
为媒体资产构建一个云原生的文件系统
Netflix Drive: 为媒体资产构建一个云原生的文件系统
Netflix Drive是一个多接口、多OS的云文件系统,旨在为设计师的工作站提供典型的POSIX文件系统和操作方式。
它还可以作为一个具有REST后端的微服务,内含很多工作流所使用的后端操作,以及无需用户和应用与文件和文件夹直接交互的自动化场景。REST后端和POSIX接口可以共存于任何Netflix Drive实例中,无需手动排除。
Netflix Drive框架中采用了事件告警后端。事件和告警是Netflix Drive的一等公民。
我们将Netflix Drive定义为通用框架,支持用户选择不同类型的数据和元数据存储。例如,可以使用DynamoD作为Netflix Drive的元数据存储,也可以使用MongoDB和Ceph Storage作为后端数据存储和元数据存储。更多参见完整的视频演示
译自:Netflix Drive: Building a Cloud-Native Filesystem for Media Assets
为什么构造Netflix Drive
总的来说,Netflix开创了云娱乐工作室的概念,它允许全球的设计师共同协作。为此,Netflix需要提供一个分布式、可扩展的高性能基础设施平台。
在Netflix,资产指由不同的系统和服务保存和管理的、包含数据和元数据的一系列文件和目录。
从数据采集开始,即当摄像机记录视频(产生数据),到数据变为电影和电视节目,这些资产会基于创作流程,被不同的系统打上各种元数据标签。
在边缘(即使用资产的设计师),设计师和他们的应用会希望使用一个接口来无缝访问这些文件和目录。当然,该工作流并不仅适用于设计师,也适用于工作室。一个最好的例子是,在使用Netflix Drive进行内容渲染的过程中会发生资产转换。
工作室流程中需要在不同的创作迭代阶段中转移资产,每个阶段都会给资产打上新的元数据标签。我们需要一个能够在数据中添加不同形式的元数据的系统。
我们还需要在每个阶段中支持多种级别的动态访问控制,这样就可以在平台项目中限制特定应用、用户或流程可以访问的资产子集。我们调研了AWS Storage Gateway,但其性能和安全性无法满足我们的需求。
最后诉求于设计Netflix Drive来满足多种场景的需求。该平台可以作为一个简单的POSIX文件系统,将数据保存到云端或从云端检索数据,同时也可以包含丰富控制接口。它将成为支持大量Netflix工作室和平台的基础存储设施的一部分。
Netflix Drive的架构
图1展示了Netflix Drive的接口:

图1:Netflix Drive的基础架构
POSIX接口(图2)展示了简单的针对文件的文件系统操作,如创建、删除、打开、重命名、移动等。该接口与Netflix Drive的数据和元数据操作进行交互。不同的应用、用户和脚本或流程可以对保存在Netflix Drive中的文件执行读取、写入、创建等操作,类似于其他文件系统。
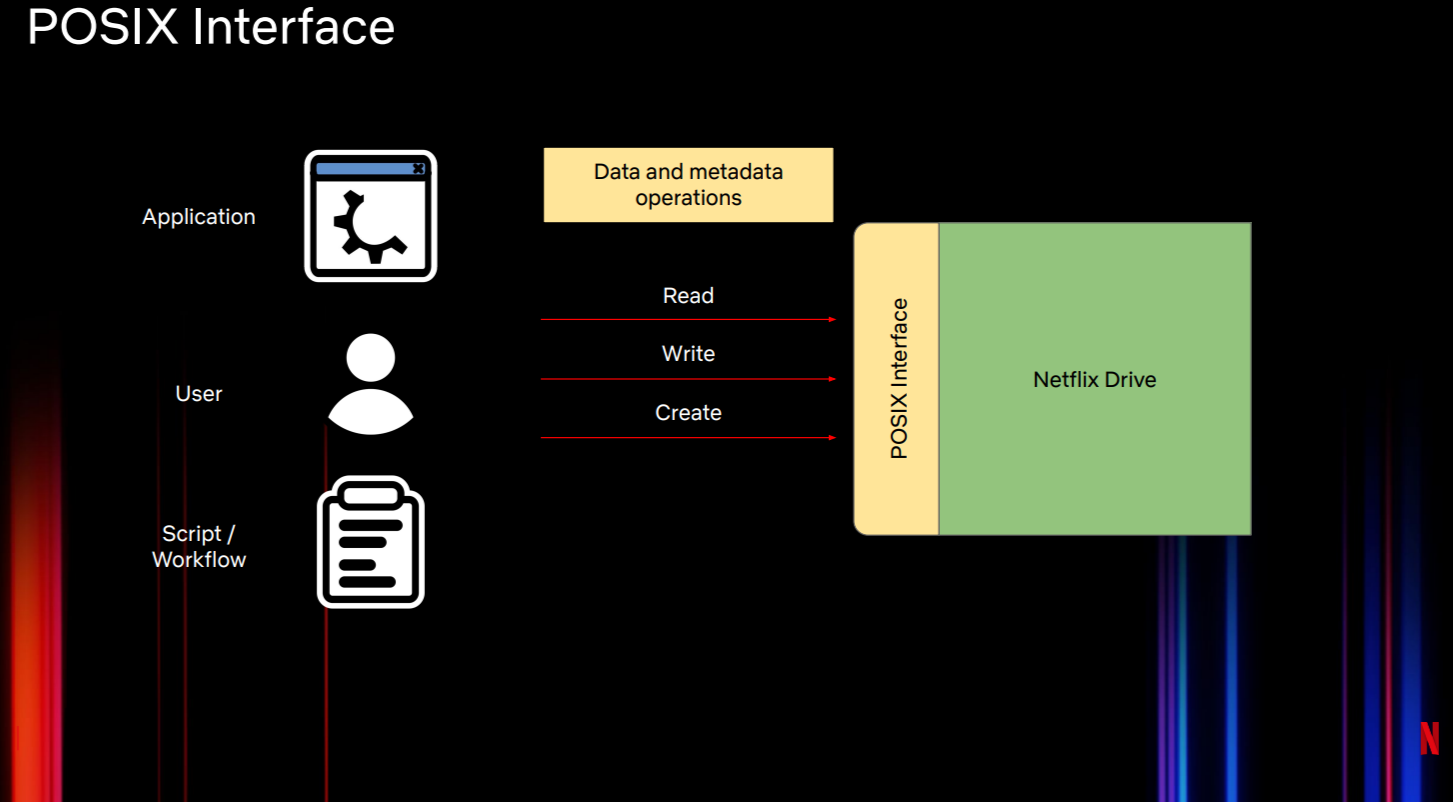
图2:Netflix Drive 的POSIX接口
图3展示了其他API接口。它提供了一个可控制的I/O接口。该API接口特别适用于某些流程管理工具或代理。它暴露了某种形式的控制操作。工作室的很多流程对资产或文件都有一定的了解,它们希望控制投射到命名空间的资产。一个简单的例子是,当在用户机器上启动Netflix Drive时,流程工具一开始会通过这类API限制用户只能访问一部分数据。该API还需要支持动态操作,如将特定文件更新到云端或动态下载特定的资产集,并将其附加并展示到命名空间的特定点上。
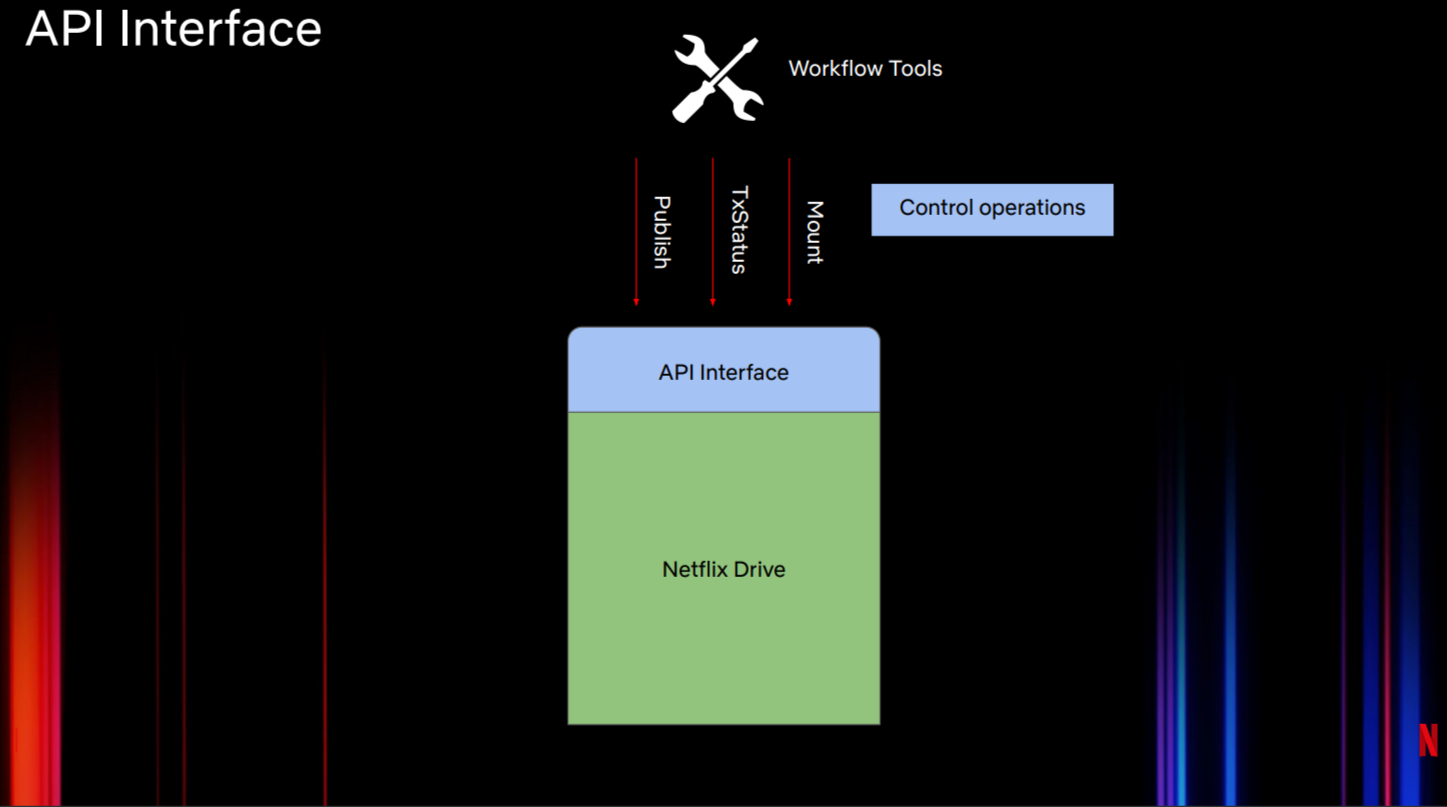
图3:Netflix Drive的API接口
如上所述,事件(图4)位于Netflix Drive架构的最重要位置,事件包含遥测信息。典型的例子是使用审计日志来跟踪用户对文件的操作。我们可能希望运行在云端的服务能够消费日志、指标以及最新情报。我们使用通用框架来允许在Netflix Drive生态中插入不同类型的事件后端。
还可以在Netflix Drive之上构建事件接口。我们可以使用该接口创建共享文件和文件夹的概念。
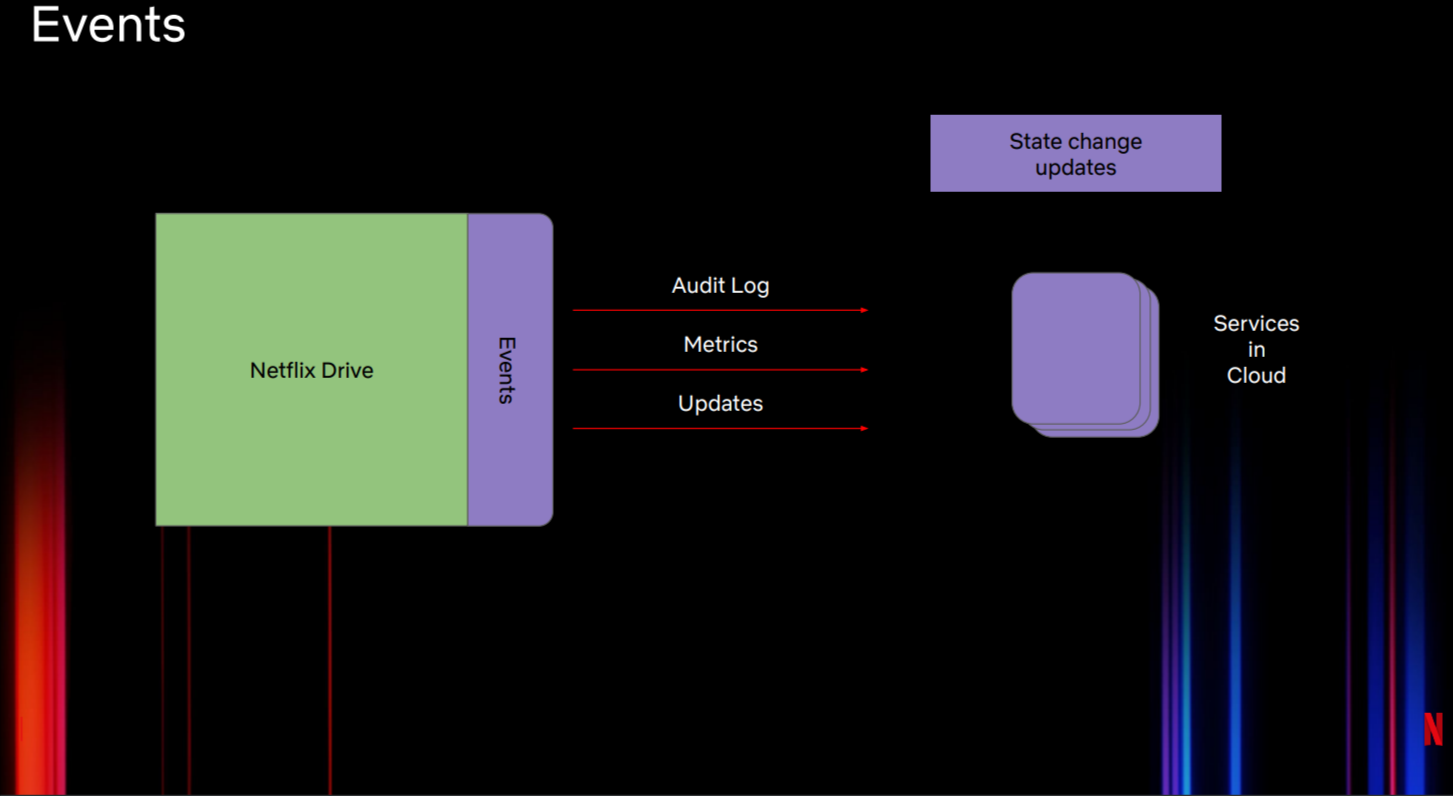
图4:Netflix Drive的事件
数据转换层(图5)负责将Netflix Drive的数据转换到多个存储层或不同类型的接口中。它可以将文件放入设计师的工作站或机器的Netflix Drive挂载点中。
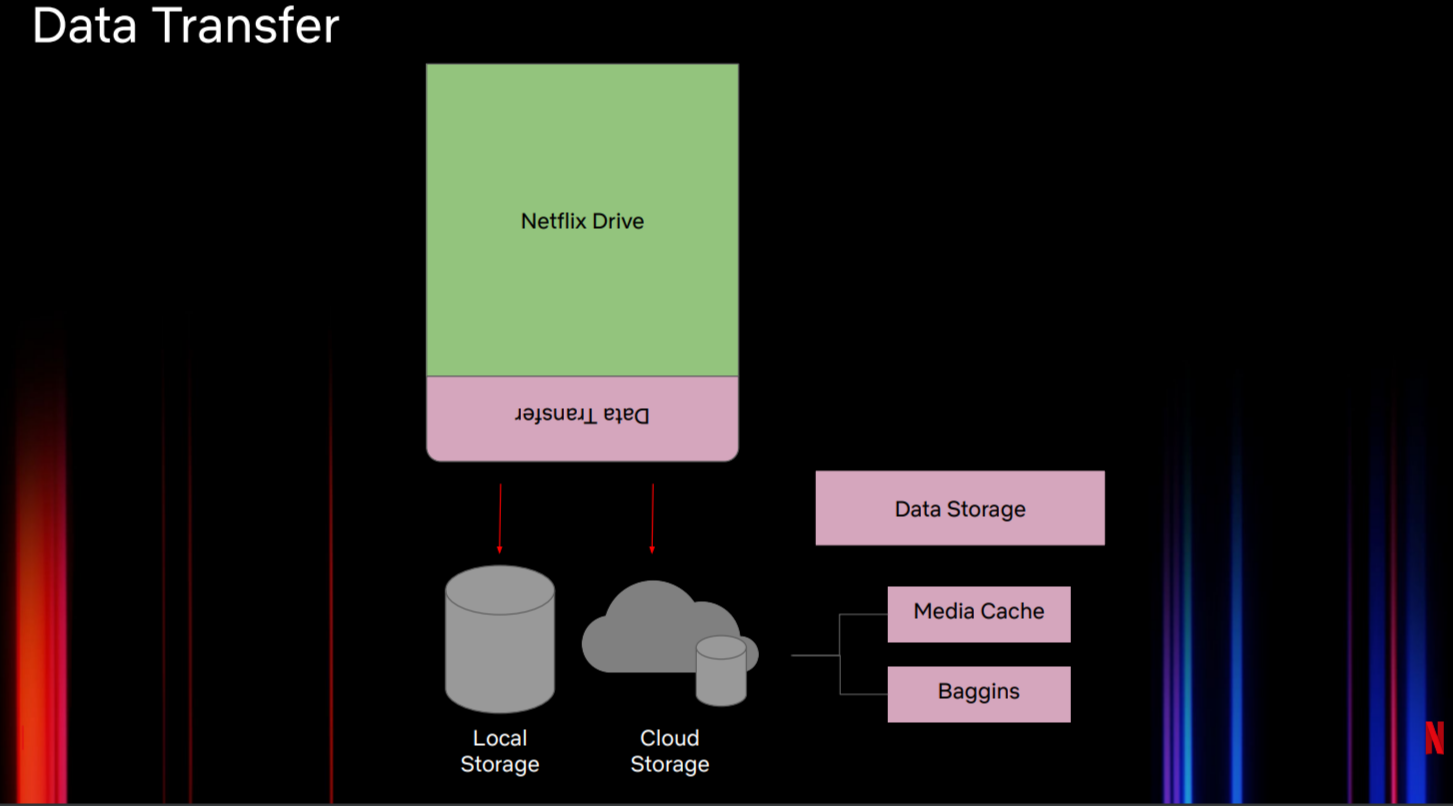
图5: Netflix Drive中的数据转换
出于性能的原因,Netflix Drive不会将数据直接发送到云端。我们希望Netflix Drive像本地文件系统一样运行,可能的话,先保存文件,然后使用某些策略将数据从本地存储上传到云端存储。
通常我们会使用两种方式来上传数据。第一种方式中,控制接口使用动态触发APIs来允许工作流将一部分资产上传到云端。另一种为自动同步,即自动将本地文件同步到云端存储,这与Google Drive的方式相同。为此,我们有不同的云存储层。图5特别提到Media Cache和Baggins:Media Cache是一个区域感知存储层,用于将数据传递给最近的边缘用户,Baggins位于S3之上,处理分块和加密内容。
总之,Netflix Drive架构设计了操作数据和元数据的POSIX接口。API接口处理不同类型的控制操作,事件接口会跟踪所有状态变更,数据传输接口负责在Netflix Drive和云端传输字节数据。
剖析Netflix Drive
Netflix Drive架构(图6)包含3层:接口、存储后端和传输服务。
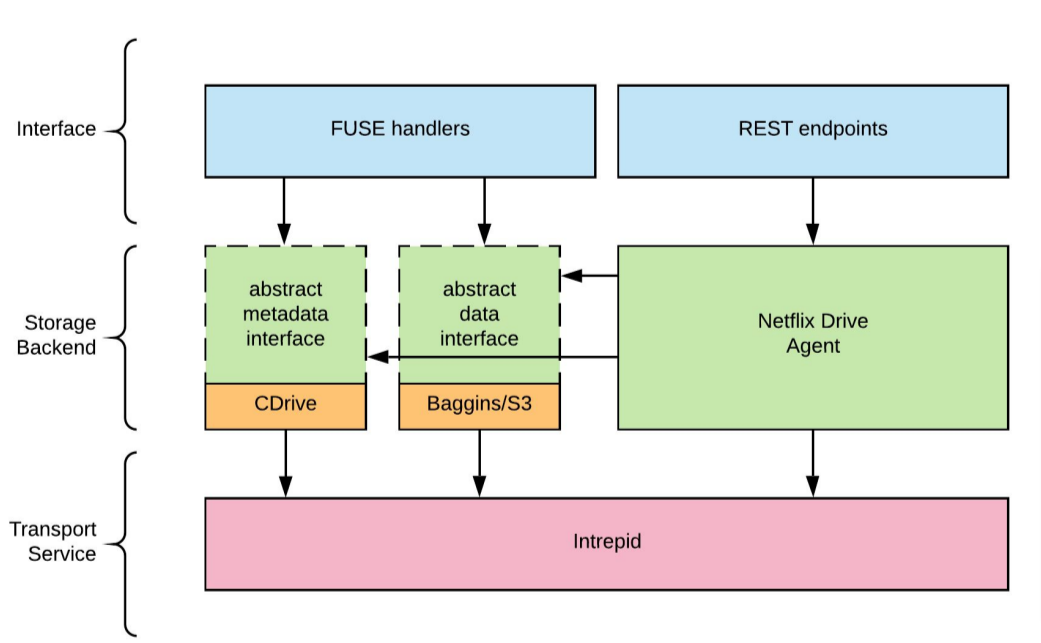
图6:剖析Netflix Drive
最上层接口包含所有的FUSE文件处理程序以及REST后端。
中间层是存储后端层。Netflix Drive提供了一个框架来帮助安装不同类型的存储后端。这里我们抽象了元数据接口以及数据接口。在第一个迭代中,我们使用CDrive作为元数据存储。CDrive是Netflix自有的工作室资产元数据存储。Baggins是Netflix的S3存储层,在将数据推送到S3之前会进行分块和加密。
Intrepid是传输层,负责在云端和Netflix Drive之间传输字节数据。Intrepid是一个内部开发的高效率传输协议,很多Netflix应用和服务会用它来传输数据。Intrepid不仅可以传输数据,还可以传输某些类型的元数据。我们需要这种能力来在云端保存元数据存储的某些状态。
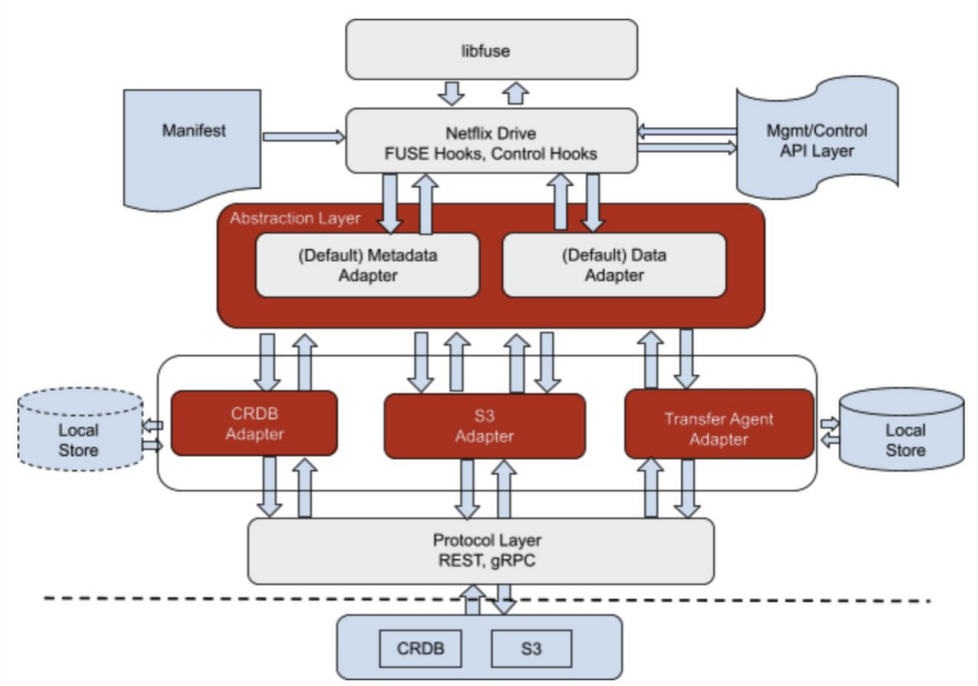
图7:Netflix Drive的抽象层
图7展示了Netflix Drive的抽象层
由于我们使用了基于FUSE的文件系统,需要使用libfuse来处理不同的文件系统操作。 我们启动Netflix Drive,并使用清单、REST API和控制接口进行引导。
抽象层抽象了默认的元数据存储和数据存储。可以有不同类型的数据和元数据存储--在下面例子中,我们使用CockroachDB适配器作为元数据存储,并使用S3适配器作为数据存储。还可以使用不同类型的传输协议,这些是Netflix Drive中即插即用接口的一部分。协议层可以是REST或gRPC。最终构成了真正的数据存储。
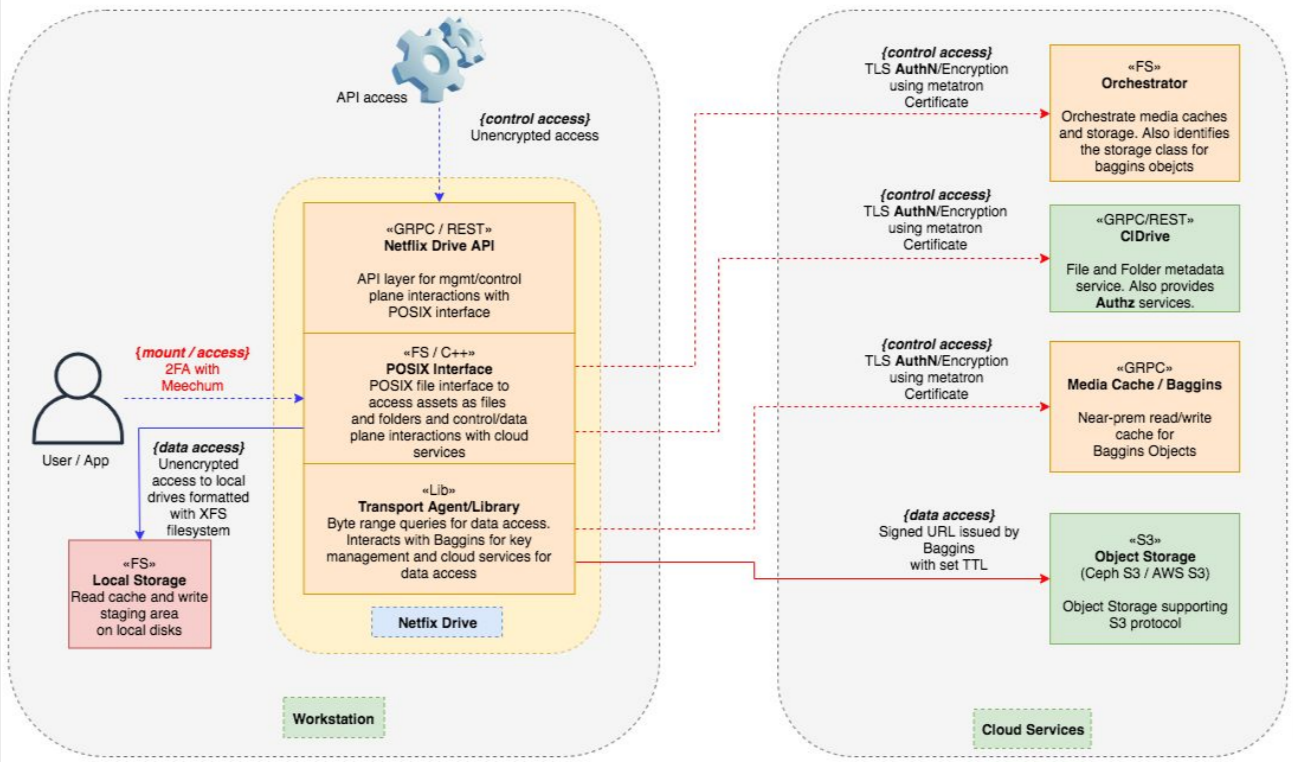
图8:Netflix Drive的抽象层
图8展示了服务是如何在本地工作站和云端进行划分的。
工作站机器包含典型的Netflix Drive API和POSIX接口。本地Netflix Drive会使用传输代理和库与元数据存储和数据存储进行交互。
云服务包含元数据存储,即Netflix的CDrive。媒体缓存作为存储的中间层,S3提供对象存储。
注意到我们还使用本地存储来缓存读写,以此来提升用户对Netflix Drive的性能预期。
Netflix Drive还需要关注安全性。很多应用程序使用云服务;它们在Netflix的所有资产中占比最大。必须确保这些资产的安全,仅允许那些具有适当权限的用户查看允许其访问的资产子集。为此,我们在Netflix Drive上启用了双因子身份验证。
我们在CockroachDB之上构建了安全层。目前Netflix Drive使用了Netflix中的一些安全服务,但不支持插入外部安全API,我们计划后续在发布开源版本之前将其抽象出来,以便所有人都可以通过构建可插拔模块来处理这一问题。
Netflix Drive的生命周期
鉴于Netflix Drive能够动态显示命名空间,并将不同的数据存储和元数据存储结合在一起,因此必须考虑其生命周期。
一开始我们会使用一个清单来引导Netflix Drive,且初始的清单为空。我们可以允许工作站或工作流从远端下载资产,并使用该内容来预加载Netflix驱动器挂载点。工作流和设计师会对变更资产,而Netflix Drive会周期性地调用API进行快照或使用自动同步功能将这些资产上传到云端。
在引导过程中,Netflix Drive通常需要明确挂载点,此时需要用到用户的认证和授权身份。该挂载点建立在本地存储上,用来缓存文件,并作为后端云元数据存储和数据存储。清单中包含可选的预加载内容字段。
当不同类型的应用程序和工作流使用Netflix Drive时,可以根据应用程序和工作流的角色来选择特定的运作风格。如果一个应用了解资产,它可能会依赖特定的REST控制接口来将文件上传到云端。而另一个应用在上传文件时则无需了解资产,因此可能会依赖自动同步功能,在后台上传文件。这些是Netflix Drive为每个角色定义的多种备选方案。

图9:简单的Netflix Drive引导清单
图9展示了简单的引导清单。在定义完本地存储之后,展示了实例信息。每个挂载点可以包含多个不同的Netflix Drive实例,下面使用了两个实例:一个动态实例和一个用户实例,每个实例都有不同的后端数据存储和元数据存储。动态实例使用一个Redis元数据存储以及一个S3数据存储。用户实例使用CockroachDB 作为元数据存储,并使用Ceph作为数据存储。Netflix Drive为每个工作区分配了一个唯一标识。
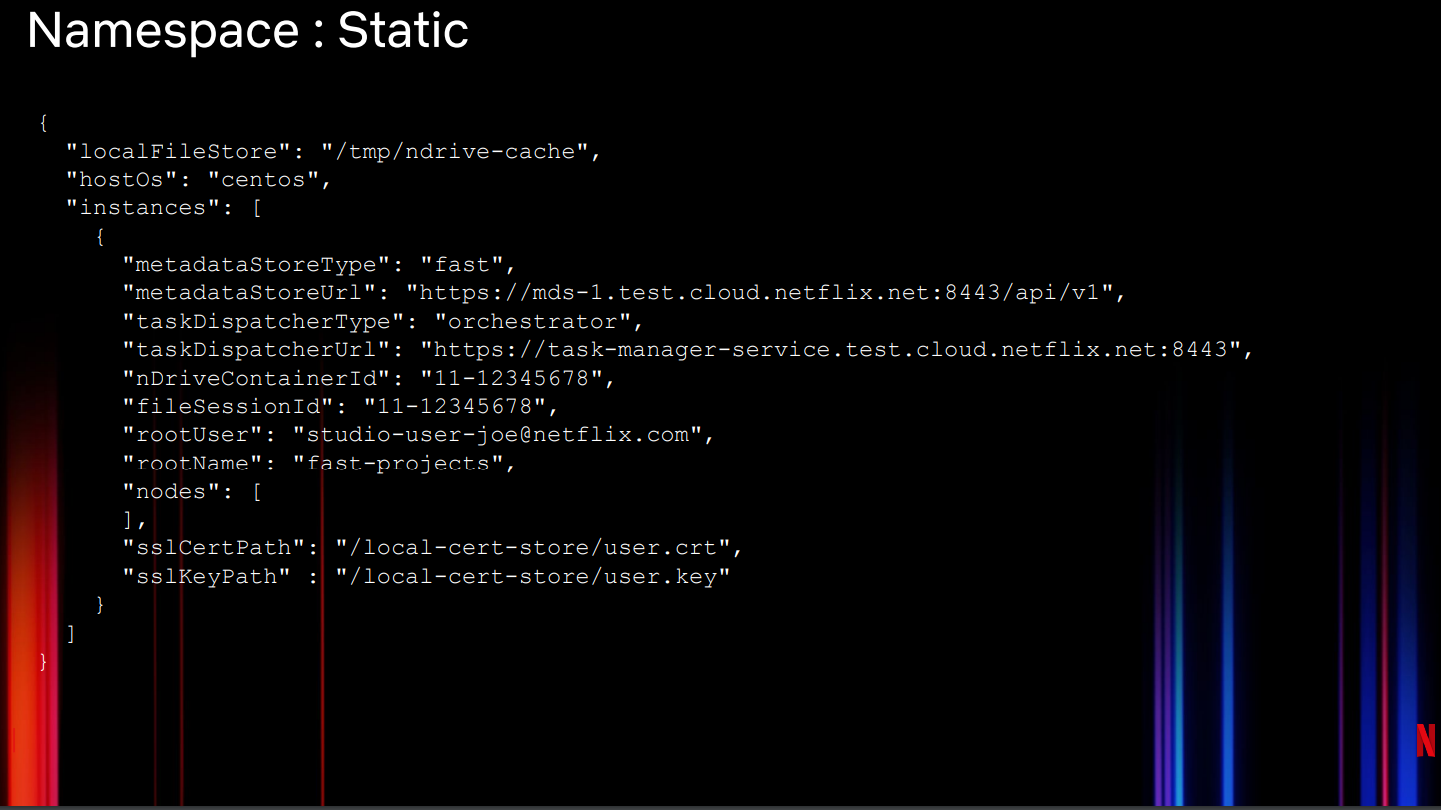
图10:静态配置一个Netflix Drive命名空间
Netflix Drive的命名空间是指内部查看的所有文件。Netflix Drive可以静态或动态创建命名空间。静态方法(图10)在引导时指定了需要预下载到当前实例的确切文件,为此我们提供了一个文件会话以及一个容器信息。工作流可以在文件中预填充Netflix Drive的挂载点,这样就可以在其之上构建后续工作流。
动态创建命名空间需要在REST接口中调用Netflix Drive APIs(图11),这种情况下,我们会使用暂存API来暂存并从云存储中提取这些文件,然后将其附加到命名空间的特定位置。静态和动态接口并不互斥。
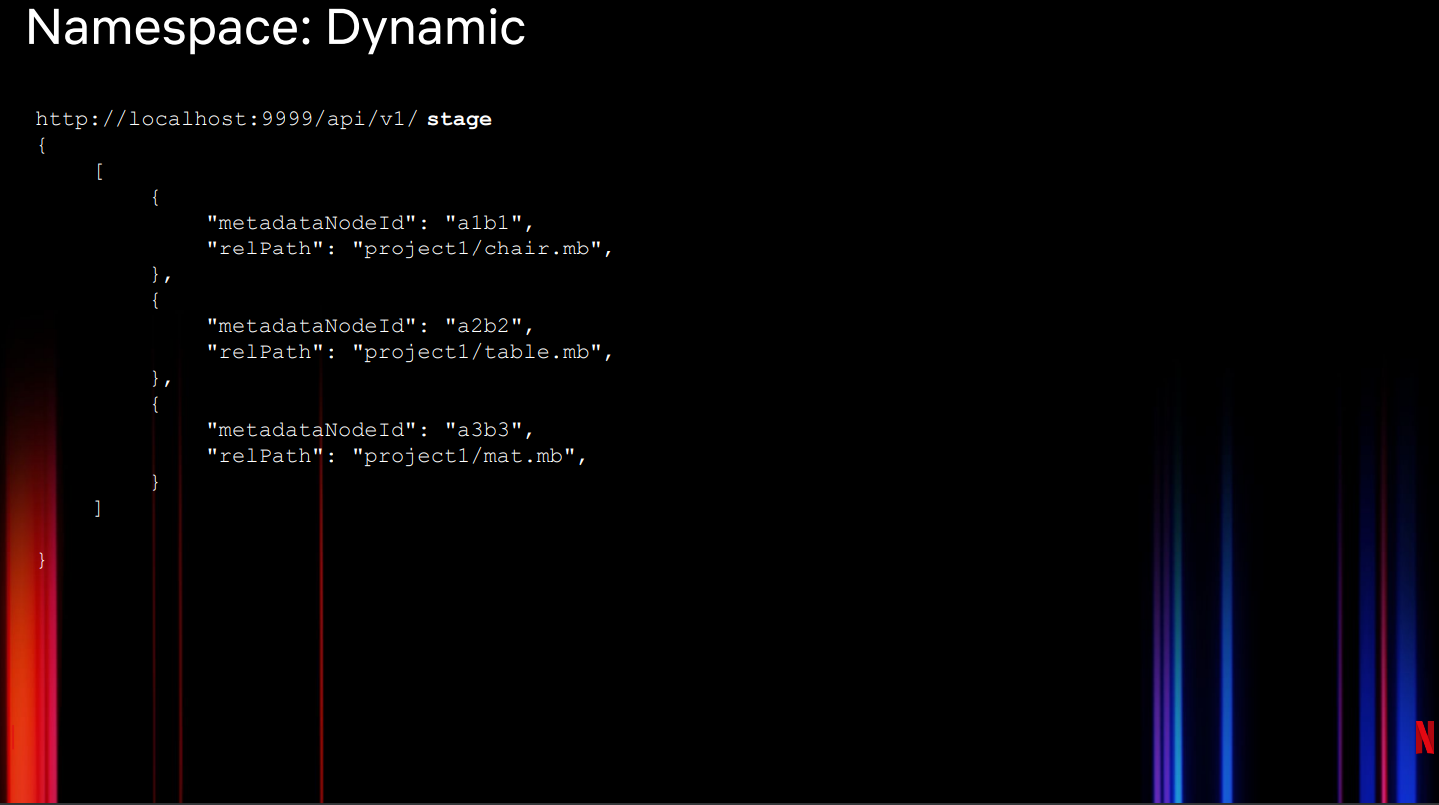
图11:动态配置Netflix Drive命名空间
更新内容
Netflix Drive上的POSIX接口可以支持open/close、move、read/write等文件操作。
部分REST API可以修改文件--例如,某个API可以暂存文件,从云端拉取文件;某个API可以检查文件;某个API可以保存文件,显示地将文件上传到云存储。
图12是展示了如何使用Publish API将文件上传到云端。我们可以自动保存文件,定期检查上传到云端的文件,并进行显示保存(上传到云端)。显式保存可以是不同工作流发布时调用的API。
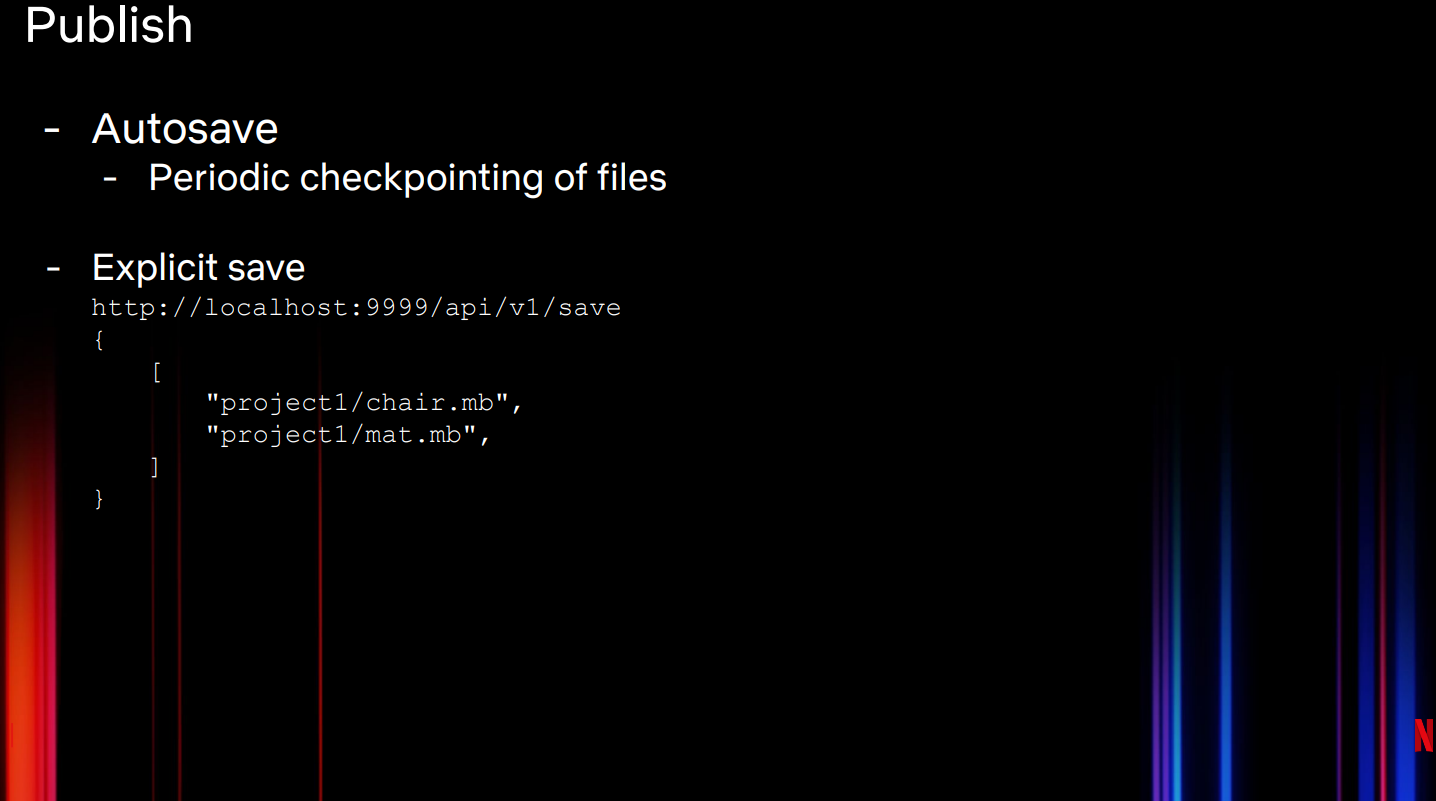
图12:Netflix Drive发布API
使用不同APIs的一个典型例子是:当设计师大量使用临时数据时。由于这类数据仅仅用于过程处理,而不是最终产品,因此大部分不需要上传到云端。对于这类工作流,应该使用显示保存,而非自动保存,Google Drive就是这种模式。一旦设计师确定可以将资产共享给其他设计师或工作流,此时可以调用API将其上传到云端。API会在设计师的Netflix Drive挂载点对所选的文件进行快照,将其上传到云端,并保存到特定的命名空间中。
经验
在支持不同工作流中的多个角色使用Netflix Drive过程中,我们吸取了很多经验。
文件、工作流、设计师工作站的性能/延迟,以及我们希望为使用Netflix Drive的设计师提供的体验,决定了架构的方方面面。我们使用C++实现了大部分代码。我们对比了编程语言,发现C++的性能最佳。没有考虑使用Rust的原因是此时Rust在FUSE文件系统的支持度还不够成熟。
我们倾向于将Netflix Drive作为一个通用的框架,支持任何数据存储和元数据存储。为某些操作系统设计通用框架是比较困难的。在调研过可替代方案后,我们决定让Netflix Drive支持CentOS、macOS和Windows上的FUSE文件系统。这增加了我们的测试矩阵和保障矩阵。
我们使用不同的后端,有不同的缓存层和存储层,并依赖缓存的元数据操作。Netflix Drive支持EB级别的数据以及十亿级别的资产。可扩展性是架构的另一个考量点。我们通常认为,云上的扩展解决方案的瓶颈是数据存储,但最后发现元数据存储才是瓶颈。扩展的关键是处理元数据。我们重点关注元数据处理,并减少元数据存储的调用量。通过在本地缓存大量数据可以提高工作室应用和工作流的性能,这些应用和工作流通常需要大量元数据。
我们调研了云文件系统,如EFS,但使用文件系统无法扩展挂载点,且会影响到性能。为了服务十亿级别的资产,我们需要使用某种形式的对象存储,而非文件存储。这意味着设计师的文件将会被转换为对象(文件和对象作一对一映射)--这种方式过于简单,但文件大小可能超过支持的最大对象大小。我们希望将一个文件映射成多个对象。如果设计师修改了文件的某个像素,Netflix Drive能够只修改包含相关文件块的对象。构建转换层是权衡之下的选择,同时这种方式也提升了扩展性。
使用对象带来的问题是去重和分块。对象存储使用版本控制:每次变更对象时,无论变更大小,都会创建一个新版本对象。因此,修改文件的一个像素会导致传送整个文件,并覆盖原有对象。无法发送并在云存储中使用增量数据。通过将一个文件分为多个对象,可以降低发送到云端的对象大小。选择合适的块大小与其说是一门科学,不如说是一门艺术,因为更小的块意味着需要更多的数据以及转换逻辑,并增加了元数据量。另一个需要考虑的是加密。我们需要对每个块进行加密,因此更小的块会导致使用更多的加密密钥以及元数据加密。Netflix Drive的块大小是可配置的。
多存储层可以提升性能。当我们设计Netflix Drive时,并没有限制仅使用本地存储还是云存储。我们希望将其构建为:可以方便地在框架中添加存储层。该观念贯穿整个设计、架构和代码。例如,我们的媒体缓存仅仅是一个靠近用户和应用的缓存层。Netflix Drive在本地文件存储中缓存了大量数据(Google Drive则不会这么做),因此可以较Google Drive可以更好的利用到本地文件系统的性能。
还有一个不使用AWS Storage Gateway的原因。如果多个设计师共同操作一个资产,并将每次迭代的资产都保存到云端,这样我们的云开销会爆炸。我们希望将这些资产保存到靠近用户的媒体缓存中,并控制何时将最终拷贝发送到云端。我们可以利用这种混合基础设施,以及AWS Storage Gateway提供的参数。
软件架构采用堆叠式方法至关重要。一个很好的例子是使用共享命名空间。我们目前正在开发支持不同工作站或命名空间的文件共享。我们将此构建在事件框架之上,并将其设计为Netflix Drive架构的一部分。当一个Netflix Drive实例上的用户向一个命名空间添加文件时,它可以生成多个云服务可能消费的事件。然后Netflix Drive使用REST接口将文件注入访问该命名空间的其他Netflix Drive实例中。
更多参见技术博客.
总结
本文介绍了Netflix自研的文件系统Netflix Drive。自研文件系统的一个原因是现有云服务无法满足业务场景,如多挂载点、使用本地缓存、文件切分等。
Netflix Drive通过使用本地缓存,减少了云存储的开销(如通过缓存减少了对象存储API的调用次数)。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/16369126.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号