

Grafana Loki查询加速:如何在不添加资源的前提下提升查询速度
Grafana Loki查询加速:如何在不添加资源的前提下提升查询速度
来自Grafana Loki query acceleration: How we sped up queries without adding resources,介绍了Loki如何通过n-grams + 布隆过滤器来加速查询。
在过去的5年中,我们在平衡特性开发和支持大规模用户之时,改善了日志聚合系统。早在Loki 3.0之前,我们就已经将峰值吞吐量从Loki 1.0的 10GB/s 提升到了1TB/s 以上。但为了更进一步,并符合低成本、易使用的准则,我们需要寻求一种更加明智的方式。
例如,最近我们在过滤查询时遇到一个有趣的事情:查询时会访问大量根本不需要的数据。例如在一个对7天数据的查询中,我们的Grafana Labs生产集群处理了280PB的日志,但从结果上看,大约有140PB的搜索日志并不匹配任何过滤表达式,换句话说,对50%的数据的查询并没有返回任何结果。更糟糕的是,在65%的数据(182PB)处理中,每1百万日志仅返回了1条日志行。
当然,我们可以通过增加更多的计算资源来解决吞吐量问题,但这与我们的愿景(Loki应该是高效可扩展的)不符。我们将此看做是一个挑战,也是一个机会。那么如何在保持Loki易用性和成本的同时提升过滤查询的效率?
如何加速Loki的查询
在深入这个话题之前,我们需要介绍本文中的两个概念: n-grams and 布隆过滤器:
- 我们使用n-grams提供子字符串排列。如假设给定字符串"abcdef",那么三元组(n-grams的n=3)为"abc"、"bcd"、"cde"和"def"
- 布隆过滤器是一种用于概率匹配的数据结构。它可以判断假阳性,但无法判断假阴性。它在数据库层面有相当长的应用历史。
正如上面所述,我们观察到,请求时间内的大部分数据都是不相关的数据,对特定的查询来说,这些数据毫无价值。我们需要识别并消除这些不相关数据,确保只搜索相关的数据。为此我们需要关注"不相关的数据在哪里",并找到一种"足够好的"空间有效的数据结构来评估出一个过滤查询的相关数据的所在位置,然后忽略掉其余数据。
另一个关键要素是n-grams。它可以帮助Loki维护"结构无意识性"(即没有schemas)。该算法会创建很多数据,但鉴于很多日志行都有共同的信息,因此可以大大减少创建的数据量。例如,下面粗体的部分在所有日志中都是重复的,这部分内容就称之为共同信息:
msg=”adding item to cart” userID="a4hbfer74g" itemID="jr8fdnasd65u4"
msg=”adding item to cart” userID="a4hbfer74g" itemID="78kjasdj4hs21"
msg=”adding item to cart” userID="h74jndvys6" itemID="yclk37uzs95j8”
幸运的是,布隆过滤器可以解决重复数据在空间上的问题。下面这张图展示了一条访问日志,其中绿色部分表示日志中经常出现的信息,黄色部分表示有时候出现的信息,而红色部分表示很少出现的信息。

将上述技术组合起来,就得到了如下方式,后续章节将详细介绍它是如何运作的:

这意味着,可以通过布隆过滤器来提升过滤查询的效率, 而在观察中发现,布隆过滤器的大小仅为日志的2%。
除了已经讨论过的所有内容之外,查询加速还附带了一种全新的查询分片策略,在该策略中,我们利用布隆过滤器来生成更少、更公平的查询分片。
传统上,通过分析TSDB的索引统计数据,Loki会将数据划分为大小大致相等的分最接近二次幂的分片。但事实上并非如此,有些序列的数据量要大于其他序列的数据量,导致分片数据处理不均衡。
我们使用布隆过滤器来降低查询前端在准备阶段需要处理的chunks数,并将chunks均衡地分发到每个需要处理的分片查询上。
布隆过滤器组件是如何工作的
下面让我们看下如何创建布隆过滤器,以及如何使用它们来匹配过滤表达式。我们引入了两个组件:Bloom compactor和Bloom gateway。
compactor会从对象存储的chunks之上构建布隆过滤器。我们为每个序列构建一个Bloom,并将其聚合为block文件。Bloom blocks中的序列遵循与Loki的TSDB和分片计算相同的排序方案。由于相同分片中的序列有可能存在于相同的block,因此有利于本地数据查询。除blocks之外,compactor还维护了一个包含对Bloom blocks的引用以及构建所需要的TSDB索引文件的元数据文件列表。
Bloom compactor是可以水平扩展的,它们使用一个环来分割租户,并声明对序列的key空间的子集的所有权。对于一个给定的序列,负责该序列的compactor会遍历其所有的chunks中日志行来构建一个Bloom。对于每个日志行,我们会计算其n-gram,并将每个n-gram的哈希值以及每个n-gram加上chunk标识符的哈希值追加到Bloom中,前者用于让gateways跳过整个序列,而后者用于跳过整个chunks。
例如,在chunk "aaf67d"中有一条日志行"abcdef",首先计算其n-grams: "abc", "bcd", "cde", "def",然后追加序列的布隆:hash("abc")、hash("abc" + "aaf67d") … hash("def")、hash("def" + "aaf67d")。
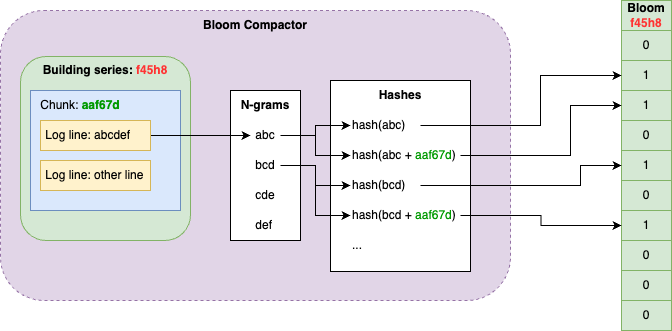
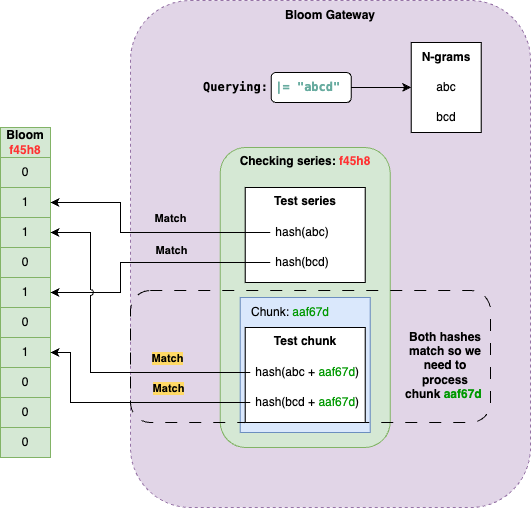
另一方面Bloom Gateway会处理来自index gateway的chunks过滤请求,它使用一系列chunks和过滤表达式来匹配布隆过滤器,并移除掉哪些不匹配过滤表达式的chunks。
类似Bloom compactors,Bloom gateways也是可以水平扩展的,并使用环来实现和compactor相同的目的:租户分片和序列key空间。index gateways使用环,并基于chunk的序列指纹来确定应该发送chunk过滤请求的bloom gateway。
将n-grams而非整条日志行添加到compactor的布隆过滤器中,可以实现Bloom gateway的部分匹配。例如上面例子中,过滤表达式 |= "abcd" 可以生成两个n-grams: "abc" 和 "bcd",两种都匹配布隆。
对于序列中的每个chunk,我们可以通过将chunk ID追加到n-gram的方式来进行布隆测试。
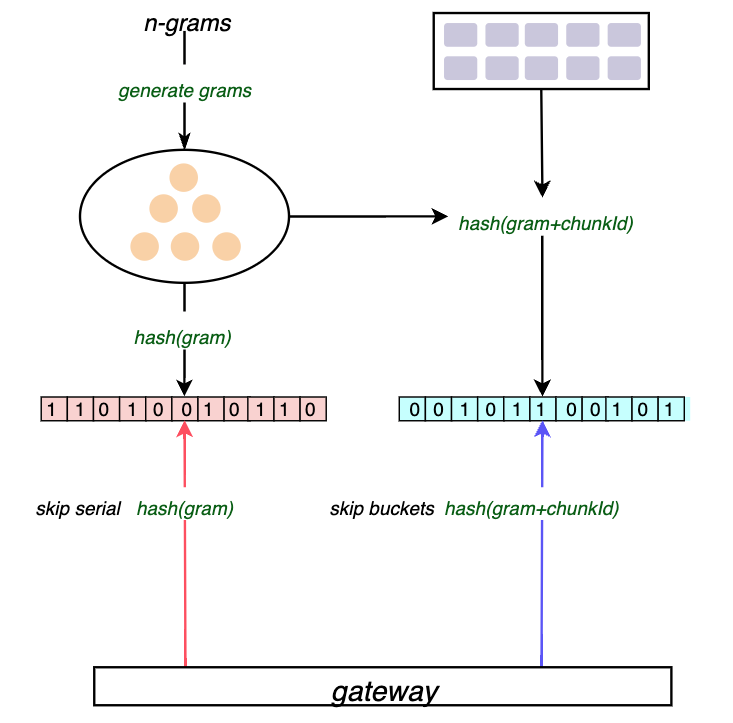
下图展示了如何构建布隆,并利用它来跳过不匹配过滤表达式的n-grams的序列和blocks。
可以看到bloom compactor用于构建bloom,而bloom gateway则会查询compactor构建的bloom。
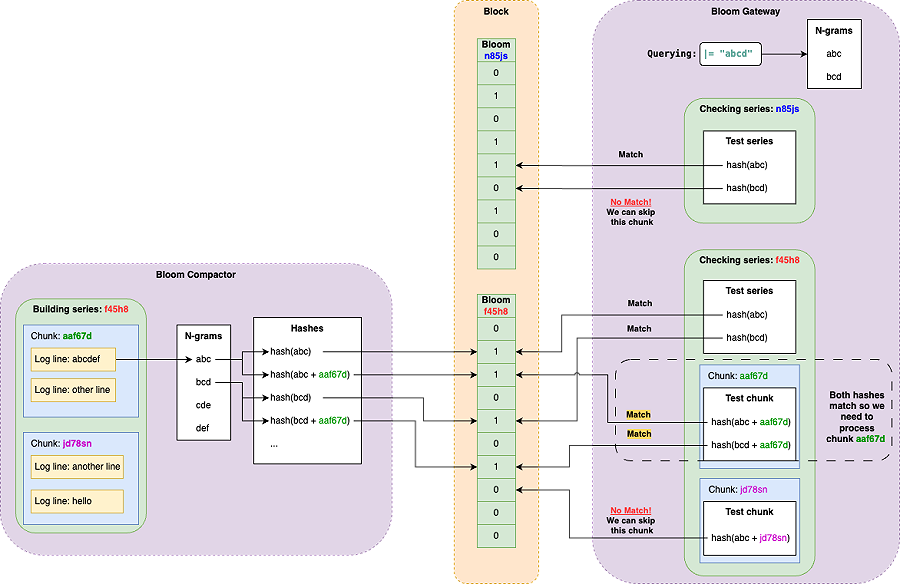
n-grams的大小是可以配置的,n-grams越长,追加到布隆过滤器的tokens越少。但同时也需要更长的过滤表达式来匹配布隆过滤器。例如,当n-grams长度为3时,则过滤表达式的长度也最少需要3个字符。
创建一个好的用户体验
当然,我们的首先目标是加快查询速度,这种方式更倾向于查询一些比较少见的数据,如UUID。
布隆过滤器非常适用于精确查询,例如,如果你要在所有日志中查找一个特定的消费者ID或一个特定的错误码,对于开发者或支持工程师来说这是一种常见的使用模式。由于布隆过滤器可以让Loki只处理可能包含这些术语的日志,而这些术语可能出现在很少的日志行中,所以对搜索时间的影响是巨大的。
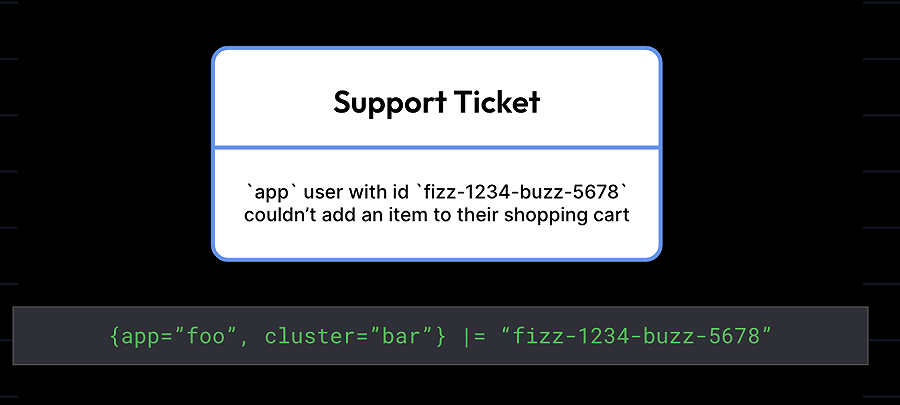
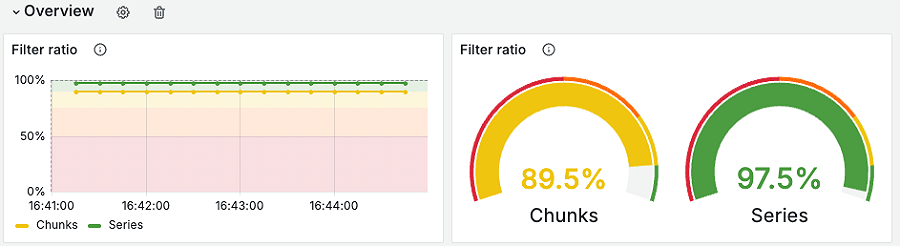
所有迹象都表明布隆过滤器确实有效。早期的内部测试发现,通过引入布隆过滤器,Loki可以在查询时跳过相当大比例的日志数据。在我们的测试环境中发现,相比之前的查询,现在可以过滤掉70%到90%的chunks。
下面是一个使用布隆过滤器执行"大海捞针"式的查询的结果,该查询包括几个过滤条件,代表了我们看到客户在由Loki支持的Grafana Cloud Logs上运行的典型使用场景。
使用注意事项
当前实现中,并不是所有的查询都能受益于布隆过滤器。下面看下哪些地方会用到布隆过滤器,哪些地方不会用到布隆过滤器。
下面场景的查询可以使用布隆过滤器:
- 包含至少一个过滤表达式,如
{env="prod"} |= "order=17863472" | logfmt就可以使用布隆过滤器,但{env="prod"} | logmt则不会
下面查询则会阻止使用布隆过滤器:
- 布隆过滤器并不适用于非等式过滤:常规和正则表达式过滤器。如
!= "debug"和!~ "(staging|dev) "都不会使用布隆过滤器 line_format之后的过滤表达式也不会使用布隆过滤器。如 |= `level="error"` | logfmt | line_format "ERROR {{.err}}" |= `traceID="3ksn8d4jj3"` 其中 |= `level="error"`将使用布隆过滤器,但 |= `traceID="3ksn8d4jj3"` 则不会使用。- 查询尚未从Bloom gateways下载的Bloom blocks。
总结
Loki新引入的这个特性包含两个组件compactor和gateway。compactor用于生成序列的布隆过滤器, 布隆过滤器有两种,一种是根据序列表达式生成的n-grams布隆过滤器,另一种是将序列表达式和对象存储的buckets关联起来的布隆过滤器。当gateway接收到一个查询请求时,会根据该请求序列表达式生成n-grams,然后在第一个布隆过滤器中查找是否存在该序列,如果不存在则直接返回,如果存在则继续通过第二个过滤器排除掉不匹配请求表达式的buckets,进而减少需要处理的buckets。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/18298453

