库(man 1 ldd)
▶ ldd会列出链接期间使用的所有库
- 不会展示在运行时使用
dlopen()加载的库
$ ldd /usr/bin/bash
linux-vdso.so.1 (0x00007ffdf3fc6000)
libreadline.so.8 => /usr/lib/libreadline.so.8 (0x00007fa2d2aef000)
libc.so.6 => /usr/lib/libc.so.6 (0x00007fa2d2905000)
libncursesw.so.6 => /usr/lib/libncursesw.so.6 (0x00007fa2d288e000)
/lib64/ld-linux-x86-64.so.2 => /usr/lib64/ld-linux-x86-64.so.2 (0x00007fa2d2c88000)
Processor and CPU monitoring Tools
▶ 很多工具可以监控系统的各个部分
▶ 大部分工具都是CLI交互程序
- 进程:ps, top, htop等
- 内存:Free, vmstat等
- 网络
▶ 大部分工具依赖sysfs 或 procfs文件系统来获取进程、内存和系统信息
- 网络工具使用内核网络子系统的netlink接口
ps & top(略)
mpstat
▶ 展示多处理器信息(man 1 mpstat)
▶ 用于探测不均衡的CPU负载、错误的IRQ亲和等
$ mpstat -P ALL
Linux 6.0.0-1-amd64 (fixe) 19/10/2022 _x86_64_ (4 CPU)
17:02:50 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
17:02:50 all 6,77 0,00 2,09 11,67 0,00 0,06 0,00 0,00 0,00 79,40
17:02:50 0 6,88 0,00 1,93 8,22 0,00 0,13 0,00 0,00 0,00 82,84
17:02:50 1 4,91 0,00 1,50 8,91 0,00 0,03 0,00 0,00 0,00 84,64
17:02:50 2 6,96 0,00 1,74 7,23 0,00 0,01 0,00 0,00 0,00 84,06
17:02:50 3 9,32 0,00 2,80 54,67 0,00 0,00 0,00 0,00 0,00 33,20
17:02:50 4 5,40 0,00 1,29 4,92 0,00 0,00 0,00 0,00 0,00 88,40
Memory monitoring tools
free
▶ free是一个简单的展示系统剩余和已使用内存用量的程序(man 1 free)
- 用于检查系统内存是否耗尽
- 使用
/proc/meminfo来获取内存信息
$ free -h
total used free shared buff/cache available
Mem: 15Gi 7.5Gi 1.4Gi 192Mi 6.6Gi 7.5Gi
Swap: 14Gi 20Mi 14Gi
▶ free字段数值较小并不意味着内存耗尽,为了优化性能,内存会将缓存未使用的内存。参见 man 5 proc中的drop_caches来观察buffers/cache对free/available内存的影响
vmstat
▶ vmstat展示了系统虚拟内存使用信息
▶ 还可以展示进程、内存、页、阻塞IO、traps、磁盘和CPU使用情况。man 8 vmstat
▶ 可以周期性获取数据:vmstat
$ vmstat 1 6
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 253440 1237236 194936 9286980 3 6 186 540 134 157 3 5 82 10 0
▶ 注意:vmstat将内核块视为1024 bytes
pmap
▶ pmap以建议的形式展示了/proc/<pid>/maps中的内容。man 1 pmap
# pmap 2002
2002: /usr/bin/dbus-daemon --session --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only
...
00007f3f958bb000 56K r---- libdbus-1.so.3.32.1
00007f3f958c9000 192K r-x-- libdbus-1.so.3.32.1
00007f3f958f9000 84K r---- libdbus-1.so.3.32.1
00007f3f9590e000 8K r---- libdbus-1.so.3.32.1
00007f3f95910000 4K rw--- libdbus-1.so.3.32.1
00007f3f95937000 8K rw--- [ anon ]
00007f3f95939000 8K r---- ld-linux-x86-64.so.2
00007f3f9593b000 152K r-x-- ld-linux-x86-64.so.2
00007f3f95961000 44K r---- ld-linux-x86-64.so.2
00007f3f9596c000 8K r---- ld-linux-x86-64.so.2
00007f3f9596e000 8K rw--- ld-linux-x86-64.so.2
00007ffe13857000 132K rw--- [ stack ]
00007ffe13934000 16K r---- [ anon ]
00007ffe13938000 8K r-x-- [ anon ]
total 11088K
I/O monitoring tools
iostat
▶ iostat展示了系统上各个设备的IOs
▶ 用于查看一个设备是否IOs过载
$ iostat
Linux 5.19.0-2-amd64 (fixe) 11/10/2022 _x86_64_ (12 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
8,43 0,00 1,52 8,77 0,00 81,28
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
nvme0n1 55,89 1096,88 149,33 0,00 5117334 696668 0
sda 0,03 0,92 0,00 0,00 4308 0 0
sdb 104,42 274,55 2126,64 0,00 1280853 9921488 0
iotop
▶ iotop展示了每个进程的IOs信息
▶ 用于查看那个进程产生了大量I/O流
- 需要在内核中启用CONFIG_TASKSTATS=y, CONFIG_TASK_DELAY_ACCT=y 和 CONFIG_TASK_IO_ACCOUNTING=y
- 还需要在运行时启用:
sysctl -w kernel.task_delayacct=1
# iotop
Total DISK READ: 20.61 K/s | Total DISK WRITE: 51.52 K/s
Current DISK READ: 20.61 K/s | Current DISK WRITE: 24.04 K/s
TID PRIO USER DISK READ DISK WRITE> COMMAND
2629 be/4 cleger 20.61 K/s 44.65 K/s firefox-esr [Cache2 I/O]
322 be/3 root 0.00 B/s 3.43 K/s [jbd2/nvme0n1p1-8]
39055 be/4 cleger 0.00 B/s 3.43 K/s firefox-esr [DOMCacheThread]
1 be/4 root 0.00 B/s 0.00 B/s init
2 be/4 root 0.00 B/s 0.00 B/s [kthreadd]
3 be/0 root 0.00 B/s 0.00 B/s [rcu_gp]
4 be/0 root 0.00 B/s 0.00 B/s [rcu_par_gp]
Networking Observability tools
ss
▶ ss展示了网络socket的状态
- IPv4, IPv6, UDP, TCP, ICMP 和 UNIX domain sockets
▶ 取代netstat
▶ 从/proc/net中获取信息
▶ 用法:
ss:默认展示连接的socketsss -l展示监听socketsss -a展示监听和连接的socketsss -4/-6/-x仅展示IPv4、IPv6或UNIX socketsss -t/-u仅展示TCP或UDP socketsss -p展示每个socket使用的进程ss -n展示数字形式的地址ss -s展示现有sockets的大概情况
▶ 参见the ss manpage
# ss
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
u_dgr ESTAB 0 0 * 304840 * 26673
u_str ESTAB 0 0 /run/dbus/system_bus_socket 42871 * 26100
icmp6 UNCONN 0 0 *:ipv6-icmp *:*
udp ESTAB 0 0 192.168.10.115%wlp0s20f3:bootpc 192.168.10.88:bootps
tcp ESTAB 0 136 172.16.0.1:41376 172.16.11.42:ssh
tcp ESTAB 0 273 192.168.1.77:55494 87.98.181.233:https
tcp ESTAB 0 0 [2a02:...:dbdc]:38466 [2001:...:9]:imap2
...
#
iftop
▶ iftop展示一个远端主机的带宽使用情况
▶ 使用直方图展示带宽
▶ iftop -i eth0:
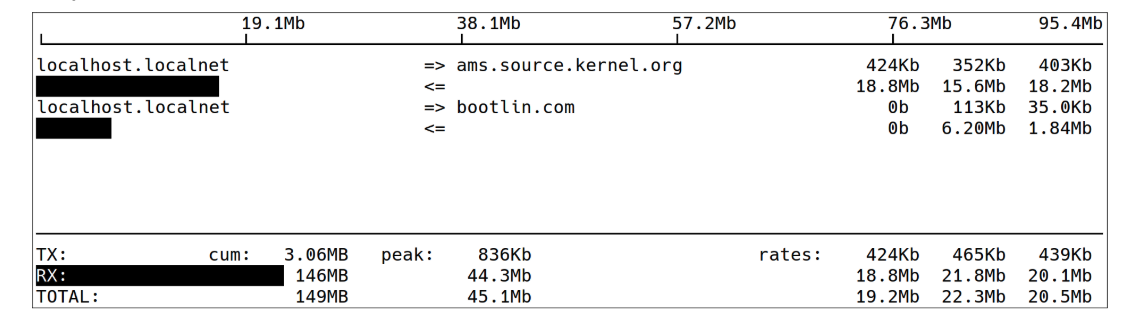
▶ 可以自定义输出
tcpdump
▶ tcpdump可以捕获网络流量并解码很多协议
▶ 基于libpcap库来捕获报文
▶ 可以将捕获的报文保存到文件,然后再读取
- 可以保存为pcap或新的pcapng格式
tcpdump -i eth0 -w capture.pcaptcpdump -r capture.pcap
▶ 可以使用过滤器来阻止捕获不相关的报文
tcpdump -i eth0 tcp and not port 22
Wireshark(略)
Application Debugging
Good practices
▶ 当前编译器可以在编译期间通过告警检测很多错误
- 如果想尽早捕获错误,推荐使用
-Werror -Wall -Wextra
▶ 编译器可以提供静态分析功能
- GCC可以通过-fanalyzer 标志提供该功能
- LLVM在构建过程中提供了特定的工具
▶ 还可以使用组件特定的helper/hardening
- 例如,在使用GNC C库时,可以通过_FORTIFY_SOURCE 宏添加运行时输入检测。
Building with debug information
Debugging with ELF files
▶ GDB 可以调试ELF文件,ELF文件中包含了调试信息
▶ 调试信息使用DWARF格式
▶ 允许调试器根据地址和符号名称、调用点等进行调试
▶ 调试信息由编译器在编译期间通过指定-g生成到ELF文件中
-g1:最小调试信息(调用栈使用)-g2:指定-g时的默认调试级别-g3:包含额外的调试信息(宏定义)
▶ 更多调试信息参见GCC文档
Debugging with compiler optimizations
▶ 编译器优化 (-O<level>)会导致优化掉某些变量和函数调用
▶ 在使用GDB展示这些被优化掉的信息时会出现:
$1 = <value optimized out>
▶ 如果想要检查变量和函数,最好使用-O0(不启用优化)编译代码
- 注意:只能通过
-O2或-Os编译内核
▶ 还可以使用编译器属性对函数进行注释:
__attribute__((optimize("O0")))
▶ 移除函数的static修饰符可以避免内联该函数
- 注意: LTO (Link Time Optimization)可以解决这个问题
▶ 将一个特定的变量设置为volatile可以被避免编译器优化
Instrumenting code crashes
▶ 可以通过GNU的扩展函数backtrace() (man 3 backtrace)来展示应用的调用栈:
char **backtrace_symbols(void *const *buffer, int size);
▶ 可以通过signal() (man signal(3)) 在特定的信号上添加钩子来打印调用栈:
- 例如可以通过捕获
SIGSEGV信号来dump当前调用栈
void (*signal(int sig, void (*func)(int)))(int);
The ptrace system call
ptrace
▶ ptrace可以通过访问tracee内存和寄存器内存来tracing进程
▶ 一个tracer可以观察和控制另一个进程的执行状态
▶ 通过将ptrace() 系统调用attach到一个tracee进程来实现tracing(man 2 ptrace)
▶ 可以直接调用ptrace(),但通常会通过工具间接调用:
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
▶ GDB、strace等调试工具都可以访问tracee进程状态
GDB
这里简单过一下gdb的一般命令:
gdb <program>:使用gdb调试开始调试一个程序gdb -p <pid>:通过指定程序PID,将gdb attach到一个正在运行的程序上(gdb) run [prog_arg1 [prog_arg2] ...]:指定使用GDB运行一个程序时的命令break foobar (b):为函数foobar()打断点break foobar.c:42:为文件foobar.c的第42行打断点print var,print $reg或print task->files[0].fd (p):打印变量var,寄存器$reg或一个复杂的引用。info registers:展示寄存器信息continue (c):在断点后继续执行next (n):继续到下一行,跳过函数调用step (s):继续到下一行,进入子函数stepi (si):继续下一条指令finish:返回函数backtrace (bt):展示程序调用栈info threads (i threads):展示available的线程列表info breakpoints (i b):展示breakpoints/watchpoints列表delete (d):删除断点thread (t):选择线程frame (f):选择调用栈的特定帧,n表示调用栈的帧watch <variable>或watch \*<address>:为特定的变量/地址添加一个watchpointprint variable = value (p variable = value):修改特定变量的内容break foobar.c:42 if condition == value:如果特定条件为true,则进入断点watch if condition == value:当特定条件为true时,触发此watchpointdisplay <expr>:在每次程序停止时,自动打印表达式x/ <n><u> <address>:展示指定地址的内存。n为展示的内存量,u为展示的数据类型(b/h/w/g)。可以通过使用i类型展示指令。list <expr>:展示与当前程序计数器位置有关的源代码disassemble <location,start_offset,end_offset> (disas):展示当前运行的汇编代码p function(arguments):通过GDB执行一个函数。注意执行该函数可能带来的副作用p $newvar = value:声明一个新的 gdb 变量,该变量可以在本地使用,也可以按照命令顺序使用define <command_name>:定义一个新的命令序列。 后续在GDB中就可以直接调用该命令序列
远程调试
▶ 在一个非嵌入的环境中,可以使用gdb作为调试前端
▶ gdb可以直接访问使用调试符号编译的二进制文件和库
▶ 但在一个嵌入的上下文中,目标平台通常会限制直接使用gdb进行调试
▶ 此时需要远程调试
ARCH-linux-gdb部署在开发工作站中,为用户提供调试特性gdbserver部署在目标系统中(arm架构下只有400KB)
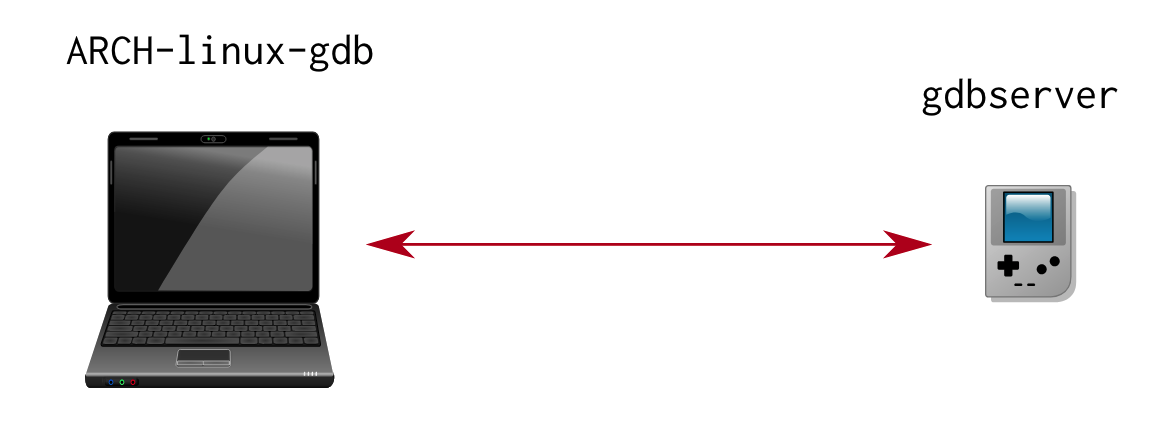
远程调试:架构
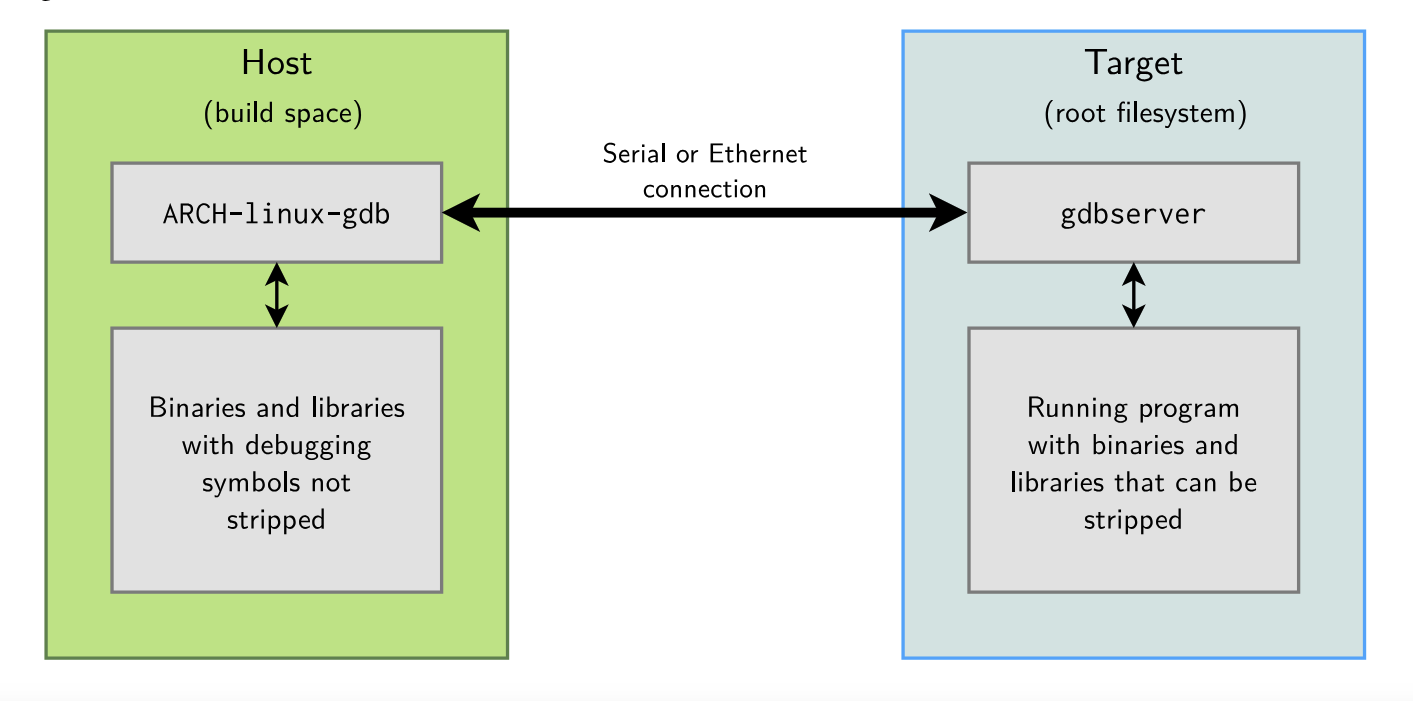
远程调试:目标配置
▶ 在目标通过gdbserver运行一个程序,此时程序不会立即执行:
gdbserver :<port> <executable> <args>
gdbserver /dev/ttyS0 <executable> <args>
▶ 或者,可以让gdbserver attach到一个正在运行的程序上:
gdbserver --attach :<port> <pid>
▶ 或者可以无需执行程序启动一个gdbserver(后续在client侧设置目标程序):
gdbserver --multi :<port>
远程调试:主机配置
▶ 在主机侧启动ARCH-linux-gdb <executable>,并使用如下gdb命令:
-
告诉
gdb共享库目录:gdb> set sysroot <library-path> -
连接目标
gdb> target remote <ip-addr>:<port> (networking) gdb> target remote /dev/ttyUSB0 (serial link)如果启动
gdbserver时指定了--multi选项时,则需要使用target extended-remote替换target remote -
如果没有在
gdbserver命令行中指定调试的程序,则执行如下命令:gdb> set remote exec-file <path_to_program_on_target>
Coredumps
▶ 当一个程序由于段错误导致崩溃时,将不受调试器控制
▶ 幸运的是,Linux可以生成一个ELF格式的包含程序崩溃时的内存的镜像文件,core文件。gdb可以使用core文件分析崩溃的程序状态
▶ 在目标端
- 通过
ulimit -c unlimited启动应用,这样可以在程序崩溃时生成一个core文件 - 可以通过
/proc/sys/kernel/core_pattern(man 5 core)修改输出的coredump文件名称 - 在使用
systemd的系统中,出于安全考虑,默认会禁用coredump功能,可以通过echo core > /proc/sys/kernel/core_pattern临时启用
▶ 在主机端
- 程序崩溃后,将
core文件从目标端传输到主机端,然后执行ARCH-linux-gdb -c core-file application-binary
minicoredumper
▶ 对于复杂程序,coredump可能会比较大
▶ minicoredumper是一个用户空间的工具,它基于标准的core dump特性
▶ 可以将core dump输出通过一个管道重定向到用户空间程序
▶ 基于JSON配置,可以:
-
仅保存相关的sections(stack、heap、选择的ELF sections)
-
压缩输出文件
-
从
/proc保存额外的信息
▶ https://github.com/diamon/minicoredumper
▶ "高效实用的嵌入式系统碰撞数据采集"
- Video:https://www.youtube.com/watch?v=q2zmwrgLJGs
- Slides:elinux.org/images/8/81/Eoss2023_ogness_minicoredumper.pdf
GDB: going further
▶ Tutorial: Debugging Embedded Devices using GDB - Chris Simmonds, 2020
- Slides: https://elinux.org/images/0/01/Debugging-with-gdb-csimmondselce-2020.pdf
- Video: https://www.youtube.com/watch?v=JGhAgd2a_Ck
GDB Python Extension
▶ GDB提供了一个python integration特性,可以脚本化一些调试操作
▶ 当使用GDB执行Python时,会使用一个名为gdb的模块,该模块包含所有与GDB有关的类
▶ 可以添加新的命令、断点和指针类型
▶ 可以通过在Python脚本中的GDB能力完全控制并观测被调试的程序
- 控制执行、添加断点、watchpoints等
- 访问程序内存、帧、符号等
GDB Python Extension
class PrintOpenFD(gdb.FinishBreakpoint):
def __init__(self, file):
self.file = file
super(PrintOpenFD, self).__init__()
def stop (self):
print ("---> File " + self.file + " opened with fd " + str(self.return_value))
return False
class PrintOpen(gdb.Breakpoint):
def stop(self):
PrintOpenFD(gdb.parse_and_eval("file").string())
return False
class TraceFDs (gdb.Command):
def __init__(self):
super(TraceFDs, self).__init__("tracefds", gdb.COMMAND_USER)
def invoke(self, arg, from_tty):
print("Hooking open() with custom breakpoint")
PrintOpen("open")
TraceFDs()
▶ 通过gdb source命令加载Python脚本
- 如果脚本的名称为
<program>-gdb.py,则它会被GDB自动加载:
(gdb) source trace_fds.py
(gdb) tracefds
Hooking open() with custom breakpoint
Breakpoint 1 at 0x33e0
(gdb) run
Starting program: /usr/bin/touch foo bar
Temporary breakpoint 2 at 0x5555555587da
---> File foo opened with fd 3
Temporary breakpoint 3 at 0x5555555587da
---> File bar opened with fd 0
Common debugging issues
▶ 在调试时可能会遇到一些问题,如不好的地址-> 符号转换、"optimized out"值或函数、空的调用栈
▶ 下面是一个checklist,可以帮助介绍一些问题解决时间:
- 确保启动的二进制文件包含debug symbols:使用gcc时,确保使用
-g,在使用gdb是确保使用non-stripped版本的二进制文件 - 可能的话,在最终的二进制文件中禁用optimizations或使用侵入性较小的级别(
-Og)- 例如,静态函数可以根据优化级别折叠进调用者,因此它们可能会从调用栈丢失
- 避免因为重用帧指针寄存器导致代码优化:使用GCC,确保使用
-fno-omit-frame-pointer- 不仅仅用于调试:很多profiling/tracing工具也会依赖调用栈
▶ 你的应用可能会包含很多库:需要将这些配置应用到所有使用的组件上。
Application Tracing
strace
系统调用 tracer - https://strace.io
▶ 所有GNU/Linux系统可用,可以通过交叉编译工具链或构建系统构建该工具
▶ 可以查看系统正在执行的内容:访问文件、分配内存,适用于查找简单的问题
▶ 用法:
strace <command>: 启动一个新的进程strace -f <command>: 同时tracing子进程strace -p <pid>: tracing一个已有的进程strace -c <command>: 统计每个系统调用信息strace -e <expr> <command>: 使用高级过滤表达式
更多信息查看strace手册
strace example output
> strace cat Makefile
[...]
fstat64(3, {st_mode=S_IFREG|0644, st_size=111585, ...}) = 0
mmap2(NULL, 111585, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7f69000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/tls/i686/cmov/libc.so.6", O_RDONLY) = 3
read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0\320h\1\0004\0\0\0\344"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0755, st_size=1442180, ...}) = 0
mmap2(NULL, 1451632, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7e06000
mprotect(0xb7f62000, 4096, PROT_NONE) = 0
mmap2(0xb7f66000, 9840, PROT_READ|PROT_WRITE,
MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb7f66000
close(3) = 0
[...]
openat(AT_FDCWD, "Makefile", O_RDONLY) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=173, ...}, AT_EMPTY_PATH) = 0
fadvise64(3, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
mmap(NULL, 139264, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f7290d28000
read(3, "ifneq ($(KERNELRELEASE),)\nobj-m "..., 131072) = 173
write(1, "ifneq ($(KERNELRELEASE),)\nobj-m "..., 173ifneq ($(KERNELRELEASE),)
strace -c example output
> strace -c cheese
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
36.24 0.523807 19 27017 poll
28.63 0.413833 5 75287 115 ioctl
25.83 0.373267 6 63092 57321 recvmsg
3.03 0.043807 8 5527 writev
2.69 0.038865 10 3712 read
2.14 0.030927 3 10807 getpid
0.28 0.003977 1 3341 34 futex
0.21 0.002991 3 1030 269 openat
0.20 0.002889 2 1619 975 stat
0.18 0.002534 4 568 mmap
0.13 0.001851 5 356 mprotect
0.10 0.001512 2 784 close
0.08 0.001171 3 461 315 access
0.07 0.001036 2 538 fstat
...
ltrace
用于tracing一个程序使用的共享库,以及它接收到的所有信号。
▶ 可以很好地补充strace,后者仅展示了系统调用
▶ 及时没有源库也能运作
▶ 允许通过正则表达式过滤或函数名称列表库调用
▶ 通过-S选项可以展示系统调用
▶ 通过-c选项可以展示摘要
▶ 手册
▶ 用 glibc 效果更好
更多信息查看 https://en.wikipedia.org/wiki/Ltrace
ltrace example output
# ltrace ffmpeg -f video4linux2 -video_size 544x288 -input_format mjpeg -i /dev
/video0 -pix_fmt rgb565le -f fbdev /dev/fb0
__libc_start_main([ "ffmpeg", "-f", "video4linux2", "-video_size"... ] <unfinished ...>
setvbuf(0xb6a0ec80, nil, 2, 0) = 0
av_log_set_flags(1, 0, 1, 0) = 1
strchr("f", ':') = nil
strlen("f") = 1
strncmp("f", "L", 1) = 26
strncmp("f", "h", 1) = -2
strncmp("f", "?", 1) = 39
strncmp("f", "help", 1) = -2
strncmp("f", "-help", 1) = 57
strncmp("f", "version", 1) = -16
strncmp("f", "buildconf", 1) = 4
strncmp("f", "formats", 1) = 0
strlen("formats") = 7
strncmp("f", "muxers", 1) = -7
strncmp("f", "demuxers", 1) = 2
strncmp("f", "devices", 1) = 2
strncmp("f", "codecs", 1) = 3
...
ltrace summary
使用-c选项:
% time seconds usecs/call calls function
------ ----------- ----------- --------- --------------------
52.64 5.958660 5958660 1 __libc_start_main
20.64 2.336331 2336331 1 avformat_find_stream_info
14.87 1.682895 421 3995 strncmp
7.17 0.811210 811210 1 avformat_open_input
0.75 0.085290 584 146 av_freep
0.49 0.055150 434 127 strlen
0.29 0.033008 660 50 av_log
0.22 0.025090 464 54 strcmp
0.20 0.022836 22836 1 avformat_close_input
0.16 0.017788 635 28 av_dict_free
0.15 0.016819 646 26 av_dict_get
0.15 0.016753 440 38 strchr
0.13 0.014536 581 25 memset
...
------ ----------- ----------- --------- --------------------
100.00 11.318773 4762 total
LD_PRELOAD
Shared libraries
▶ 大部分共享库是以.so结尾的ELF文件
- 启动时被
ld.so加载(动态加载器) - 或在运行时通过通过
dlopen()加载
▶ 当启动一个程序时(ELF文件),内核会解析该文件并加载对应的解析器
- 大部分情况下,ELF文件的
PT_INTERP程序首部被设置为ld-linux.so
▶ 在加载期间,动态链接器ld.so会解析动态库中的所有符号
▶ 动态库只会被OS加载一次,然后映射到所有使用这些库的应用中
- 便于降低使用库所需的内存
Hooking Library Calls
▶ 为了执行更复杂的库调用钩子,可以使用LD_PRELOAD环境变量
▶ LD_PRELOAD用于指定一个可以在动态加载器加载其他库之前需要加载的共享库
▶ 可以通过预加载另一个库来拦截所有库调用
- 覆盖相同名称的库符号
- 允许重定义一小部分符号
- 可以通过
dlsym(man 3 dlsym)加载"真实"的符号
▶ 调试/tracing库(libsegfault, libefence)会使用该环境变量
▶ C和C++都可以使用
LD_PRELOAD example
▶ 使用LD_PRELOAD预加载期望的库
#include <string.h>
#include <unistd.h>
ssize_t read(int fd, void *data, size_t size) {
memset(data, 0x42, size);
return size;
}
▶ 使用LD_PRELOAD下的库编译:
$ gcc -shared -fPIC -o my_lib.so my_lib.c
▶ 使用LD_PRELOAD预加载新的库
$ LD_PRELOAD=./my_lib.so ./exe
uprobes and perf
uprobes
▶ uprobe是内核提供的可以tracing用户空间代码的一种机制
▶ 可以在任何用户空间符号中动态添加tracepoints
- 内核tracing系统会在
.textsection中打上断点
▶ 通过/sys/kernel/debug/tracing/uprobe_events暴露tracing信息
▶ 通常会被perf, bcc等工具封装使用
The perf tool
▶ perf工具是一个使用性能计数器采集应用profile信息的工具 (man 1 perf)
▶ 还可以管理tracepoints, kprobes 和 uprobes
▶ perf可以同时在用户空间和内核空间执行profile
▶ perf基于内核暴露的perf_event接口
▶ 提供了一组操作,每个操作有特定的参数
stat,record,report,top,annotate,ftrace,list,probe等
Using perf record
▶ perf可以记录基于线程、进程和CPU的性能
▶ 只用时需要内核配置 CONFIG_PERF_EVENTS=y选项
▶ 需要从程序执行中采集数据,并输出到perf.data文件中
▶ 可以通过perf annotate 和 perf report分析perf.data文件
- 可以在其他计算机上对嵌入式系统进行分析
Probing userspace functions
▶ 列出可在特定可执行文件中探测的函数
$ perf probe --source=<source_dir> -x my_app -F
▶ 列出可在特定可执行文件/函数中探测的行数
$ perf probe --source=<source_dir> -x my_app -L my_func
▶ 在用户空间库/可执行文件的函数中创建uprobes
$ perf probe -x /lib/libc.so.6 printf
$ perf probe -x app my_func:3 my_var
$ perf probe -x app my_func%return ret=%r0
▶ 记录执行的tracepoints
$ perf record -e probe_app:my_func -e probe_libc:printf
Memory issues
Usual Memory Issues
▶ 程序几乎都需要访问内存
▶ 如果操作不当,可能会产生大量错误
- 当访问无效内存时可能会产生段错误(访问NULL指针或被释放的内存)
- 如果访问了缓冲之外的地址可能会产生缓冲溢出
- 申请内存之后忘了释放会产生内存泄漏
Segmentation Faults
▶ 当程序尝试访问一个不允许访问的内存区域,或以一种错误的方式访问了一个内存区域时,内核会产生段错误:
- 如写入一个只读内存区域
- 尝试执行一段无法执行的内存
int *ptr = NULL;
*ptr = 1;
▶ 产生段错误时,会在终端显示Segmentation fault
$ ./program
Segmentation fault
Buffer Overflows
▶ 当访问数组越界时会产生缓冲溢出
▶ 在以下场景中,根据访问情况可能会也可能不会导致程序崩溃:
- 在
malloc ()的数组末尾之后写入数据通常会覆盖malloc的数据结构,导致崩溃 - 在栈上申请的数组末尾之后写入数据会损坏栈数据
- 读取数据末尾之后的数据并不总是会产生段错误,具体取决于访问的内存区域
uint32_t *array = malloc(10 * sizeof(*array));
array[10] = 0xDEADBEEF;
Memory Leaks
▶ 内存泄露是一种不会触发程序崩溃(但迟早会),但会消耗系统内存的一种错误
▶ 这种情况发生在为程序申请了内存,但忘了释放这段内存
▶ 在生产环境中可能运行很长时间才会被发现
- 最好在开发阶段提早发现此类问题
void func1(void) {
uint32_t *array = malloc(10 * sizeof(*array));
do_something_with_array(array);
}
Valgrind memcheck
Valgrind
▶ Valgrind是一个用于构建动态分析工具的工具框架
▶ Valgrind本身也是一个基于该框架的工具,提供了内存错误检测、heap profile和其他profile功能
▶ 支持所有流行的平台:Linux on x86, x86_64, arm(仅armv7), arm64, mips32, s390, ppc32 和 ppc64
▶ 可以将其添加到你的代码并运行在其虚拟CPU core上。大大减慢了执行速度,因此适合于调试和分析
▶ Memcheck是默认的valgrind工具,可以检测内存管理错误:
- 访问无效的内存区域,使用未初始化的值、内存泄露、错误释放堆块等
- 可以运行在任何应用中,无需编译
$ valgrind --tool=memcheck --leak-check=full <program>
Valgrind Memcheck usage and report
$ valgrind ./mem_leak
==202104== Memcheck, a memory error detector
==202104== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==202104== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info
==202104== Command: ./mem_leak
==202104==
==202104== Conditional jump or move depends on uninitialised value(s)
==202104== at 0x109161: do_actual_jump (in /home/user/mem_leak)
==202104== by 0x109187: compute_address (in /home/user/mem_leak)
==202104== by 0x1091A2: do_jump (in /home/user/mem_leak)
==202104== by 0x1091D7: main (in /home/user/mem_leak)
==202104==
==202104== HEAP SUMMARY:
==202104== in use at exit: 120 bytes in 1 blocks
==202104== total heap usage: 1 allocs, 0 frees, 120 bytes allocated
==202104==
==202104== LEAK SUMMARY:
==202104== definitely lost: 120 bytes in 1 blocks
==202104== indirectly lost: 0 bytes in 0 blocks
==202104== possibly lost: 0 bytes in 0 blocks
==202104== still reachable: 0 bytes in 0 blocks
==202104== suppressed: 0 bytes in 0 blocks
==202104== Rerun with --leak-check=full to see details of leaked memory
Valgrind and VGDB
▶ Valgrind还可以作为一个接收处理命令的GDB server。用户可以通过gdb客户端或vgdb与valgrind gdb server进行交互。vgdb可以用于如下场景:
- 作为一个独立的CLI程序,向valgrind发送"monitor"命令
- 作为gdb客户端和已存在的valgrind会话之间的中继器
- 作为一个server,处理来自远端gdb客户端的多个valgrind会话
▶ 更多参见man 1 vgdb
Using GDB with Memcheck
▶ valgrind可以将GDB attach到正在分析的进程上
$ valgrind --tool=memcheck --leak-check=full --vgdb=yes --vgdb-error=0 ./mem_leak
▶ 然后将gdb attach到使用vdgb的 valgrind gdbserver上
$ gdb ./mem_leak
(gdb) target remote | vgdb
▶ 如果valgrind检测到一个错误,它会停止执行并进入GDB
(gdb) continue
Continuing.
Program received signal SIGTRAP, Trace/breakpoint trap.
0x0000000000109161 in do_actual_jump (p=0x4a52040) at mem_leak.c:5
5 if (p[1])
(gdb) bt
#0 0x0000000000109161 in do_actual_jump (p=0x4a52040) at mem_leak.c:5
#1 0x0000000000109188 in compute_address (p=0x4a52040) at mem_leak.c:11
#2 0x00000000001091a3 in do_jump (p=0x4a52040) at mem_leak.c:16
#3 0x00000000001091d8 in main () at mem_leak.c:27
Electric Fence
libefence
▶ libefence是一个比valgrind更加轻量的应用,但精度也相对较低
▶ 可以捕获两种常见的内存错误
- 缓冲溢出和使用释放的内存
▶ libefence可以在遇到第一个错误后触发段错误,生成coredump
▶ 可以使用静态链接或使用LD_PRELOAD方式预加载libefence共享库
$ gcc -g program.c -o program
$ LD_PRELOAD=libefence.so.0.0 ./program
Electric Fence 2.2 Copyright (C) 1987-1999 Bruce Perens <bruce@perens.com>
Segmentation fault (core dumped)
▶ 根据段错误,可以在当前目录生成一个coredump
▶ 可以使用GDB打开该coredump,并定位到发生错误的位置
$ gdb ./program core-program-3485
Reading symbols from ./libefence...
[New LWP 57462]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Core was generated by `./libefence'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 main () at libefence.c:8
8 data[99] = 1;
(gdb)
Application Profiling
Profiling
▶ Profiling是一个为了通过分析程序、优化程序或修复程序问题而从程序运行中收集数据的动作
▶ 可以通过在代码中观插入instrumentation或利用内核/用户空间机制来实现profiling
- profile函数调用和调用次数,以此来优化性能
- profile处理器使用情况来优化性能并降低使用的电量
- profile内存使用情况来优化使用的内存
▶ 在profiling之后,需要使用数据来分析潜在的提升点
Performance issues
▶ profiling通常用于确定和修复性能问题
▶ 内存使用、IOs负载或CPU使用等都会影响性能
▶ 在修复性能问题前最好能够采集profiling数据
▶ profiling时,通常首次会使用一些典型工具进行粗粒度的定位
▶ 一旦确定了问题类型,就可以进行细粒度的profiling
Profiling metrics
▶ 可以通过多种具来采集profile指标
▶ 使用Massif, heaptrack 或 memusage来profile内存使用
▶ 使用perf和callgrind来profile函数调用
▶ 使用perf来profile CPU硬件使用(Cache、MMU等)
▶ profiling的数据可以同时包含用户空间应用和内核数据
Visualizing data with flamegraphs
▶ 基于堆栈的可视化
▶ 可以快速找到性能瓶颈以及浏览调用栈
▶ Brendan Gregg工具(因该工具而流行)可以为perf结果生成火焰图
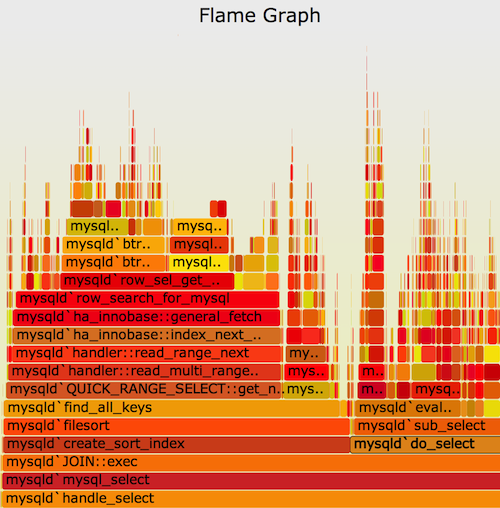
Going further with Flamegraphs
▶ 更多参见如下内容(Brendann Gregg的技术演讲,展示了火焰图中的各种指标的用法):
Memory profiling
▶ profiling应用的内存使用(堆/栈)有助于优化性能
▶ 申请过多的内存可能会导致系统内存耗尽
▶ 频繁申请/释放内存会导致内核花费大量时间执行 clear_page()
- 内核需要在将内存页交给进程前清理内存页,避免数据泄露
▶ 降低应用内存占用空间可以优化缓存使用,如page miss
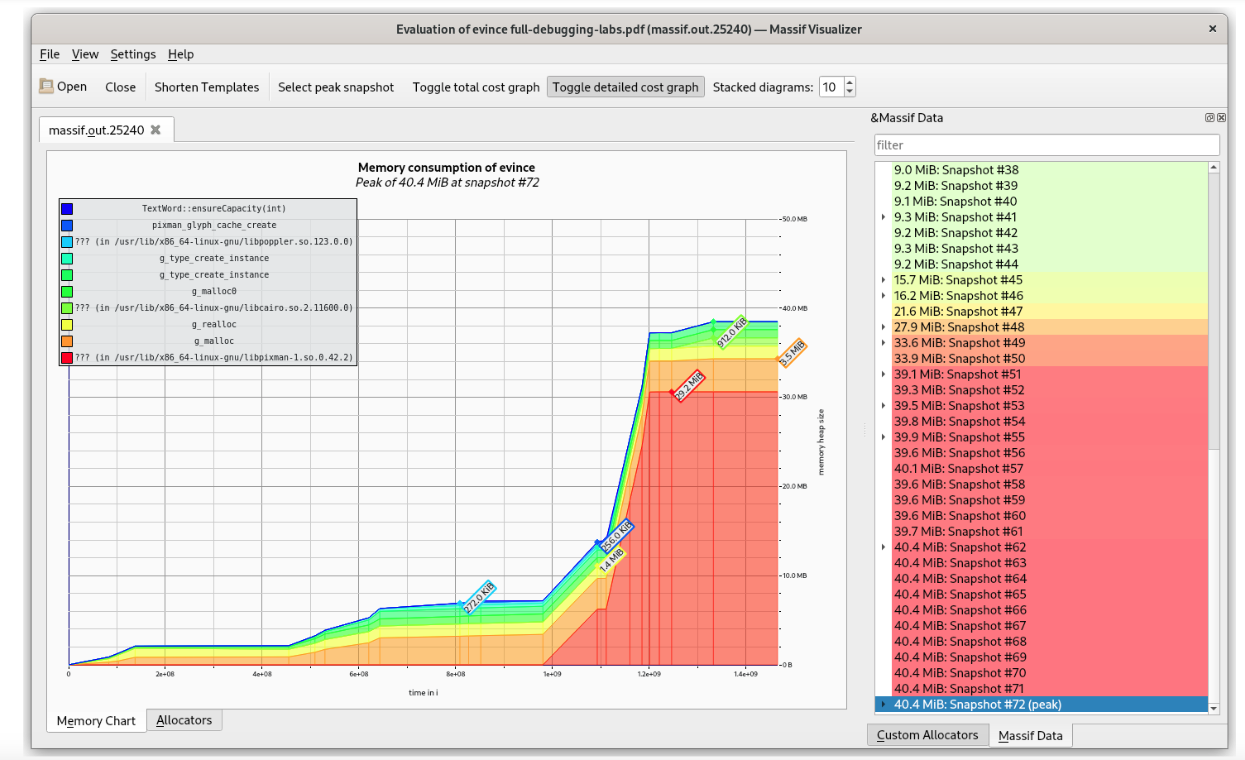
Massif usage
▶ Massif是一个valgrind提供的工具,可以在程序执行时profile堆使用(仅用于用户空间)
▶ 原理为创建内存申请快照:
$ valgrind --tool=massif --time-unit=B program
▶ 一旦执行,会在当前目录生成一个 massif.out.<pid> 文件
▶ 然后可以使用ms_print工具展示堆分配图:
$ ms_print massif.out.275099
▶ #: 最高内存申请
▶ @: 快照细节 (可以通过 --detailed-freq调节数目)
Massif report

massif-visualizer - Visualizing massif profiling data
heaptrack usage
▶ heaptrack是一个堆内存profile工具
- 需要用到
LD_PRELOAD库
▶ 具有比Massif更好的tracing和可视化能力
- 每个内存申请都会关联到一个栈
- 可以发现内存泄露、内存申请热点和临时申请的内存
▶ 可以通过GUI (heaptrack_gui) 或 CLI 工具 (heaptrack_print)查看结果
▶ https://github.com/KDE/heaptrack
$ heaptrack program
▶ 最后生成一个heaptrack.<process_name>.<pid>.zst文件,可以在另外一台计算机上使用heaptrack_gui查看分析
heaptrack_gui - Visualizing heaptrack profiling data
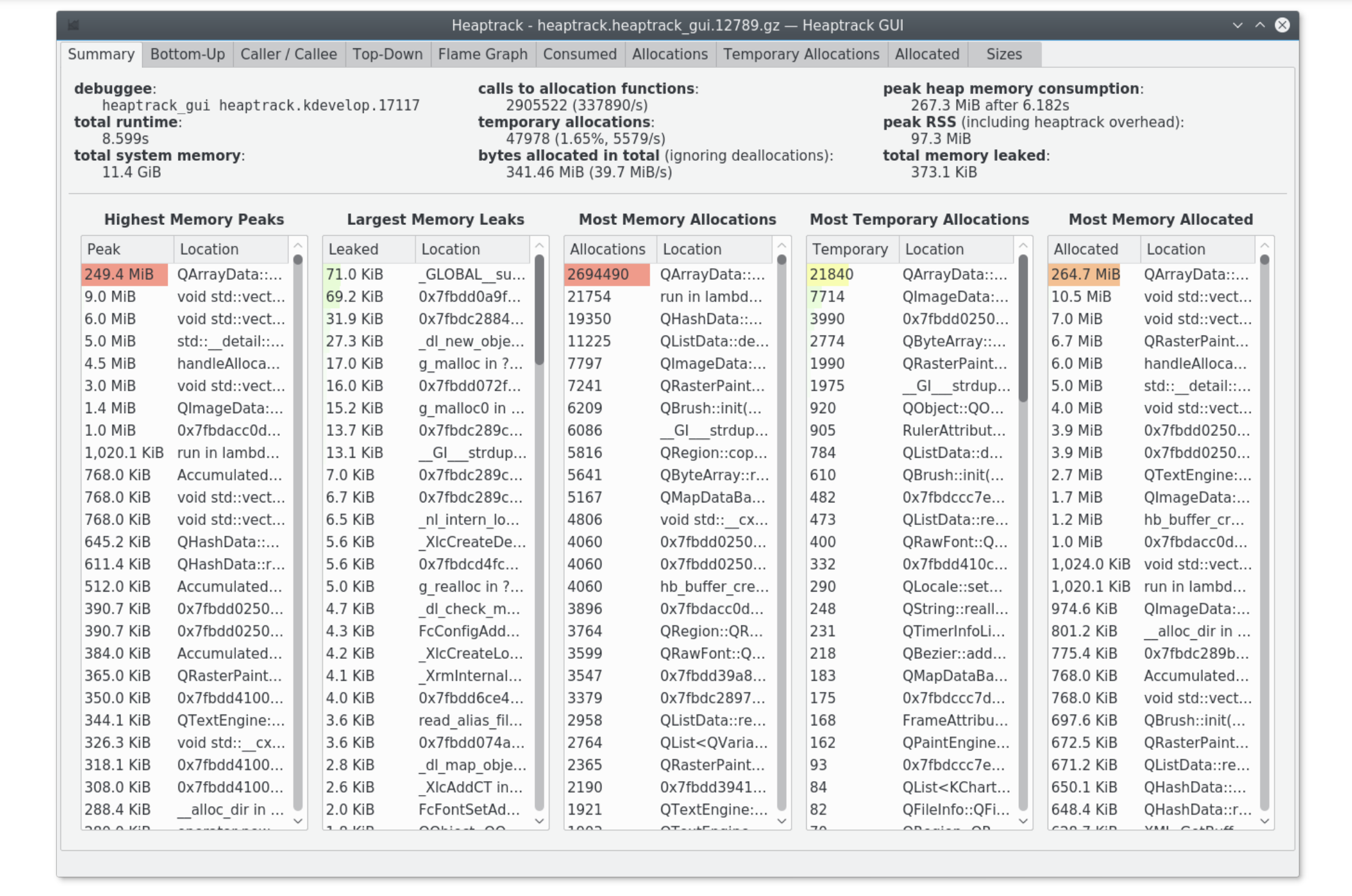
heaptrack_gui - Flamegraph view
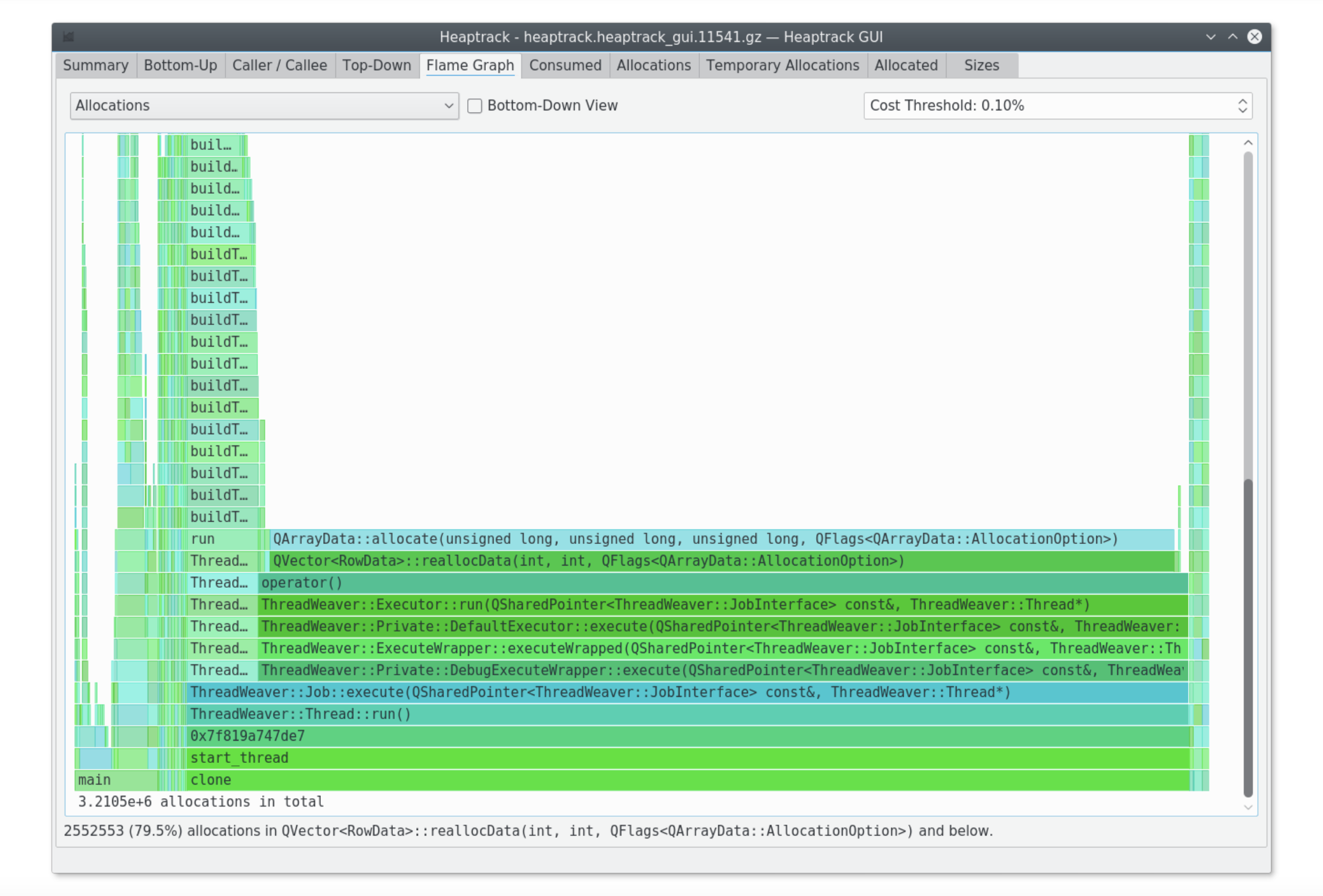
memusage
▶ memusage是一个使用libmemusage.so profile 内存使用的程序(man 1 memusage) (仅用户空间)
▶ 可以profile heap、stack以及mmap的内存使用
▶ 可以在终端显示profile信息,也可以输出到一个文件或一个PGN文件中
▶ 相比valgrind Massif来说,它更轻量(由于使用了LD_PRELOAD机制)
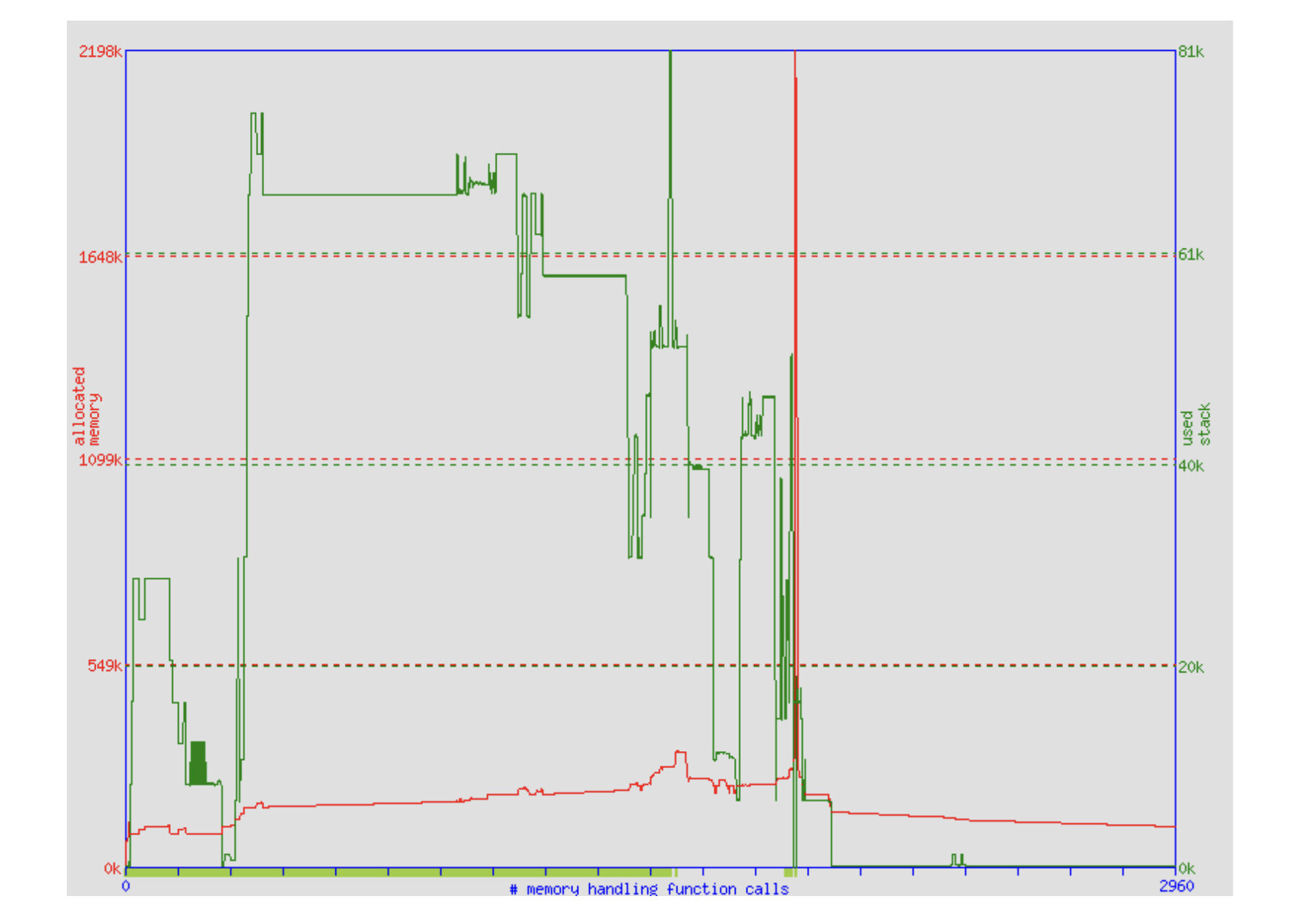
memusage usage
$ memusage convert foo.png foo.jpg
Memory usage summary: heap total: 2635857, heap peak: 2250856, stack peak: 83696
total calls total memory failed calls
malloc| 1496 2623648 0
realloc| 6 3744 0 (nomove:0, dec:0, free:0)
calloc| 16 8465 0
free| 1480 2521334
Histogram for block sizes:
0-15 329 21% ==================================================
16-31 239 15% ====================================
32-47 287 18% ===========================================
48-63 321 21% ================================================
64-79 43 2% ======
80-95 141 9% =====================
...
21424-21439 1 <1%
32768-32783 1 <1%
32816-32831 1 <1%
large 3 <1%
Execution profiling
▶ 为了优化程序,需要理解程序使用了哪些硬件资源
▶ 很多硬件元素可能会影响程序运行
- 如果应用没有考虑内存空间局部性,则可能会导致CPU缓存性能下降
- 如果应用没有考虑内存空间局部性,则会导致缓存miss
- 执行不对齐访问时会产生对齐错误
Using perf stat
▶ perf stat可以通过采集性能计数器来profile一个应用
- 使用性能计数器可能需要root权限,可以通过
# echo -1 > /proc/sys/kernel/perf_event_paranoid修改
▶ 硬件上的性能计数器的数目通常有限
▶ 采集过多数据可能会导致多路复用,perf会放大结果
▶ 采集性能计数器然后进行估算:
- 为获取更精确的数值,需要降低event数目并通过多次执行
perf来修改期望观测的events集 - 更多参见 perf wiki
perf stat example
$ perf stat convert foo.png foo.jpg
Performance counter stats for 'convert foo.png foo.jpg':
45,52 msec task-clock # 1,333 CPUs utilized
4 context-switches # 87,874 /sec
0 cpu-migrations # 0,000 /sec
1 672 page-faults # 36,731 K/sec
146 154 800 cycles # 3,211 GHz (81,16%)
6 984 741 stalled-cycles-frontend # 4,78% frontend cycles idle (91,21%)
81 002 469 stalled-cycles-backend # 55,42% backend cycles idle (91,36%)
222 687 505 instructions # 1,52 insn per cycle
# 0,36 stalled cycles per insn (91,21%)
37 776 174 branches # 829,884 M/sec (74,51%)
567 408 branch-misses # 1,50% of all branches (70,62%)
0,034156819 seconds time elapsed
0,041509000 seconds user
0,004612000 seconds sys
▶ 注意:末尾的百分比是内核计算多路复用情况下的event的持续时间
▶ 列出所有event:
$ perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
...
▶ 统计特定命令的L1-dcache-load-misses 和 branch-load-misses事件:
$ perf stat -e L1-dcache-load-misses,branch-load-misses cat /etc/fstab
...
Performance counter stats for 'cat /etc/fstab':
23 418 L1-dcache-load-misses
7 192 branch-load-misses
...
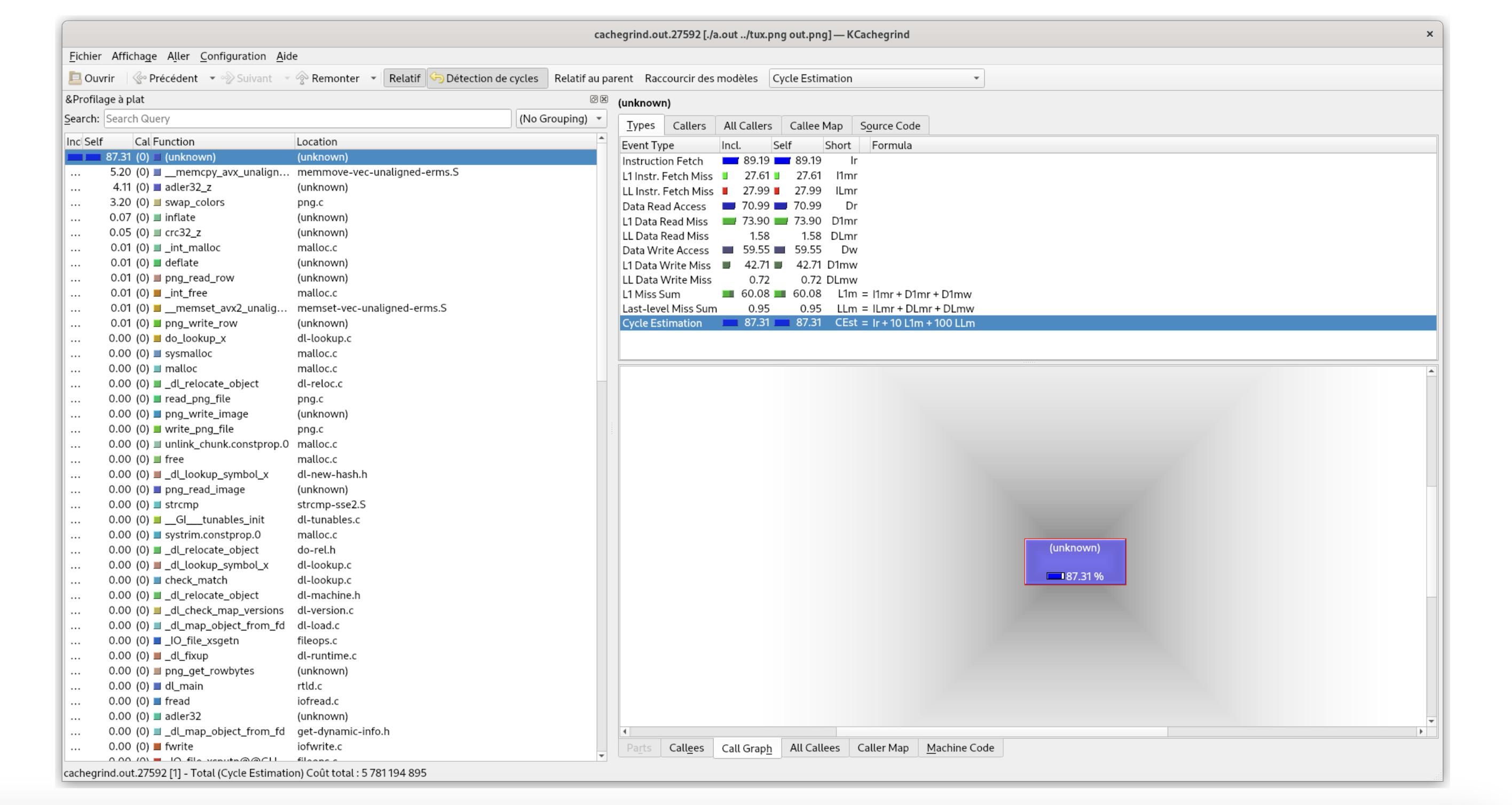
Cachegrind
▶ Cachegrind是一个valgrind提供的用于profile应用指令和数据缓存层级的工具
- Cachegrind还可以profile分支预测成功
▶ 可以模拟一台具有独立 I$和 D$支持的机器,该机器具有统一的 L2缓存
▶ 非常有助于检测缓存使用问题(过多miss等)
$ valgrind --tool=cachegrind --cache-sim=yes ./my_program
▶ 会生成一个包含测量结果的cachegrind.out.<pid>文件
▶ cg_annotate是一个用于展示Cachegrind仿真结果的CLI工具
▶ 它还可以通过--diff选项对比两个测量结果文件。
▶ cachegrind的缓存仿真存在一些精度缺陷,参见 Cachegrind accuracy
Kcachegrind - Visualizing Cachegrind profiling data
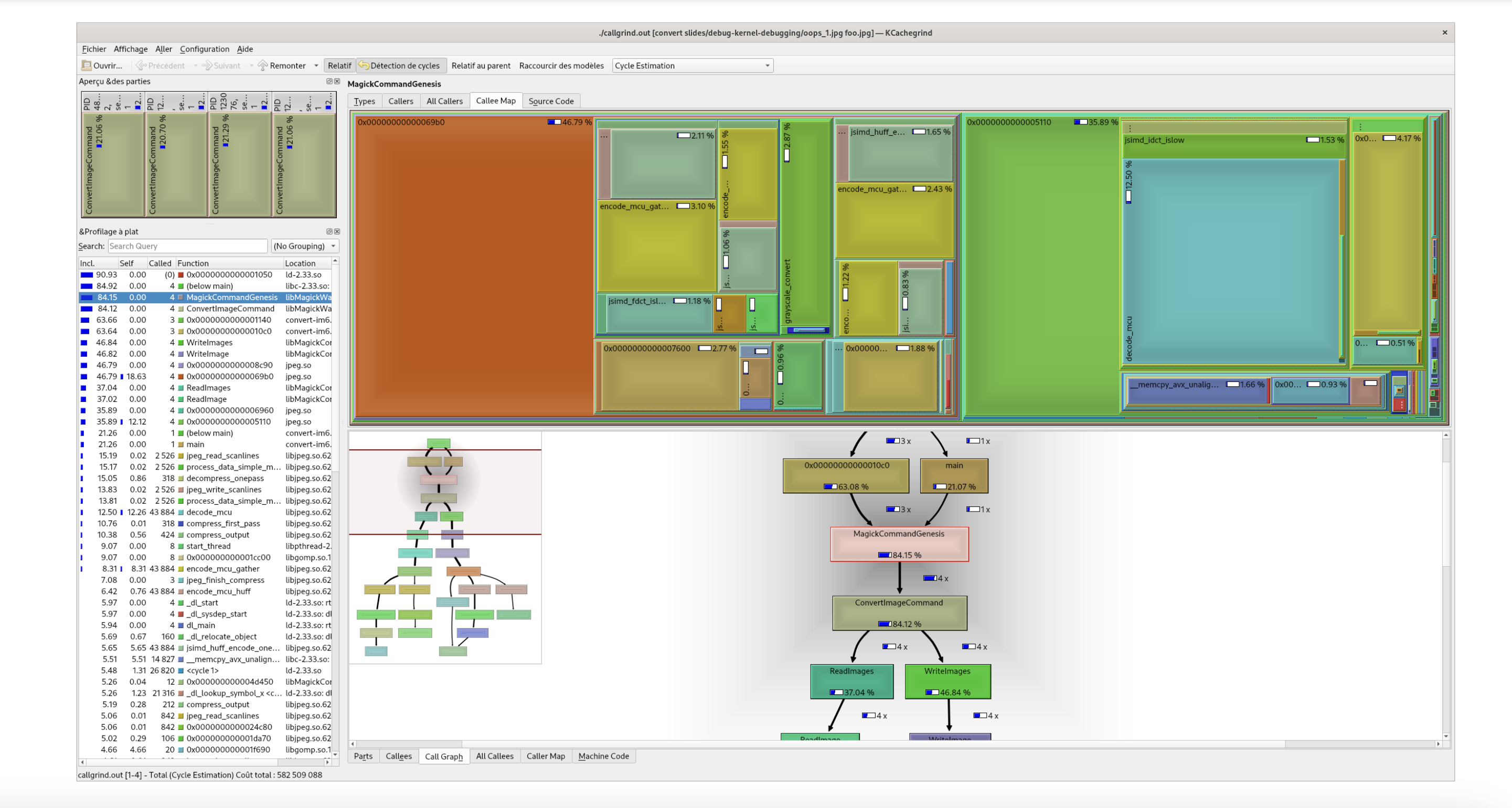
Callgrind
▶ Callgrind是valgrind提供的一种可以profile调用图的工具(仅用户空间)
▶ 可以在程序执行时采集指令数目和与数据相关的源代码行
▶ 记录函数和函数有关的调用次数:
$ valgrind --tool=callgrind ./my_program
▶ callgrind_annotate 是一个可以展示callgrind仿真结果的CLI工具
▶ Kcachegrind也可以展示callgrind的结果
Kcachegrind - Visualizing Callgrind profiling data
System-wide Profiling & Tracing
▶ 优势问题的根因并不仅限于应用本身,可能会涉及到多个层面(驱动、应用、内核)
▶ 这种情况下,需要分析整个栈
▶ 内核提供了大量可以被特定工具记录的tracepoints
▶ 可以通过各种机制(如kprobes)来静态或动态地创建新的tracepoints
Kprobes
▶ Kprobes几乎可以在任何内核地址动态插入断点,并抽取调试和性能信息
▶ 通过代码补丁的方式在文本代码中插入调用特定的handler的方法
kprobes可以在执行hooked指令(即需要调试的指令)时执行特定的handler- 当从一个函数返回时会触发
kretprobes抽取函数的返回值,以及函数调用的参数
▶ 需要启用内核选项CONFIG_KPROBES=y
▶ 由于需要通过模块插入探针,因此需要启用选项CONFIG_MODULES=y 和 CONFIG_MODULE_UNLOAD=y来允许注册探针
▶ 当使用symbol_name字段hooking探针时需要启用CONFIG_KALLSYMS_ALL=y选项
▶ 更多参见trace/kprobes
Registering a Kprobe
▶ 可以通过加载模块的方式动态注册kprobes,即通过register_kprobe()注册一个struct kprobe
▶ 在模块退出时需要通过unregister_kprobe()取消注册的探针:
struct kprobe probe = {
.symbol_name = "do_exit",
.pre_handler = probe_pre,
.post_handler = probe_post,
};
register_kprobe(&probe);
Registering a kretprobe
▶ kretprobe的注册方式与普通探针的注册方式相同,区别是需要通过 register_kretprobe()注册一个struct kretprobe
- 在函数进入和退出时会调用提供的handler
- 在模块退出时需要通过unregister_kretprobe()取消注册的探针
int (*kretprobe_handler_t) (struct kretprobe_instance *, struct pt_regs *);
struct kretprobe probe = {
.kp.symbol_name = "do_fork",
.entry_handler = probe_entry,
.handler = probe_exit,
};
register_kretprobe(&probe);
perf
▶ perf可以执行更大范围的tracing,并记录操作
▶ 内核已经包含了可以使用的events和tracepoints,可以通过perf list列出这些内容
▶ 需要通过CONFIG_FTRACE_SYSCALLS启用syscall tracepoints
▶ 在缺少调试信息时,可以在所有符号和寄存器上动态创建新的tracepoint
▶ tracing函数会使用它们的名称记录变量和参数内容。需要开启内核选项CONFIG_DEBUG_INFO
▶ 如果perf无法找到vmlinux,则需要通过-k <vmlinux>提供此文件。
perf example
▶ 展示匹配syscalls:*的所有events:
$ perf list syscalls:*
List of pre-defined events (to be used in -e):
syscalls:sys_enter_accept [Tracepoint event]
syscalls:sys_enter_accept4 [Tracepoint event]
syscalls:sys_enter_access [Tracepoint event]
syscalls:sys_enter_adjtimex_time32 [Tracepoint event]
syscalls:sys_enter_bind [Tracepoint event]
...
▶ 在perf.data文件中记录执行sha256sum命令产生的syscalls:sys_enter_read事件:
$ perf record -e syscalls:sys_enter_read sha256sum /bin/busybox
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.018 MB perf.data (215 samples) ]
perf report example
▶ 按照花费的时间展示采集的样本:
$ perf report
Samples: 591 of event 'cycles', Event count (approx.): 393877062
Overhead Command Shared Object Symbol
22,88% firefox-esr [nvidia] [k] _nv031568rm
3,21% firefox-esr ld-linux-x86-64.so.2 [.] __minimal_realloc
2,00% firefox-esr libc.so.6 [.] __stpncpy_ssse3
1,86% firefox-esr libglib-2.0.so.0.7400.0 [.] g_hash_table_lookup
1,62% firefox-esr ld-linux-x86-64.so.2 [.] _dl_strtoul
1,56% firefox-esr [kernel.kallsyms] [k] clear_page_rep
1,52% firefox-esr libc.so.6 [.] __strncpy_sse2_unaligned
1,37% firefox-esr ld-linux-x86-64.so.2 [.] strncmp
1,30% firefox-esr firefox-esr [.] malloc
1,27% firefox-esr libc.so.6 [.] __GI___strcasecmp_l_ssse3
1,23% firefox-esr [nvidia] [k] _nv013165rm
1,09% firefox-esr [nvidia] [k] _nv007298rm
1,03% firefox-esr [kernel.kallsyms] [k] unmap_page_range
0,91% firefox-esr ld-linux-x86-64.so.2 [.] __minimal_free
perf probe
▶ 通过perf probe可以在内核函数和用户空间函数中创建动态tracepoints
▶ 为了插入探针,需要在内核中启用CONFIG_KPROBES
- 注意:使用perf探针时需要编译libelf文件
▶ 在创建新的动态探针之后就可以在perf record中使用此探针
▶ 嵌入式平台中通常不存在vmlinux,此时只能使用符号和寄存器
perf probe examples
▶ 列出所有可以被探测的内核符号:
$ perf probe --funcs
▶ 使用filename参数在do_sys_openat2上创建一个新的探针:
$ perf probe --vmlinux=vmlinux_file do_sys_openat2 filename:string
Added new event:
probe:do_sys_openat2 (on do_sys_openat2 with filename:string)
▶ 执行tail并捕获前面创建的探针事件:
$ perf record -e probe:do_sys_openat2 tail /var/log/messages
...
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.003 MB perf.data (19 samples) ]
▶ 使用perf script展示记录的tracepoint:
$ perf script
tail 164 [000] 3552.956573: probe:do_sys_openat2: (c02c3750) filename_string="/etc/ld.so.cache"
tail 164 [000] 3552.956642: probe:do_sys_openat2: (c02c3750) filename_string="/lib/tls/v7l/neon/vfp/libresolv.so.2"
...
▶ 在ksys_read上创建新的探针,并使用r0(ARM)返回值(赋给ret):
$ perf probe ksys_read%return ret=%r0
▶ 执行sha256sum并捕获前面创建的探针事件:
$ perf record -e probe:ksys_read__return sha256sum /etc/fstab
▶ 展示创建的所有探针:
$ perf probe -l
probe:ksys_read__return (on ksys_read%return with ret)
▶ 移除一个已存在的tracepoint:
$ perf probe -d probe:ksys_read__return
perf record example
▶ 记录所有的CPU events(系统模式)
$ perf record -a
^C
▶ 使用perf script展示perf.data记录的events
$ perf script
...
klogd 85 [000] 208.609712: 116584 cycles: b6dd551c memset+0x2c (/lib/libc.so.6)
klogd 85 [000] 208.609898: 121267 cycles: c0a44c84 _raw_spin_unlock_irq+0x34 (vmlinux)
klogd 85 [000] 208.610094: 127434 cycles: c02f3ef4 kmem_cache_alloc+0xd0 (vmlinux)
perf 130 [000] 208.610311: 132915 cycles: c0a44c84 _raw_spin_unlock_irq+0x34 (vmlinux)
perf 130 [000] 208.619831: 143834 cycles: c0a44cf4 _raw_spin_unlock_irqrestore+0x3c (vmlinux)
klogd 85 [000] 208.620048: 143834 cycles: c01a07f8 syslog_print+0x170 (vmlinux)
klogd 85 [000] 208.620241: 126328 cycles: c0100184 vector_swi+0x44 (vmlinux)
klogd 85 [000] 208.620434: 128451 cycles: c096f228 unix_dgram_sendmsg+0x46c (vmlinux)
kworker/0:2-mm_ 44 [000] 208.620653: 133104 cycles: c0a44c84 _raw_spin_unlock_irq+0x34 (vmlinux)
perf 130 [000] 208.620859: 138065 cycles: c0198460 lock_acquire+0x184 (vmlinux)
...
Using perf trace
▶ perf trace可以捕获和展示在执行命令时触发的所有tracepoints/events。
$ perf trace -e "net:*" ping -c 1 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
0.000 ping/37820 net:net_dev_queue(skbaddr: 0xffff97bbc6a17900, len: 98, name: "enp34s0")
0.005 ping/37820 net:net_dev_start_xmit(name: "enp34s0",
skbaddr: 0xffff97bbc6a17900, protocol: 2048, len: 98,
network_offset: 14, transport_offset_valid: 1, transport_offset: 34)
0.009 ping/37820 net:net_dev_xmit(skbaddr: 0xffff97bbc6a17900, len: 98,name: "enp34s0")
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.867 ms
Using perf top
▶ perf top可以实时分析内核
▶ 可以采样函数调用,并按照时间消耗排序
▶ 可以profile整个系统:
$ perf top
Samples: 19K of event 'cycles', 4000 Hz, Event count (approx.): 4571734204 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
2,01% [nvidia] [k] _nv023368rm
0,94% [kernel] [k] __static_call_text_end
0,89% [vdso] [.] 0x0000000000000655
0,81% [nvidia] [k] _nv027733rm
0,79% [kernel] [k] clear_page_rep
0,76% [kernel] [k] psi_group_change
0,70% [kernel] [k] check_preemption_disabled
0,69% code [.] 0x000000000623108f
0,60% code [.] 0x0000000006231083
0,59% [kernel] [k] preempt_count_add
0,54% [kernel] [k] module_get_kallsym
0,53% [kernel] [k] copy_user_generic_string
ftrace and trace-cmd
ftrace
▶ ftrace是一个内核tracing框架,为"Function Tracer"的简称
▶ 为观测系统行为提供了广泛的tracing能力
- 可以跟踪已经存在内核中的tracepoints(scheduler、interrupts等)
- 依赖GCC 的mount() 能力和内核代码补丁机制来调用ftrace tracing handler
▶ 所有跟踪数据都保存在一个ring buffer中
▶ 使用tracefs文件系统来控制和展示tracing events
-
# mount -t tracefs nodev /sys/kernel/tracing.
▶ 使用ftrace前必须开启内核选项CONFIG_FTRACE=y
▶ CONFIG_DYNAMIC_FTRACE可以让加入的trace功能在不使用时对系统性能几乎没有影响。
ftrace files
▶ ftrace通过/sys/kernel/tracing中的特定文件来控制跟踪的内容:
current_tracer: 当前使用的traceravailable_tracers: 列出编译进内核的可用tracerstracing_on: 启用/禁用 tracing.trace: 以可读方式展示跟踪。不同的tracer可能会有不同的格式trace_pipe: 与trace类似,但每次读都会消费其读取的跟踪数据trace_marker{_raw}: 可以向跟踪缓冲区中的用户空间同步内核事件set_ftrace_filter: 过滤特定的函数set_graph_function: 以图形方式展示特定的函数的子函数
▶ 还有其他控制跟踪的文件,参见trace/ftrace
▶ 可以使用trace-cmd CLI 和 Kernelshark GUI记录和展示tracing数据
ftrace tracers
▶ ftrace提供了多种"tracers"
▶ 需要将使用的tracer写入current_tracer文件
nop:不执行跟踪,禁用所有tracingfunction:跟踪所有调用的内核函数function_graph:类似function,但会跟踪函数的进入和退出hwlat:跟踪硬件延迟irqsoff:跟踪禁用中断的部分,并记录延迟branch:跟踪likely()/unlikely()分支预测调用mmiotrace:跟踪所有硬件访问(read[bwlq]/write[bwlq])
▶ 警告:有些tracer开销可能会比较大
# echo "function" > /sys/kernel/tracing/current_tracer
function_graph tracer report example
▶ function_graph可以跟踪所有函数及其相关的调用树
▶ 可以展示进程、CPU、时间戳和函数调用图
$ trace-cmd report
...
dd-113 [000] 304.526590: funcgraph_entry: | sys_write() {
dd-113 [000] 304.526597: funcgraph_entry: | ksys_write() {
dd-113 [000] 304.526603: funcgraph_entry: | __fdget_pos() {
dd-113 [000] 304.526609: funcgraph_entry: 6.541 us | __fget_light();
dd-113 [000] 304.526621: funcgraph_exit: + 18.500 us | }
dd-113 [000] 304.526627: funcgraph_entry: | vfs_write() {
dd-113 [000] 304.526634: funcgraph_entry: 6.334 us | rw_verify_area();
dd-113 [000] 304.526646: funcgraph_entry: 6.208 us | write_null();
dd-113 [000] 304.526658: funcgraph_entry: 6.292 us | __fsnotify_parent();
dd-113 [000] 304.526669: funcgraph_exit: + 43.042 us | }
dd-113 [000] 304.526675: funcgraph_exit: + 78.833 us | }
dd-113 [000] 304.526680: funcgraph_exit: + 91.291 us | }
dd-113 [000] 304.526689: funcgraph_entry: | sys_read() {
dd-113 [000] 304.526695: funcgraph_entry: | ksys_read() {
dd-113 [000] 304.526702: funcgraph_entry: | __fdget_pos() {
dd-113 [000] 304.526708: funcgraph_entry: 6.167 us | __fget_light();
dd-113 [000] 304.526719: funcgraph_exit: + 18.083 us | }
irqsoff tracer
▶ ftrace irqsoff tracer可以跟踪由于太长时间禁用中断而导致的中断延迟
▶ 可以帮助定位系统中断延迟高的问题
▶ 需要启用IRQSOFF_TRACER=y
preemptoff,premptirqsofftracer可以跟踪禁用抢占的代码段
irqsoff tracer report example
# latency: 276 us, #104/104, CPU#0 | (M:preempt VP:0, KP:0, SP:0 HP:0 #P:2)
# -----------------
# | task: stress-ng-114 (uid:0 nice:0 policy:0 rt_prio:0)
# -----------------
# => started at: __irq_usr
# => ended at: irq_exit
#
#
# _------=> CPU#
# / _-----=> irqs-off
# | / _----=> need-resched
# || / _---=> hardirq/softirq
# ||| / _--=> preempt-depth
# |||| / delay
# cmd pid ||||| time | caller
# \ / ||||| \ | /
stress-n-114 0d... 2us : __irq_usr
stress-n-114 0d... 7us : gic_handle_irq <-__irq_usr
stress-n-114 0d... 10us : __handle_domain_irq <-gic_handle_irq
...
stress-n-114 0d... 270us : __local_bh_disable_ip <-__do_softirq
stress-n-114 0d.s. 275us : __do_softirq <-irq_exit
stress-n-114 0d.s. 279us+: tracer_hardirqs_on <-irq_exit
stress-n-114 0d.s. 290us : <stack trace>
Hardware latency detector
▶ ftrace hwlat tracer 可以帮助查找硬件是否产生延迟
- 如,不可屏蔽的系统管理中断会直接触发某些固件支持特性,导致CPU暂停执行
- 某些安全监控产生的中断也可能会导致延迟
▶ 如果使用该tracer发现了某种延迟,说明该系统可能不适合实时用途
▶ 原理为在禁用中断的情况下在单核上循环执行指令,并计算连续的两次读之间的时间差
▶ 需要启用CONFIG_HWLAT_TRACER=y
trace_printk()
▶ Utrace_printk()可以向跟踪缓存中输出字符串
▶ 可以跟踪代码中的特定条件并将其展示在跟踪缓存中:
#include <linux/ftrace.h>
void read_hw()
{
if (condition)
trace_printk("Condition is true!\n");
}
▶ 在跟踪缓存中使用function_graph tracer展示如下结果:
1) | read_hw() {
1) | /* Condition is true! */
1) 2.657 us | }
trace-cmd
▶ trace-cmd 是Steven Rostedt编写的一款用于和ftrace交互的工具(man 1 trace-cmd)
▶ trace-cmd支持的tracer为ftrace暴露的tracer
▶ trace-cmd支持多个命令:
list:列出可以被记录的各种plugins/eventsrecord:将一条trace写入trace.dat文件report:展示trace.dat获取的结果
▶ 在采集结束之后,会生成一个 trace.dat文件
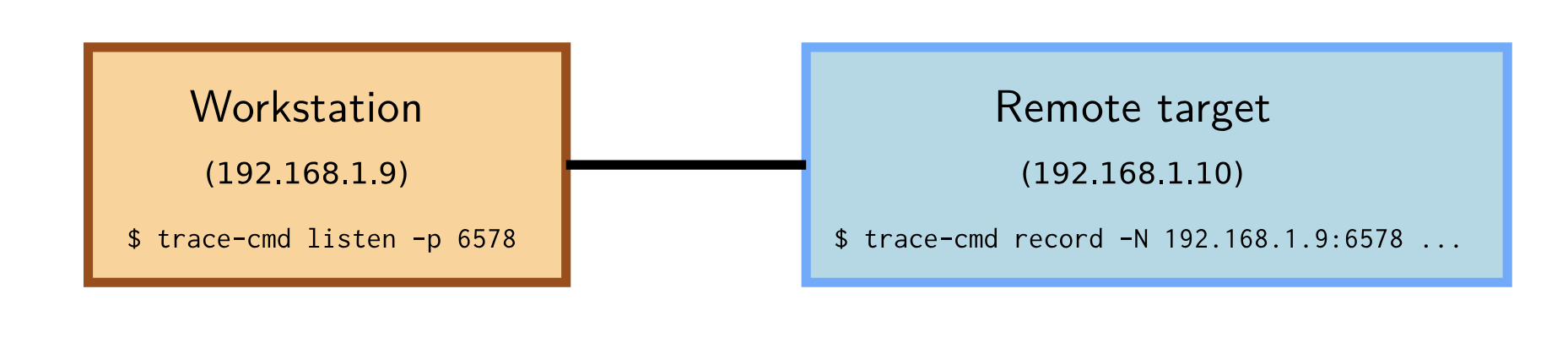
Remote tracing with trace-cmd
▶ trace-cmd 的输出可能会相当大,因此很难将其保存在存储有限的嵌入式平台
▶ 为此,可以使用listen命令通过网络发送结果:
-
在需要采集tracing的远端系统上运行
trace-cmd listen -p 6578 -
在目标系统上,使用
trace-cmd record -N <target_ip>:6578指定采集tracing信息的远端系统![image]()
trace-cmd examples
▶ 列出可用的tracers:
$ trace-cmd list -t
blk mmiotrace function_graph function nop
▶ 列出可用的events:
$ trace-cmd list -e
...
migrate:mm_migrate_pages_start
migrate:mm_migrate_pages
tlb:tlb_flush
syscalls:sys_exit_process_vm_writev
...
▶ 列出function和function_graph tracers可过滤的函数:
$ trace-cmd list -f
...
wait_for_initramfs
__ftrace_invalid_address___64
calibration_delay_done
calibrate_delay
...
▶ 启用function tracer并在系统上记录全局数据:
$ trace-cmd record -p function
▶ 使用function graph tracer跟踪dd命令:
$ trace-cmd record -p function_graph dd if=/dev/mmcblk0 of=out bs=512 count=10
▶ 展示trace.dat的数据:
$ trace-cmd report
▶ 重置所有ftrace缓冲并移除tracers:
$ trace-cmd reset
▶ 在系统上执行irqsoff tracer:
$ trace-cmd record -p irqsoff
▶ 只记录系统的irq_handler_exit/irq_handler_entry events:
$ trace-cmd record -e irq:irq_handler_exit -e irq:irq_handler_entry
Adding ftrace tracepoints
▶ 出于自定义的需要,可以添加自定义tracepoints
▶ 首先需要在一个.h文件中声明该tracepoint
#undef TRACE_SYSTEM
#define TRACE_SYSTEM subsys
#if !defined(_TRACE_SUBSYS_H) || defined(TRACE_HEADER_MULTI_READ)
#define _TRACE_SUBSYS_H
#include <linux/tracepoint.h>
DECLARE_TRACE(subsys_eventname,
TP_PROTO(int firstarg, struct task_struct *p),
TP_ARGS(firstarg, p));
#endif /* _TRACE_SUBSYS_H */
/* This part must be outside protection */
#include <trace/define_trace.h>
▶ 然后使用上述头文件注入tracepoint:
#include <trace/events/subsys.h>
#define CREATE_TRACE_POINTS
DEFINE_TRACE(subsys_eventname);
void any_func(void)
{
...
trace_subsys_eventname(arg, task);
...
}
▶ 更多信息,参见trace/tracepoints
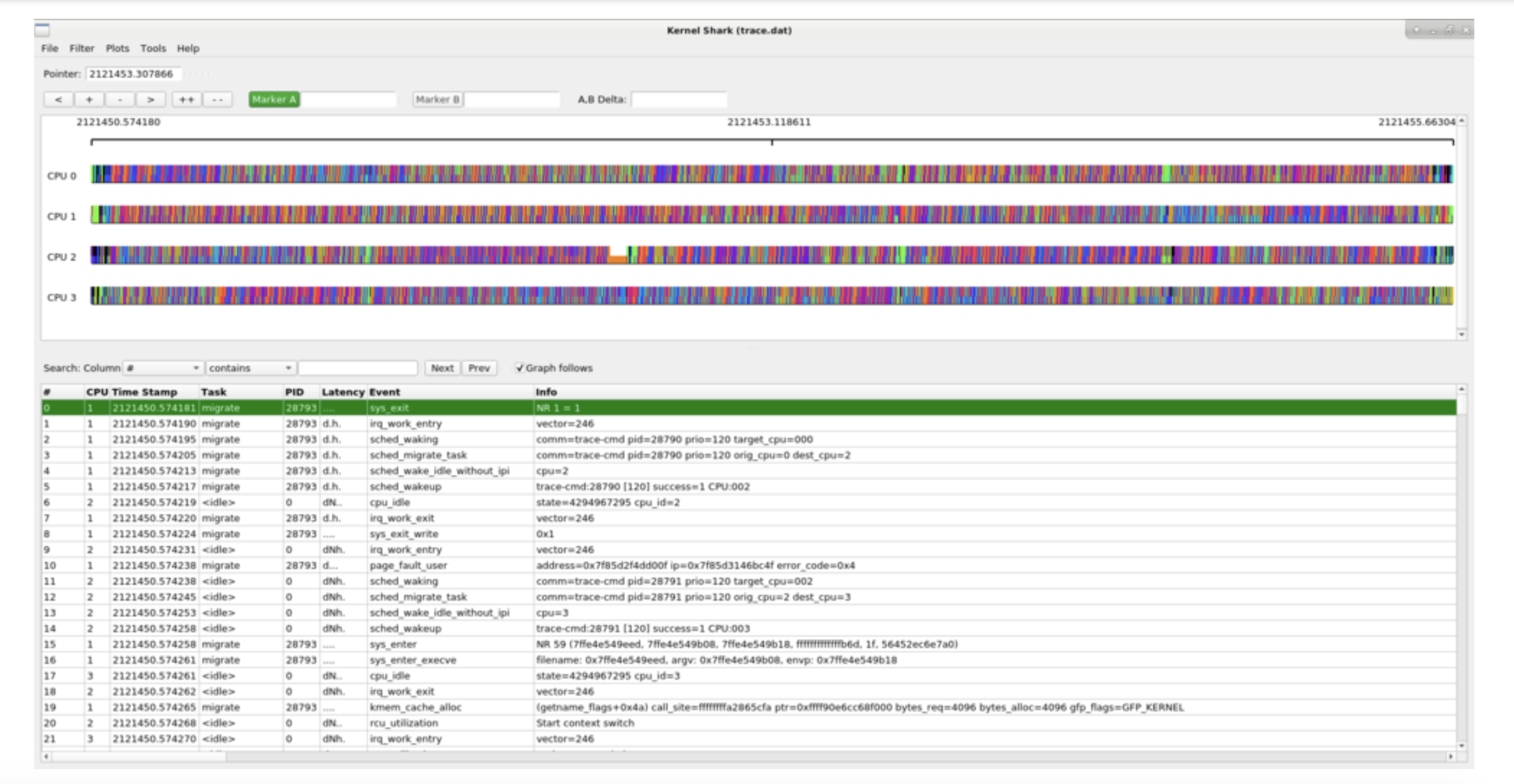
Kernelshark
▶ Kernelshark是一个基于Qt的可以处理trace-cmd trace.dat报告的图像界面
▶ 可以通过trace-cmd配置和获取数据
▶ 使用不同的颜色来展示记录的CPU和tasks events
▶ 可以用于特定bug的进一步分析
LTTng
▶ LTTng是一个由EfficiOS 公司维护的Linux开源tracing框架
▶ 通过LTTng可以了解到内核和应用之间的交互(C、C++、Java、Python)
- 还未应用暴露了一个
/dev/lttng-logger
▶ Tracepoints会关联一个payload
▶ LTTng注重低开销的tracing
▶ 使用Common Trace Format(因此可以使用babeltrace或trace-compass之类的软件读取trace数据)
Tracepoints with LTTng
▶ LTTng有一个session守护进程,用于接收从内核和用户空间的LTTng tracing组件产生的events
▶ LTTng可以用于跟踪如下内容:
- LTTng内核tracepoints
- kprobes和kretprobes
- Linux内核系统调用
- Libux用户空间probe
- 用户空间的LTTng tracepoints
Creating userspace tracepoints with LTTng
▶ 可以使用LTTng定义新的用户空间tracepoints
▶ 可以为一个tracepoint配置多个属性
- 一个provider命名空间
- 一个辨别tracepoint的名称
- 各种类型参数(int、char*等)
- 描述如何展示tracepoint参数的字段(十进制、十六禁止等),参见LTTng-ust
▶ 为了使用UST tracepoint,开发者需要执行多个操作:编写一个tracepoint provider(.h),编写一个tracepoint package(.c),构建package,在被跟踪的应用中调用该tracepoint,最后构建应用,链接lttng-ust库和package provider。
▶ LTTng提供了 lttng-gen-tp简化这些步骤,只需要编写一个模板(.tp)文件即可
Defining a LTTng tracepoint
▶ Tracepoint模板(hello_world-tp.tp)
LTTNG_UST_TRACEPOINT_EVENT(
// Tracepoint provider name
hello_world,
// Tracepoint/event name
first_tp,
// Tracepoint arguments (input)
LTTNG_UST_TP_ARGS(
char *, text
),
// Tracepoint/event fields (output)
LTTNG_UST_TP_FIELDS(
lttng_ust_field_string(message, text)
)
)
▶ lttng-gen-tp会使用该模板文件来生成/构建所需的文件(.h,.c和.o文件)
Defining a LTTng tracepoint
▶ 构建tracepoint provider:
$ lttng-gen-tp hello_world-tp.tp
▶ 使用Tracepoint(hello_world.c)
#include <stdio.h>
#include "hello-tp.h"
int main(int argc, char *argv[])
{
lttng_ust_tracepoint(hello_world, my_first_tracepoint, 23, "hi there!");
return 0;
}
▶ 编译:
$ gcc hello_world.c hello_world-tp.o -llttng-ust -o hello_world
Using LTTng
$ lttng create my-tracing-session --output=./my_traces
$ lttng list --kernel
$ lttng list --userspace
$ lttng enable-event --userspace hello_world:my_first_tracepoint
$ lttng enable-event --kernel --syscall open,close,write
$ lttng start
$ /* Run your application or do something */
$ lttng destroy
$ babeltrace2 ./my_traces
▶ 可以使用 trace-compass来展示结果
Remote tracing with LTTng
▶ LTTng可以通过网络记录跟踪数据
▶ 适用于只有有限存储的嵌入式系统
▶ 在远端计算机上执行lttng-relayd命令
$ lttng-relayd --output=${PWD}/traces
▶ 在目标机器上创建的会话中指定--set-url:
$ lttng create my-session --set-url=net://remote-system
▶ 这样就可以直接记录远端计算机的跟踪信息
eBPF
The ancestor: Berkeley Packet filter
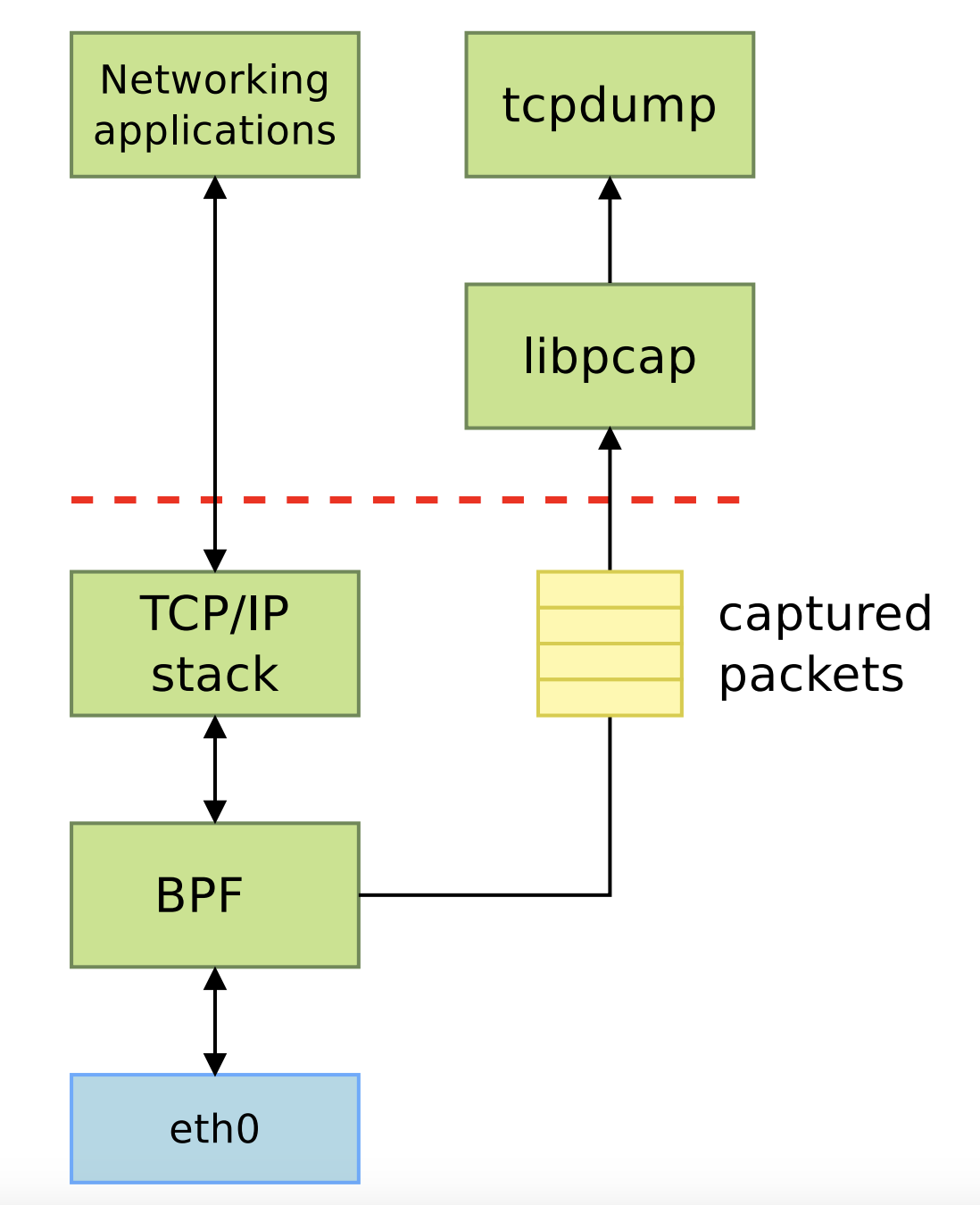
▶ BPF是Berkeley Packet Filter的简称,一开始用于网络报文过滤
▶ BPF用于Linux的Socket过滤(参见networking/filter)
▶ tcpdump和Wireshark严重依赖BPF(通过libpcap)进行报文捕获
BPF in libpcap: setup
▶ tcpdump可以将用户的报文过滤字符串传入libpcap
▶ libpcap会将捕获过滤器转换为一个二进制程序
- 该程序使用一个抽象的机器指令集(BPF指令集)
▶ libpcap通过setsockopt()系统调用将该二进制程序发送到内核
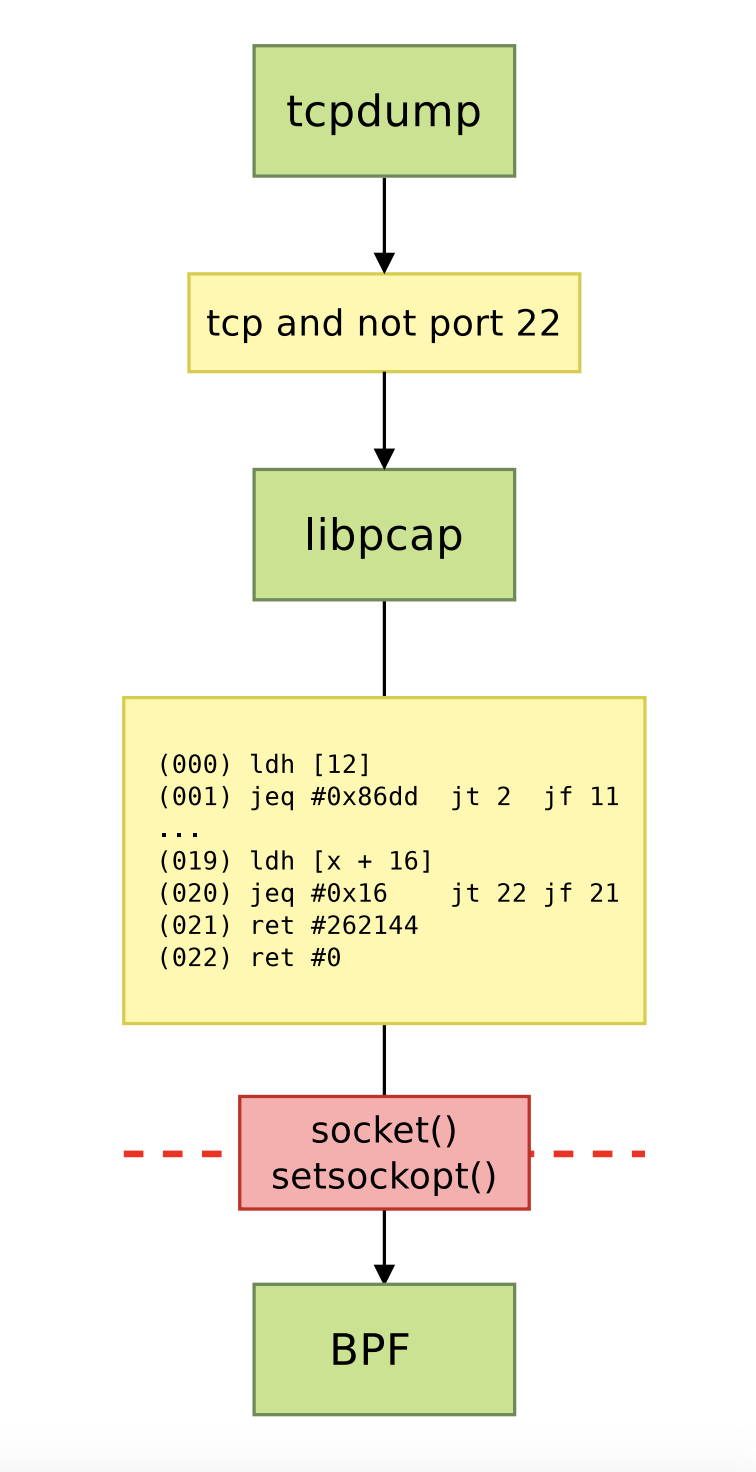
BPF in libpcap: capture
▶ 内核实现了BPF"虚拟机"
▶ BPF虚拟机为每个报文执行BPF程序
▶ 程序会检查报文数据,如果需要捕获报文,则返回一个非0值
▶ 如果返回值非0,则除了常规的报文处理之外,还会捕获报文
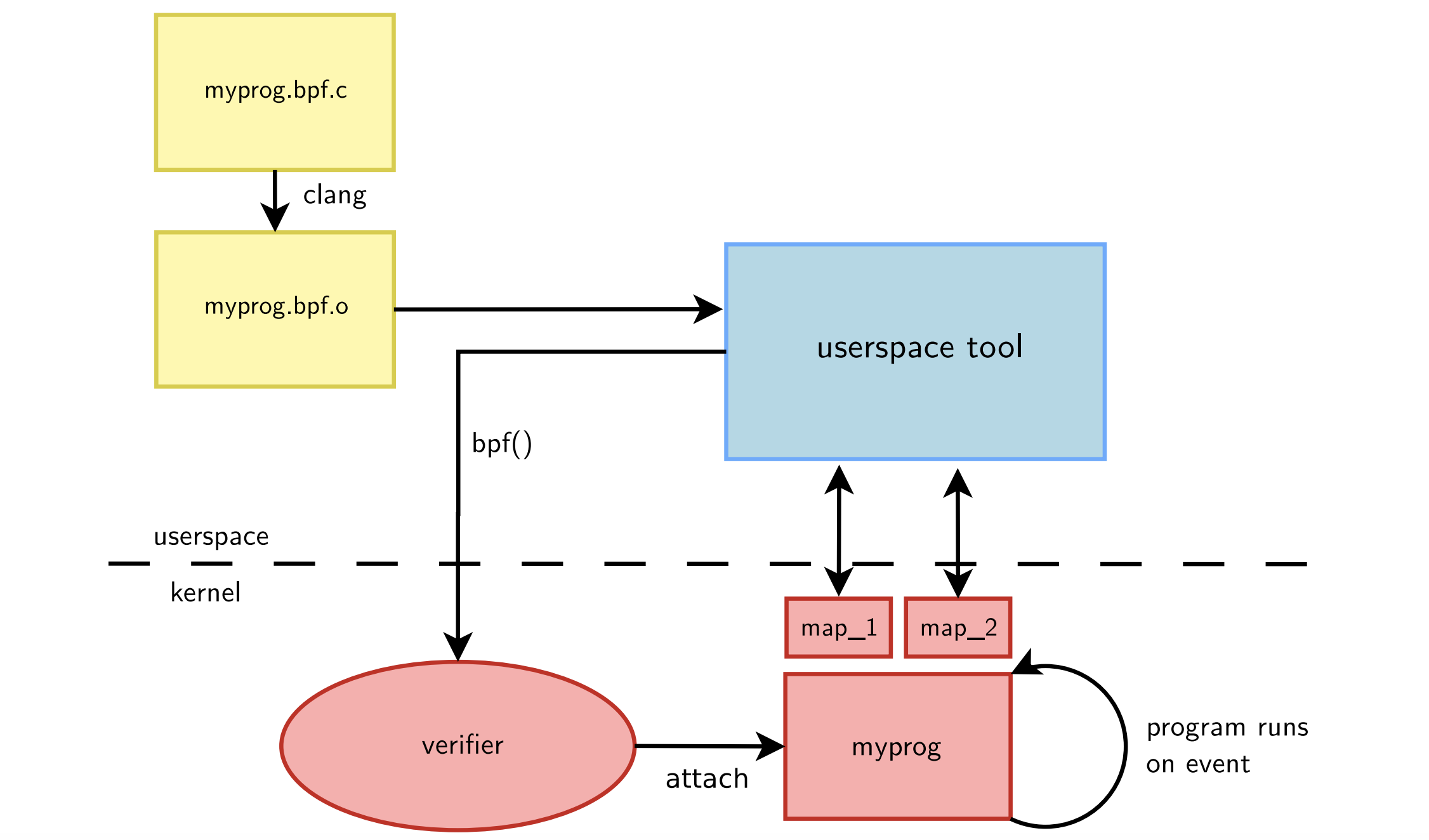
eBPF
▶ eBPF是一种允许在内核中安全有效地运行用户程序的新框架。于内核3.18版本引入,且仍然在演化和频繁更新中
▶ eBPF程可以捕获并向用户空间暴露内核数据,以及基于一些用户定义的规则来改变内核行为
▶ eBPF是事件驱动的:特定的内核事件可以触发并执行eBPF程序
▶ eBPF的一个主要好处是可以重新编程内核行为,而无需针对内核开发:
- 不会因为bug导致内核崩溃
- 可以实现更快的特性开发周期
▶ eBPF值得注意的特性有:
- 新的指令集、中断器和校验器
- 更大范围的"attach"位置,几乎可以在内核的任何位置hook程序
- 使用名为"maps"的特定结构来在多个eBPF程序之间或程序和用户空间之间交换数据
- 使用一个特定的
bpf()系统调用来操作eBPF程序和数据 - eBPF程序中提供了大量内核辅助函数
eBPF program lifecycle
Kernel configuration for eBPF
▶ 通过CONFIG_NET启用eBPF子程序
▶ 通过CONFIG_BPF_SYSCALL启用bpf()系统调用
▶ 通过CONFIG_BPF_JIT在程序中启用JIT,提升性能
▶ CONFIG_BPF_JIT_ALWAYS_ON强制启用JIT
▶ CONFIG_BPF_UNPRIV_DEFAULT_OFF=n 可以在开发阶段允许非root使用eBPF
▶ 你可能想要通过更多特性来解锁特定的hook位置:
- CONFIG_KPROBES可以在kprobes上hook程序
- CONFIG_TRACING 可以在内核tracepoint上hook程序
- CONFIG_NET_CLS_BPF可以编写报文分类器
- CONFIG_CGROUP_BPF 可以在cgroup hook上attach programs
eBPF ISA
▶ eBPF是一个"虚拟的" ISA,定义了其所有的指令集:加载和存储指令、算术指令、跳转指令等
▶ 它还定义了一组10个64位的寄存器,以及一个调用准则:
R0: 函数和BPF程序的返回值R1, R2, R3, R4, R5: 函数参数R6, R7, R8, R9: 调用保存寄存器R10: 栈指针
; bpf_printk("Hello %s\n", "World");
0: r1 = 0x0 ll
2: r2 = 0xa
3: r3 = 0x0 ll
5: call 0x6
; return 0;
6: r0 = 0x0
7: exit
The eBPF verifier
▶ 在将一个程序加载到内核时,eBPF verifier会校验程序的有效性
▶ verifier是一个复杂的软件片段,用于通过一组规则来校验eBPF程序,确保运行的代码不会损害整个内核。如:
- 程序必须返回,否则不确定的代码路径可能会导致无限运行(如无限循环)
- 程序必须保证引用的指针是有效的
- 程序不能随意访问内存地址,必须通过context或有效的helpers
▶ 如果一个程序违背了verifier的规则,则拒绝该程序
▶ 除了verifier的要求之外,在编写程序时也必须格外小心。eBPF程序启用了抢占(但禁用CPU迁移),因此仍然可能会受到并发问题的影响
- 可以通过一些机制和helpers来避免这些问题,比如per-cpu maps类型
Program types and attach points
▶ eBPF可以在不同类型的位置hook一个程序:
- 任意kprobe
- 内核定义的静态tracepoint
- 特定的perf event
- 整个网络栈
- 更多参见bpf_attach_type
▶ 特定的attach点有可能仅支持hook一部分特定的程序,参见bpf_prog_type 和 bpf/libbpf/program_types
▶ 程序类型定义了程序被调用时传入eBPF程序的数据,如:
BPF_PROG_TYPE_TRACEPOINT程序会接收一个包含目标tracepoint返回给用户空间的所有数据的结构。BPF_PROG_TYPE_SCHED_CLS程序(用于实现报文分类器)将接收一个struct __sk_buff, 在内核中体现为一个Socket buffer- 更多传递到程序类型的上下文,参见 include/linux/bpf_types.h
eBPF maps
▶ eBPF可以通过不同的maps与用户空间或其他程序交互数据:
BPF_MAP_TYPE_ARRAY:通用数组存储。可以划分不同的CPUBPF_MAP_TYPE_HASH:包含key-value的存储。keys可以是不同的类型:__u32、设备类型、IP地址等BPF_MAP_TYPE_QUEUE:FIFO类型队列BPF_MAP_TYPE_CGROUP_STORAGE:使用cgroup id作为key的一种hash map。除此之外还有其他对象类型的maps(inodes、tasks、sockets等)
▶ 对于基本的数据,简单有效的方式是直接使用eBPF的全局变量(与maps相反,不涉及系统调用)
The bpf() syscall
▶ 内核通过暴露一个bpf()系统调用来允许和eBPF子系统进行交互
▶ 该系统调用有一个子命令集,并根据不同的子命令接收特定的数据:
- BPF_PROG_LOAD:加载一个bpf程序
- BPF_MAP_CREATE:为程序分配使用的maps
- BPF_MAP_LOOKUP_ELEM:在map中查询表项
- BPF_MAP_UPDATE_ELEM:更新map中的表项
▶ 该系统调用使用指向eBPF资源的文件描述符。只要至少有一个程序持有有效的文件描述符,则这些资源(program、maps、links等)将一直有效。如果没有程序使用,则这些资源将会被自动清理。
▶ 更多参见man 2 bpf
Writing eBPF programs
▶ 可以直接使用原始的eBPF汇编或高级语言(如C或rust)编写eBPF程序,并使用clang编译器进行编译。
▶ 内核为eBPF程序提供了一个辅助函数:
bpf_trace_printk将log传递到trace bufferbpf_map_{lookup,update,delete}_elem操作mapsbpf_probe_{read,write}[_user]安全地从/向内核或用户空间读/写数据bpf_get_current_pid_tgid返回当前进程ID和线程组IDbpf_get_current_uid_gid返回当前用户ID和组IDbpf_get_current_comm返回当前task中的可执行文件的名称bpf_get_current_task返回当前 struct task_struct- 更多辅助函数,参见man 7 bpf-helpers
▶ 内核还暴露了kfuncs(参见bpf/kfuncs),但与bpf辅助函数相反,它们并不属于内核的稳定接口
Manipulating eBPF program
▶ 有多种方式可以构建、加载和管理eBPF程序:
- 一种是可以编写一个eBPF程序,使用clang进行构建,然后加载,在attach之后,在自定义用户空间程序中使用
bpf()读取数据 - 还可以使用bpftool操作构建好的eBPF程序(load、attach、read maps等),无需编写任何用户空间工具
- 或者可以通过一些中间库来编写自己的eBPF工具来处理一些负载的工作,如libbpf
- 还可以使用特定的框架,如BCC或bpftrace
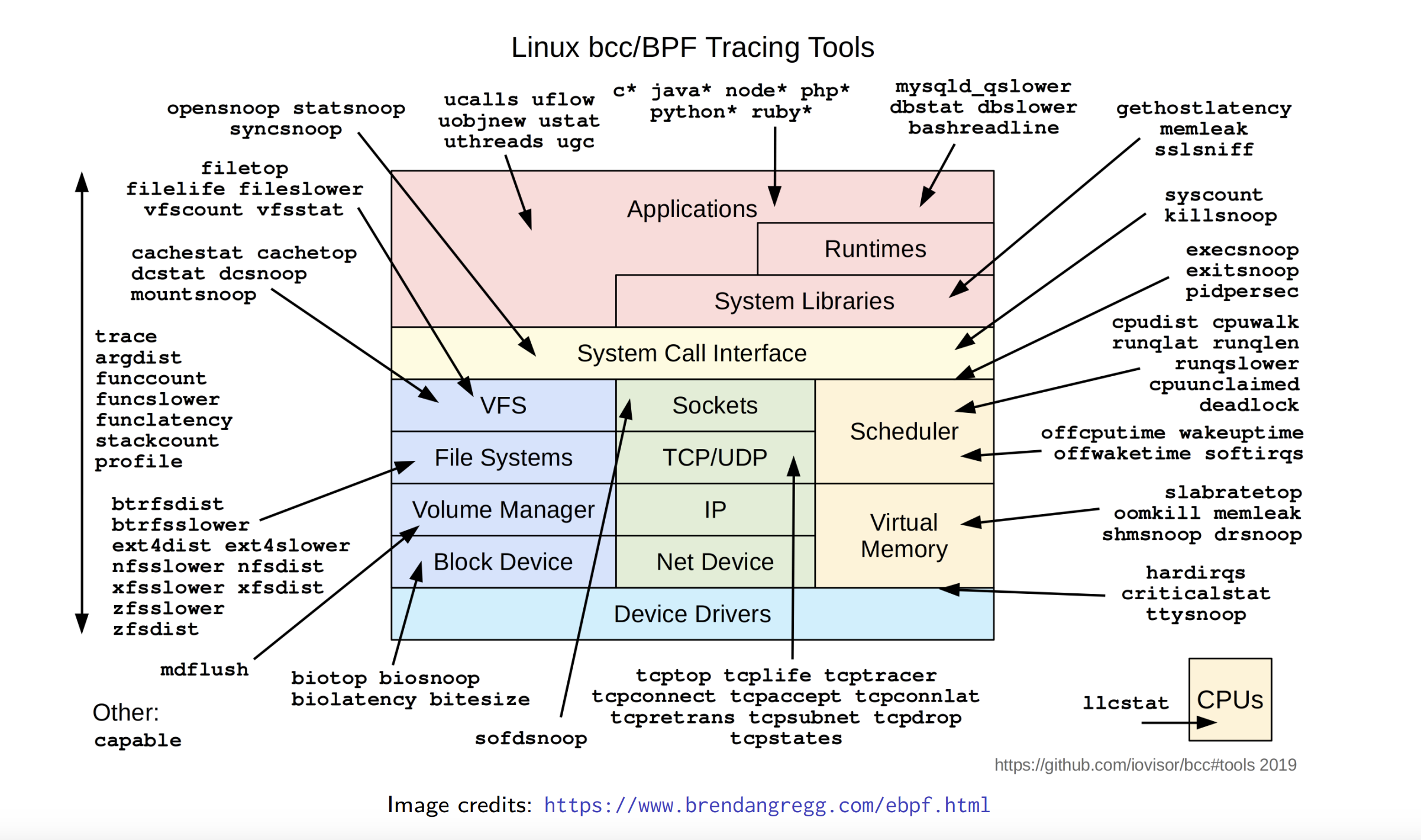
BCC
▶ BPF Compiler Collection (BCC) 是一个基于BPF的工具集
▶ BCC提供了大量现成的基于BPF的工具
▶ 还提供了比使用"原始"的BPF语言更简单的用于编写、加载和hook BPF的程序的接口
▶ 适用于大量平台(但不包括ARM32)
- 在debian架构中,所有工具名为
<tool>-bpfcc
▶ BCC要求内核版本>=4.1
▶ BCC的演化很快,很多发行版的版本都比较旧:你可能需要编译最新的源码。
BCC tools
BCC Tools example
▶ profile.py 是一个CPU profiler,可以捕获当前执行的栈。可以将输出转换为火焰图:
$ git clone https://github.com/brendangregg/FlameGraph.git
$ profile.py -df -F 99 10 | ./FlameGraph/flamegraph.pl > flamegraph.svg
▶ tcpconnect.py展示了所有新的TCP连接:
$ tcpconnect
PID COMM IP SADDR DADDR DPORT
220321 ssh 6 ::1 ::1 22
220321 ssh 4 127.0.0.1 127.0.0.1 22
17676 Chrome_Child 6 2a01:cb15:81e4:8100:37cf:d45b:d87d:d97d 2606:50c0:8003::154 443
[...]
▶ 更多参见https://github.com/iovisor/bcc
Using BCC with python
▶ BCC暴露了一个bcc模块,以及一个BPF类
▶ eBPF程序使用C语言编写,将其存储到外部文件或直接作为一个python字符串
▶ 当创建一个BPF类的实例,并将其(以文件或字符串形式)提供给eBPF程序时,它会自动构建、加载并attach程序
▶ 有多种attach一个程序的方式:
- 根据目标attach点,使用合适的程序名前缀(这样会自动执行attach步骤)
- 通过明确调用之前创建的BPF实例方法
Using BCC with python
▶ 使用kprobe hook clone()系统调用,每次hook时打印"Hello, World!"。
from bcc import BPF
# define BPF program
prog = """
int hello(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
libbpf
▶ 除使用BCC这样的高级框架之外,还可以使用libbpf构建自定义工具,更好地控制程序的方方面面
▶ libbpf是一个基于C的库,通过如下特性来降低eBPF编程的复杂度:
- 用于处理open/load/attach/teardown bpf程序的用户空间API
- 用于与attach的程序交互的用户空间API
- 简化编写eBPF程序的eBPF APIs
▶ 很多发行版和构建系统(如Buildroot)都打包了libbpf
▶ 更多参见https://libbpf.readthedocs.io/en/latest/
eBPF programming with libbpf
my_prog.bpf.c
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#define TASK_COMM_LEN 16
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, __u32);
__type(value, __u64);
__uint(max_entries, 1);
} counter_map SEC(".maps");
struct sched_switch_args {
unsigned long long pad;
char prev_comm[TASK_COMM_LEN];
int prev_pid;
int prev_prio;
long long prev_state;
char next_comm[TASK_COMM_LEN];
int next_pid;
int next_prio;
};
SEC("tracepoint/sched/sched_switch")
int sched_tracer(struct sched_switch_args *ctx)
{
__u32 key = 0;
__u64 *counter;
char *file;
char fmt[] = "Old task was %s, new task is %s\n";
bpf_trace_printk(fmt, sizeof(fmt), ctx->prev_comm, ctx->next_comm);
counter = bpf_map_lookup_elem(&counter_map, &key);
if(counter) {
*counter += 1;
bpf_map_update_elem(&counter_map, &key, counter, 0);
}
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
Building eBPF programs
▶ eBPF使用C编写,可以通过clang构建为一个可加载的对象:
$ clang -target bpf -O2 -g -c my_prog.bpf.c -o my_prog.bpf.o
▶ 最近的版本中也可以使用GCC:
- 可以在Debian/Ubuntu中使用
gcc-bpf安装工具链 - 它暴露了
bpf-unknown-none目标
▶ 为了简化在用户空间程序中操作基于libbpf的程序 ,我们需要"skeleton" API,通过 bpftool 生成这些 API 可以
bpftool
▶ bpftool是一个可以通过与bpf对象文件和内核交互来管理bpf程序的命令行工具:
- 将程序加载到内核
- 列出加载的程序
- dump程序指令,BPF代码或JIT代码
- dump map内容
- 将程序attach到hooks等
▶ 你可能需要mount bpf文件系统来pin程序(即在bpftool结束运行之后仍然加载程序)
$ mount -t bpf none /sys/fs/bpf
▶ 列出加载的程序:
$ bpftool prog
348: tracepoint name sched_tracer tag 3051de4551f07909 gpl
loaded_at 2024-08-06T15:43:11+0200 uid 0
xlated 376B jited 215B memlock 4096B map_ids 146,148
btf_id 545
▶ 加载并attach 一个程序:
$ mkdir /sys/fs/bpf/myprog
$ bpftool prog loadall trace_execve.bpf.o /sys/fs/bpf/myprog autoattach
▶ 卸载一个程序:
$ rm -rf /sys/fs/bpf/myprog
▶ dump一个加载的程序:
$ bpftool prog dump xlated id 348
int sched_tracer(struct sched_switch_args * ctx):
; int sched_tracer(struct sched_switch_args *ctx)
0: (bf) r4 = r1
1: (b7) r1 = 0
; __u32 key = 0;
2: (63) *(u32 *)(r10 -4) = r1
; char fmt[] = "Old task was %s, new task is %s\n";
3: (73) *(u8 *)(r10 -8) = r1
4: (18) r1 = 0xa7325207369206b
6: (7b) *(u64 *)(r10 -16) = r1
7: (18) r1 = 0x7361742077656e20
[...]
▶ dump eBPF程序logs:

▶ 列出创建的maps:
$ bpftool map
80: array name counter_map flags 0x0
key 4B value 8B max_entries 1 memlock 256B
btf_id 421
82: array name .rodata.str1.1 flags 0x80
key 4B value 33B max_entries 1 memlock 288B
frozen
96: array name libbpf_global flags 0x0
key 4B value 32B max_entries 1 memlock 280B
[...]
▶ 展示一个map的内容:
$ sudo bpftool map dump id 80
[{
"key": 0,
"value": 4877514 }
]
▶ 生成libbpf API来操作一个程序:
$ bpftool gen skeleton trace_execve.bpf.o name trace_execve > trace_execve.skel.h
▶ 我们可以使用高级API编写自己的用户空间程序来更好地操作自己的eBPF程序:
- 实例化一个可以被所有程序、maps、links等引用的全局上下文对象
- 加载/attact/卸载程序
- eBPF 程序作为字节数组直接嵌入到生成的header中
Userspace code with libbpf
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include "trace_sched_switch.skel.h"
int main(int argc, char *argv[])
{
struct trace_sched_switch *skel;
int key = 0;
long counter = 0;
skel = trace_sched_switch__open_and_load();
if(!skel)
exit(EXIT_FAILURE);
if (trace_sched_switch__attach(skel)) {
trace_sched_switch__destroy(skel);
exit(EXIT_FAILURE);
}
while(true) {
bpf_map__lookup_elem(skel->maps.counter_map, &key, sizeof(key), &counter, sizeof(counter), 0);
fprintf(stderr, "Scheduling switch count: %d\n", counter);
sleep(1);
}
return 0;
}
eBPF programs portability
▶ 与用户空间API相反,内核内部不会暴露稳定的API,这意味着可以操作某些内核数据的eBPF程序并不一定可以在其他版本的内核上运行
▶ CO-RE(Compile Once - Run Everywhere)用于解决该问题,使得程序可以在不同版本的内核之间进行移植,它依赖如下特性:
- 内核必须通过CONFIG_DEBUG_INFO_BTF=y构建来嵌入BTF。BTF是一个与dwarf类似的格式,可以高效地编码数据布局以及函数签名
- eBPF编译器必须能发出BTF重定位(最近版本的clang和GCC都支持,使用
-g参数) - 需要一个能够处理基于BTF数据的BPF程序以及调节对应的数据访问的BPF加载器。
libbpf是实际上的标准bpf加载器 - 需要eBPF API来读/写CO-RE重定向的变量。libbpf提供了这类辅助函数,如
bpf_core_read
▶ 更多参见Andrii Nakryiko’s CO-RE guide
▶ 除了CO-RE外,由于内核主特性的引入或变更,还可能会面临不同内核版本的不同限制(eBPF子系统在持续频繁更新中):
- 4.2版本中加入了eBPF尾部调用(可以允许一个程序调用一个函数),5.10版本中可以允许调用另一个程序
- 5.1版本中加入了eBPF自旋锁,防止在不同CPUs间并发访问共享的maps
- 不断引入不同的attach类型,但可能存在不同架构的不同版本中。如
fentry/fexitattach points在x86的5.5内核中引入,但却在arm32的6.0版本中引入。 - 5.3版本之前禁止任何类型的循环(即使是有界的)
- 5.8版本加入的
CAP_BPF可以允许执行一个eBPF任务
eBPF for tracing/profiling
▶ eBPF是一个非常强大的可以探测内核内部的框架:通过大量attach 点,几乎可以暴露任何内核路径和代码
▶ 同时,eBPF程序x和内核代码隔离,使之(相比内核开发)更安全更简单
▶ 由于内核翻译器和优化措施,如JIT编译的存在,eBPF非常适合低开销的tracing和profiling,即使在生产环境中也非常灵活
▶ 这也是为什么eBPF在debugging、tracing和profiling中接纳度不断增加地原因。eBPF可以用于:
eBPF: resources
▶ BCC教程:https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
▶ libbpf-bootstrap: https://github.com/libbpf/libbpf-bootstrap
▶ A Beginner’s Guide to eBPF Programming - Liz Rice, 2020
Choosing the right tool
▶ 在开始profile或trace之前,需要知道使用哪种类型的工具。
▶ 通常根据profile的级别来选择工具
▶ 通常一开始会使用应用tracing/profiling工具(valgrind、perf等)对应用层面进行分析/优化
▶ 然后分析用户空间+内核的性能
▶ 最后,如果只有在负载系统中才会出现性能问题时,需要trace或profile整个系统
- 对于"常量"复杂问题,可以使用snapshot工具
- 对于偶尔发生的问题,可以记录trace并进行分析
▶ 如果在分析前需要复杂的配置,可以考虑使用自定义工具:脚本、自定义trace、eBPF等。
Kernel Debugging
Preventing bugs
Static code analysis
▶ 可以使用sparse工具执行静态分析
▶ sparse使用annotation来探测编译时存在的各种错误
- 锁问题(非均衡锁)
- 地址空间问题,如直接访问用户空间指针
▶ 使用make C=2分析需要重新编译的文件
▶ 或使用make C=1分析所有文件
▶ 非均衡锁例子
rzn1_a5psw.c:81:13: warning: context imbalance in 'a5psw_reg_rmw' - wrong count
at exit
Good practices in kernel development
▶ 当编写驱动代码时,不能期望用户能够提供正确的值,因此总是需要对这些值进行校验
▶ 如果想要展示一个特定场景下的调用栈时,可以使用WARN_ON()宏
- 还可以在调试过程中使用dump_stack()展示当前调用栈:
static bool check_flags(u32 flags)
{
if (WARN_ON(flags & STATE_INVALID))
return -EINVAL;
return 0;
}
▶ 如果需要在编译期间检查变量(配置输入,sizeof()结构体字段),则可以使用BUILD_BUG_ON()保证满足条件
BUILD_BUG_ON(sizeof(ctx->__reserved) != sizeof(reserved));
▶ 如果在编译期间得到关于未使用的变量/参数告警,则需要修复这些问题
▶ 使用checkpatch.pl --strict 可以帮助查看代码的潜在问题
Linux Kernel Debugging
▶ 有多种Linux内核特性工具来帮助简化内核调试
- 特定的日志框架
- 使用标准方式dump低级崩溃信息
- 多种运行时检查器来帮助检查各种问题:内存问题、锁问题、未定义的行为等
- 交互式或事后调试
▶ 需要在内核menuconfig中明确启用这些特性,它们被分配到 Kernel hacking -> Kernel debugging 配置表项中。
- 需要将CONFIG_DEBUG_KERNEL设置为"y"来启动其他调试选项
Debugging using messages
有3种可用的APIs:
▶ 对于新的调试消息,不推荐使用老的printk()
▶ pr_*()族函数:pr_emerg(), pr_alert(), pr_crit(), pr_err(), pr_warn(), pr_notice(), pr_info(), pr_cont(),以及特殊的pr_debug()(见后文)
- 定义在include/linux/printk.h
- 使用经典格式的字符串作为参数,如
pr_info("Booting CPU %d\n", cpu); - 下面是输出的内核日志:
[ 202.350064] Booting CPU 1
▶ print_hex_dump_debug(): 使用类似hexdump的格式dump缓冲内容
▶ dev_*()族函数:dev_emerg(), dev_alert(), dev_crit(), dev_err(), dev_warn(), dev_notice(), dev_info() 以及特殊的 dev_dbg() (见下文):
-
它们使用一个指向 struct device的指针作为第一个参数,后跟一个格式化字符串参数
-
可以用在与Linux设备模块集成的驱动中
-
使用方式:
dev_info(&pdev->dev, "in probe\n"); -
内核输出:
[ 25.878382] serial 48024000.serial: in probe [ 25.884873] serial 481a8000.serial: in probe
▶ *_ratelimited() 版本的方法可以基于/proc/sys/kernel/printk_ratelimit{_burst}值来限制高频调用下的大量输出
▶ 相比标准的printf(),内核定义了更多的格式说明符:
%p:默认展示指针的哈希值%px:总是真实指针地址(用于不敏感的地址)%pK:展示哈希指针值,根据kptr_restrictsysctl值可以是0或指针地址%pOF:设备树节点格式说明符%pr:资源结构格式说明符%pa:展示物理地址(所有32/64 bits均支持)%pe:错误指针(展示对应的错误值对应的字符串)
▶ 为使用%pK,应该将/proc/sys/kernel/kptr_restrict设置为1
▶ 更多支持的格式说明符,参见core-api/printk-formats
pr_debug() and dev_dbg()
▶ 当使用定义的DEBUG编译驱动时,所有这些消息都将以debug级别进行编译和打印。可以通过在驱动的开头使用#define DEBUG或在Makefile中使用ccflags-$(CONFIG_DRIVER) += -DDEBUG来启用DEBUG
▶ 当使用CONFIG_DYNAMIC_DEBUG编译内核时,这些消息将自动转换为以单文件、单模块或单消息方式输出(通过/proc/dynamic_debug/control设置)。默认不启用消息功能
- 细节参见admin-guide/dynamic-debug-howto
- 可以获取仅感兴趣的调试消息
▶ 使用DEBUG 或 CONFIG_DYNAMIC_DEBUG时,并不会编译这些消息
pr_debug() and dev_dbg() usage
▶ 可以通过 /proc/dynamic_debug/control 文件启用调试打印
cat /proc/dynamic_debug/control将显示内核启用的所有消息行- 如:
init/main.c:1427 [main]run_init_process =p " \%s\012"
▶ 通过下面语法可以启用单独的行、文件或模块:
echo "file drivers/pinctrl/core.c +p" > /proc/dynamic_debug/control会启用drivers/pinctrl/core.c中的所有调试信息echo "module pciehp +p" > /proc/dynamic_debug/control会启用pciehp模块中的调试打印echo "file init/main.c line 1427 +p" > /proc/dynamic_debug/control回启用init/main.c文件第1247行的调试打印- 将
+p换为-p即可禁用调试打印
Debug logs troubleshooting
▶ 当使用动态调试时,确保启用debug调用:需要在debugfs的control文件中看到且必须启用(=p)
▶ 日志输出是否仅位于内核日志缓冲?
- 可以通过
dmesg查看 - 可以降低
loglevel来直接输出到终端 - 可以在内核命令行中设置
ignore_loglevel来强制所有内核日志输出到终端
▶ 如果正在处理外置模块,可能需要在模块源码或Makefile中定义DEBUG,而非使用动态调试
▶ 如果通过内核命令行进行配置,这些配置会被正确解析吗?
-
从5.14开始,内核可以通知故障的命令行
Unknown kernel command line parameters foo, will be passed to user space. -
需要小心使用特殊的字符串转义(如引号)
▶ 注意,一部分子系统使用了自身的日志基础设置以及特定的配置/控制,如drm.debug=0x1ff
Kernel early debug
▶ 在booting阶段,内核可能会在展示系统消息之前崩溃
▶ 在ARM上,如果内核无法boot或暂停而没有消息任何消息,可以激活early调试选项
- CONFIG_DEBUG_LL=y 启用ARM early窗口输出功能
- CONFIG_EARLYPRINTK=y 将允许printk输出打印信息
▶ 需要使用earlyprintk命令行参数来启用early printk输出功能
Kernel crashes and oops
Kernel crashes
▶ 内核并不能免疫崩溃,很多错误可能会导致崩溃
- 内存访问错误(空指针、越界访问等)
- 错误检测使用了panic
- 不正确的内核执行模式(如在原子上下文使用了sleeping)
- 内核探测到死锁
▶ 在发生错误时,内核会在终端暂时一条消息"Kernel oops"
Kernel oops
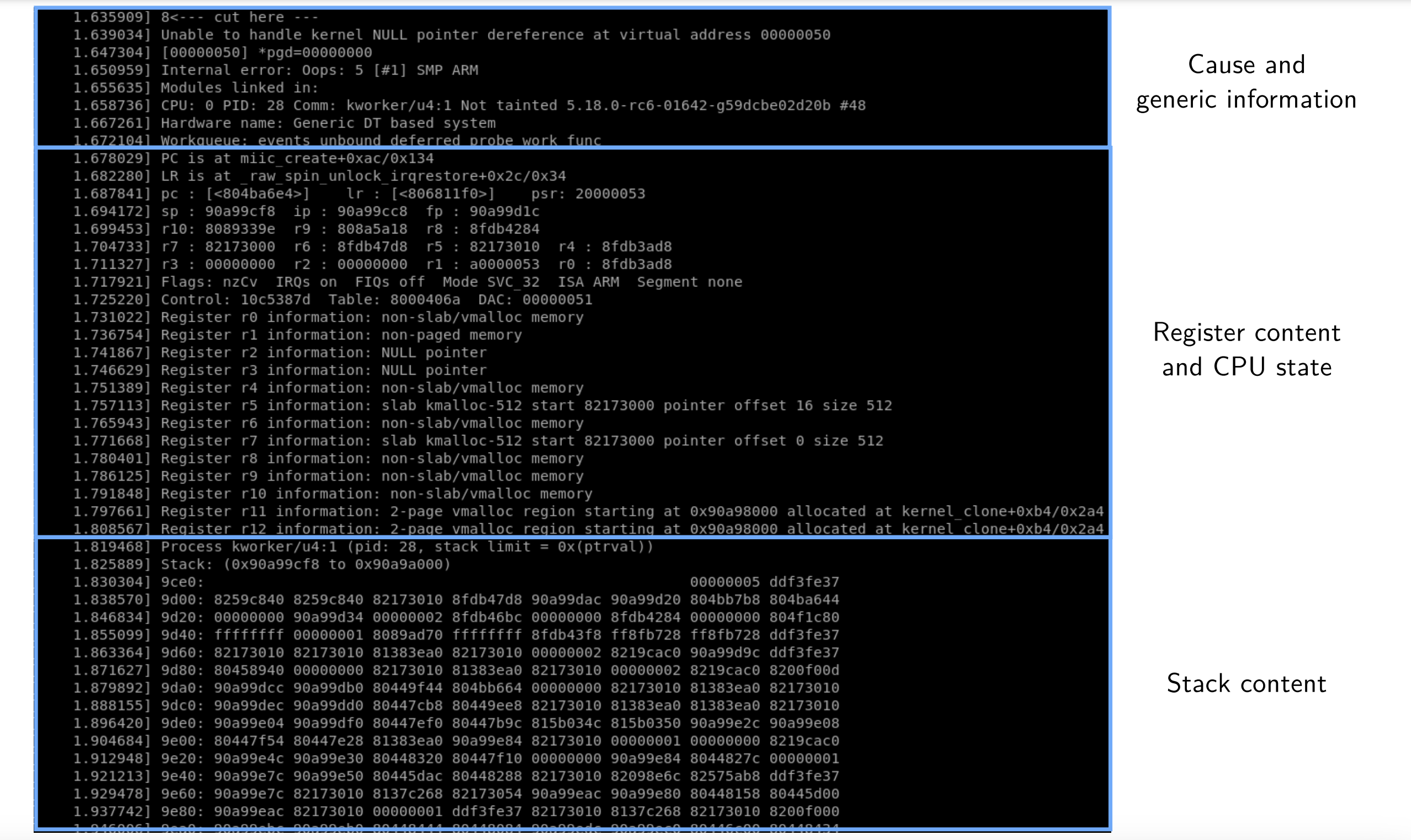
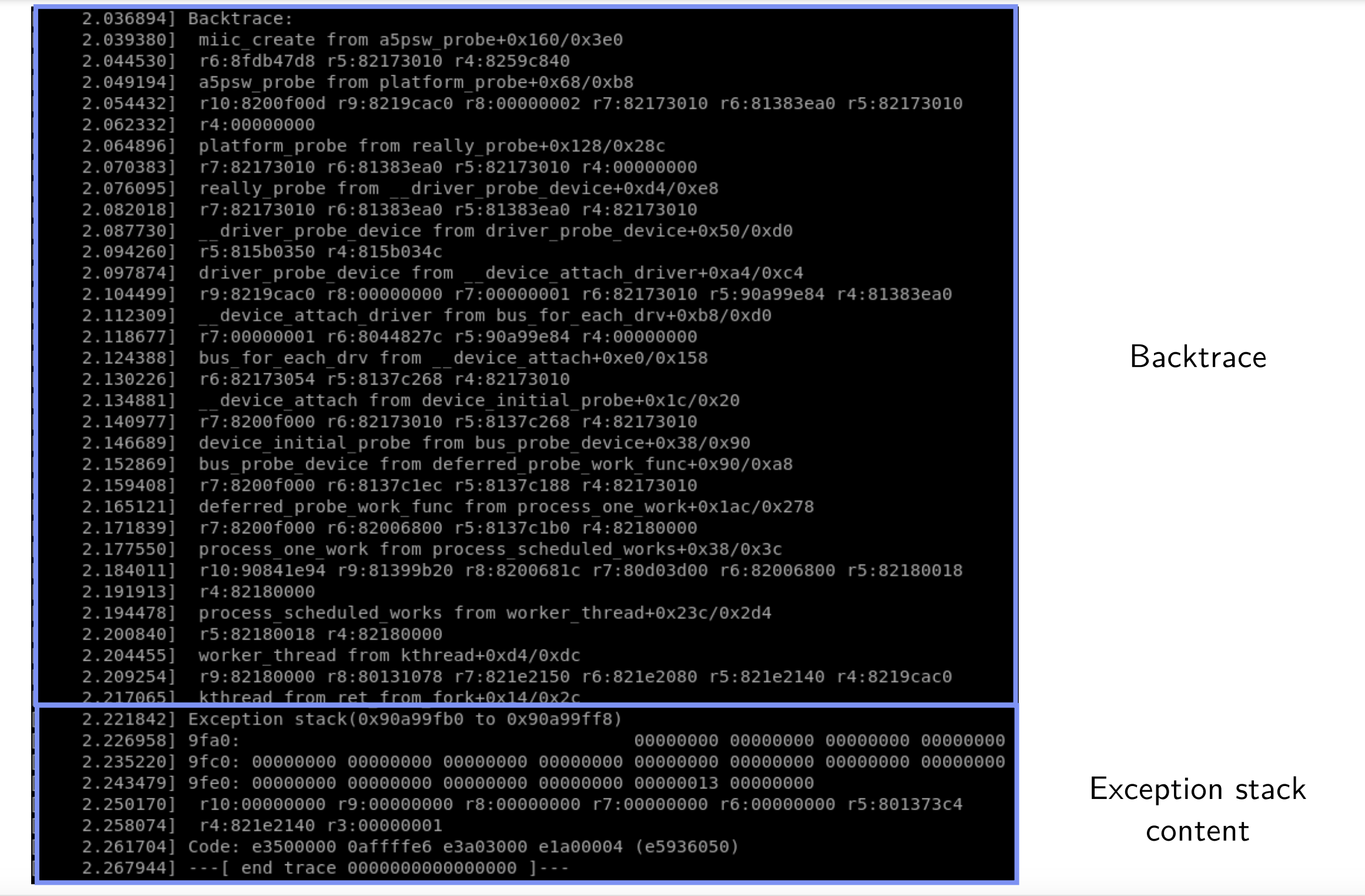
▶ 消息内容取决于使用的架构
▶ 大部分架构会至少展示如下信息:
- oops发生时的CPU状态
- 寄存器内容
- 导致崩溃的回溯函数调用
- 栈内容(最后X字节)
▶ 取决于架构,可以使用PC寄存器(有时称为IP、EIP等)内存分辨崩溃位置
▶ 使用CONFIG_KALLSYMS=y可以将符号名称嵌入内核镜像,进而可以在回溯栈中获得有意义的符号名称
▶ 回溯栈中展示的符号格式为:
<symbol_name>+<hex_offset>/<symbol_size>
▶ 如果oops不是重要的(发生在进程上下文中),则内核会杀死进程并继续执行
- 必须为内核稳定性妥协
▶ hung太长时间的任务也可能产生oops(CONFIG_DETECT_HUNG_TASK)
▶ 如果支持KGDB,则在发生oops时,内核会切换到KGDB模式
Oops example
Kernel oops debugging: addr2line
▶ 可以使用addr2line将展示的地址/符号转换到源码行:
addr2line -e vmlinux <address>
▶ GNU binutils >= 2.39 会处理符号+偏移量符号
addr2line -e vmlinux + <symbol_name>+<off>
▶ 可以通过内核源码的faddr2line脚本处理老版本的symbol+offset符号
scripts/faddr2line vmlinux + <symbol_name>+<off>
▶ 必须通过CONFIG_DEBUG_INFO=y编译内核来将调试信息嵌入vmlinux文件
Kernel oops debugging: decode_stacktrace.sh
▶ 可以通过内核源码提供的decode_stacktrace.sh实现addr2line的oops自动解码
▶ 该脚本可以将所有符号名称/地址转换到对应的文件/行,并展示触发崩溃的汇编代码
▶ ./scripts/decode_stacktrace.sh vmlinux linux_source_path/ < oops_ report.txt > decoded_oops.txt
▶ 注意:应该设置CROSS_COMPILE和ARCH环境变量来获得正确的汇编dump
Oops behavior configuration
▶ 有时,崩溃可能比较严重,导致内核panic,并完全停止执行,处于繁忙循环中
▶ 可以通过 CONFIG_PANIC_TIMEOUT启用在panic时自动重启
- 0:用不重启
- 负值:立即重启
- 正值:重启前等待的秒数
▶ 可以将OOPS配置为总是panic
- 在boot期间,将
oops=panic添加到命令行 - 在构建期间,设置CONFIG_PANIC_ON_OOPS=y
The Magic SysRq
串口驱动提供
▶ 在内核出现严重问题的情况下可以执行多个调试/恢复命令
- 嵌入式中:在终端发送中断符号(按
[Ctrl]+a再按[Ctrl]+\),然后按<character> - 在
/proc/sysrq-trigger中会会回应<character>
▶ 例子:
- h:展示可用的命令
- s:同步所有挂载的文件系统
- b:重启系统
- w:展示所有sleeping进程的内核栈
- t:展示所有运行进程的内核栈
- g:进入kgdb模式
- z:刷新trace缓冲
- c:触发一个崩溃(内核panic)
- 还可以注册自己的命令
▶ 详情参见 admin-guide/sysrq
Built-in Kernel self tests
Kernel memory issue debugging
▶ 在用户空间编写内核代码时可能会发生内存问题
- 越界访问
- 使用释放的内存(在
kfree()之后解引用一个指针) - 由于没有执行
kfree()导致内存不足
▶ 有多种工具可以捕获这些问题
- KASAN可以查找使用释放的内存和越界访问问题
- KFENCE可以在生产系统中查找使用释放的内存和越界访问问题
- Kmemleak可以查找由于忘记释放内存导致的内存泄露
KASAN
▶ 可以查找使用释放的内存和越界访问问题
▶ 在编译期间使用GCC检测内核
▶ 几乎支持所有架构(ARM, ARM64, PowerPC, RISC-V, S390, Xtensa and X86)
▶ 通过内核配置CONFIG_KASAN启用KASAN
▶ 可以通过修改Makefile为特定文件启用KASAN
KASAN_SANITIZE_file.o := y为特定文件启用KASANKASAN_SANITIZE := y为Makefile文件夹中的所有文件启用KASAN
Kmemleak
▶ Kmemleakl可以查找使用kmalloc()动态申请的对象中存在的内存泄漏
- 通过扫描内存来检测内存地址是否被引用
▶ 一旦启用了CONFIG_DEBUG_KMEMLEAK,就可以在debugfs中查看kmemleak控制的文件
▶ 每10分钟扫描一次内存泄露
▶ 可以通过如下方式立即触发一次扫描
# echo scan > /sys/kernel/debug/kmemleak
▶ 结果展示在debugfs中
# cat /sys/kernel/debug/kmemleak
▶ 更多信息参见 dev-tools/kmemleak
Kmemleak report
# cat /sys/kernel/debug/kmemleak
unreferenced object 0x82d43100 (size 64):
comm "insmod", pid 140, jiffies 4294943424 (age 270.420s)
hex dump (first 32 bytes):
b4 bb e1 8f c8 a4 e1 8f 8c ce e1 8f 88 c6 e1 8f ................
10 a5 e1 8f 18 e2 e1 8f ac c6 e1 8f 0c c1 e1 8f ................
backtrace:
[<c31f5b59>] slab_post_alloc_hook+0xa8/0x1b8
[<c8200adb>] kmem_cache_alloc_trace+0xb8/0x104
[<1836406b>] 0x7f005038
[<89fff56d>] do_one_initcall+0x80/0x1a8
[<31d908e3>] do_init_module+0x50/0x210
[<2658dd55>] load_module+0x208c/0x211c
[<e1d48f15>] sys_finit_module+0xe4/0xf4
[<1de12529>] ret_fast_syscall+0x0/0x54
[<7ee81f34>] 0x7eca8c80
UBSAN
▶ UBSAN是一个运行时检测器,检测未定义的代码行为
- 使用大于类型的值进行移位
- 整数溢出
- 未对齐的指针访问
- 越界访问静态数组
- https://clang.llvm.org/docs/UndefinedBehaviorSanitizer.html
▶ 使用编译期间检测来插入在运行时执行的检查
▶ 必须启用CONFIG_UBSAN=y
▶ 可以通过修改Makefile为特定文件启用UBSAN
UBSAN_SANITIZE_file.o := y为特定文件启用UBSANUBSAN_SANITIZE := y为Makefile文件夹的所有文件启用UBSAN
UBSAN: example of UBSAN report
▶ 下面报告了一个未定义的行为:使用>32的值进行移位
UBSAN: Undefined behaviour in mm/page_alloc.c:3117:19
shift exponent 51 is too large for 32-bit type 'int'
CPU: 0 PID: 6520 Comm: syz-executor1 Not tainted 4.19.0-rc2 #1
Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS Bochs 01/01/2011
Call Trace:
__dump_stack lib/dump_stack.c:77 [inline]
dump_stack+0xd2/0x148 lib/dump_stack.c:113
ubsan_epilogue+0x12/0x94 lib/ubsan.c:159
__ubsan_handle_shift_out_of_bounds+0x2b6/0x30b lib/ubsan.c:425
...
RIP: 0033:0x4497b9
Code: e8 8c 9f 02 00 48 83 c4 18 c3 0f 1f 80 00 00 00 00 48 89 f8 48
89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d
01 f0 ff ff 0f 83 9b 6b fc ff c3 66 2e 0f 1f 84 00 00 00 00
RSP: 002b:00007fb5ef0e2c68 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
RAX: ffffffffffffffda RBX: 00007fb5ef0e36cc RCX: 00000000004497b9
RDX: 0000000020000040 RSI: 0000000000000258 RDI: 0000000000000014
RBP: 000000000071bea0 R08: 0000000000000000 R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000246 R12: 00000000ffffffff
R13: 0000000000005490 R14: 00000000006ed530 R15: 00007fb5ef0e3700
Debugging locking
▶ 锁调试:验证锁的正确性
- CONFIG_PROVE_LOCKING
- 检测内核锁代码
- 探测在系统生命中是否违反了锁原则,如:
- 要求不同的锁顺序(持续跟踪并比较锁顺序)
- 中断处理器以及启用中断的进程上下文会获得Spinlocks
- 不适合生产系统
- 细节参见locking/lockdep-design
▶ CONFIG_DEBUG_ATOMIC_SLEEP允许检测原子代码段中错误休眠的代码(通常在保持锁的情况下)。
- 可以通过dmesg显示检测出的问题
Concurrency issues
▶ 内核并发SANitizer框架
▶ Linux5.8引入CONFIG_KCSAN
▶ 基于编译时检测的动态竞争检测器
▶ 可以发现系统的并发问题(主要是数据竞争)
▶ 更多参见dev-tools/kcsan 和 https://lwn.net/Articles/816850/
KGDB
kgdb - A kernel debugger
▶ 内核的执行完全由另一台使用串口线连接的机器上的gdb控制
▶ 几乎可以做任何事情,包括在中断处理器上插入断点
▶ 支持最流行的CPU架构
▶ CONFIG_GDB_SCRIPTS 可以构建内核提供的GDB python脚本
kgdb kernel config
▶ CONFIG_DEBUG_KERNEL=y 支持KDGB
▶ CONFIG_KGDB=y 启用KGDB
▶ CONFIG_DEBUG_INFO=y 使用调试信息编译内核 (-g)
▶ CONFIG_FRAME_POINTER=y 可以具有更多可靠的栈
▶ CONFIG_KGDB_SERIAL_CONSOLE=y 启用串口KGDB
▶ CONFIG_GDB_SCRIPTS=y 启用内核 GDB python 脚本
▶ CONFIG_RANDOMIZE_BASE=n 禁用 KASLR
▶ CONFIG_WATCHDOG=n禁用 watchdog
▶ CONFIG_MAGIC_SYSRQ=y 启用 Magic SysReq 支持
▶ CONFIG_STRICT_KERNEL_RWX=n 禁用内核段的内存保护,可以允许添加断点
kgdb pitfalls
▶ 需要禁用KASLR,防止gdb操作随机内核地址
- 如果启用kaslr,则可以使用
nokaslr命令禁用kaslr模式
▶ 禁用平台watchdog,防止在调试时重启
- 当KGDB中断时,会禁用所有中断,watchdog不提供服务
- 有时,高级别boot会启用watchdog。确保在此处禁用watchdog
▶ 无法使用interrupt命令或Ctrl+C中断内核执行
▶ 不支持在任意位置插入断点(参见CONFIG_KGDB_HONOUR_BLOCKLIST)
▶ 需要支持polling的终端驱动
▶ 某些机构缺少相应的功能(如在arm32上没有watchpoint),因此可能会不稳定
Using kgdb
▶ 细节参见内核文档:dev-tools/kgdb
▶ 必须包含一个kgbd I/O驱动,如通过串口终端使用kgdb(通过 CONFIG_KGDB_SERIAL_CONSOLE启用kgdboc: kgdb over console)
▶ 通过传入如下参数在boot期间配置kgdboc
kgdboc=<tty-device>,<bauds>,如kgdboc=ttyS0,115200
▶ 在运行时使用sysfs
echo ttyS0 > /sys/module/kgdboc/parameters/kgdboc- 如果终端不支持polling,则命令行会提示一个错误
▶ 然后将kgdbwait传入内核:它会让kgdb等到调试器连接
▶ boot内核,在终端初始化之后,使用中止符号+g在串口终端上中断内核(参见Magic SysRq)
▶ 在工作台上,启动gdb:
arm-linux-gdb ./vmlinux(gdb) set remotebaud 115200(gdb) target remote /dev/ttyS0
▶ 一旦连接,就可以像调试应用程序一样调试内核
▶ 在GDB侧,第一个线程代表CPU上下文(ShadowCPU
Kernel GDB scripts
▶ CONFIG_GDB_SCRIPTS可以通过构建python脚本来简化内核调试(添加新命令和函数)
▶ 当使用gdb vmlinux时,会自动加载构建根目录中的vmlinux-gdb.py文件
lx-symbols: 为vmlinux和模块重载符号lx-dmesg: 显示内核 dmesglx-lsmod:显示加载的模块lx-device-{bus|class|tree}: 显示设备总线、类和树lx-ps: ps类似查看任务$lx_current()包含当前task_struct$lx_per_cpu(var, cpu)返回一个单-cpu变量apropos lx显示所有可用的函数
▶ dev-tools/gdb-kernel-debugging
KDB
▶ CONFIG_KGDB_KDB包含一个kgdb的前端名称"KDB"
▶ 该前端在串口终端上暴露了一个调试提示,可以在不需要外部gdb的情况下调试内核
▶ 可以使用与进入kgdb模式相同的机制进入KDB
▶ 可以同时使用KDB和KGDB
- 使用在KDB中使用
kgdb进入kgdb模式 - 通过gdb发送一条
maintenance packet 3维护命令,可以从kgdb切换到KDB模式
kdmx
▶ 当系统只有一个串口时,由于一个应用只能访问一个端口,因此无法同时使用KGDB和串口线输出终端
▶ 幸运的是,kdmx工具可以通过将GDB消息和标准终端从一个端口切分为2个字pty(/dev/pts/x)来支持同时使用KGDB和串口输出
▶ https://git.kernel.org/pub/scm/utils/kernel/kgdb/agent-proxy.git
- kdmx子目录

Going further with KGDB
▶ 更多例子和解释参见如下链接:
- Video: https://www.youtube.com/watch?v=HBOwoSyRmys
- Slides: https://elinux.org/images/1/1b/ELC19_Serial_kdb_kgdb.pdf
crash
▶ crash是一个可以与内核(dead 或 alive)交互的CLI工具
- 使用
/dev/mem或/proc/kcore - 要求CONFIG_STRICT_DEVMEM=n
▶ 可以使用kdump、kvmdump等生成coredump文件
▶ 基于gdb并提供很多特定的命令来检查内核状态
- 栈、dmesg、进程的内存映射、irqs、虚拟内存域等
▶ 可以检查系统上运行的所有任务
▶ https://github.com/crash-utility/crash
crash example
$ crash vmlinux vmcore
[...]
TASKS: 75
NODENAME: buildroot
RELEASE: 5.13.0
VERSION: #1 SMP PREEMPT Tue Nov 15 14:42:25 CET 2022
MACHINE: armv7l (unknown Mhz)
MEMORY: 512 MB
PANIC: "Unable to handle kernel NULL pointer dereference at virtual address 00000070"
PID: 127
COMMAND: "watchdog"
TASK: c3f163c0 [THREAD_INFO: c3f00000]
CPU: 1
STATE: TASK_RUNNING (PANIC)
crash> mach
MACHINE TYPE: armv7l
MEMORY SIZE: 512 MB
CPUS: 1
PROCESSOR SPEED: (unknown)
HZ: 100
PAGE SIZE: 4096
KERNEL VIRTUAL BASE: c0000000
KERNEL MODULES BASE: bf000000
KERNEL VMALLOC BASE: e0000000
KERNEL STACK SIZE: 8192
post-mortem analysis
Kernel crash post-mortem analysis
▶ 有时,无法访问崩溃的系统或在系统无法在等待调试时保持offline状态
▶ 内核可以在远端生成崩溃日志(vmcore文件),这样就可以快速重启系统,并支持gdb事后分析
▶ 该特性依赖kexec和kdump,在发生崩溃并dump出vmcore文件后boot另一个内核。
- 可以通过SSH、FTP等方式将vmcore文件保存到本地存储
kexec & kdump
▶ 在panic时,内核kexec支持直接从崩溃的内核上执行一个"dump-capture kernel"操作
- 大部分时候,会为任务编译特定的dump-capture kerne(
initramfs/initrd指定了最小配置)
▶ kexec系统在启动时为kdump 内核执行预留了一部分RAM
- 可以通过
crashkernel参数指定崩溃内核的特定物理内存域
▶ 然后使用kexec-tools将dump-capture kernel加载到该内存域
- 内部会使用
kexec_load系统调用man 2 kexec_load
▶ 最后,在panic时,内核会重启进入dump-capture Kernel,允许用户dump内核coredump(/proc/vmcore)到任意媒介中
▶ 不同的架构可能还需要选择性添加命令行
▶ 参见admin-guide/kdump/kdump来全面了解如何使用kexec配置kdump内核
▶ 此外还有用户空间服务和工具可以自动采集并将vmcore dumo到远端
- kdump systemd service和
makedumpfile工具还可以将vmcore压缩成一个较小的文件(只适用于x86, PPC, IA64, S390) - https://github.com/makedumpfile/makedumpfile
kdump
kexec config and setup
▶ On the standard kernel: •
-
CONFIG_KEXEC=y 启用KEXEC支持
-
kexec-tools通过kexec命令 -
kexec可以访问的一个内核和DTB
▶ dump-capture kernel:
- CONFIG_CRASH_DUMP=y 启用dump崩溃的内核
- CONFIG_PROC_VMCORE=y 启用
/proc/vmcore支持 - CONFIG_AUTO_ZRELADDR=y ARM32平台
▶ 设置正确的crashkernel命令行选项:
crashkernel=size[KMG][@offset[KMG]]
▶ 使用kexec将dump-capture kernel加载为第一个内核
kexec --type zImage -p my_zImage --dtb=my_dtb.dtb -- initrd=my_initrd --append="command line option"
Going further with kexec & kdump
▶ 关于kexec/kdump的更多信息参见如下内容:
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/18366714

 浙公网安备 33010602011771号
浙公网安备 33010602011771号