


BP-Wrapper:无锁竞争的缓存替换算法系统框架
BP-Wrapper:无锁竞争的替换算法系统框架
最近看了一个golang的高性能缓存ristretto,该缓存可以很好地实现如下功能:
- Concurrent
- High cache-hit ratio
- Memory-bounded (limit to configurable max memory usage)
- Scale well as the number of cores and goroutines increases
- Scale well under non-random key access distribution (e.g. Zipf).
在官方的introducing-ristretto-high-perf-go-cache一文中提到了一个名为BP-Wrapper的(几乎)无锁竞争的框架,用于提升缓存的扩展性。本文就是该框架的论文。
译自:bp_wrapper
概要
在高端数据库系统中,多处理器环境中的并发级别随着并行事务的增加以及多核处理器的引入而不断攀升。这给缓存管理带来了新的挑战,如何在保证扩展性的同时满足高并发数据处理的需求。如果缓存管理中的页替换算法不支持扩展,则可能会严重降低系统的性能。大多数替换算法会使用锁来保护数据结构,但并发访问也会引起大量锁竞争。通常的做法是通过修改替换算法来降低竞争,如使用时钟算法来近似实现LRU替换。不幸的是,这种修改通常会破坏原始算法的缓存命中率。在低并发环境下可能不会存在(或可以容忍)这个问题,因此可能会导致该问题长时间不被重视。本论文不会在替换算法的高命中率和低锁竞争之间进行权衡。在这里,我们提出了一个系统框架,称为BP-Wrapper,该框架几乎可以帮助所有替换算法消除锁竞争,而无需对算法作任何改动。在BP-Wrapper中,我们使用批处理和预加载技术降低了锁竞争,并获得高命中率。8.2版本的PostgreSQL仅使用300行C代码就实现了BP-Wrapper。与使用锁竞争的替换算法相比,当运行TPC-C类型和TPC-W类型的负载时,它可以将吞吐量增提升两倍。
I.简介
现代数据库管理系统通常会管理TB级别的数据,并在多处理器系统上并行处理成百上千条事务。这类数据库系统的缓存管理要求能够高效降低磁盘I/O操作所需要的时间,并能够随并发事务数量以及底层处理器数量的增加进行扩展。缓存管理的核心是数据替换算法,用来确定哪些数据页应该被缓存到内存中,以高效响应上层事务处理线程对磁盘数据的请求。替换算法通常会维护复杂的数据结构来跟踪线程对数据的访问历史,这样就可以依赖数据结构中的原始信息来执行替换算法。在高端生产系统中,会有大量线程频繁地并行访问数据页,这时会要求替换算法同时兼具高效性和可扩展性。
磁盘I/O操作变得越来越昂贵。为了最小化磁盘访问,出现了多种替换算法以及针对数据库、虚拟内存和I/O 缓存的实现,主要通过组织和管理深度页访问历史来提升命中率。如LIRS [1]、2Q [2]、和 ARC [3]。这些算法通常会在每次I/O访问时采取动作(命中或未命中缓存,以及对记录数据访问历史的数据结构的一系列更新)。这些操作非常频繁,因此通常被设计为简单而高效的,避免造成访问开销。
为了保证数据结构的完整性,替换算法会以一种序列化的方式采取操作,来响应页访问。因此为了在多任务系统上实现这些算法,通常会用到同步锁,换句话说,在采取动作前必须使用排他锁进行保护。当一个事务处理线程持有锁时,其他请求该锁的线程必须使用busy-waiting(自旋锁)或上下文切换的方式达到互斥效果。
在大型系统中,锁竞争会导致严重的性能问题,针对该问题的研究已经持续了很多年(即[4], [5], [6])。在我们的实验中,在16个处理器系统上,由于替换算法造成的锁竞争使得吞吐量下降了2倍。两种因素导致了性能降级:一个是频繁地请求锁,目前通过在所有事务请求线程中共享锁来调节页访问,线程每次访问页时都会请求锁;另一个因素是获取锁的代价,包括改变锁状态,busy-waiting,和/或上下文切换。与花费在锁保护下的操作相比,获取锁的代价可能更高。随着支持DBMS系统的多处理器上多核处理器的增加,上述两个因素造成的性能降级也愈发严重。
由于替换算法设计者没有关注锁竞争造成的问题,因此在实际系统中,算法的好处(包括高命中率)可能会大打折扣,例如,一些普遍使用的DBMS系统(如postgreSQL)没有采用高级的替换算法,相反诉诸于基于时钟的近似LRU替换算法。其他DBMS系统(如Oracle Universal Server [7]和ADABAS [8])则使用分布式锁来解决锁竞争问题。
相比于对应的原始算法(分别对应LRU,LIRS或ARC),基于时钟的近似算法,如CLOCK [9],CLOCK-PRO [10] 和CAR [11]等通常不会获得高命中率。它们将缓存页组织为环形列表,并使用引用位或引用计数来记录每个缓存页的访问信息。当命中缓存中的一个页时,基于时钟的近似算法会设置引用位或增加计数,而不会修改环形列表本身。由于这些操作并不需要时钟,因此缓存性能是可扩展的。然而,基于时钟的算法只能记录有限的历史访问信息,如是否访问某个页或对该页的访问次数,但无法知道访问顺序。历史信息的缺失可能会影响命中率。很多成熟的替换算法并不会采用基于时钟的数据结构,原因是无法使用时钟结构来近似表达它们需要的信息。如SEQ[12]算法和DB2[13] 使用的缓存替换策略,它们需要知道缓存页的访问顺序,并以此来检测顺序以及访问顺序/随机访问模式。
通常,可以使用分布式锁降低锁粒度( [4], [5], [6], [14])的方式来减少锁竞争。但这种方式并不能有效地解决替换算法中的锁问题。在分布式锁中,会将缓存分成多块,每一块都使用一个本地锁进行保护。使用轮询或哈希方式将数据页均匀分布到各块。由于只有访问相同块的缓存才会用到相同的锁,因此可以改善锁竞争。但由于记录的历史信息位于本地的各个缓存块,因此全局历史信息的缺少可能会对替换算法的性能造成影响。例如,如果算法需要检测访问顺序,但此时相同顺序中的页被分布到多个缓存块中,此时无法保证性能优势。
总之,现有的对DBMS系统的研究和开发都聚焦在如何在高命中率和低锁竞争之间进行权衡。相比于如何在这两个方面采取妥协,我们的目标是在保持高级替换算法性能优势的同时,提供一种有效的框架来消除(大部分)替换算法中的锁竞争。通过为每个DBMS事务处理线程维护一个小的FIFO队列,我们的框架提供了两种主要的、可以普遍应用于所有替换算法的扩展。一种是批量执行,通过批量的页访问来改善锁竞争开销;另一个是预加载,通过将替换算法需要的数据预加载到处理器缓存中来降低平均所加载时间。我们将这种引入批量(Batching)和预加载(Prefetching)的框架称为BP-Wrapper。在8.2.3 版本的PostgreSQL 引入该框架后,通过消除TPCW 和TPCC负载中与缓存页替换有关的(几乎所有)锁竞争,使吞吐量提升了两倍。
本论文剩余的结构如下:在II章节中,我们简单描述了典型数据库系统中的替换算法和锁扮演的角色。在III章节中,我们描述了BP-Wrapper。第IV章节针对BP-wrapper进行了全面评估。第V和VI章节总结了相关的工作。
II. DBMSs中的缓存管理背景
在一个DBMS系统中,它的缓存在内存空间中保存了DBMS中所有事务处理线程共享的固定大小的缓存页。从磁盘读取的数据页会被缓存起来,以此避免(不久之后)重复获取数据页的I/O操作造成的开销。缓存管理器会使用数据结构(如链接的列表或哈希表)来组织缓存页的元数据。元数据包含缓存的数据页的标识,页状态以及构成链接列表或哈希表的指针。
图1展示了典型的缓存管理器。当一个线程请求数据页时,该线程会查询包含数据页的缓存页。通常会使用一个哈希表来加速查找。如果找到(命中)缓存页,替换算法会执行一个操作来更新数据结构,以此反映页访问。例如,当请求一个缓存页时,LRU替换算法会从LRU列表中移除缓存页,并将其插入到列表末尾的MRU。然后返回缓存页,结束请求。如果没有在缓存中找到请求的数据页(缓存未命中),替换算法会选择一个牺牲页,然后淘汰该页中的数据,以此来为需要加载的数据腾出空间。LRU算法总是选择LRU列表末尾的缓存页作为牺牲页。当数据页读入内存后,缓存页会转移到LRU列表的首部,并返回给请求。
因为缓存管理器是所有事务处理线程的请求经常使用的中央组件,因此必须以某种方式控制同时更新数据结构,以保证数据的完整性。DBMS使用排他锁解决该问题。
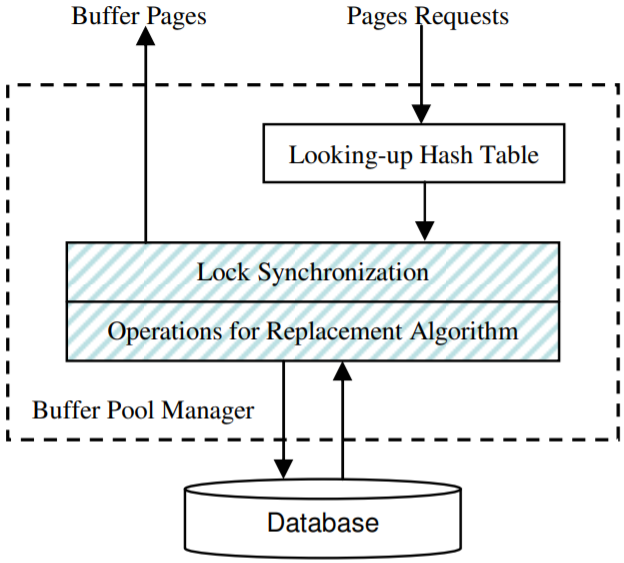
图1.典型的DBMS中的缓存管理器。虚线矩形中的缓存管理器可以同时查找哈希表,而阴影块表示的替换算法则必须序列化执行。
使用锁并不会影响哈希表搜索的系统扩展性,因为: (1)在哈希表中,缓存页的元数据均匀分布在哈希桶中。通过为每个桶提供一个锁(而不是提供全局锁)来控制对桶的访问。为了保证查找时间,通常会使用大量桶,这样就降低了多个线程访问相同桶的概率。(2)如果多个线程不修改桶,则多个线程可以同时访问该桶。哈希桶很少会发生变化,只有当发生发生未命中以及当两个哈希桶因为同一个缓存未命中(一个桶保存牺牲页,另一个保存新页)时才会发生变化。在具有大容量内存的DBMS中,只有一小部分访问会发生缓存未命中,因此我们不考虑哈希表查找中的锁竞争场景。
相反,替换算法会因为锁竞争而严重影响性能,因为:(1)一个替换算法会为它的数据结构使用一个单独的锁,这是一个集中式的访问热点。(2)大多数替换算法会在每次页访问时更新它们的数据结构,因此一个线程必须在每次页访问请求时获取锁,并执行替换算法操作。高度的锁竞争可能会严重降低多处理器系统上DNMS系统的性能。
III. 使用BP-WRAPPER最小化锁竞争
在一个替换算法中,与锁使用有关的开销分为两部分,称为获取锁开销和锁预热开销。获取锁开销是指当请求的锁被另一个线程持有时,线程本身阻塞所造成的时间开销。取决于具体实现,这类开销可能是处于busy-waiting锁占用的CPU周期,和/或上下文切换占用的CPU周期,开销的多少由锁竞争的激烈程度而定,如果一个服务上有很多处理器,且并发处理大量事务,则获取锁所需要的时间可能会大大超过小型系统所需要的时间。换句话说,开销直接与替换算法的扩展性关联,因为每次页访问时都需要获取一个锁才能在锁保护的共享数据结构中保存访问历史记录。
锁预热开销是指在处理器缓存中,为准备运行关键代码段所需的数据造成的开销,或从非关键代码段(事务处理的代码)进入关键代码段(用于更新替换算法的共享数据结构的代码)的过程中发生的处理器缓存未命中惩罚。当获取到锁后,处理器缓存中可能没有描述锁的数据以及关键代码段需要访问的数据集,因此在缓存预热过程中可能会发生一系列缓存未命中。重点是在一个线程获取到锁,而其他线程等待该锁时的未命中惩罚可能会被放大。遵循最小化关键代码段开销的原则,我们主要消除预热开销。
为了降低两种潜在的锁开销,我们在BP-Wrapper中设计并集成了两种方法,这两种方法都由替换算法本身实现,这样任何替换算法都可以直接通过BPWrapper获得高扩展性。
A 使用批量技术降低锁请求开销
正如前面提到的,当一个线程进入关键代码段后,在代表替换算法执行其操作前必须获取锁。通常不需要关心请求锁造成的缺页,因为与I/O操作造成的开销相比,锁请求开销通常可以忽略不计,此外,其缓存未命中数也大大低于数据库系统。主要的挑战是大部分替换算法(特别是最近提出的算法[1], [2], [3])的命中率都非常低,每次页请求时都会访问锁保护的数据(即使数据已经存在于缓存中),当锁竞争激烈时,锁请求所造成的开销也会增加,并成为系统扩展的性能瓶颈。
现有数据库系统中的替换算法在每次页访问时都需要获取锁。获取锁的总开销会随着访问频率的增加而增加(通常发生在高并发的数据库系统中)。我们使用一种称为批量的技术来分摊并降低多个页访问造成的开销。基本的思路是,当页访问累积到一定数目后,周期性地请求锁,然后在持有锁的周期内执行相应的替换操作。为了解该技术的效果如何,我们在一个具有16个处理器的系统上(详细的配置参见Section IV)测量2Q替换算法中的锁请求以及一个线程处理一定数目的(针对锁保护的数据结构的)页访问所占用的(锁持有)时间(包括请求锁产生的开销)。批量大小范围为1-64(即,获取锁前累计的页访问数目为1到64)。图2展示了获取锁和持有锁的时间随批量大小变化的平均值。我们发现,虽然多个访问涉及的关键代码段的执行时间与访问次数成正比,该测量结果展示了批处理技术的有效性,同时得出,当使用小批量时,如64,可以显著降低获取锁的开销。
图2. 每次页访问涉及的锁获取和持有锁时间的平均值随批量数目的变化(1-64)。图中的两个轴都为对数标度,负载为DBT-1,处理器数目为16。
虽然每次页访问都需要操作锁保护的数据,但根据替换算法的要求,通常不必在页面访问之后立即执行操作。替换算法有两个特性为我们提供了使用批量技术显著降低锁请求频率的机会。首先,延迟替换算法(如LRU栈或LIRS栈[1])操作数据结构的操作,这样就不会影响线程从缓存中获取正确的数据,因此也不会影响事务处理的正确性。其次,在具有百万级别的页的系统上(如我们实现的服务使用了64GB内存或上百万个8KB的页),延迟在锁保护的数据中记录最近的页访问信息的操作(如64个页访问)可能会对分页算法的性能造成一些影响,此外,批量操作的执行顺序不会因为采纳批量技术而发生变化。
在批量技术中,我们为每个事务处理线程设置了一个FIFO队列。当一个访问与某个线程关联时,会将本次的访问信息记录在该线程的队列中。特别地,当一个线程请求的页位于缓存中时,会在线程的FIFO队列中记录指向该页的指针。图3展示了使用批量技术的缓存管理器。当队列满或队列中的访问记录达到预设的阈值时(称为批量阈值),我们会获取到锁并以批量的方式为队列中的所有访问执行替换算法定义的操作,该过程称为提交访问记录。在提交之后,队列会变为空。通过FIFO队列,一个线程可以允许访问多个页,而无需为页替换算法请求锁(或不存在获取锁开销)。
在批量技术的设计中,一种替代方案是在多个线程间共享FIFO队列。但最终我们选择为每个线程配置独立的队列,原因如下:
- 私有队列可以更精确地保证相应线程的页访问顺序。访问顺序对某些页替换算法(如SEQ[12])来说至关重要,因为它们需要顺序信息来检测访问模式。
- 在私有FIFO队列中记录访问信息降低了同步访问的概率和整体开销以及一致性成本,而这些开销正是多线程共享FIFO队列时,填充和清空队列时所需要的。
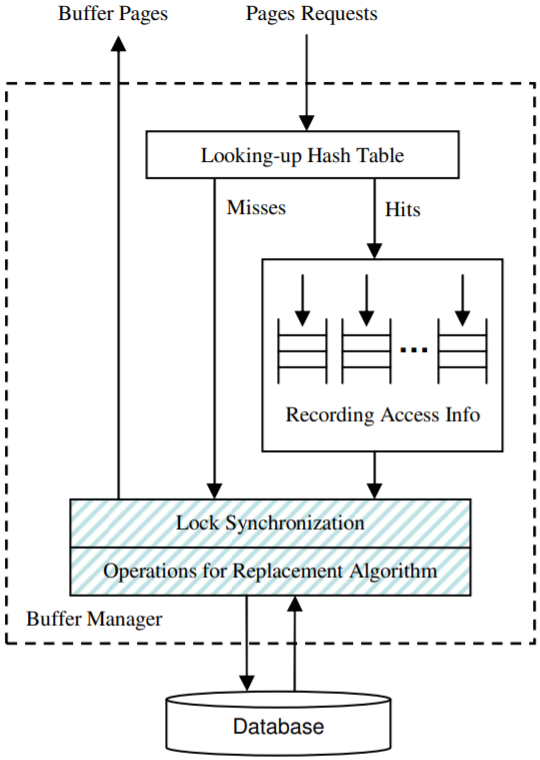
图3.使用批量技术的缓存管理器
图4的伪代码描述了批量技术,包括页命中(hit())和未命中(miss())时的相关锁操作。在伪代码中,当出现页命中时,会首先在队列中记录此次访问(Queue[])。然后,有两个条件会触发提交过程,并执行实际的替换算法。第一个条件是一个队列中有足够数量的访问(不能少于批量阈值),且可以获取锁(TryLock()成功)。由于获取锁的开销通常比较高,因此不应该为少量的访问付出此类开销。TryLock()会尝试获取锁。如果此时其他线程持有该锁,该操作会失败,但不会阻塞调用线程。反之调用线程会以非常低的开销获取锁。虽然TryLock()的开销小,但也不能在每个页访问时调用,否则会造成大量锁竞争,并降低TryLock()获取到锁的机会。第二个条件是队列满。这种场景下,必须明确请求锁(13行的Lock())。当两种条件都不满足时,替换算法会为队列中的每个访问记录涉及的锁保护的数据执行延迟簿记工作。以LRU算法为例,它会将每个访问涉及的页转移到队列末尾的MRU中。注意,伪代码实际描述了一个使用批量技术的框架,该框架可以给所有算法使用,以高效访问锁保护的数据(替换算法本身独立于批量技术)。现有的替换算法并没有在提高其命中率上花费很多精力,必须做出一定修改来适应该技术,降低锁开销。与将算法转换为其时钟近似的算法相比,后者减少了锁竞争,但在替换性能上做了一定妥协。
/* a thread’s FIFO queue whose maximum size is S */ 1 Page *Queue[S]; /* the minimal number of pages in Queue[] to trigger a committing 2 #define batch_threshold T /* current queue position to receive next page */ 3 int Tail = 0; /* called upon a page hit */ 4 void replacement_for_page_hit(Page *this_access) { 5 Queue[Tail] <-- this_access; 6 Tail = Tail + 1; 7 if (Tail >= batch_threshold) /* a non-blocking attempt to acquire lock */ 8 trylock_outcome = TryLock(); 9 if(trylock_outcome is a failure) { 10 if( Tail < S) 11 return; 12 else 13 Lock(); 14 } /* A lock has been secured. Now commit the pages */ 15 For each page P in Queue[]{ 16 do what is specified by the replacement algorithm upon a hit on P; 17 } 18 UnLock(); 19 Tail = 0; 20 } /* called upon a page miss */ 21 void replacement_for_page_miss(Page *this_access) { 22 Lock(); 23 for each page P in Queue[] { 24 do what is specified by the replacement algorithm upon a hit on P; 25 } 26 do what is specified by the replacement algorithm upon a miss on ’this_access’; 27 UnLock(); 28 Tail = 0; 29 }
图4. 独立于替换算法的框架伪代码,使用批量技术为算法提供了高效访问锁保护的数据的能力
B 使用预加载技术降低锁预热开销
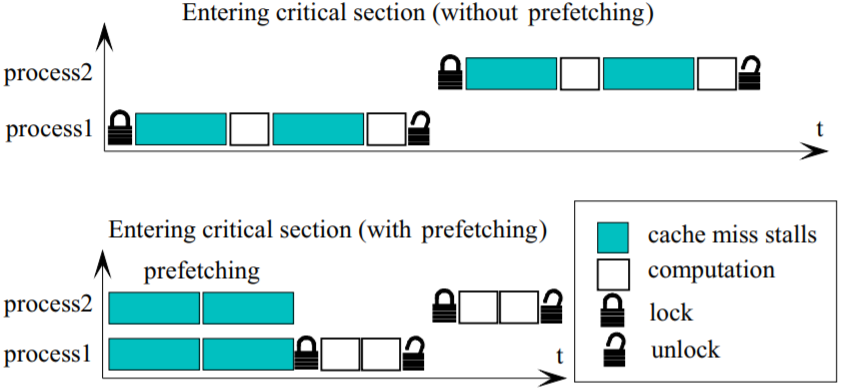
图5. 使用预加载技术将缓存未命中惩罚转移到锁持有阶段
我们使用预加载技术降低锁预热开销(此为锁持有时间的一部分)。在该技术中,我们会在请求锁前读取替换算法的关键代码段所需要立即访问的数据。以LRU算法为例,我们会读取在向页列表末尾的MRU移动时涉及的前/后指针,以及锁数据结构字段。读取的一个副作用是需要将数据加载到处理器缓存中,但消除了关键代码段的缓存未命中惩罚。图5中示了该技术的潜在好处。
在无锁的共享数据上执行预加载操作并不会对替换算法中的全局数据结构的完整性造成影响。预加载(读)操作只会将数据加载到处理器缓存中,不会修改任何数据。同时,如果预加载的数据在线程使用前已经被其他线程进行了修改,则处理器中的某些硬件机制会自动让这些缓存失效,或使用最新的值进行更新,以保证数据的一致性。
IV. 性能评估
我们已经在8.2.3版本的postgreSQL数据库系统上实现了PB-Wrapper框架,包括两个降低锁竞争的技术。先前版本的PostgreSQL使用的是LRU和2Q替换算法,但最终因为扩展性问题而被废弃。从8.1版本开始,为了提升多处理器系统上缓存管理的扩展性,postgreSQL采用了时钟替换算法。时钟替换算法在访问命中时不需要锁,消除了锁竞争,并提供了最佳的扩展性。
在评估的第一部分,我们只关注扩展性问题。评估结果得出,将高级替换算法(如2Q)和BP-Wrapper配合使用,可以获得跟时钟替换算法相同的扩展性。在实验中,我们将缓存配置的足够大来保存所有性能测试中的工作集,并对缓存进行预热。这样无论使用哪种替换算法都不会发生未命中的情况。使用不同缓存管理器的PostgreSQL系统之间的性能差异完全来自其实现的可扩展性上的差异,而非命中率。因此可扩展性越高,观察到的性能越好。由于时钟算法的扩展性最好,因此当系统扩展时,其性能最佳。后面我们会对实现的扩展性进行测试,衡量其性能与时钟实现的差异。Section IV-D展示了测试结果。
在实验的第一部分,我们主要如下问题:(1)在降低替换算法的锁竞争上,那种技术更好,批量还是预加载?(2)与时钟算法相比,使用这些技术降低了多少锁竞争?(3)这些技术的性能受多处理器平台以及多核平台的影响?
目前存在很多高级替换算法可以在命中率方面提供(比时钟算法更)出色的性能,但除了LRU之外,其他算法很难转换为时钟算法,如果无法转换,这类算法就不适宜运行在高并发环境中。在评估的第二部分中可以看到,如果没有采取降低锁竞争的动作,在大型系统中,这类高级算法的在命中率上的性能优势将会大打折扣。同时,评估也给出了我们的技术在帮助保持算法优势的同时,提升了扩展性。
A. 被测系统
我们修改了8.2.3版本的postgreSQL,使用2Q算法(提供高命中率的高级替换算法)替换了原来的时钟算法。我们将修改后的系统称为postgreSQL-2Q或简称为pg2Q(未针对较低的锁争用进行优化),在比较中作为基线系统。然后使用BP-Wrapper框架增强该基线系统。我们分别启用了批量技术和预加载技术,并将启动这些技术的系统分别命名为pgBatching和pgPref,在另一个系统上同时启用批量技术和预加载技术,并将该系统命名为pgBat-Pre。原始的postgreSQL 8.2.3称为pcClock。表T对这些系统进行了概括。我们还使用LIRS [1] 和 MQ [15]替换算法分别替代了图标中最后四个使用2Q算法的系统。在实验中,我们不会观察使用这些算法的系统与对应的使用2Q算法的系统之间的性能差异。
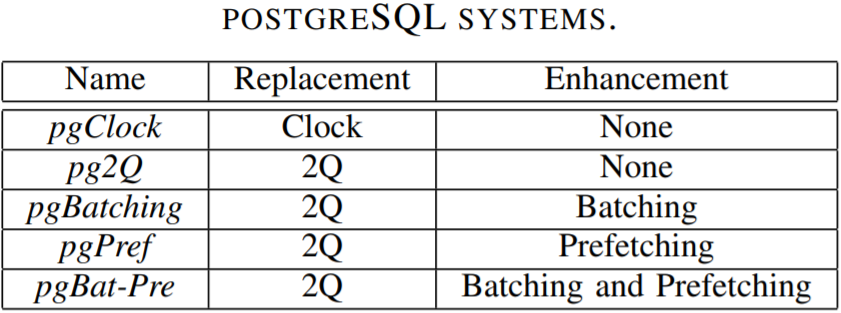
表I
B. 实验问题
仅需要对基线系统作有限修改就可以实验批量和预加载。我们在postgreSQL 8.2.3中添加的代码不超过300行。大部分修改都位于一个单独的文件中(src/backend/storage/buffer/freelist.c),该文件包含替换算法的源码。在实现中,FIFO队列中的每一项都包含两个字段:一个指向缓存页的元数据(BufferDesc structure)的指针,另外一个保存BufferTag(用于区分数据页)。在表项提交前,我们会将表项中的BufferTag与缓存页的元数据中的BufferTag进行比较,保证该数据页是有效的或未被淘汰。如果缓存中存在有效的数据页,我们会在页访问时,运行替换算法来更新该数据结构。在2Q算法中,如果页的结构是Am列表,更新后的页会转移到列表末尾的MRU中;在LIRS算法中,它会在LIR或HIR列表中转移;在MQ算法中,它会在多个FIFO队列中转移。
C. 实验配置和负载
我们会在传统的单核SMP平台和多核平台上进行实验。单核SMP平台使用的是一个 SGI Altix 350 SMP服务器,使用16个1.4GHz的Intel Itanium 2处理器,64GB内存。存储为一个位于IBM FAStT600 turbo存储子系统上的2TB大小的LUN,该LUN包含9个250GB的SATA磁盘,使用8+PRAID5进行配置。操作系统为 Red Hat Enterprise Linux AS release 3(SGI ProPack 3 SP6);多核平台是一个DELL PowerEdge 1900服务器,含2个2.66GHz的四核Xeon X5355处理器。为了方便,我们将每个计算核认为是一个处理器。这样PowerEdge 1900服务器有8个计算核,或8个处理器。内存大小为16GB。存储为使用5个15K RPM SCSI磁盘的RAID5阵列,操作系统为Red Hat Enterprise Linux AS release 5。
我们使用DBT-1测试套件和来自OSDL数据库测试套[16]的DBT2测试套件,以及一个构造的基准TableScan对系统进行测试。DBT-1模拟web用户在一个在线书店浏览并下单的行为,它生成具有与(1.7版本的)TPC-W基准规范相同特征的数据库工作负载[17]。数据库会生成100,000个条目,以及290万个客户。DBT2衍生自(5.0 [18]版本的)TPC-C规范,提供在线事务处理(OLTP)负载。在实验中,我们将数仓的数目设置为50,TableScan会模拟顺序扫描(数据库的常用操作之一)。它会执行并行请求,每个请求都会扫描整张表,每张表包含800,000行,每行大小为128个字节。
在实验中,我们会通过设置postgreSQL后端进程的CPU亲和性掩码来变更postgreSQL使用的处理器数目,即负责PostgreSQL处理事务的线程。由于PostgreSQL的后端进程会在因为竞争而无法获得锁时阻塞自身并唤醒其他处理器。因此我们会通过设置postgreSQL的后端进程数大于处理器数来使处理器保持工作。实验中,我们将FIFO队列数设置为64,pgBatching 和 pgBat-Pre的批量阈值为32。
D. 扩展性实验
在实验中,我们评估了5个不同的postgreSQL分别在3种负载下的扩展性(在Altix 350服务器上,我们将处理器数量从1增加到16。在PowerEdge 1900服务器上,我们将处理器数量从1增加到8).为了消除负载运行过程中的缺页,我们调整了共享缓存的大小,确保内存中总是持有整个负载集。我们会采集事务的吞吐量(每秒的事务)以及平均响应时间。对于系统pg2Q、pgBatching、pgPref和pgBat-Pre,我们还会计算平均锁竞争。当无法即时满足一个锁请求,并发生上下文切换时,就产生了一个锁竞争。在负载运行过程中,平均锁竞争定义为每毫秒内的访问页产生的锁竞争数。图6和图7中展示了不同系统下,三个负载的吞吐量、平均响应时间和平均锁竞争。
然后增加处理器的数目,与预期相符,pgClock的吞吐量随处理器的数目线性增加,且DBT-1和TableScan负载下的平均响应时间适度增加。但在DBT2负载下,pcClock的吞吐量亚线性增加,而平均响应时间则大大增加。这是因为产生了锁竞争(如发生预写式日志(Write-Ahead-Logging)活动时),使锁竞争随处理器的数目增加而愈发激烈。
当处理器数目小于4时,系统pg2Q可以维持其扩展性。在Altix 350 服务器上,DBT-1和TableScan的处理器的数目大于8,或DBT-2的处理器大于4时,吞吐量达到饱和状态,并且在进一步增加处理器时,平均响应时间也会大大增加。对于TableScan负载,当处理器的数目从8增加到16后,其吞吐量下降了12.7%。当使用16个处理器时,DBT1, DBT-2 和 TableScan负载下的吞吐量分别为pcClock的61.1%、56.5% 和 66.5%,其平均响应时间分别为pcClock的1.6、1.5 和 1.8倍。通过检查平均锁竞争的曲线,我们发现pg2Q每毫秒页访问的锁竞争数目最多,并随着处理器数目快速上升(注意,数字以对数刻度显示)。因此这些实验表明锁竞争是系统性能降级的元凶。
在PowerEdge 1900服务器上,我们观察到类似的现象。TableScan负载下吞吐量更早地达到饱和状态(或当处理器的数目达到4)。平均锁竞争表明在多核的PowerEdge 1900上锁竞争要比Altix 350更加激烈(特别是针对TableScan负载的基准测试)。当使用8个处理器时,PowerEdge 1900上的3个负载的平均锁竞争分别为Altix 350上相应负载的产生的平均锁竞争的74.4%、18.5% 和 270.2%。因此,相比 Altix 350,锁竞争对PowerEdge 1900的性能影响更大。使用8个处理器时,PowerEdge 1900上的系统pg2Q的吞吐量为pgClock吞吐量的37.9%、52.1% 和 57.2%,是Altix 350上的系统pgClock的吞吐量的30.1%、51.5% 和 32.6%。类似地,当使用系统pg2Q时,在PowerEdge 1900上锁竞争提高的工作负载的平均响应时间百分比要大于在ALTIX 350上提升的工作负载的平均响应时间百分比。
PowerEdge 1900上的锁竞争更激烈的原因归咎于系统使用的处理器。PowerEdge 1900上的Xeon X5355处理器具有缓存预加载模块,该模块可以通过预测,将数据加载到最后一级缓存,从而加速顺序内存访问。而Itanium 2处理器则没有这样的硬件支持,因此在PowerEdge 1900服务器上,预加载模块可以加快关键段外的计算(通常顺序访问内存),但被锁保护的替换算法的操作通常会随机访问内存,几乎不能被(预加载模块)加速。因此PowerEdge 1900 服务器上的锁竞争更激烈,花在关键部分上的时间比例要大于 Altix 350。
与pg2Q相比,pgPref在Altix 350系统上的平均锁竞争减少33.7%至82.6%,在PowerEdge 1900上的平均锁竞争减少20.8%至87.5%。这是因为预加载降低了锁持有时间,并相应增加了获取到锁的机会。最终,pgPerf的吞吐量比pg2Q高26.1%,而平均响应时间则小 25.2%。我们注意到在Altix 350上运行预加载技术比PowerEdge 1900更有效,这是因为在X5355处理器上运行长流水线且无序的事务,增加了处理缓存未命中的负担。基于此观察,我们可以预见预加载技术在大型多核处理器系统(如Sun Niagara 2处理器和Azul vega处理器)上可以更有效地降低锁竞争。这些处理器在一个芯片内有很多顺序的用于支持并发线程计算核。因此相比于具有少量无序计算核的处理器(如Xeon 5355处理器),缓存未命中对此类系统的性能影响更大。
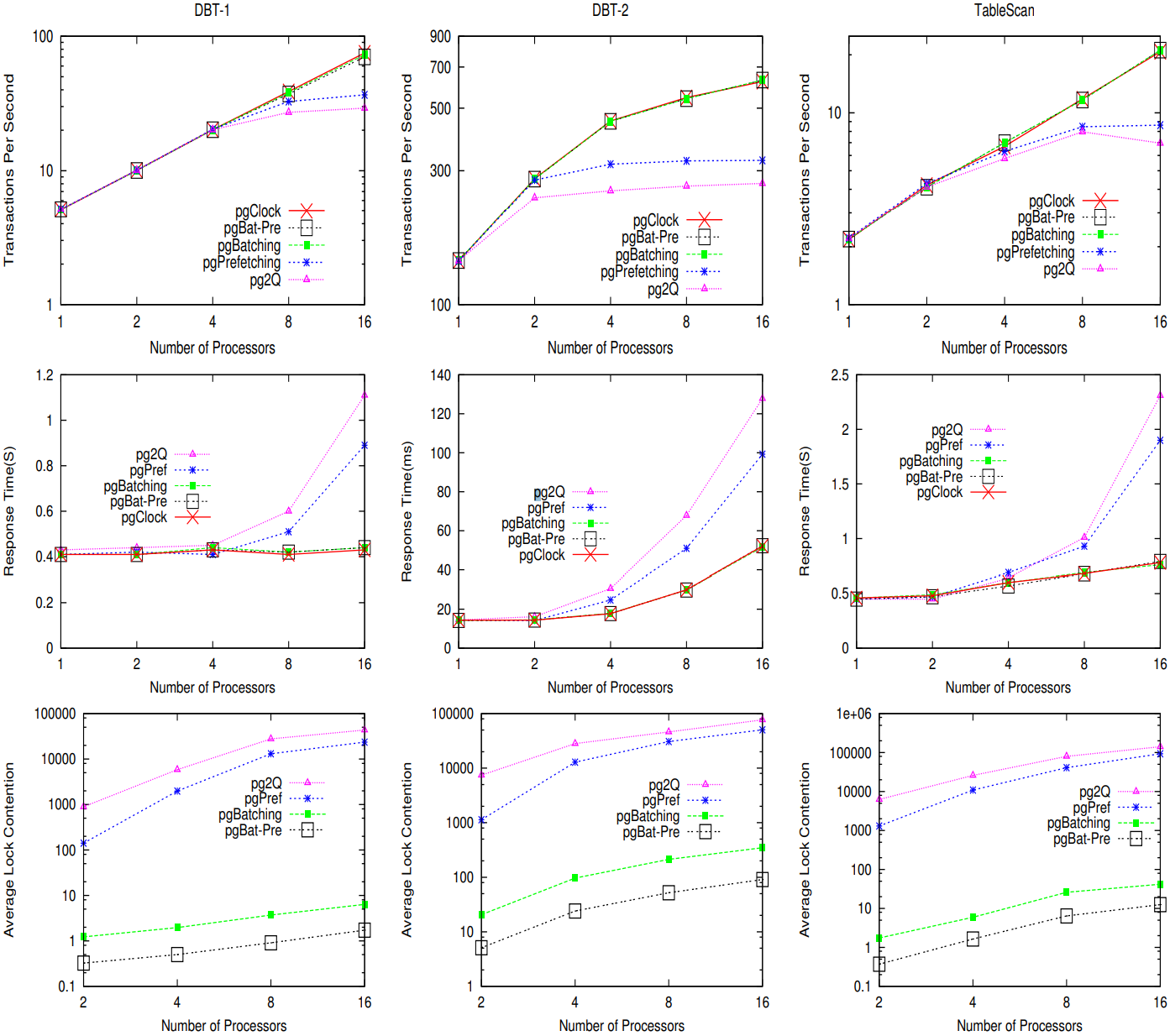
图6. Altix 350上,5种postgreSQL系统(pgClock、pg2Q、pgPref、pgBatching 和 pgBat-Pre)在DBT-1、DBT-2 和 TableScan负载下的吞吐量、平均响应时间和平均锁竞争(处理器数从1增加到16)。注意吞吐量和平均锁竞争曲线的Y轴为对数刻度。仅使用一个处理器时,我们没有展示平均锁竞争,这是因为这种情况下,锁竞争非常少,无法在图中展示出来。
在平均锁竞争的曲线中可以看到,系统pgPref的扩展性要弱于pg2Q,这是因为批量技术无法显著降低锁竞争,特别 是在使用大于4个处理器时。例如,当在 Altix 350服务器上使用两个处理器时,在3个负载下,平均降低了pg2Q上82.4%的平均锁竞争,当处理器数目为4时,降低的锁竞争的百分比减少到60.2%;当处理器数目为8时,降低的锁竞争的百分比减少到46.3%;当处理器数目为16时,降低的锁竞争的百分比减少到38.6%。pgPref中的批量技术降低了锁竞争,并提升了系统的吞吐量。但随着吞吐量的增加,请求的锁也愈发频繁,抵消了降低锁竞争带来的好处。在处理器数目较多的系统上,该现象更加明显。
在实验中,系统pgBatching展示了与pgClock几乎相同的扩展性,为扩展性最佳的算法。当处理器数目增加时,它的吞吐量曲线和平均响应时间曲线与pgclock非常契合。在平均锁竞争曲线图中可以看到,系统pgBatching将锁竞争数从9000多降低了127倍,提升了扩展性。我们还注意到,使用16个处理器的pgBatching的平均锁竞争要远低于使用2个处理器的pgPref和pg2Q。
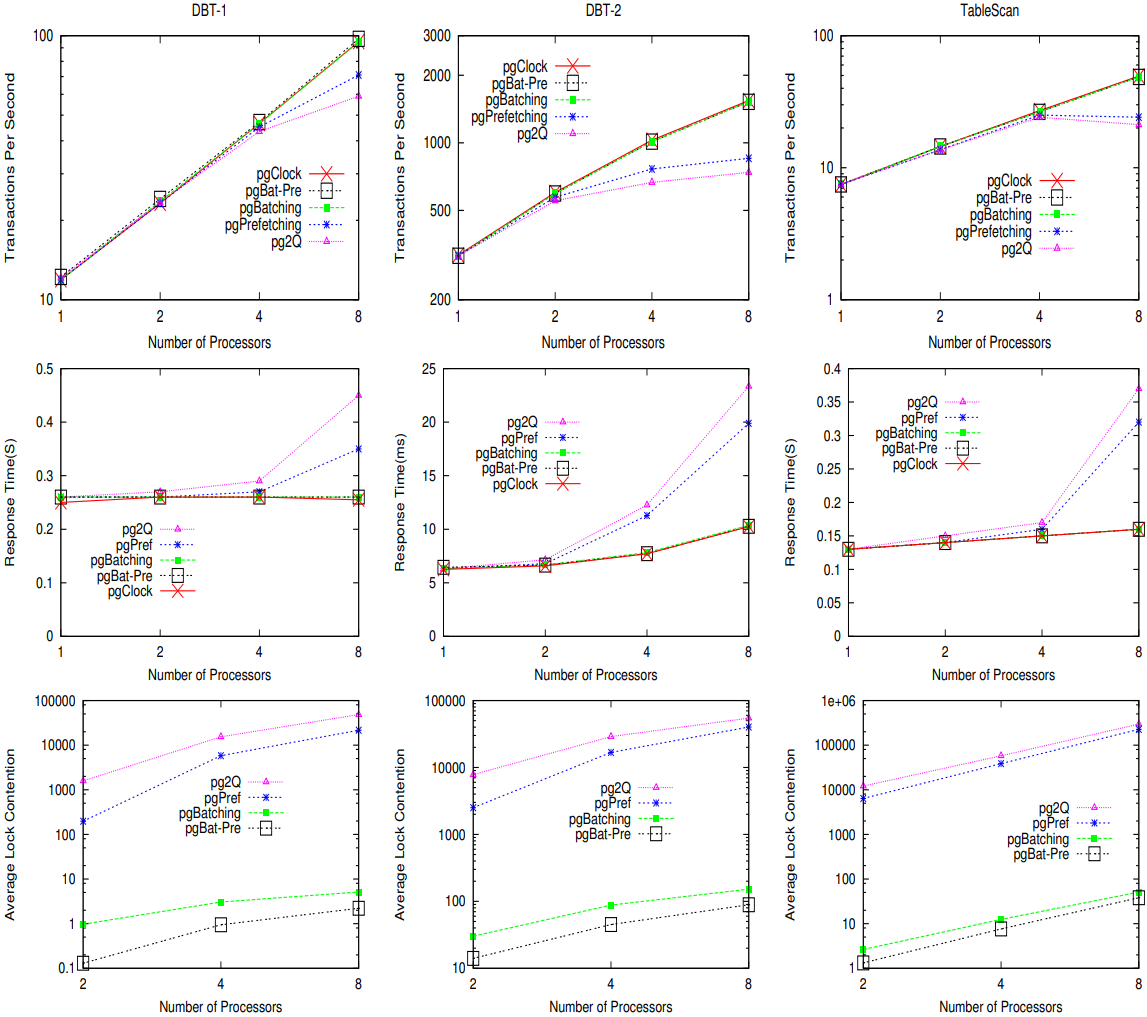
图7. DELL PowerEdge 1900上,5种postgreSQL系统(pgClock、pg2Q、pgPref、pgBatching 和 pgBat-Pre)在DBT-1、DBT-2 和 TableScan负载下的吞吐量、平均响应时间和平均锁竞争(处理器数从1增加到8)。注意吞吐量和平均锁竞争曲线的Y轴为对数刻度。仅使用一个处理器时,我们没有展示平均锁竞争,这是因为这种情况下,锁竞争非常少,无法在图中展示出来。
同时使用批量和预加载技术时,相比pgBatching,系统pgBat-Pre可以进一步降低锁竞争。然而,如图所示,降低锁竞争并不会提高吞吐量或降低平均响应时间,这是因为pgBatching的平均锁竞争非常少,因此对性能的影响范围也不大。当使用16个处理器时,在每100万个页访问中,pgBatching和pgBatPre的锁竞争在400个(或少于400个)左右。当继续增加处理器的数目时,在常见的多核处理器中,锁竞争会变得更严重,这种情况下,pgBat-Pre可以帮助进一步降低锁竞争,提升系统性能。
E. 参数敏感性研究
系统pgBatching使用一个小的FIFO队列来记录每个postgreSQL后端进程的访问历史来分摊锁请求开销。批量技术中有两个主要参数,一个是FIFO队列的大小,另一个是批量阈值,或触发提交时队列中的最少元素个数。在本节中,我们将会在包含16个处理器的 Altix 350系统上对两个参数的敏感性进行研究。
首先在保证批量阈值为队列大小一半的前提下,逐步将队列大小从2增加到64,并使用3个负载运行paBatching,表II中展示了对应的吞吐量和平均锁竞争。然后将队列大小固定为64,并使用3个负载运行paBatching,表III中展示了对应的吞吐量和平均锁竞争。
表 II .当队列长度从2增加到64,且批量阈值为1/2的队列长度时,在系统pgBatching在负载DBT-1, DBT-2 和 TABLESCAN下的吞吐量和平均锁竞争
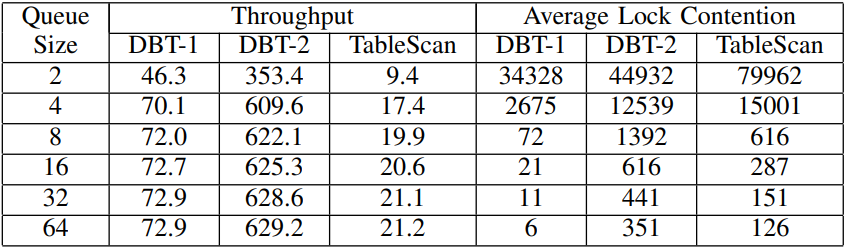
表 III. 批量阈值从1增加到64时,DBT-1,DBT-2和TABLESCAN负载下系统pgBatching的吞吐量和平均锁竞争
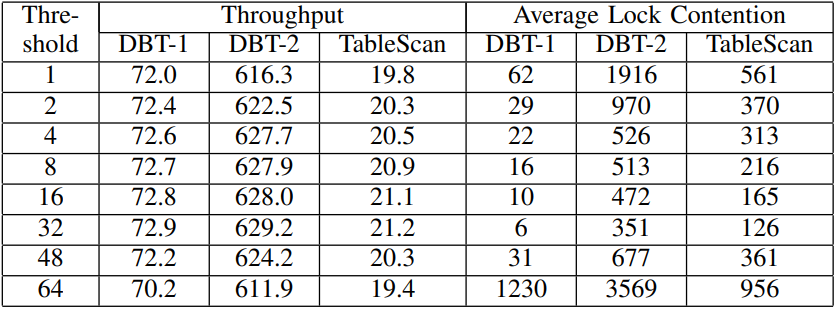
增加队列大小可以降低平均锁竞争并提升吞吐量,因为此时可以一次性提交更大批的访问历史。当队列大小从2增加大8时,DBT-1的平均锁竞争降低了477倍,DBT-2降低了32倍,TableScan降低了130倍,对应的吞吐量则大幅上升。当队列大小超过8时,增加队列大小仍然可以降低平均锁竞争,但很难将这部分提升转换为吞吐量(锁竞争已经被大幅降低了)。同时,我们发现,即使队列非常小(2),Pgbatching也优于PGPref。
直观上,选择一个小的批量阈值可以让postgreSQL后端进程更容易获取锁(无需在FIFO队列满之前多次阻塞调用TryLock()获取锁),因此可以降低锁竞争的概率。但表III的数据显示出,只有当批量阈值的数目小于32时才会出现这种趋势。当将批量阈值从1增加到32,我们发现其平均竞争降低了,且吞吐量增加。这是因为较低的阈值可以提前触发提交动作(或可以以小批量提交访问历史),并增加线程通过TryLock()获取锁的概率。
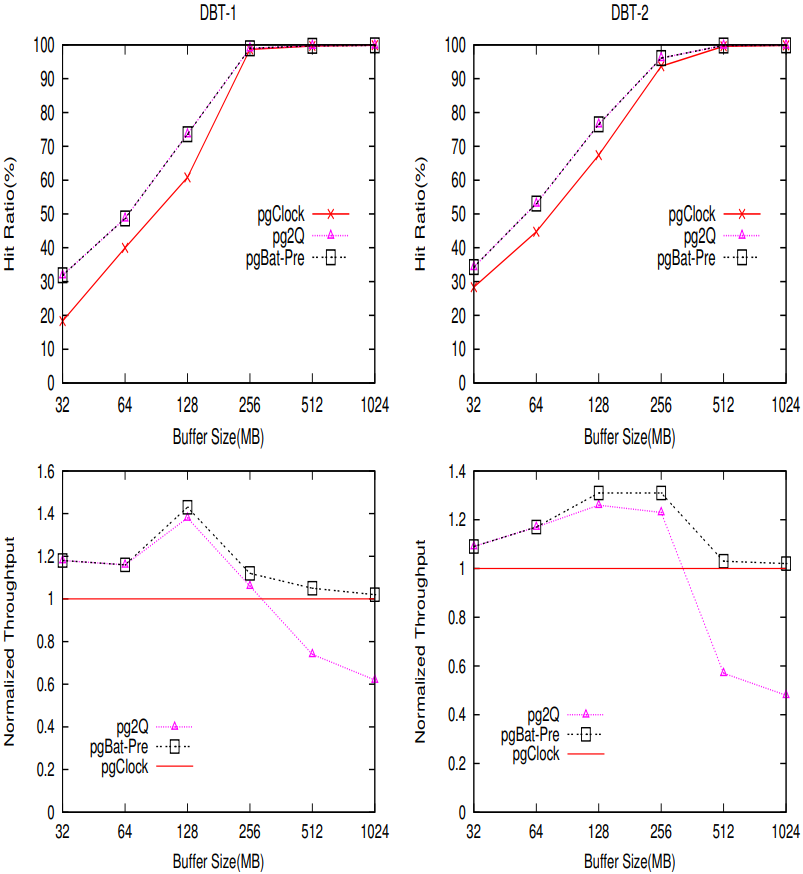
图8. PowerEdge 1900服务器上,在3个postgreSQL系统(pgClock, pg2Q 和pgBat-Pre)中使用DBT-1和DBT-2负载时的命中率和归一化吞吐量(处理器数目为8)。吞吐量为与pgClock系统的归一化值。
当批量阈值超过32后,后端进程批量提交的访问历史会大于32(个页访问),通过这样方式有效分摊获取锁开销。上面展示了非阻塞获取锁(TryLock())的优势。使用相对较小的阈值,在FIFO队列满之前会多次调用TryLock(),且在不阻塞自身的前提下获取到锁的概率也非常高。因此,我们可以看到,当批量阈值从32增加到64时,平均锁竞争增加,吞吐量下降。
当批量阈值设置为队列大小(64)时,后端进程获取TryLock()的概率将非常小。最终,可以看到平均锁竞争的大幅上升以及吞吐量的下降(尽管使用大批量分摊了获取锁的成本)。实验表明为了获得TryLock()的优势,有必要让批量阈值足够小于队列的大小。
F. 总体性能
本节中,我们将评估当PowerEdge 1900上的处理器数为8时,3个系统pgClock, pg2Q 和 pgBat-Pre的整体性能。我们已经评估了在缓存大小等于负载数据大小情况下各种系统的扩展性。实验结果表明,结合批量和预加载技术,可以有效降低锁竞争。然而,真实系统中,缓存大小通常远小于数据大小。因此,通过提升命中率来降低I/O操作的开销对整体性能来说非常重要。在本次实验中,我们将缓存大小从32MB增加到1024MB,并让系统发起直接I/O来绕过操作系统的缓存。DBT-1 和 DBT2的数据量分别为6.8GB 和 5.6GB,因此缓存无法满足所有的访问。
图8展示了3个系统中的命中率吞吐量。当内存比较小时(小于256MB),系统是I/O密集型的。通过维持更好的高命中率,系统pg2Q和pgBat-Pre产生了比系统pgClock更高的吞吐量。但随着内存大小的增加,系统的整体性能主要取决于其扩展性,系统pg2Q的命中率优势则不那么明显。当缓存大小增加到1GB时,整体性能将低于系统pgClock。同时,系统pgBat-Pref在提升扩展性的同时,维持了其性能优势。同时也可以注意到,pg2Q个pgBatPref的命中率曲线重叠率非常高。表明,我们的技术并没有影响命中率。
V. 相关工作
在系统和数据库社区中,已经积极开展了应对锁竞争引起的性能降级的研究。通常可以通过如下方式降低锁竞争:
A. 使用分布式锁降低锁的粒度
降低锁粒度是降低锁竞争的常用方法。使用多个细粒度锁来替换全局锁可以移除单点竞争。Oracle Universal Server [7], ADABAS [8] 和 Mr.LRU 的替换算法[19]使用多个列表来管理缓存,每个列表由独立的锁保护。当一个新页进入缓存后,Oracle Universal Server会将该页插入无锁列表的首部,而ADABAS会以轮询的方式选择一个列表。它们都允许从一个列表中淘汰页,并将其插入另一个列表。因此很多替换算法,如2Q[2]和LIRS[1]将无法工作。为了解决该问题,Mr.LRU会通过哈希选择列表,保证每次从磁盘加载一个页时,该页都能进入相同的列表。
(包括Mr.LRU使用的)分布式锁方式有如下严重缺陷:(1)无法用于实现检测访问顺序的替换算法,如SEQ[12],因为相同顺序的页可能被分布到多个列表中。(2)虽然可以将页均匀地分布到多个列表中,但对缓存页的访问则可能并不均匀。具有热点页的列表,如顶级索引或用于并行连接(parallel join)的小型表中的页,仍然会受制于锁竞争。(3)为了降低竞争,需要将缓存切分为成百上千个列表。这样每个列表的大小要远小于缓存的大小。使用小型列表时,需要对这些页进行特殊处理,防止被淘汰,如脏页和索引页就有可能被永久从缓存中淘汰。相比之下,我们的框架能够实现所有的替换算法,而无需切分缓存。
B. 降低锁持有时间
从前面可知,锁的持有时间越长,竞争越严重。降低锁持有时间是另一种有效降低锁竞争的方式。
Charm中使用的TSTE(二阶段事务执行)策略将磁盘I/O和锁获取分成两个互斥的阶段,从而保证一个事务所需要的所有数据页在锁定前就已经存在于内存中。通过这种方式TSTE将磁盘事务处理系统中的锁竞争延迟降低到与内存事务系统相同的水平。
在2.4版本的Linux内核中,调度器会遍历使用自旋锁保护的全局队列中的task结构体,并从中选择一个任务运行。论文[21]表明,在遍历过程中,硬件缓存中的不必要的冲突未命中可能会增加遍历时间,进而恶化自旋锁上的竞争。通过在内存中仔细布局task结构,减少遍历所需的时间,可以避免大部分冲突未命中,并且可以大大减少锁竞争。相比之下,我们的框架可以通过预加载技术减少在执行替换算法时,用在降低硬件缓存未命中中的锁持有时间,以及在批量模式下,为多个访问执行替换算法时的锁持有时间。
C. Wait-Free 同步和事务内存
由于锁同步会导致性能降级和优先级翻转等问题。wait-free同步[22]通过确保一个事务能够在有限的步骤内完成访问共享资源的操作(无需关心其他事务的执行进度)来解决这些问题。然而,很难设计采纳这种技术的程序,同时有可能找不到实现了wait-free的算法。再者,wait-free同步要求硬件支持原子语义。例如,双边队列的wait-free实现要求实现Double CompareAnd-Swap (DCAS),而大多数处理器不支持这类实现。
事务内存是另一种解决这类锁竞争的方式。在事务内存中,一个事务被认为是基于共享资源的一系列操作。由实现事务内存的硬件[23]或软件[24]保证执行的原子性。它通过启用乐观并发控制[25],[26]来提升系统的扩展性。虽然硬件事务内存还没有实现,但已经有各种软件事务内存(STM)实现。对STM和锁同步的性能比较发现,只有当事务处理[27]不会频繁修改共享资源时,STM才会优于锁。因为替换算法中的数据结构可以(基于每个页访问)被频繁修改,事务内存几乎无法提升替换算法的扩展性。相比之下,可以在软件中简单实现BP-Wrapper中的批量和预加载技术,且不需要硬件支持。
VI. 总结和后续工作
在本论文中,我们解决了DBMS系统中高级替换算法由于锁竞争导致的扩展性问题。我们提出了一种有效且可扩展的框架,BP-Wrapper,该框架中的批量和预加载技术可以在不修改算法的前提下适用于所有替换算法。由于不需要对算法进行修改,因此可以保证原始替换算法的性能优势,并节省人力。该框架的唯一开销是为每个事务处理线程分配一个小型的FIFO队列,该队列中保存了线程最近的访问信息。
我们已经在postgreSQL 8.2.3中实现了该框架,并使用一个TPC-W-like负载,一个TPC-C-like负载以及一个组合负载进行测试。我们的性能评估表明,与未修改的替换算法(如LRU和2Q)相比,BP-Wrapper可以增加近两倍的系统吞吐量,以及获得如同在命中时不使用锁的算法一样的扩展性(如时钟算法)。后续,我们计划在大型系统上(特别是具有更多个多核处理器的系统)以及使用真实负载的生产环境上评估BP-Wrapper。
引用
[1] S. Jiang and X. Zhang, "LIRS: an efficient low inter-reference recency set replacement policy to improve buffer cache performance,"in SIGMETRICS '02: Proceedings of the 2002 ACM SIGMETRICS international conference on Measurement and modeling of computer systems, 2002, pp. 31–42.
[2] T. Johnson and D. Shasha, "2Q: A low overhead high performance buffer management replacement algorithm," in VLDB ’94: Proceedings of the 20th International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc., 1994, pp. 439–450.
[3] N. Megiddo and D. S. Modha, ”ARC: A self-tuning, low overhead replacement cache,“ in FAST ’03: Proceedings of the 2nd USENIX Conference on File and Storage Technologies, 2003, pp. 115–130.
[4] T. E. Anderson, “The performance of spin-lock alternatives for sharedmemory multiprocessors,” in IEEE Transactions on Parallel and Distributed Systems, vol. 1, no. 1, 1990, pp. 6–16.
[5] J. M. Mellor-Crummey and M. L. Scott, “Algorithms for scalable synchronization on shared-memory multiprocessors,” ACM Trans. Comput. Syst., vol. 9, no. 1, pp. 21–65, 1991.
[6] X. Zhang, R. Castaneda, and E. W. Chan, “Spin-lock synchronization on ˜ the butterfly and KSR1,” IEEE Parallel Distrib. Technol., vol. 2, no. 1, pp. 51–63, 1994.
[7] W. Bridge, A. Joshi, M. Keihl, T. Lahiri, J. Loaiza, and N. MacNaughton, “The oracle universal server buffer manager,” in VLDB’97, Proceedings of 23rd International Conference on Very Large Data Bases, August 25-29, 1997, Athens, Greece, M. Jarke, M. J. Carey, K. R. Dittrich, F. H. Lochovsky, P. Loucopoulos, and M. A. Jeusfeld, Eds. Morgan Kaufmann, 1997, pp. 590–594.
[8] H. Schoning, “The ADABAS buffer pool manager,” in ¨ VLDB ’98: Proceedings of the 24rd International Conference on Very Large Data Bases. Morgan Kaufmann Publishers Inc., 1998, pp. 675–679.
[9] F. J. Corbato, “A paging experiment with the multics system,” in In Honor of Philip M. Morse, Feshbach and Ingard, Eds. Cambridge, Mass: MIT Press, 1969, p. 217.
[10] S. Jiang, F. Chen, and X. Zhang, “CLOCK-Pro: An effective improvement of the CLOCK replacement,” in Proceedings of the Annual USENIX Technical Conference ’05, Anaheim, CA, 2005.
[11] S. Bansal and D. S. Modha, “CAR: Clock with adaptive replacement,” in FAST ’04: Proceedings of the 3rd USENIX Conference on File and Storage Technologies, 2004, pp. 187–200.
[12] G. Glass and P. Cao, “Adaptive page replacement based on memory reference behavior,” in SIGMETRICS ’97: Proceedings of the 1997 ACM SIGMETRICS international conference on Measurement and modeling of computer systems, 1997, pp. 115–126.
[13] “DB2 for z/OS: DB2 database design,” 2004, URL: http://www.ibm.com/developerworks/db2/library/techarticle/dm0408whitlark/index.html.
[14] M. Blasgen, J. Gray, M. Mitoma, and T. Price, “The convoy phenomenon,” SIGOPS Oper. Syst. Rev., vol. 13, no. 2, pp. 20–25, 1979.
[15] Y. Zhou, J. Philbin, and K. Li, “The multi-queue replacement algorithm for second level buffer caches,” in Proceedings of the General Track: 2002 USENIX Annual Technical Conference, 2001, pp. 91–104.
[16] The Open Source Development Laboratory, “OSDL - database test suite,” URL: http://old. linux-foundation.org/lab activities/kernel testing/ osdl database test suite/.
[17] Transaction Processing Performance Council, “TPC-W,” URL: http://www.tpc.org/tpcw.
[18] Transaction Processing Performance Council., “TPC-C,” URL: http://www.tpc.org/tpcc.
[19] W. Wang, “Storage management for large scale systems,” Ph.D. dissertation, Department of Computer Science, University of Saskatchewan, Canada, 2004.
[20] L. Huang and T. cker Chiueh, “Charm: An I/O-driven execution strategy for high-performance transaction processing,” in Proceedings of the General Track: 2002 USENIX Annual Technical Conference, 2002, pp. 275–288.
[21] S. Yamamura, A. Hirai, M. Sato, M. Yamamoto, A. Naruse, and K. Kumon, “Speeding up kernel scheduler by reducing cache misses,” in Proceedings of the FREENIX Track: 2002 USENIX Annual Technical Conference, 2002, pp. 275–285.
[22] M. Herlihy, “Wait-free synchronization,” ACM Trans. Program. Lang. Syst., vol. 13, no. 1, pp. 124–149, 1991.
[23] M. Herlihy and J. E. B. Moss, “Transactional memory: Architectural support for lock-free data structures,” in Proceedings of the 20th Annual International Symposium on Computer Architecture, 1993, pp. 289–300.
[24] N. Shavit and D. Touitou, “Software transactional memory,” in PODC ’95: Proceedings of the fourteenth annual ACM symposium on Principles of distributed computing, 1995, pp. 204–213.
[25] H. T. Kung and J. T. Robinson, “On optimistic methods for concurrency control,” ACM Trans. Database Syst., vol. 6, no. 2, pp. 213–226, 1981.
[26] D. Gawlick and D. Kinkade, “Varieties of concurrency control in IMS/VS fast path,” IEEE Database Eng. Bull., vol. 8, no. 2, pp. 3–10, 1985.
[27] B. Saha, A.-R. Adl-Tabatabai, R. L. Hudson, C. C. Minh, and B. Hertzberg, “McRT-STM: a high performance software transactional memory system for a multi-core runtime,” in PPoPP ’06: Proceedings of the eleventh ACM SIGPLAN symposium on Principles and practice of parallel programming, 2006, pp. 187–197.
参考
- caching-in-go,比较了bigCache、freeCache、GroupCache各自实现上的优缺点
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/14861768.html

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步