


全局负载均衡方案
全局负载均衡方案
译自:Global Load Balancer Approaches
本文经验更适用于混合云场景,公有云一般直接使用供应商提供的LB即可。
简介
当在多云(可能是混合云)中使用Kubernetes或Openshift部署应用时,需要考虑到如何跨集群分发应用流量。为了解决该问题,我们设计了一个全局负载均衡器。
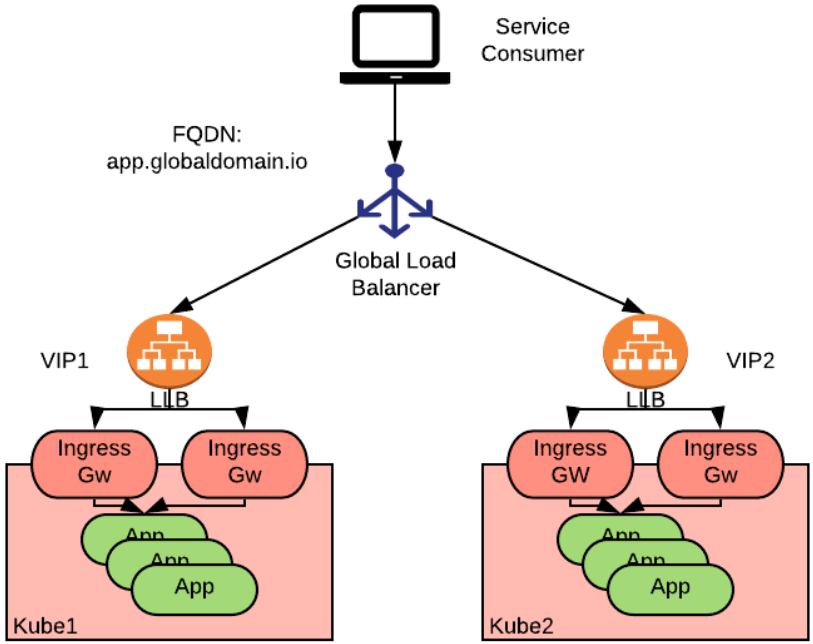
上图描述了一个称为"app"的应用,并将其部署到了两个Kubernetes集群中,通过 Ingress 或 Gateway APIs资源(本地负载均衡器,简称LLB)进行访问,LLB对外暴露了两个虚拟IP:VIP1和VIP2。全局负载均衡器位于LLB之上,用于将消费者(指一个全局的FQDN,上例中为app.globaldomain.io)定向到某个集群的应用中。
在本文发表时(October 5, 2021),Kubernetes 社区中并没有明确的指导方案来告诉用户如何设计和实现Kubernetes集群的全局负载均衡器。
在本文中,我们会讨论如何设计一个合理的全局负载均衡器,以及如何根据Kubernetes集群中运行的负载来实现自动配置。
在选择具体的架构前,首先看下常用的全局负载均衡器的特点。
全局负载均衡器的要求
Kubernetes集群的全局负载均衡器负责将到服务的连接路由到某个Kubernetes集群中运行的实例上。这些集群可以是物理上分开的,也可以位于相同的区域。
Kubernetes提供了两种主要的方式来控制进入集群的流量:Ingresses(Ingress, Gateway API 和 OpenShift Routes) 和LoadBalancer 服务。
我们的全局负载均衡器两种都要支持,需要注意的是,对于ingresses(L7反向代理)的场景,我们提供了一个暴露VIP的多应用共享的本地负载均衡器。
再者,全局负载均衡器应该提供除轮询之外的复杂的负载均衡策略。实践中,一个策略通常能够根据某些指标(延迟、地理距离等)来给尝试连接的消费者返回最近的端点。在地理上分布的场景中,该策略允许消费者以最小的延迟连接到后端。在相同区域的场景中,允许在同一数据中心内路由连接。
另一个常见的策略是路由权重,通过一次只给一个集群分配权重来达到正向/反向配置的效果。
最后,一个全局负载均衡器应该在应用不可达时将流量导入健康的后端,这通常需要配置健康检查。
概况一下一个全局负载均衡器的要求:
- 能够支持LoadBalancer Services 和Ingresses的负载均衡
- 复杂的负载均衡策略
- 支持健康检查,并能够从负载均衡池中移除不健康的后端
全局负载均衡器架构选型
基于我们的经验,可以通过如下两种架构方案来设计全局负载均衡器:
- 基于DNS
- 基于任播(Anycast)
基于DNS方案
在基于DNS的方案中,通过一个DNS服务来决定负载均衡。

在上图中可以看到,一个服务消费者首先会向DNS服务请求app.globaldomain.io,然后DNS服务会返回其中一个集群的地址。
鉴于DNS服务是所有网络基础设置必不可少的一部分,因此基于DNS的负载均衡的好处是相对容易实现。但简单的同时也带来了一系列的限制:
- 客户端需要在一定时间内(通常为DNS TTL,但不保证)缓存DNS的响应结果。但如果缓存的地区出现中断,则在该地区问题解决之前或DNS缓存刷新之前,客户端可能无法继续运作。
- 当DNS服务配置为返回多个IP值时,客户端需要负责选择连接的后端,这有可能导致流量不均衡。即使DNS服务器将返回IP的顺序随机化,也会发生这种情况。这是因为DNS规范中没有规定在响应返回DNS服务层次结构时必须保留IP的顺序,或者服务使用者必须遵守该顺序。
除了上述限制,典型的DNS服务并不支持复杂的负载均衡策略,也不支持对后端的健康检查。
但有一些高级的DNS实现可以支持这些特性:
- 网络设备,如F5 BigIP 和 Citrix ADC,通常位于本地数据中心
- DNS托管服务,如Infoblox 和 CloudFlare
- 大型公有云服务商的DNS服务:AWS Route53, Azure Traffic Manager
注意,当实现这些全局负载均衡器方案时,如果Ingresses (Ingress v1, v2 或OpenShift Routes)正在路由到应用的流量,则ingress中配置的主机名必须与消费者在查询DNS服务器时使用的全局FQDN相同。该主机名与应用的默认地址不同,默认地址通常是集群特定的,必须显式设置。
概括
| 基于DNS的负载均衡 | 简单DNS 服务 | 高级DNS 服务 |
|---|---|---|
| 支持负载均衡服务 | yes | yes |
| 支持Ingress | yes | yes |
| 支持复杂的负载策略 | no | yes |
| 支持健康检查 | no | yes |
| 例子 | 所有DNS 服务 | 本地: F5 BigIP, Citrix ADC等 |
| 限制 | 有可能会出现负载不均衡 当后端出现中断时,反应较慢(30s) |
当后端出现中断时,反应较慢(30s) |
基于任播方案
基于任播的方案是一种架构模式,即很多服务会宣告相同的IP,路由器可以通过不同的网络路径将报文路由到不同的服务。
有两种方式可以实现这种架构:
- 基于IP/BGP的任播服务:设计并使用IP/BGP技术来实现任播负载均衡功能。
- 使用任播/CDN云服务:使用现有的启用任播的网络(如特定的公有云任播服务(可以提供以选播为中心的负载平衡)和CDN服务)。这类公有云服务包括Google Cloud Network Load balancer, AWS Global Accelerator 和其他供应商的简单全局负载均衡服务。
基于IP/BGP的方案
首先看下基于IP/BGP的方案。可以使用配置 BGP 和ECMP了的IPv4,或本身就支持任播的IPv6来实现。
最终的架构如下:
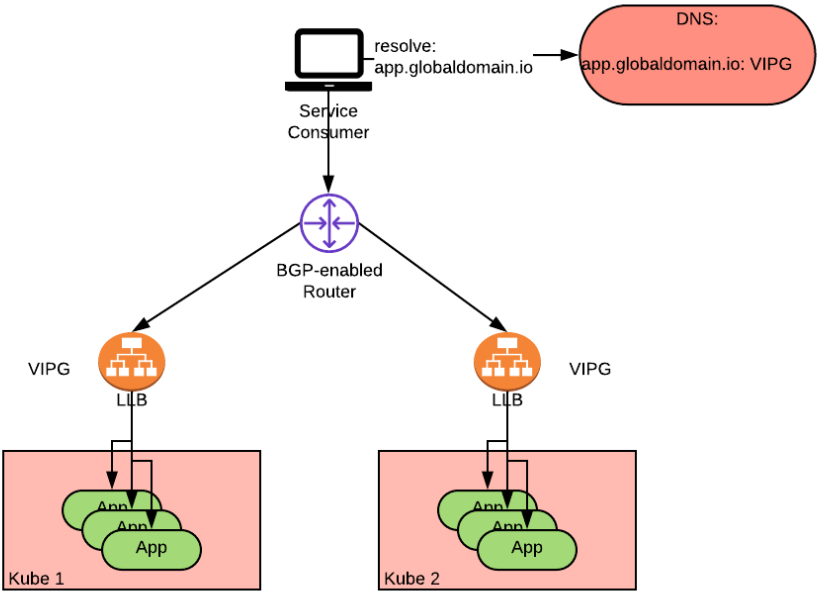
上图展示了一个部署到两个集群的应用,并通过负载均衡器对外提供服务。两个负载均衡器的VIP是相同的(即上图中的VIPG)。通过BGP对路由器进行编程,并给两条路径设置相同的开销(ECMP),以此来实现双活任播负载均衡方案。可以使用备选的BGP指标,如设置不同的开销或本地偏好来实现不同的负载均衡策略,如主备。
可以让一个集群宣告的路由指标比其他集群好得多的方式来实现主备。通常情况下,特定VIP上的所有流量都会路由到该集群(无论该集群与客户端的跳数)。当发生灾难时,会使用优先级较低的路由。
这种方式的好处是依赖路由器而非客户端进行故障切换,其故障切换远比基于DNS的方案快得多(毫秒级别)。
为了获得更好的故障切换体验,路由器需要基于3元组或5元组哈希以及一致性哈希(有时称为resilient hashing)来感知多路负载均衡。如果没有这些功能,则故障切换和可用性可能会受到影响,这是因为在因网络故障事件导致会话从一个后端重新散列和重新路由到另一个后端时,可能会重置大量TCP会话。现代路由器通常会支持这些特性,但需要确保其配置能够支持一致性哈希。
这种方式有如下限制:
- 本地数据中心中的BGP/任播功能不一定可用。
- 由于BGP运行在L3/L4层,因此无法直接独立切换共享相同VIP的多个应用程序(如上图多个APP使用了同一个VIPG,要切换只能一组同时切换,切换粒度比较大)。
Kubernetes的参考实现
实现上述方案的一个可选方式是在BGP模式下使用MetalLB来实现Kubernetes负载平衡器服务,并将群集节点连接到支持BGP的物理网络。
该拓扑结构与上图类似,部署到每个集群节点的MetalLB 代理与外部BGP网络形成对等网络,并通过多个集群的多个节点宣告相同VIP的可达性。
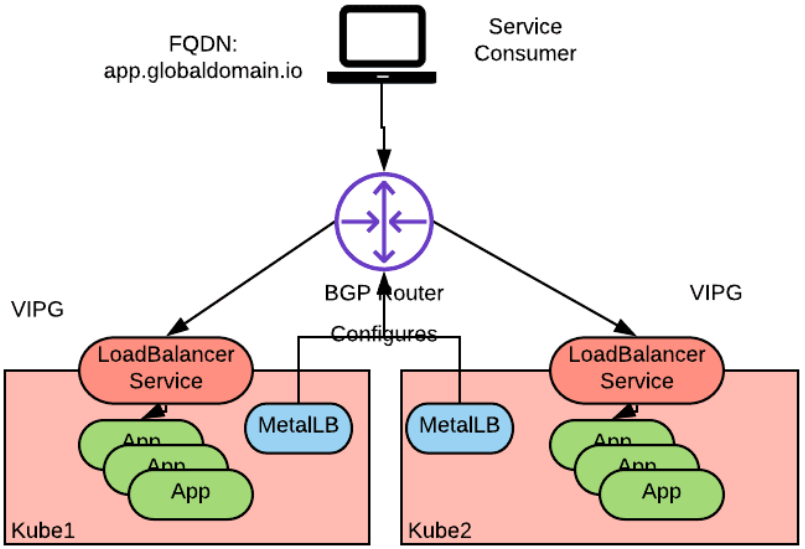
注意上述方案中,无需使用支持BGP路由的CNI插件来实现集群内pod到pod的路由。MetalLB 仅仅使用BGP来向外部网络宣告负载均衡器的VIP。MetalLB 遵循Kubernetes服务规范的负载均衡器API,因此可以用于云供应商不支持或云供应商不遵循负载均衡器API的场景。
为了让全局负载均衡器运作,需要给多个集群配置相同的VIP。
可以引入自动化来同步多个集群的配置。例如,查找全局负载均衡器服务或强制它们配置相同的负载均衡器 VIP。可以通过集中自动化来协调支持BGP路由的指标(如 本地偏好),以此来配置集群的优先级。
基于云服务的任播负载均衡方案
很多公共云提供商支持将全局负载均衡作为一种实现选播方法的服务,因为租户可以使用单个静态全局IP地址,并且可以将其作为多集群多区域服务的前端。
这类服务包括 Google Cloud Network Load Balancer, AWS Global Accelerator, Fastly Anycast 和 CloudFlare Anycast。这些云服务通常会绑定CDN和/或 API网关,但大多数情况下会单纯作为一个全局任播负载均衡服务。
这些服务通常位于边缘云,并宣告全局静态VIP。发送到全局VIP的流量会被定向到离请求者最近的边缘云,然后进行负载均衡并在云供应商内部进行路由(到后端实例)。
这些技术细节由云供应商实现,对最终用户不可见,但通常会涉及基于IP/BGP的任播和弹性ECMP的内部组合。云供应商可以使用其私有网络来提供高级的负载均衡策略和流量控制,但这些特性在不同供应商的实现中有可能会不一致。
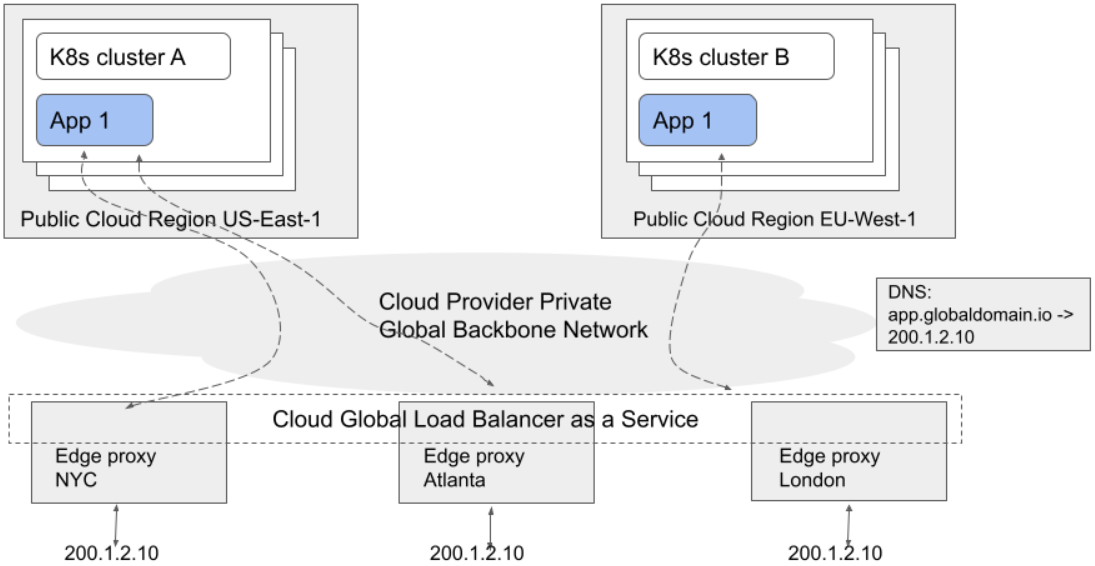
每个任播云服务提供的特性各不相同,包括是否允许客户使用自带的IP,以及全局IP是内部的还是对外的。
概况
| 任播负载均衡 | 简单BGP+ECMP 方案 | 任播LBaaS-based 方案 |
|---|---|---|
| 支持负载均衡器服务 | yes | yes |
| 支持Ingress | no | yes |
| 支持复杂的负载均衡策略 | 一部分 | yes |
| 支持健康检查 | no | yes |
| 例子 | 所有 BGP+ECMP 实现 | LBaaS: Akamai, F5 silverline |
| 限制 | 需要实现满足BGP的负载均衡器服务 | 通常不是本地部署的,每个特定的实现都有额外的限制 |
自带全局负载均衡配置
至此,我们已经调研了几种构建全局负载均衡器的方案。但想象一种场景,如果需要选择一种方式来为部署到上百个集群的应用实现负载均衡,是否存在某种途径来为这些应用自动化创建全局负载均衡配置?
有人可能会使用传统的自动化工具来自动配置网络,但在Kubernetes上下文中,最好的方式是使用operator。
一个全局负载均衡器operator需要监控集群的配置,并基于集群状态来配置全局负载均衡器。这里的一个难点是,现今用于构建operator的生态工具主要面向单个集群,因此大部分operator都是绑定到集群的。
部分出于这个原因,部分出于可以通过多种方式来实现全局负载平衡器,因此Kubernetes社区中似乎没有针对这类operator的官方实现。但可以参考下面两个实现:k8gb 和global-loadbalancer-operator
K8gb
K8gb是一个基于DNS的全局负载均衡operator。K8gb比较有意思的是,DNS服务使用了集群自建的CoreDNS pods。这种方式本身提供了灾难恢复能力以及独立于外部网络的能力。
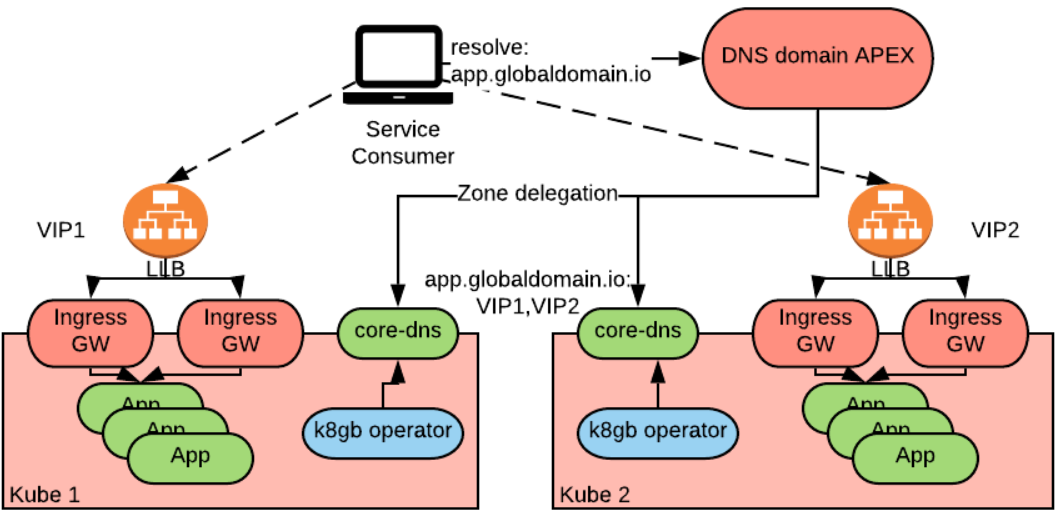
k8gb 的局限是它限制了对高级负载均衡策略的支持。目前正在努力通过使用CoreDNS插件来缓解这些缺点。请参阅最近添加的geoip负载平衡策略来了解正在进行工作。
Global-loadbalancer-operator
global-loadbalancer-operator是一个运行在控制集群(使用全局负载均衡器配置),并监控多个被控制集群的operator。
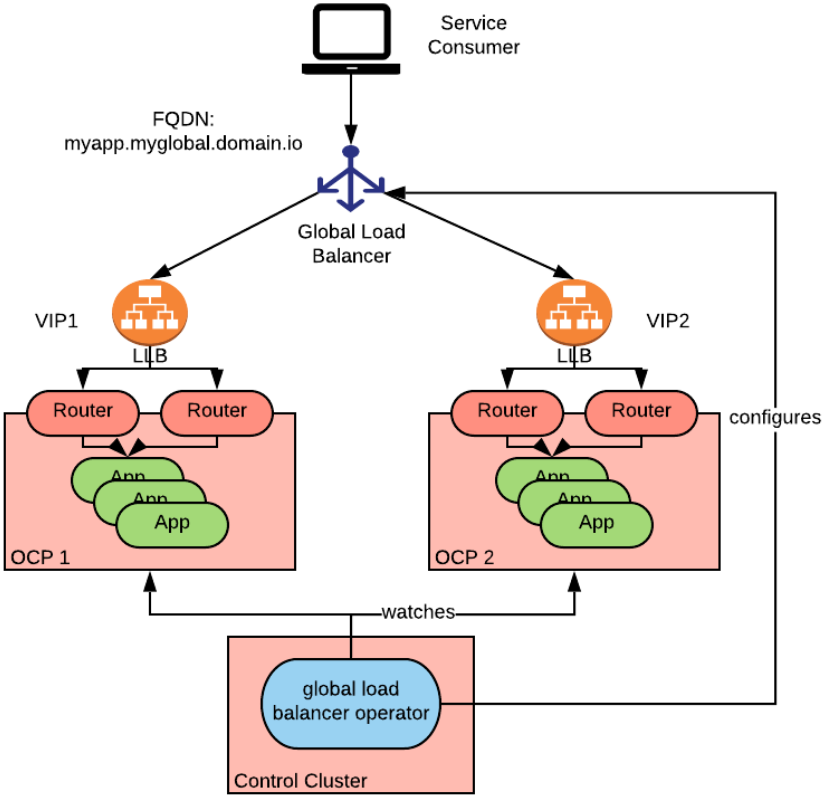
它可以使用所有external-dns operator 中支持的DNS服务来实现基于DNS的全局负载均衡。
它还被设计为同时支持基于DNS和基于云任播的全局负载均衡。当运行在公有云中时,还可以添加高级配置项。
在本文发表时,支持AWS Route53, Azure Traffic Manager 和 Google Global IPs,这些供应商提供了更高级的能力,如不同的负载均衡策略和健康检查等。
需要使用控制集群和仅支持在OpenShift中部署是global-loadbalancer-operator的两个限制。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/15822238.html
