
流量控制--5.Classless Queuing Disciplines (qdiscs)
Classless Queuing Disciplines (qdiscs)
本文涉及的队列规则(Qdisc)都可以作为接口上的主qdisc,或作为一个classful qdiscs的叶子类。这些是Linux下使用的基本调度器。默认的调度器为pfifo_fast。
6.1 FIFO,先进先出(pfifo和bfifo)
注:虽然FIFO是队列系统中最简单的元素之一,但pfifo和bfifo都不是Linux接口上的默认qdisc。参见 Section 6.2, “
pfifo_fast, the default Linux qdisc”了解更多关于默认qdisc(pfifo_fast)的信息。
6.1.1 pfifo, bfifo算法
FIFO算法是所有Linux网络接口的默认qdisc(pfifo_fast)。它不会对报文进行整流和重排,仅在接收到报文并在报文入队列后尽快将其发送出去。这也是新创建的类使用的qdisc(除非使用其他的qdisc或类替换FIFO)。

FIFO算法维护了一个报文列表,当一个报文入队列后,会将其插入队列末尾。当需要将一个报文发送到网络上时,会将列表首部的报文进行发送。
6.1.2 limit参数
真实的FIFO qdisc必须限制列表的大小(缓冲大小)来防止溢出,这种情况下无法将接收到的报文入队列。Linux实现了两个基本的FIFO qdisc,一个基于字节数,另一个基于报文。如果不考虑使用的FIFO类型,队列的大小由参数limit决定。对于pfifo(Packet limited First In, First Out queue),其单位为报文,对于bfifo(Byte limited First In, First Out queue) ,其单位为字节。
对于pfifo,大小默认等于接口的txqueuelen,可以使用ifconfig或ip查看。该参数的范围为[0, UINT32_MAX]。
对于bfifo,大小默认等于txqueuelen乘以接口MTU。该参数的范围为[0, UINT32_MAX]字节。在计算报文长度时会考虑链路层首部。
例6. 为一个报文FIFO或字节FIFO指定一个limit
[root@leander]# cat bfifo.tcc
/*
* make a FIFO on eth0 with 10kbyte queue size
*
*/
dev eth0 {
egress {
fifo (limit 10kB );
}
}
[root@leander]# tcc < bfifo.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 bfifo limit 10240
[root@leander]# cat pfifo.tcc
/*
* make a FIFO on eth0 with 30 packet queue size
*
*/
dev eth0 {
egress {
fifo (limit 30p );
}
}
[root@leander]# tcc < pfifo.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 pfifo limit 30
6.1.3. tc –s qdisc ls
tc -s qdisc ls的输出包含limit(报文数或字节数),以及实际发送的字节数和报文数。未发送和丢弃的报文使用括号括起来,并不计算在Sent之内。
本例中,队列长度为1000个报文,发送的681个报文的大小为45894 字节。没有丢包,由于pfifo不会降低报文的速率,因此没有overlimits:
$ tc -s qdisc ls dev eth0
qdisc pfifo 8001: dev eth0 limit 100p
Sent 45894 bytes 681 pkts (dropped 0, overlimits 0)
如果出现积压(overlimits),也会显示出来。
与所有非默认的qdisc一样,pfifo和bfifo会维护统计数据。
6.2. pfifo_fast, 默认的Linux qdisc
pfifo_fast (three-band first in, first out queue) qdisc是Linux上所有接口使用的默认qdisc。当创建一个接口后,会自动使用pfifo_fast qdisc队列。如果附加了其他qdisc,这些qdisc则会抢占默认的pfifo_fast,当移除现有的qdisc时,pfifo_fast会自动恢复运行。
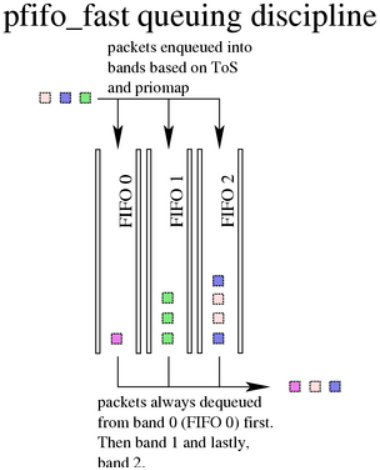
6.2.1. pfifo_fast算法
该算法基于传统的FIFO qdisc,但同时也提供了一些基于优先级的处理。它使用三个不同的band(独立的FIFO)来分割流量。具有最高优先级的流量(交互式流量)会进入band 0,总是会被优先处理。类似地,在band 2出队列之前,band 1中不会存在未处理的报文。
该算法与classful prio qdisc非常类似。pfifo_fast qdisc就像三个并排的pfifo队列,一个报文可以根据其服务类型(ToS)位进入其中某一个FIFO。三个band并不能同时入队列(当具有最小值,即优先级高的band包含流量时,具有高数值的,即优先级低的band就不能出队列)。这样可以优先处理交互流量,或者对“最低成本”的流量进行惩罚。每个band最多可以容纳txqueuelen 大小的报文,可以使用ifconfig或ip配置。当接收到额外的报文时,如果特定的band满了,则会丢弃该报文。
参见下面的6.2.3章节来了解ToS为如何转换为band。
6.2.2. txqueuelen 参数
三个band的长度取决于接口的txqueuelen。
6.2.3. Bugs
终端用户无需对pfifo_fast qdisc进行配置。下面是默认配置。
priomap决定了报文的优先级,由内核分配并映射到bands。内核会根据报文的八个比特位的ToS进行映射,ToS如下:

四个ToS位的定义如下:

可以使用 tcpdump -v -v 显示整个报文的ToS字段(不仅仅是四个比特位的内容)。
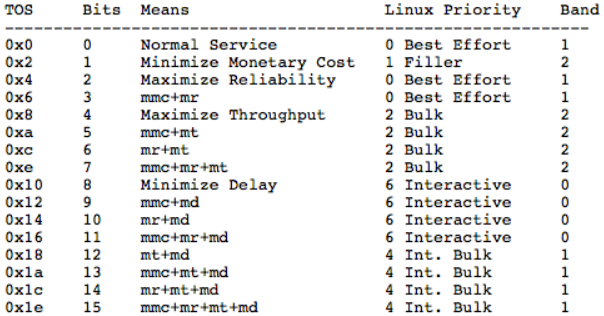
上面展示了很多数值,第二列包含于ToS比特位相关的数值,后面是其对应的意义。例如15表示期望最小货币开销,最大可靠性,最大吞吐量以及最小延迟。
上述四列的内容给出了Linux是如何解析ToS 比特位的,以及它们被映射到的优先级,如优先级4映射到的band 号为1。允许映射到更高的优先级(>7),但这类优先级与ToS映射无关,表示其他意义。
最后一列给出了默认的优先级映射的结果。在命令行中,默认的优先级映射为:
1, 2, 2, 2, 1, 2, 0, 0 , 1, 1, 1, 1, 1, 1, 1, 1
与其他非标准的qdisc不同,pfifo_fast不会维护信息,且不会展示在tc qdisc ls命令中。这是因为它是默认的qdisc。
6.3. SFQ, 随机公平队列
随机公平队列是tc命令使用的用于流量控制的classless qdisc。SFQ不会整流,仅负责根据流来调度传输的报文,目的是保证公平,这样每个流都能够依次发送数据,防止因为单条流影响了其他流的传输速率。SFQ使用一个哈希函数将流分到不同的FIFO中,使用轮询的方式出队列。因为在哈希函数的选择上存在不公平的可能性,该函数会周期性地改变,通过扰动(参数perturb)来设置此周变动期性(参见6.3.3参数)。
因此,SFQ qdisc会在任意多的流中,尝试给每条流分配相同的机会来发送数据。

6.3.1. SFQ 算法
在进入队列之后,会基于报文的哈希值给每个报文分配一个哈希桶。该哈希值可能是从外部的流分类器获取到的,如果没有配置外部分类器,则使用默认的内部分类器。当使用内部分类器时,sfq会使用:
- 源地址
- 目的地址
- 源和目的端口
SFQ能够区分ipv4,ipv6,以及UDP,TCP和ESP等。其他协议的报文会基于32位的目的和源进行哈希。一条流大多数对应一个TCP/IP连接。
每个桶都应该表示唯一的一条流。由于多条流可能哈希到同一个桶,sdq的内部哈希算法可能会在可配置的时间间隔内受到干扰,但不公平仅会持续很短的一段时间。然而,扰动可能会在无意中导致发送报文的重排。在Linux 3-3之后,就不会存在报文重排的问题,但可能在重哈希达到上限(流的数目或每条流的报文数)后丢弃报文。
当出队列时,会以轮询的方式请求每个哈希桶的数据。
在Linux3-3之前,SFQ 的最大长度为128个报文,即最多可以分布在128个桶(1024个可用桶)上。当发生溢出时,满的桶会发生尾部丢弃,从而保持公平性。
在Linux3-3之后,SFQ 的最大长度为65535 个报文,除数的极限是65536。当发生溢出时,除非明确要求头部丢弃,否则满的桶会发生尾部丢弃,
6.3.2. 命令行使用
tc qdisc ... [divisor hashtablesize] [limit packets] [perturb seconds] [quantum bytes] [flows number] [depth number] [head drop] [redflowlimit bytes] [min bytes] [max bytes] [avpkt bytes] [burst packets] [probability P] [ecn] [harddrop]
6.3.3. 参数
- divisor: 可以用于设置不同的哈希表大小,从2.6.39内核开始可用。指定的除数必须是2的幂,并且不能大于65536。默认为1024。
- limit: SFQ limit的上限。可以用于减少默认的127个报文长度。在linux-3.3之后,可以增加该值。
- depth: 每条流的报文限制(linux-3.3之后)。默认为127,可以降低。
- perturb: 队列算法干扰的时间间隔(秒)。默认为 0,意味着不会发生干扰。不要设置过低的值,因为每个干扰都可能导致报文的重排或丢失。建议值为60。当使用外部流分类时,该值将不起作用。为了降低哈希冲突,可以增加该建议值。
- quantum: 在轮询处理期间允许出队列的字节数。默认为接口的MTU,这也是建议的最小值。
- flows: 在linux-3.3之后,可以修改默认的流的限制,默认为127。
- headdrop: 默认的SFQ行为是尾部丢弃一条流的报文。也可以使用首部丢弃,可以给TCP流提供更好的反馈。
- redflowlimit: 在每个SFQ流上配置可选的RED模块(用于防止产生bufferbloat问题)。RED(Random Early Detection)的原理是以概率的方式标记或丢弃报文。redflowlimit对每条SFQ流队列的大小作了硬性限制,单位为字节。(以下参数为RED的参数)
- min: 可以进行标记的平均队列大小,默认为max的三分之一。
- max: 在此平均队列大小下,标记的概率最大。默认为 redflowlimit的四分之一。
- probability: 可以用于标记的最大概率,为一个0.0到1.0的浮点数,默认为0.02。
- avpkt: 以字节为单位。与burst一起用于确定平均队列大小计算的时间常数,默认为1000。
- burst: 用于确定真实队列大小对平均队列大小的影响速度,默认为: (2 * min + max) / (3 * avpkt)。
- ecn: RED可以执行"标记"或"丢弃 "。显式的拥塞通知(Explicit Congestion Notification)允许RED通知远程主机它们的速率超过了可用带宽。没有启用ECN的主机可能会接收到报文丢弃的通知。如果指定了该参数,那么支持ECN的主机的报文将会被标记,而不会被丢弃(除非队列满)。
- harddrop: 如果平均流队列长度大于max字节数,该参数会强制丢弃报文,而不会执行ecn标记。
SFQ中比较容易混淆的是参数:limit,depth,flows这三个参数。limit用于限制SFQ的队列数目,depth用于限制每条流的数目,flows用于限制流的数目。SFQ会对报文进行哈希,将哈希结果相同的报文作为同一条流上的报文,然后将这条流单独放到一个队列中(受限于哈希算法,有可能存在实际上多个不同的流被哈希成了SFQ中的同一条流,因此引入了perturb)。
6.3.4 例子和用法
附加到ppp0口。
$ tc qdisc add dev ppp0 root sfq
请注意SFQ和其他非整流的qdisc一样,仅对其拥有的队列有效。链路速度等于实际可用的带宽时就是这种情况。 适用于常规电话调制解调器,ISDN连接和直接非交换式以太网链接。
大多数情况下,有线调制解调器和DSL设备不属于这一类。 当连接到交换机并尝试将数据发送到同样连接到该交换机的拥塞段时,情况也是如此。在这种情况下,有效队列并不在Linux内,因此不能用于调度。在classful qdisc中嵌入SFQ可以确保它拥有该队列。
可以在sfq中使用外部分类器,例如基于源/目的IP地址对流量进行哈希:
$ tc filter add ... flow hash keys src,dst perturb 30 divisor 1024
注意给定的divisor应该匹配sfq使用的一个哈希表。如果修改了sfq的divisor的默认值1024,则流哈希过滤器也会使用相同的值。
例7. 带可选RED模块的SFQ
[root@leander]# tc qdisc add dev eth0 parent 1:1 handle 10: sfq limit 3000 flows 512 divisor 16384 redflowlimit 100000 min 8000 max 60000 probability 0.20 ecn headdrop
例8. 创建一个SFQ
[root@leander]# cat sfq.tcc
/*
* make an SFQ on eth0 with a 10 second perturbation
*
*/
dev eth0 {
egress {
sfq( perturb 10s );
}
}
[root@leander]# tcc < sfq.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 sfq perturb 10
不幸的是,一些聪明的软件(如Kazaa和eMule等)会通过打开尽可能多的TCP会话(流)来消除公平排队带来的好处。在很多网络中,对于行为良好的用户,SFQ可以充分地将网络资源分配给竞争的流,但当遭受恶意软件入侵网络时,可能需要采取其他措施。
可以参见说明文档:man tc-sfq。
SFQ是多队列算法,RED是单队列算法,可以通过结合两个算法来达到更好的流量控制的目的。
6.4. ESFQ, 扩展随机公平队列
从概念上而言,虽然这类qdisc相比SFQ给用户提供了更多的参数,但它与SFQ并没有什么不同。该qdisc旨在解决上述SFQ的缺点。通过允许用户控制用于分配网络带宽的哈希算法(hash参数),有可能实现更加公平的带宽分配。
例9. ESFQ用法
Usage: ... esfq [ perturb SECS ] [ quantum BYTES ] [ depth FLOWS ]
[ divisor HASHBITS ] [ limit PKTS ] [ hash HASHTYPE]
Where:
HASHTYPE := { classic | src | dst }
6.5. RED,Random Early Drop
随机早期探测(Random Early Detection)是一种灵活的用于管理队列大小的classless qdisc。一般的队列在满后会从尾部丢弃报文,这种行为有可能不是最优的。RED也会执行尾部丢弃,但是以一种更平缓的方式。
一旦队列达到特定的平均长度,入队列的报文会有一定的(可配置)概率会被标记(有可能意味着丢弃该报文),这个概率会线性地增加到某一点,称为最大平均队列长度(队列也可能会变更大)。
相比简单的尾部丢弃,这样做有很多好处,且不会占用大量处理器。这种方式可以避免在流量突增之后导致的同步重传(这些重传会导致更多的重传)。这样做的目的是使用一个比较小的队列长度,在信息的交互的同时不会因为在流量突增之后导致的丢包而干扰TCP/IP流量。
取决于配置的ECN,标记有可能意味着丢弃或仅仅表示该报文是超限的报文。
6.5.2. Algorithm
平均队列大小用于确定标记的概率,该概率是使用指数加权平均算法计算出来的,通过该值可以调节对流量突发的敏感度。当平均队列大小低于最小字节时,此时不会标记任何报文;当超过最小字节时,概率会直线上升到probability(参数指定),直到平均队列大小达到最大字节数。因为通常不会将概率设置为100%,而队列大小也可能会超过最大字节,因此,limit参数用于硬性设置队列大小的最大值。
大致工作方式为:
- 低于min:此时不做任何处理,队列压力较小,可以直接正常处理。
- 在min和max之间:此时界定为队列感受到阻塞压力,开始按照某一几率P从队列中丢包,几率计算公式为:P = probability * (平均队列长度 - min)/(max - min)。
- 高于max:此时新入队的请求也将丢弃。
6.5.3. 用法
$ tc qdisc ... red limit bytes [min bytes] [max bytes] avpkt bytes [burst packets] [ecn] [harddrop] [bandwidth rate] [probability chance] [adaptive]
6.5.4. 参数
- min: 可能进行标记的平均队列大小。默认为 max/3.
- max: 当平均队列大小达到该值后,标记的概率值是最大的。为了避免同步重传,应该至少是min的两倍,且大于最小的min值,默认为limit/4。
- probability: 标记的概率的最大值,为0.0到1.0之间的浮点数,建议值为0.01或0.02(分别表示1%或2%),默认为0.02。
- limit: 真实(非平均)队列的硬性限制,单位为字节。应该大于max+burst的值。建议将这个值设置为最大值的几倍。
- burst: 用于决定平均队列大小受真实队列大小影响的速度。更大的值会延缓计算的速度,从而允许在标记开始之前出现更长的流量突发。实际经验遵循如下准则: (min+min+max)/(3*avpkt)。
- Avpkt: 单位是字节,与burst一起确定平均队列长度的时间常数。建议值1000。
- bandwidth: 该速率用于在一段空闲时间之后计算平均队列的大小,设置为接口的带宽。并不意味着RED会进行整流。可选,默认值为10Mbit。
- ecn: 如上所述,RED可以执行"标记"或"丢弃",显式拥塞通知允许RED通知远程主机它们的速率超过了可用带宽。不支持ECN的主机仅会通知报文丢弃。如果指定了该参数,支持ECN的主机上的报文只会被标记而不会被丢弃(除非队列达到limit的字节数),推荐使用。
- harddrop: 如果平均流大小大于max字节数,该参数会强制丢弃报文,而不是进行ECN标记。
- adaptive: (linux-3.3新加的功能 ) 在自适应模式中设置RED,参见 http://icir.org/floyd/papers/adaptiveRed.pdf,自适应的RED的目的是在1%和50%之间动态设置
probability,以达到目标平均队列:(max-min)/2。
6.5.5. 例子
# tc qdisc add dev eth0 parent 1:1 handle 10: red limit 400000 min 30000 max 90000 avpkt 1000 burst 55 ecn adaptive bandwidth 10Mbit
6.6. GRED, Generic Random Early Drop
GRED用在DiffServ 实现中,且在物理队列中包含虚拟队列(VQ)。当前,虚拟队列的数值限制为16。
GRED分两步配置:首先是通用的参数,用于选择虚拟队列DPs的数目,以及是否打开类RIO的缓冲区共享方案。此时会选择一个默认的虚拟队列。
其次为单独的虚拟队列设置参数。
6.6.1. 用法
... gred DP drop-probability limit BYTES min BYTES max BYTES avpkt BYTES burst PACKETS probability PROBABILITY bandwidth KBPS [prio value]
OR
... gred setup DPs "num of DPs" default "default DP" [grio]
6.6.2. 参数
- setup: 表示这是一个GRED的通用设置
- DPs: 虚拟队列的数目
- default: 指定默认的虚拟队列
- grio: 启用类RIO的缓冲方案
- limit: 定义虚拟队列的"物理"限制,单位字节
- min: 定义最小的阈值,单位字节
- max: 定义最大的阈值,单位字节
- avpkt: 平均报文大小,单位字节
- bandwidth: 接口的线路速度
- burst: 允许突发的平均大小的报文数目
- probability: 定义丢弃的概率范围 (0…);
- DP: 标识分配给这些参数的虚拟队列;
- prio: 如果在通用参数中设置了grio,则表示虚拟队列的优先级
6.7. TBF,令牌桶过滤器
该qdisc构建在令牌和桶上。它会对接口上传输的流量进行整形(支持整流)。为了限制特定接口上出队列的报文的速度,TBF qdisc是个不错的选择。它仅会将传输的流量下降到特定的速率。
只有在包含足够的令牌时才能传输报文。否则,会推迟报文的发送。以这种方式延迟的报文将报文的往返时间中引入人为的延迟。
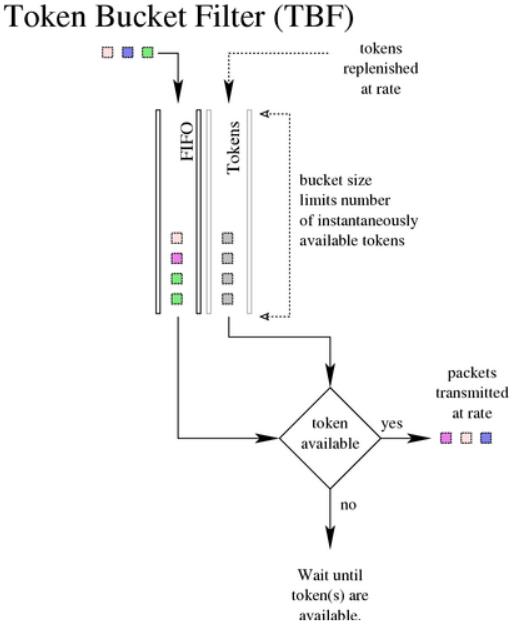
6.7.1. 算法
如其名称所示,对流量的过滤会基于消耗的令牌。令牌会大致对应到字节数,每个报文会消耗一个令牌,无论该报文有多小。这样会导致零字节的报文占用一定的链路时间。在创建时,TBF会保存一定的令牌,以应对一次性流量突发的量。令牌会以稳定的速率放到桶中,直到桶满为止。如果没有可用的令牌,则报文会保留在队列中(队列中的报文不能超过配置的上限)。TBF会计算令牌的亏空,并进行节流,直到可以发送队列中的第一个报文。如果不能接收最大速度的报文突发,可以配置峰值速率来限制桶清空的速度。峰值速率使用第二个TBF来实现,其桶相对较小,因此不会发生突发。
6.7.2. 参数
-
limit or latency: limit表示可以在队列中等待令牌的字节数。还可以通过设置延迟参数的方式变相地设置此值,延迟参数指定了报文可以在TBF中停留的最大时间。后者的计算会使用到桶的大小,速率和峰值速率(如果设置) 。这两个参数是互斥的。
-
Burst: 即突发或最大突发。等于桶的大小,单位是字节。这是令牌在一瞬间可用的最大字节数。通常大的整流速率需要大的缓冲。如对于Intel上的10mbit/s,则至少需要10kbyte的缓冲才能跟上配置的速率。如果缓存过小,可能导致报文丢失,此时每个时间点到达的报文要大于桶的可用容量。最小的缓冲大小可以用频率除以HZ计算出来。
对令牌使用的计算是通过一个表来计算的,该表默认情况下有8个报文的分辨率。可以通过指定突发的单元大小来更改此分辨率。例如,为了指定一个6000字节的缓冲,其单元大小为16字节,需要将突发设置为6000/16。单元大小必须是2的整数次幂。
-
Mpu: 零大小的报文不会使用零带宽。对于以太网来说,报文的大小不能小于64字节。最小的报文单元(MTU)决定了一个报文使用的最小令牌(单位字节),默认是0。
-
Rate: 速度旋钮。此外,如果需要峰值速率,可以使用以下参数:
-
peakrate: 桶的最大消耗速率。只有在需要毫秒级别的整流时才会用到峰值速率。
-
mtu/minburst: 指定了峰值速率的桶大小。为了精确计算,应该将其设置为MTU的大小。如果用了峰值速率,但有些突发又是可以接受的,则可以增加该值的大小。一个3000字节的minburst可以允许3mbit/s的峰值速率,支持1000字节的报文。与常规的突发大小一样,也可以指定单元大小。
6.7.3. 例子
例10. 创建一个 256kbit/s 的TBF
[root@leander]# cat tbf.tcc
/*
* make a 256kbit/s TBF on eth0
*
*/
dev eth0 {
egress {
tbf( rate 256 kbps, burst 20 kB, limit 20 kB, mtu 1514 B );
}
}
[root@leander]# tcc < tbf.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 tbf burst 20480 limit 20480 mtu 1514 rate 32000bps
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/13993695.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号