


在云环境中实现成功的现代数据分析平台
在云环境中实现成功的现代数据分析平台
译自:Architecting a Successful Modern Data Analytics Platform in the Cloud
前面讨论了如何在云环境中构建成功的现代数据分析平台,本文会通过AWS和微软Azure的参考架构来帮助我们提升设计上的可扩展性,灵活性和健壮性。
介绍
过去20年间,我曾帮助了上百个公司,利用不断发展的技术工具将业务创意变为现实。有些公司出生在云时代(如Waze, Viber, and JFrog),有些是本身有很多技术人员和软件开发者的科技巨头(如Amazon 和Intuit),而有些则是尝试重塑自我来保持未来竞争力的大型企业。本文将重点关注后一类公司(它们是如今的经济支柱,如Capital One, AmEx, Liberty Mutual, Orbia, Grupo Salinas, 和PepsiCo)。
保持竞争力并采用现代技术(如云(快速实现价值)和AI(更智能地使用数据,更先进的分析方式,以及机器学习等))的一种方式是为"AI飞轮"搭建一套环境。在前面的文章中已经解释了飞轮的细节。简而言之,转动飞轮的方法为:
- 输入更多的、可以从数据和机器学习模型获益的业务使用场景。
- 添加更多的、可以用于解决上述业务场景的数据源。
- 提升可以构建分析和机器学习模型的数据分析和科学。
- 提升上述分析和模型的生产级别和可用性。
现在飞轮的转速还不够快。然而一旦成形,就可以变成一个强有力的业务工具,进而影响到内部业务管理和外部客户服务的方方面面。
根据数据来构建飞轮架构的首要障碍就是关系型数据库(如大型组织中用到的Oracle)的黏性。我在“Kill Oracle and Break Down Teradata一文中对问题进行了描述,即当今需要一个分布的且更具扩展性的数据平台来适应业务的动态和大小。数据分析平台的主要布局分为以下三层:
- Tier I :从传统事务型数据库(如 SAP, Salesforce, Oracle, 或MS-SQL)中复制到低成本对象存储中的原始数据。
- Tier II:通过丰富和优化Tier I而衍生出来的形式,仍然是低成本的对象存储。
- Tier III:优化访问模式的数据存储。使用不同且更昂贵的存储方式,如 RDBMS, 内存式缓存或其他基于索引的系统。
实际可以将数据架构分为了数据采集层(数据复制)、数据优化层(压缩、聚合、安全、分析等)和数据展示层(提供API网关和BI展示等)
通用参考架构
下面是三层模型在通用参考架构中的示意图:
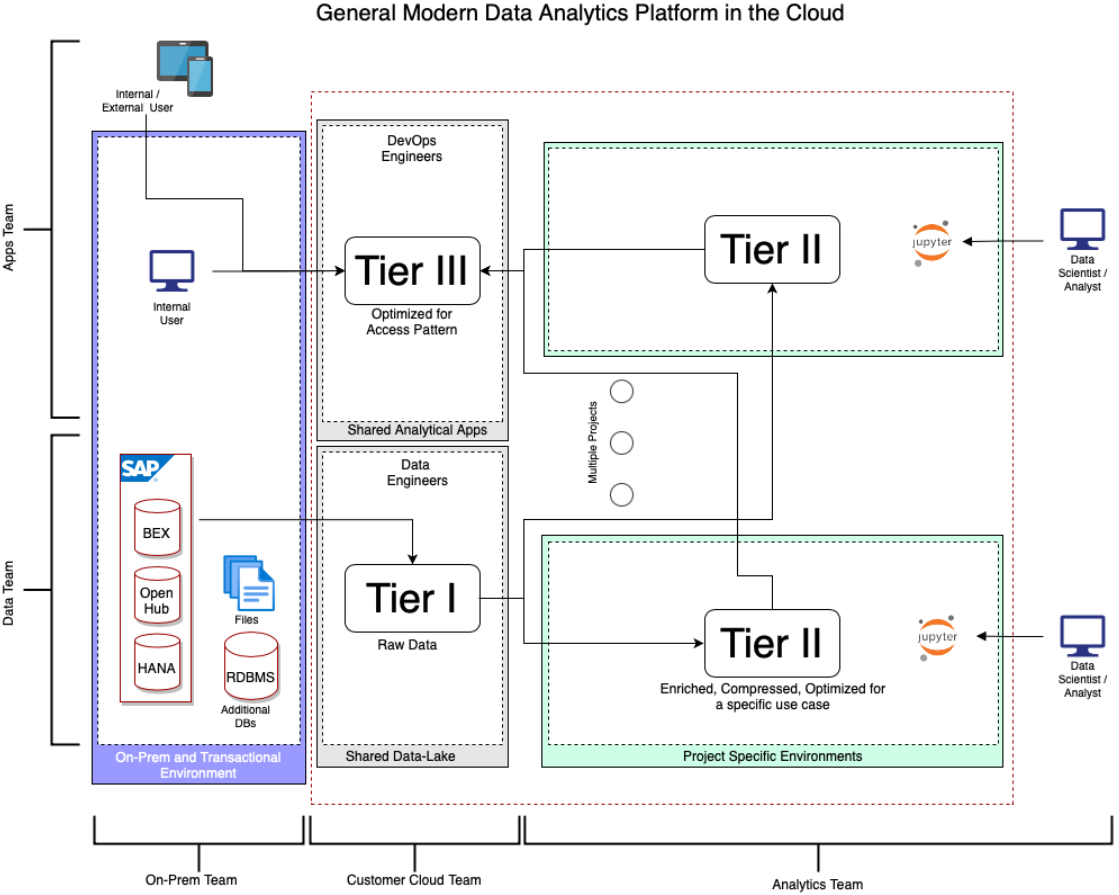
General Modern Data Analytics Platform in the Cloud
第一步是从不同的内部系统或数据库(如ERO和CRM)中复制数据,然后将其导入云环境中(通常称为数据湖)。
可以借助很多工具并以某种形式来实现数据湖和数仓。飞轮的概念使得数据湖的实现更具敏捷和可迭代性。将"首先解决数据的问题"以及构建一个"完整的"数据湖作为分析项目的先决条件,常常会导致大型组织中的数据和分析项目的失败。主要的失败原因为:
- 前期投资
- 实现价值的时间很长
- 缺少反馈环,无法确定需要哪些数据以及如何组织这些数据
飞轮旋转的迭代性质对应如下标语:
“You always have enough data, and you never have enough data.”
正如前面讨论的,应该从特定的业务场景开始,并以此进行后续的工作:
- Q1:如何与业务用户进行交互来支持他们的工作流程(=app),
- Q2:如何构建一个业务逻辑或机器学习模型来满足工作流程(=分析)的需要,且
- Q3:如何获取相关的数据来构建模型(=数据)?
一旦解决了上述问题,就可以让数据工程师就绪数据。然后分析团队会通过试验这些数据来不断优化模型,DevOps团队可以构建模型接口。
需要注意的是,飞轮的各个参与者来自不同的学科,并使用不同的工具。业务用户应该继续使用他们喜欢的接口;数据工程师可以自由地使用他们的大数据工具。数据分析和科学团队应该有自己的实验环境,而DevOps团队可以构建生产级别的系统。上面的架构旨在使每个团队都能高效地工作,并整合了周边团队。
AWS参考架构
可以根据每个公司使用的云、每个组织所需的安全措施、云成熟度以及正在使用的数据系统的类型等来实现各种通用架构。
首先看下AWS的参考架构。一开始,它会使用Data Migration Service (DMS)从传统数据库中复制数据。DMS可以连接到各种RDBMS,如Oracle或MS-SQL数据库,并支持使用一次性或连续模式将数据复制到S3中。图中的第二种复制方法使用SFTP将文件上传到S3,这些文件通常是从内部数据库导出的数据,或从内部系统生成的大型报告。
实际中有很多方式可以设计共享的数据库环境(tier I),如使用Redshift,EMR(+Spark),Data-lake Formation等。但最经济的方式是使用S3和Athena (使用PrestoDB管理)。
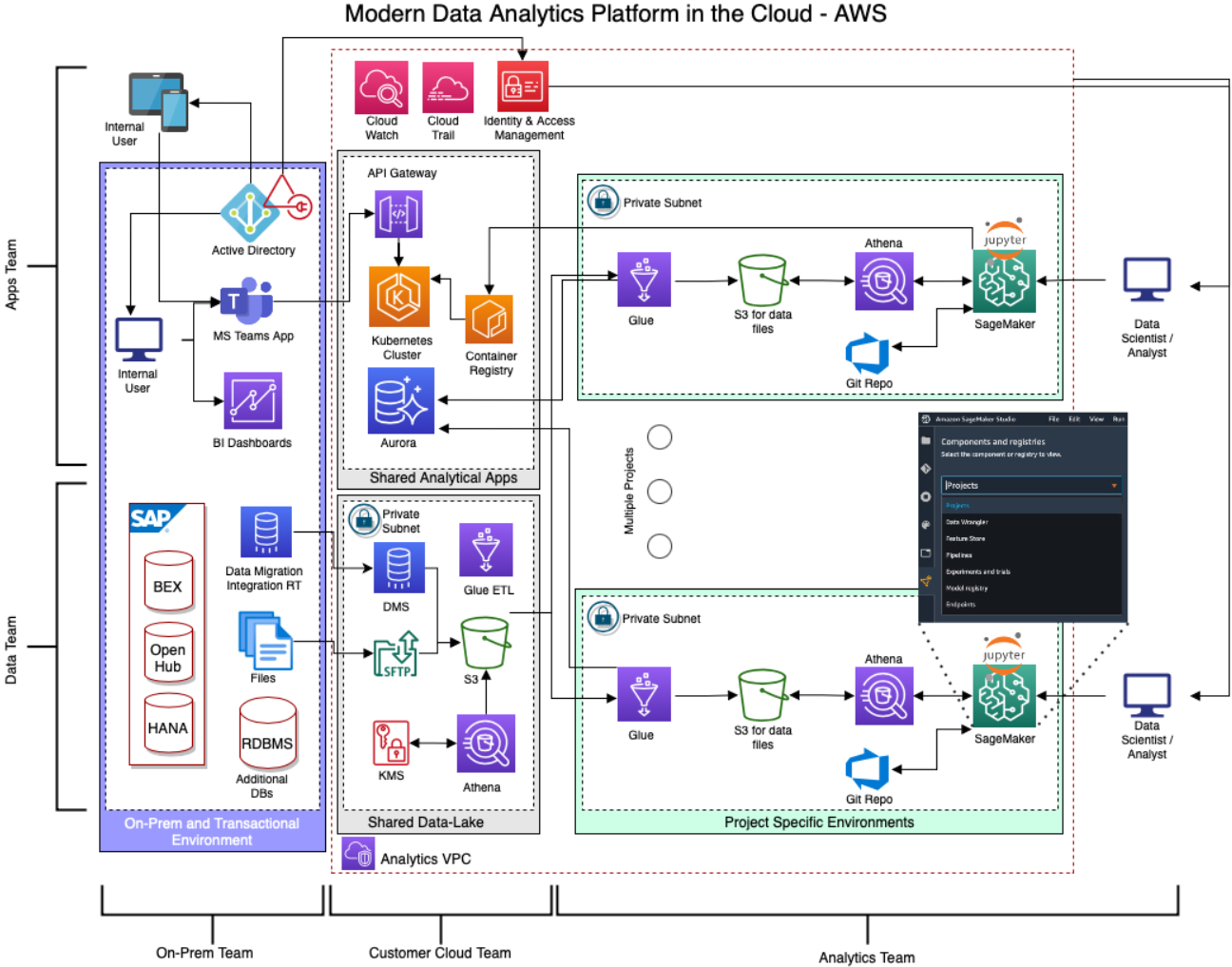
Modern Data Analytics Platform in the Cloud — AWS Version
特定项目环境(Tier II)比较难以理解,因为它违反了“一个数据源”以及我们在Tier I逐步建立的单个数据仓库/湖的原则。首先,你希望有多个环境,用来支持不同的团队使用不同的形式、规模和次数来实验数据和进行分析。每个团队都可以从环境中拉取他们的模型所需要的数据,而共享数据库团队可以控制团队访问的数据。复杂环境中,可以使用AWS Lake Formation 来管理数据湖。这种分离环境的方式可以让外部团队协助(组织)引导分析实践。对于组织来说,这些技能通常比较新,可以让一个可信的外部团队(快速地)获取一个独立的环境并进行实验、PoC、并构建一个特定的模型。组织最重要的是对数据的控制能力,与将数据“发送”到SaaS服务或其他失控环境相比,管控权限和数据访问的能力对于数据治理和隐私至关重。云独有的能力允许“按量付费”以及简单地“正确调整资源大小”,可以高效而直接地操作多个独立的环境。
部署到Tier II环境上的服务也可以发生变化,例如在Athena 无法满足任意团队的需求时可以包含Redshift Spectrum,或在团队并不需要SageMaker 时,可以为其指定一个EC2。我建议使用上述S3,Glue,Athena和SageMaker的高性价比组合。
在Azure 一节中,我们将详细讨论共享分析apps环境(Tier III),它在这在两个云环境中都非常相似。在AWS中,你可以使用像Lambda这样新型的服务(而不是笨重的kubernetes集群),可以在Lambda中部署Dockers镜像,让AWS为你管理集群。但在上面的架构中,我建议使用EKS,是因为很多大公司更倾向于在其他环境中使用更通用的技术,并在需要时雇佣更多的人力(专家)来对其进行管理。选择K8的其他因素如它集成了标准的监控的安全工具。
Azure 参考架构
我曾向很多公司建议过使用多云策略来从供应商手中选择最合适的工具,但有些公司会选择单一供应商产品来实现"标准化",这样做的原因可能是云提供商给予了较大优惠,一旦客户因此次投资而“锁定”该供应商,则它就极有可能在未来的投资中再次获胜。另一种原因可能是组织需要对多个环境进行安全加固,并培训管理员来使用不同的云。
我建议公司使用供应商提供的优惠来在一个云环境中培训人员,并做好扩展到其他云供应商的准备,一旦优惠过期,团队人员就可以随时就绪。下面的架构旨在使用多云操作。你可以在Azure中部署数据湖,将一半分析环境放在Azure中,一半放在AWS中(例如将分析App放到AWS中)。
该架构的布局与映射到Azure环境中的相关服务对应。如下图所示,特定的服务其实有很多替代品,下面建议的架构中使用了更先进、更成熟的服务。如,你可以在本地环境中使用SSIS,但最好使用功能更全面的 Data Factory。同时,你可以使用 Synapse,而不是更成熟的 Azure Databricks,但对企业来说,这样做可能为时过早。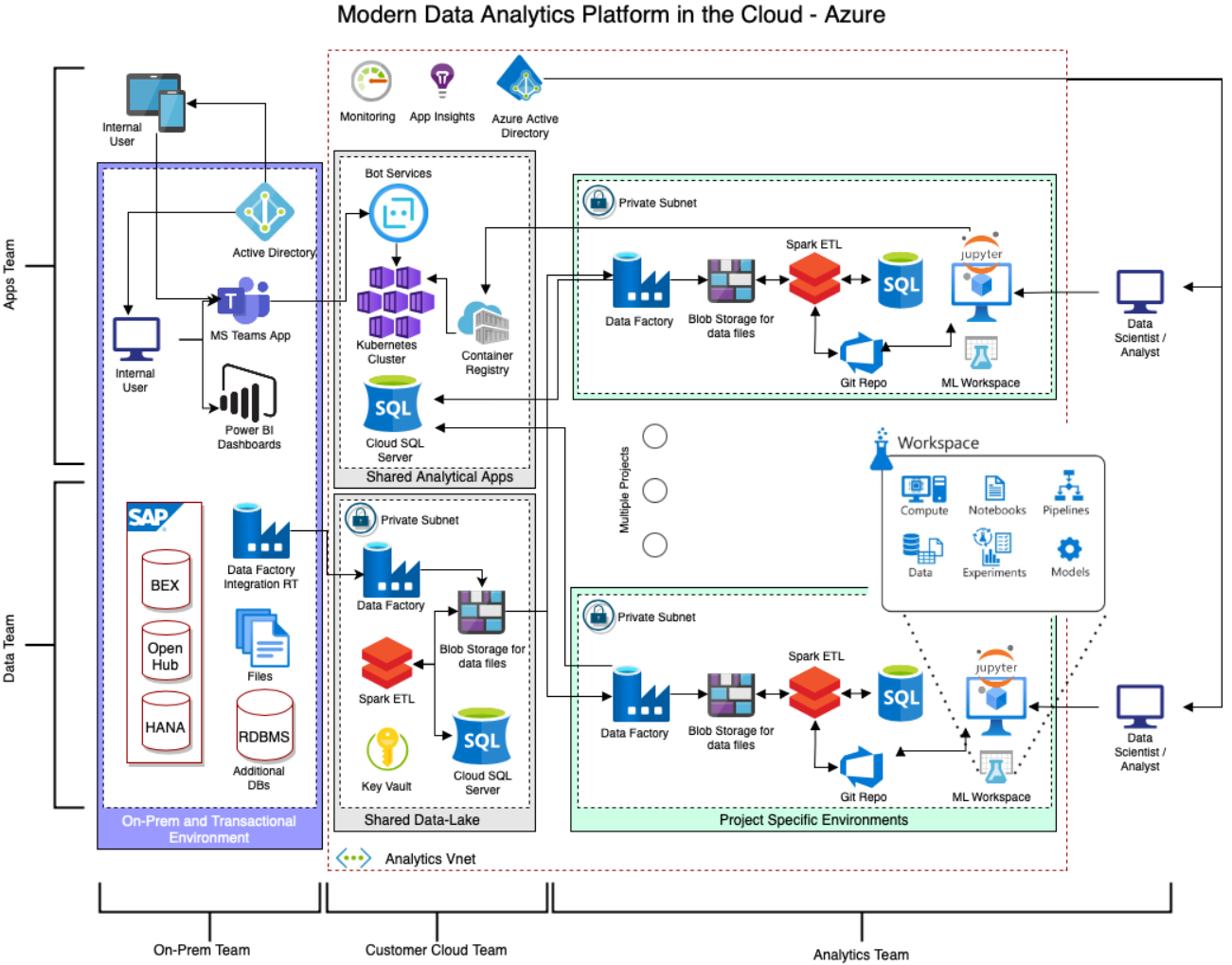
Modern Data Analytics Platform in the Cloud — Azure Version
需要注意的是,与AWS中使用的Athena服务相比,上述分析环境增加了一个SQL数据库。数据科学家和分析人员需要两个数据接口:直接加载文件和SQL方式,用来对数据集进行过滤和聚合。因此,提供SQL接口可以提高他们的生产率,并减少在Pandas或其他实例的过滤和聚合处理中使用的过于强大的计算实例所造成的开销。
分析应用服务
我们经常会更加关注数据工程和ML模型,反而忘了我们需要服务的对象。业务用户是这些需求->数据->模型->输出环的开头和结尾。在外面构建分析流时,我们会假设最终会在BI工具或看板中展示结果。可支持的工具如Tableau, QlikView, PowerBI, SiSense, QuickSight, reDash, Looker, SuperSet等。为了支持最终展示,我们需要将分析结果写回到SQL数据库,如 MS-SQL, RDS Aurora, Redshift或其他类似的RDBMS。
我建议不要在 Tier I描述的关系数据湖中包含这类数据库。主要原因是要考虑谁可以访问这部分数据以及Tier本身的特性(TierI是不可变的)。同时Tier III 是随时可以进行变动和更新的。
在下图中可以看到我添加了一个Kubernetes集群(或其他向ECS或Lambda这样的集群管理)来允许在各种场景下为业务用户提供分析输出。例如,一个分析机器学习项目的输出可能是一个价格模型,用于给销售人员提供价格建议;或是一个预测模型,对特定市场的产品销售做出预测,优化贸易经理的促销建议。当这些模型进行部署,测试,并可以给业务用户使用时,项目团队就可以将这些模型打包到Docker容器中,并将其推送到一个容器仓库,最后部署到容器服务中。一旦服务可用,应用团队就可以通过使用现有系统中的新字段或全新系统将其集成到应用中。App产品团队负责在这些系统上应用最佳实践和工具。
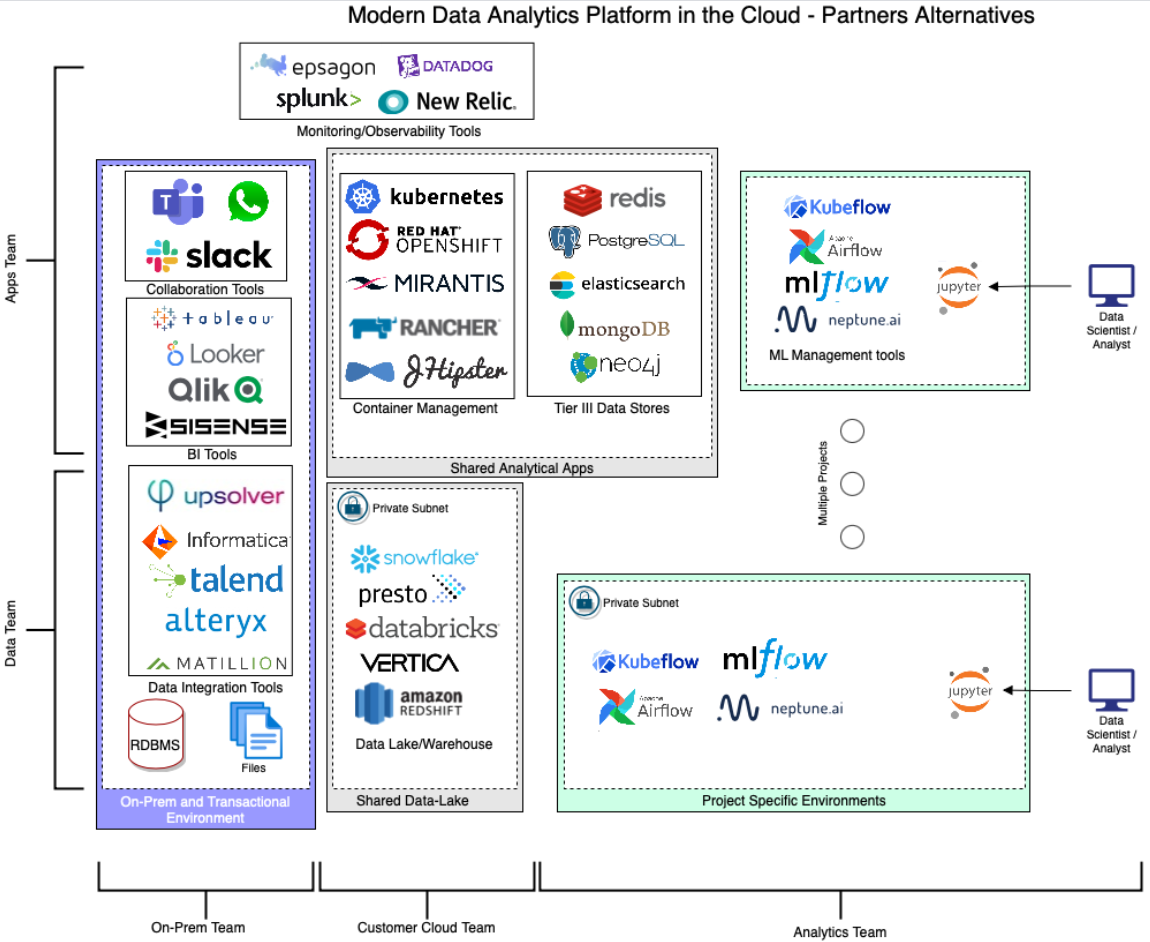
Modern Data Analytics Platform in the Cloud — Partners Alternatives
在上图中,我添加了很多可替代的选项。上述列表并不全面,但包含很多公司常用的工具或我建议公司尝试去使用的工具,特别适用于那些为未来的业务数据分析寻求成熟、安全的解决方案的大型企业。
上图中需要注意的一点是Tier III中的数据存储部分,数据存储需要支持高效的数据访问和用户消费。最常用来为终端用户存储数据的地方是关系型数据库(RDBMS),在第一个版本中,我使用了RDS和SQL服务。然而,正如对Tier III属性的描述一样,最好根据访问模式来选择数据存储,而不应该依赖通用的SQL访问服务。今天企业可以选择使用Redis, ElasticSearch, and MongoDB等这类足够成熟的服务,它们可以简化很多使用场景,如有序集合,文本文档,JSON文档,关系图或其他难以在RDBMS中映射、存储和访问的格式。
细心的读者可能注意到,我在 Shared Data-Lake 部分中引入了Amazon Redshift,该服务在其他云平台上是不可用的。原因是Redshift 在第一个真实的云数仓解决方案中扮演者至关重要的角色。Redshift为其他行业指明了方向。如今,它是集出色性能,成本结构和灵活性为一身的最佳数据工具之一。Redshift是我参与启动的第一个AWS服务,直到2012年,它对静态和昂贵数据仓库域产生了巨大影响。
总结
本文简要介绍了针对每层的最佳服务,以及选择其中一种的理由。但随着数据领域生态的快速演进以及功能的重叠,依然会存在很多问题和困惑。但无论怎样,一旦架构模型化,并且"没有把所有鸡蛋放到一个篮子里",后续的升级和服务替换就会相对容易,即使在大型企业中也不会中断整体的数据流,分析以及普遍性创新。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/14497921.html

