


一种分布式预写日志系统
Waltz 一种分布式预写日志系统
本文讲述了一种分布预写式日志系统Waltz,文中介绍了在实现预写式日志系统时遇到的问题及其解决方案,可以为类似的需求提供一定的启发。
译自:Waltz: A Distributed Write-Ahead Log
简介
Waltz 是一种分布式预写式日志(WAL)系统,一开始它被设计为WePay系统上的货币交易账簿,但后续延申到需要序列化一致性的分布式系统场景中。Waltz 与现有的日志系统(如Kafka)类似,接收/持久化/传递 由很多服务 产生/消费 的事务数据。但与其他系统不同的是,Waltz 提供了一种在分布式应用中序列化一致性的机制。它会在事务提交到日志前进行冲突检测(这也是为什么需要自己实现的原因,它对应用有一定的侵入性)。Waltz 作为单一的事实源头(而非数据库),可以实现以日志为中心的系统架构。
背景
数据库
随着WePay系统的增长,需要处理的流量和功能点也越来越多。我们将一个大型服务分割成多个合理的小服务来更好地管理系统。每个服务通常都有各自的数据库,为了隔离性,不会在服务间共享数据库。
当出现如网络故障、处理故障和机器故障时,并不需要保证所有数据库的一致性。服务间通过网络进行交互,交互通常会更新两端的数据库。而故障可能会导致数据库之间的不一致。大部分不一致可以通过守护进程进行修复,如周期性地进行检修操作,但并不是所有的操作都可以自动执行,有时也需要人工接入。
此外,使用数据库副本来进行容错。我们使用MySQL的异步复制功能,当主域下线后,会切换域,备用域会接手处理,这样就可以继续处理支付业务。多域复制也有自己的问题,主数据库的更新并不会立即反映到备数据库中,两者之间总会存在延迟,且复制延迟也是常态。无法保证新的数据库中包含所有需要更新的数据,也无法保证这些数据能够正常同步。
流处理
我们在很多地方引入了异步处理,并期望推迟那些不需要立即保持一致的更新操作,这样做可以使事务处理变得轻量化,并提升响应和吞吐量。我们使用面向流处理的Kafka来实现这些功能。在一个服务更新自己的数据库的同时,将消息写入Kafka。然后在消费Kafka消息的同时,该服务或其他服务会异步执行其他数据库的更新操作。这种方式行得通,但缺点是一个服务必须写入两个独立的存储系统:数据库和Kafka,此外仍然需要检修。
基本思想
Waltz 中记录的日志既不是从数据库捕获的数据变更输出,也不是来自应用的次级输出,而是系统状态转换的主要信息(可以理解为第一时间获得的数据变更)。它不同于围绕数据库系统构建的典型事务系统(数据库作为事实源头)。在新的模型中,日志作为了事实源头(主要信息),而数据库则衍生自日志(次级信息)。现在的挑战是如何保证数据库中的所有数据与日志保持一致,以及保证序列化的数据的准确性。
如何保证数据库和日志的一致性?保证最终一致性相对比较简单,因为日志中记录的事务是有序且不可变的。如果应用以相同的顺序应用到自身的数据库中,那么结果也是明确的。下面描述了基本的思想:
- 应用构造事务消息,消息中包含对期望变更的数据的描述
- 应用将其发送到Waltz,此时应用还没有更新数据库
- Waltz接收到事务消息后,将其持久化到Waltz日志
- Waltz将事务消息返回给应用
- 应用接收到事务消息,并将数据变更应用到其数据库
下面是一个应用从数据库中读取V=x,并更新到V=y的例子
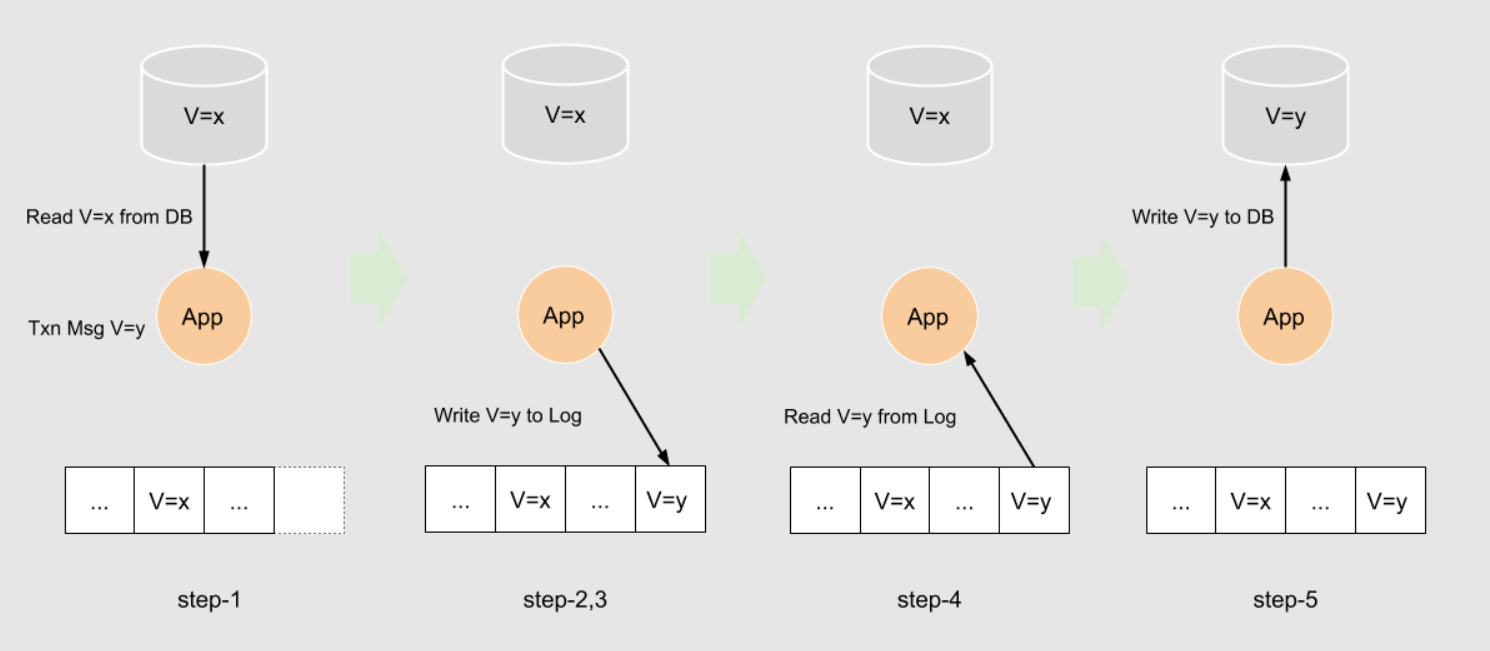
Waltz 日志包含所有的数据变更。通过Waltz的消息(事务数据)来更新应用数据库。因此,Waltz 是主要信息的所有者、事实的源头。而服务的数据库为衍生的信息,可以认为是Waltz 日志物化后的视图。
这样使得应用能够容错。如果一个应用在步骤5之前失败了,此时Waltz 中已经持久化了事务信息,但应用无法更新其数据库,Waltz 将会在重启应用进程之后再次发送事务消息。应用在接收到来自Waltz 的剩余的事务消息之后恢复数据库。
这种设计使得数据复制和共享非常简单。Waltz 允许多个客户端读取和写入相同的日志。可以通过应用Waltz 的消息进行数据复制,且根据应用的需要,相同的事务数据可以用于不同的目的,而无需变更其他应用。它允许在不增加沟通和协调复杂度的前提下,将一个服务划分为更小的服务。
这听起来很不错,但如果考虑一下在可能尝试并行进行数据更新的分布式环境中时,就会意识到保证数据的完整性并没有那么容易。这种场景下多个客户端可能会提交冲突的事务。如果不理会一致性,对所有消息做持久化的话,将必须依赖后处理来解决这些冲突。可能会使用一个数据库进行去重和完整性校验。最终可能会拒绝错误的消息,并向上游服务通知消息的处理状态,并产生一个新的"已清理"日志。这会增加系统设计的复杂度。并增加资源消耗和延迟。最终仍然无法保证后处理数据库和"已清理"日志的一致性。问题又回到了起点。这是使用现有日志系统无法解决的主要难点,这也是为什么我们要实现自己的日志系统,Waltz,可以在第一时间防止发生日志与事务记录不一致的情况。
现有日志系统的难点
在进入细节前,我们展示一下现有使用简单的key-value存储作为日志系统的难点。
读-修改-写的难点
为了使日志作为事实源头,需要在更新key-value存储之前写入日志。服务将新数据发往日志系统,并在接收到日志的新消息之后,将新数据存到KV存储中。假设新数据通过对key-value存储中现有数据的计算而来,那么如何保证更新的正确性?为了正确更新,必须读取最新的数据。但问题是由于存在延迟,KV存储中的数据可能无法反映日志中最新的更新。
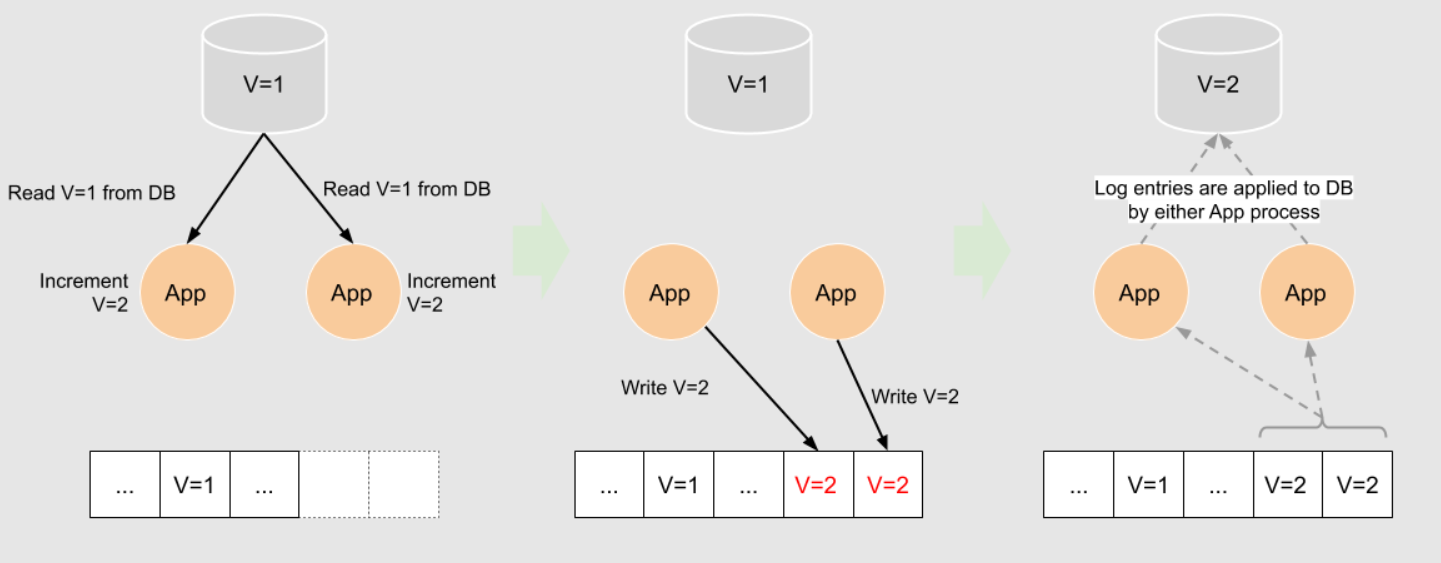
假设有一个简单的计数器服务,它将结果保存在KV存储中:
- 应用发生一个INCREMENT 到服务
- 服务读取当前KV存储中的值
- 服务发送"当前值+1"到日志
- 在接收到日志的新消息后,服务更新KV存储中的计数器值
当服务接同时接收到另一个INCREMENT 请求时会发生竞争。如果在服务完成第一个请求的步骤4前处理了第一个请求的步骤2,则第一个请求会被第二个请求覆盖。最终,两个INCREMENT 请求只增加了一次。
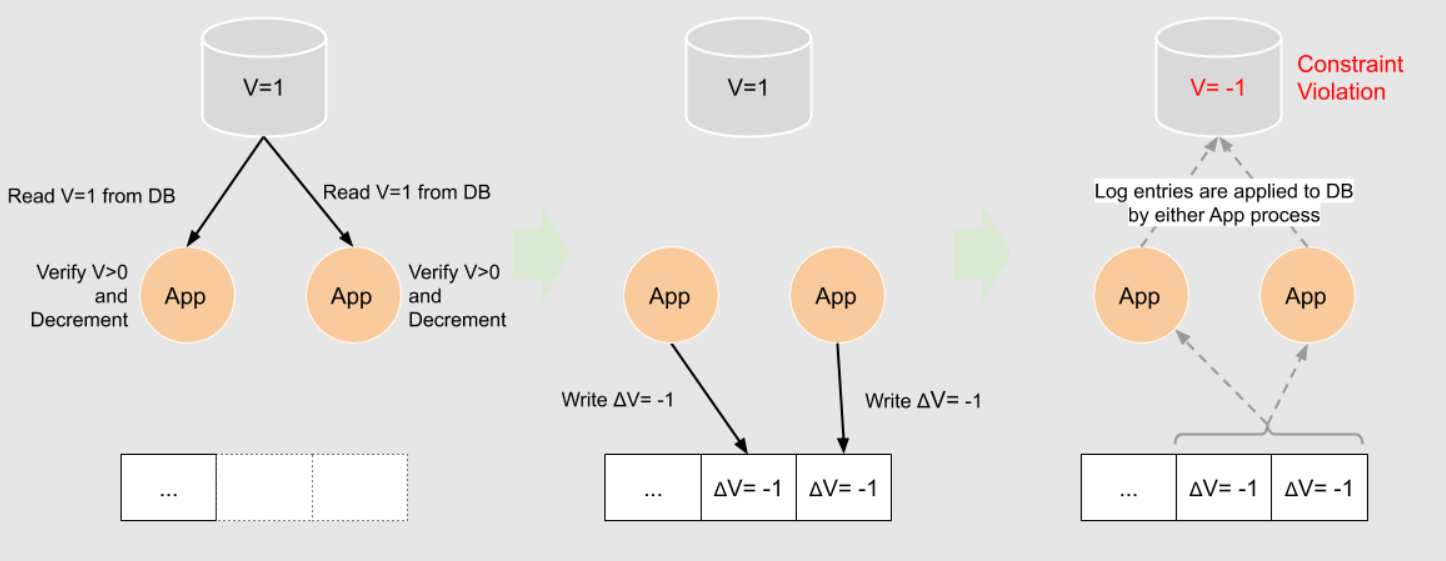
实现约束的难度
在上述场景中,你可能认为消息不应该记录新计算的结果,而应该是差值,如"+1"。由于服务以单一线程的方式消费日志消息,且由于服务接收到的是两个"+1"消息,因此可以正确计算计数器的值。现在假设需要在计数器值上实现一个限制,如"计数器值不能为负"。此时问题又来了,由于服务没有一个可靠的途径了解到真实的当前值(由于竞争),因此无法可靠地实现该限制条件。
重复消息
重复消息是一个大问题。你不会期望在单次采购时,支付系统中记录了重复的付款。如果一个日志写入失败,则需要应用重试。然而应用无法知道哪个写入环节出现了问题。消息可能也可能不会持久化到日志。相同的消息仅会被日志系统采纳一次。换句话说,日志系统需要幂等。使用现有日志系统的简单方案是给消息附带一个唯一的Id,并过滤掉重复的消息。永久保留对所有唯一ID的映射将是一个巨大的负担。这类系统通常会使用保留策略来降低数据量。保留策略周期通常会足够长,以确保不可能发生误删。但"不可能"并不可靠。如何保证幂等?
我们的方案
Waltz 通过一种熟知的方法,乐观锁来解决上述问题。
乐观锁
应用可以在事务消息中附带锁。一个锁包含锁ID和模式。锁IDs是应用定义的。实际中会指派给某些实体,如支付或账户等。但Waltz 并不知道IDs代表什么。应用可以决定锁的粒度。Waltz 支持两种锁模式,READ和WRITE。READ模式意味着事务基于一个锁ID代表的实体的状态。WRITE模式意味着事务会根据实体的当前状态来更新状态。
在解释Waltz 中的乐观锁的工作方式之前,我们需要描述Waltz 中的一些关键概念,事务ID、客户端高水位标记、锁表、锁高水位标记以及锁兼容性测试。
事务ID是一个分配给成功持久化的事务的(唯一的)64位整数ID。在提交一个新的事务后,会增加事务ID。事务ID在Waltz 的乐观锁中扮演重要角色。
客户端高水位标记是客户端应用应用到其数据库的最大事务ID。
客户端传递给日志系统的客户端高水位标记 应该大于或等于锁高水位标记,此时表示客户端的数据比日志系统的数据新,可以更新日志系统的数据。反之则表示客户端的数据比日志系统的数据旧,无法更新覆盖。
其实就是针对每个元素作了版本号限定,只能更新最新版本的元素。
Waltz 内部管理着锁表,它是一个锁ID到事务ID的映射。当锁的事务消息处于WRITE模式时,锁表会返回一个给定锁ID对应的最新事务ID,称为锁高水位标记(映射实际是一个大小固定的随机数据结构,给出给定锁ID的最后一次成功的事务的预估事务ID)。预估的事务ID应该等于或大于真实的事务ID。
通过比较客户端高水位标记和锁高水位标记来执行锁兼容性测试。对于一个给定的锁ID,如果客户端高水位标记等于或大于锁高水位标记时,则说明锁是兼容的。
当处理WRITE模式的消息附带一个锁ID时,将会发生如下步骤:
- 客户端发送一条事务消息,包含客户端高水位标记
- Waltz 使用一个锁ID接收该消息
- Waltz 查找锁表,并执行锁兼容性测试
- 如果测试失败,Waltz 会拒绝该消息
- 如果测试成功,Waltz 会分配一个新的事务ID,并将消息写入日志。
- 如果写入失败,Waltz 不会更新锁表
- 如果写入成功,Waltz 会使用新的事务ID更新锁表
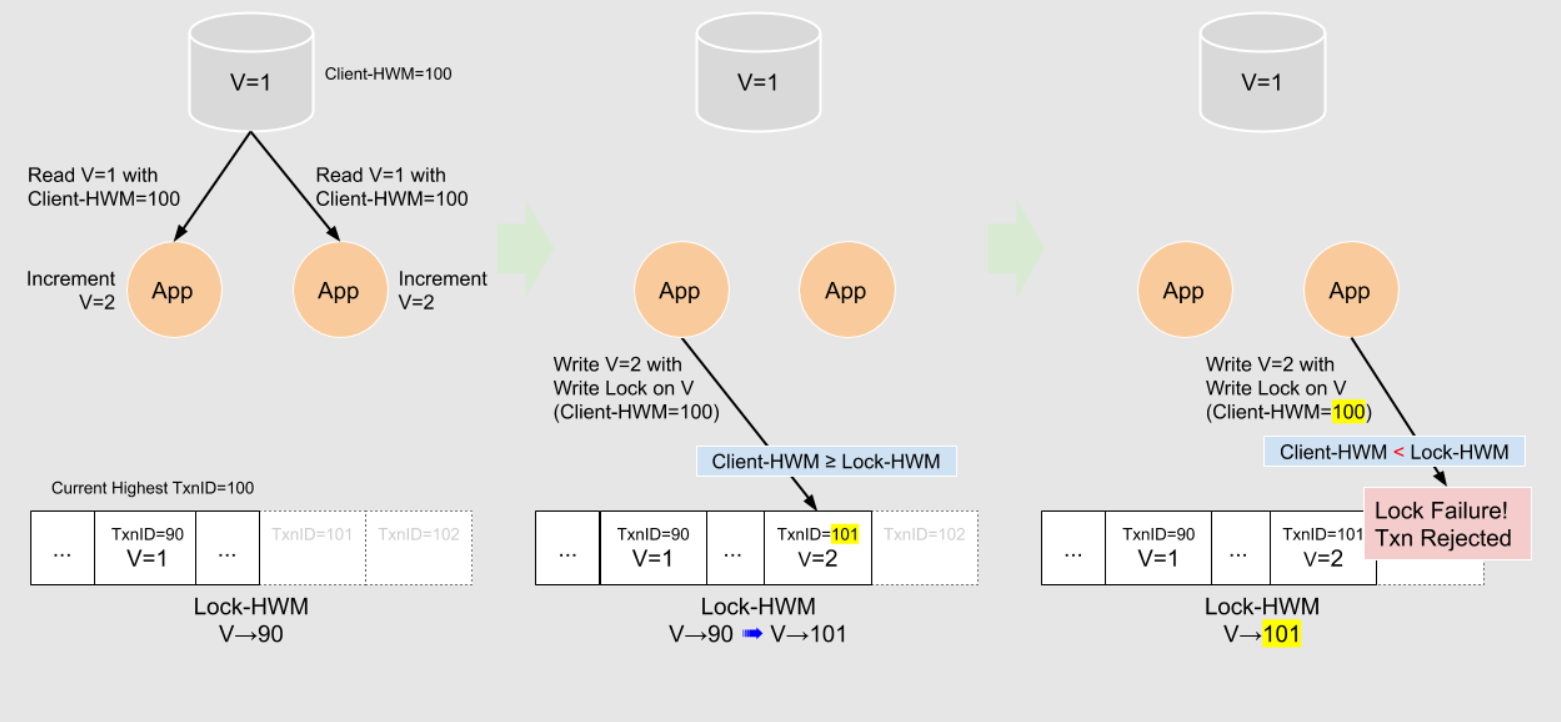
锁兼容性测试失败意味着什么?当失败时,客户端高水位标记会低于锁高水位标记。意味着应用还没有消费这条更新锁高水位标记的事务。因此,事务由旧数据构成,不能接收该事务。
可以使用乐观锁探测前面讨论的竞争条件。假设两个客户端在相同的时间使用相同的写锁发送了消息。一个有趣的场景是当这两个客户端的高水位标记相同且同时兼容锁高水位标记时,当Waltz 服务首先处理其中一条消息时,它会通过兼容性测试(因为其客户端高水位标记与锁高水位标记相同)。在提交后,锁表项会更新到新的事务ID。此时第二个消息将会失败,因为锁高水位标记高于客户端高水位标记。
限制和要求
乐观锁能很好地适应我们的场景,但并不意味着它是一个万能的解决方案。需要对应用设计作特定的限制和要求。
我们的场景中不存在长期的事务。一个事务必须打包到一个单独的Waltz 消息中。一个事务不能跨多个消息。这并不意味着一个事务局限为一个单独的数据操作。一个应用可以在一条消息中包含多个数据操作(作为一个原子操作)。当一个应用消费这类消息时,该消息会映射为在单个SQL事务中执行的多个DML语句。
我们要求一个应用有一个如SQL数据库这样的事务数据存储。数据库作为Waltz 事务日志物化后的视图。应用消费来自Waltz 的事务消息,根据应用的需求,该消息可能会也可能不会应用到数据库中。Waltz 不会强制任何特定的数据库模式,应用可以定义自己的模式。此外应用数据库必须存储高水位标记(服务消费的最大事务ID)。
其他常规分布式系统的东西
集群
Waltz 是一个分布式系统。一个Waltz 集群包含服务节点,存储节点和客户端。客户端跑在应用进程中。一个服务节点作为客户端和存储节点之间的代理和缓存。一个客户端会向服务节点发送事务消息,然后服务节点将其写入到多个存储节点中(为了持久和容错)。可以使用ZooKeeper来管理集群,由ZooKeepe来跟踪服务进程。Zookeeper也可以作为共享副本状态的元数据的存储。

分区
Waltz 日志使用分区来保证可扩展性。由应用来控制事务到分区的关系。分区使用独立的日志,每个分区使用独立的锁。
服务节点负责协调对存储节点的写入操作。每个服务节点负责一个分区子集。每个服务节点会负责一个分区。当一个服务节点出故障后,Waltz 会自动将失败的服务节点的分区重新分配给剩余的服务节点,并启动恢复处理。客户端也会感知到分区变更,这样后续会向正确的服务进行写操作。
复制协议
Waltz 使用仲裁写入(quorum write)来进行日志复制。当一个主存储节点确认写入成功后会提交一个事务,仲裁写入无法构建一个一致的分布式系统。Waltz 使用Zookeeper进行leader选举,生成唯一ID、故障检测和元数据存储等。此外,Waltz实现了一个类似Multi-Paxos和Raft 的协议来保证存储节点中日志的一致性。
对于每个分区,会选举一个服务作为分区的所有者,负责分区的读写。使用ZooKeeper来选举分区所有者。存储节点被动参与协议,它们不需要跟ZooKeeper进行交互,由分区所有者(服务)决定它们的动作。
我们在ZooKeeper中保存了少量关于存储状态的元数据(用于恢复)。在服务分配到分区或发生故障时,服务会执行恢复流程。在恢复完成前,客户端的所有写请求都将被阻塞。Waltz服务仅会在同步的副本中路由写请求,并在后台继续修复非同步的副本。
未完成的特性和后续工作
我们的需求是将所有事务作为不可变历史进行保存,因此我们没有一个日志保留策略,不会删除老的记录。类似地,我们也没有基于日志的压缩功能(如kafka)。我们设置没有表项key的概念。在存储节点中保存所有的事务记录并不经济,因此我们需要一种方式来方便对老的记录进行归档。
Topics
Waltz 没有Kafka的topic概念。Waltz 是一个单topic系统。目前还不支持多topic功能。我们使用独立的集群来对topic进行隔离。
工具
目前已经有一个CLI工具,待实现GUI 工具。
代理/缓存
我们考虑在每个域中增加一个代理/缓存。可以加速事务数据的传递,并降低跨域调用。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/15062420.html
