
流量控制--4.软件和工具
软件和工具
5.1 内核要求
许多发行版都为内核提供了模块化或整体式的流量控制(QOS)。自定义的内核可能不会支持这些特性。
对内核编译不了解或经验不多的用户建议阅读Kernel-HOWTO。对于熟练的内核编译者在了解流量控制之后就可以确定需要开启如下哪些选项。
例1.内核的编译选项
#
# QoS and/or fair queueing
#
CONFIG_NET_SCHED=y
CONFIG_NET_SCH_CBQ=m
CONFIG_NET_SCH_HTB=m
CONFIG_NET_SCH_CSZ=m
CONFIG_NET_SCH_PRIO=m
CONFIG_NET_SCH_RED=m
CONFIG_NET_SCH_SFQ=m
CONFIG_NET_SCH_TEQL=m
CONFIG_NET_SCH_TBF=m
CONFIG_NET_SCH_GRED=m
CONFIG_NET_SCH_DSMARK=m
CONFIG_NET_SCH_INGRESS=m
CONFIG_NET_QOS=y
CONFIG_NET_ESTIMATOR=y
CONFIG_NET_CLS=y
CONFIG_NET_CLS_TCINDEX=m
CONFIG_NET_CLS_ROUTE4=m
CONFIG_NET_CLS_ROUTE=y
CONFIG_NET_CLS_FW=m
CONFIG_NET_CLS_U32=m
CONFIG_NET_CLS_RSVP=m
CONFIG_NET_CLS_RSVP6=m
CONFIG_NET_CLS_POLICE=y
使用如上选项编译的内核可以为本文讨论的所有场景提供模块化支持。用户在使用一个给定的特性前可能需要执行modprobe *module*。
5.2 iproute2工具(tc)
iproute2是一个命令行套件,可以用于管理一台机器上与IP网络配置有关的内核结构。如果要查看这些工具技术文档,可以参阅iproute2 文档,如果要了解更具探讨性的内容,请参阅linux-ip.net上的文档。在iproute2工具包中,二进制的tc是唯一用于流量控制的工具。本文档将忽略其他工具。
由于tc需要与内核交互来创建,删除和修改流量控制结构,因此在编译tc时需要支持所有期望的qdisc。实际上,在iproute2上游包中还不支持HTB qdisc。更多信息参见Section 7.1, “HTB, Hierarchical Token Bucket” 。
tc工具会执行支持流量控制所需要的所有内核结构配置。由于它的用法多种多样,其命令语法也是晦涩难懂的。该工具将三个Linux流量控制组件(qdisc、class或filter)中的一个作为其第一个必选参数。
例2.tc命令的用法
[root@leander]# tc
Usage: tc [ OPTIONS ] OBJECT { COMMAND | help }
where OBJECT := { qdisc | class | filter }
OPTIONS := { -s[tatistics] | -d[etails] | -r[aw] }
每个对象都可以接收其他不同的选项,本文后续将会进行完整的描述。下例展示了tc命令行语法的多种用法。更多用法可以参见 LARTC HOWTO。如果要更好地了解tc,可以参阅内核和iproute2源码。
例3.tc qdisc
[root@leander]# tc qdisc add \ <1>
> dev eth0 \ <2>
> root \ <3>
> handle 1:0 \ <4>
> htb <5>
- 添加一个队列规则,动作也可以为
del - 指定附加新队列规则的设备
- 表示"ergess",此处必须使用
root。另外一个qdisc的功能是受限的,ingress qdisc可以附加到相同的设备上 - handle是一个使用
major:minor格式指定的用户自定义号。当使用队列规则句柄时,次号必须为0。qdisc句柄可以简写为"1:"(等同于"1:0"),如果没有指定,则次号默认为0 - 附加的队列规则,上例为HTB。队列规则指定的参数将会跟在后面。上例中没有指定任何参数
上述展示了使用tc工具将一个队列规则添加到一个设备的用法。下面是使用tc给现有的父类添加类的用法:
例4.tc 类
[root@leander]# tc class add \ <1>
> dev eth0 \ <2>
> parent 1:1 \ <3>
> classid 1:6 \ <4>
> htb \ <5>
> rate 256kbit \ <6>
> ceil 512kbit <7>
- 添加一个类,动作也可以为
del - 指定附加的新类的设备
- 指定附加的新类的父句柄
- 表示类的唯一句柄(主:次)。次号必须为非0值
- 这两个classful qdiscs都要求任何子类使用与父类相同类型的类。此时一个HTB qdisc将包含一个HTB类
-
- 这是一个类指定的参数,更多参见Section 7.1, “HTB, Hierarchical Token Bucket”
例5. tc过滤器
[root@leander]# tc filter add \ <1>
> dev eth0 \ <2>
> parent 1:0 \ <3>
> protocol ip \ <4>
> prio 5 \ <5>
> u32 \ <6>
> match ip port 22 0xffff \ <7>
> match ip tos 0x10 0xff \ <8>
> flowid 1:6 \ <9>
> police \ <10>
> rate 32000bps \ <11>
> burst 10240 \ <12>
> mpu 0 \ <13>
> action drop/continue <14>
-
添加一个过滤器,动作也可以为
del -
指定附加的新过滤器的设备
-
指定附加的新过滤器的父句柄
-
该参数是必须的
-
prio参数允许给定的过滤器优先于另一个过滤器 -
这是一个分类器,是每个tc过滤器命令中必需的部分。
-
- 这些是分类器的参数。这种情况将选择具有tos类型(用于交互使用)和匹配端口22的数据包。
-
flowid指定了目标类(或qdisc)的句柄,匹配的过滤器应该将选定的数据包发送到该类。 -
这是一个策略器,这是每个tc过滤器命令可选的部分
-
策略器会在速率达到某一个值后执行一个动作,并在速率低于某一值时执行另一个动作
-
突发与HTB中的突发类似(突发是桶的概念)。
-
最小的策略单元,为了计算所有的流量,使用的
mpu为0 -
action表示当
rate与策略器的属性匹配时将会执行那些操作。第一个字段指定了当超过策略器后的动作,第二个字段指定了其他情况下的动作
如上所示,即使对于上述简单的例子来说,tc命令行工具的语法也是晦涩难懂的,如果说存在一种更简单的方法来配置Linux流量控制,对于读者来说,应该不会感到惊讶。参见下一节Section 5.3, “tcng, Traffic Control Next Generation”。
5.3 tcng下一代流量控制
参见 Traffic Control using tcng and HTB HOWTO 以及 tcng 文档。
下一代流量控制(tcng)为Linux提供了所有流量控制的能力。
5.4 Netfilter
Netfilter 是Linux内核提供的一个框架,允许使用自定义的格式来实现各种与网络有关的操作。Netfilter 为报文过滤、网络地址转换、端口转换等提供了多种功能和操作,这些功能包括在网络中重定向报文所需的功能,以及提供禁止报文到达计算机网络中的敏感位置的功能。
Netfilter 为一组Linux内核钩子,允许特定的内核模块将回调函数注册到内核的网络栈上。这些函数通常会用于流量的过滤和规则的修改,当报文经过网络栈的各个钩子时都会调用这些函数。
5.4.1 iptables
iptables是一个用户空间的应用程序,允许系统管理员配置由Linux内核防火墙(由不同的Netfilter 实现)提供的表以及其保存的链和规则。不同的内核模块和程序目前用于不同的协议,iptables用于IPv4,ip6tables用于IPv6,arptables用于ARP,ebtables用于以太帧。
iptables需要提升到特权才能运行,并且必须由root用户执行,否则无法运行。在大多数Linux系统上,iptables安装在/usr/sbin/iptables 下,且有对应的man文档。此外iptables安装还可能安装在/sbin/iptables下,但相比于一个基本的二进制可执行文件,iptables更像一个服务,因此最好将其保留在/usr/sbin下面。
术语iptables也通常用于指内核级的组件。x_tables是内核模块的名称,其中包含四个模块所使用的共享代码部分,这些模块还提供了用于扩展的API。后来,Xtables或多或少被用来指整个防火墙(v4、v6、arp和eb)体系结构。
Xtables 允许系统管理员定义包含处理报文的规则的表。每个表都与一个不同类型的报文处理相关联。报文会按照顺序通过链中的规则来处理。链中的一个规则可能会跳转到另外一个链,通过这种方式可以做到任意级别的嵌套。每个到达或离开计算机的报文都会经过至少一个链。

报文的源可以决定该报文首先进入哪个链。iptables中预定义了五个链(对应五个Netfilter 钩子),但不是每个表都包含所有的链。
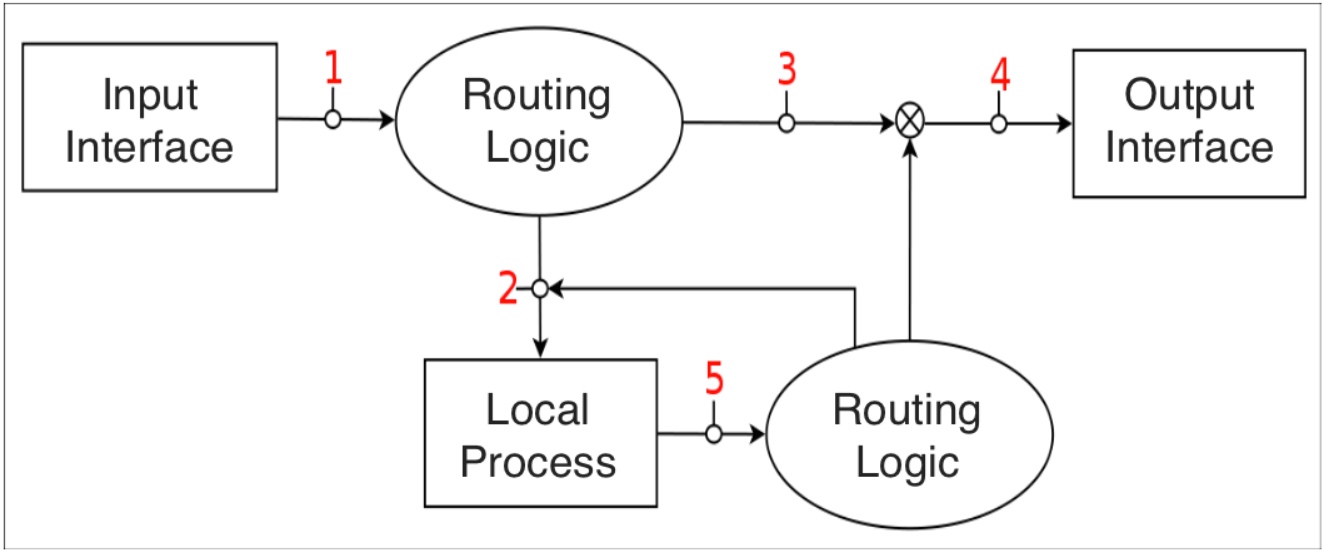
预定义的链都有一个策略,如DROP,即当报文到达链尾时会执行丢弃动作。系统管理员可以按照需要创建任意多的链,新创建的链并没有任何策略,当报文到达链尾时,会返回到调用该链的位置。一个链也可能是空的。
PREROUTING:报文在进行路由处理前会进入该链。INPUT:报文会上送到本地,它与本地打开的socket没有任何关系。本地上送的逻辑由"本地上送"路由表控制。可以使用ip route show table local命令查看FORWARD:所有已经路由到非本地的报文将会经过该链OUTPUT:本机发送的报文会经过该链POSTROUTING:在完成路由决策后,报文传递给硬件之前进入这个链
链中的每个规则都包含报文匹配的规范,还有可能包含目标(target ,用于扩展)或判定(verdict ,内置决策之一)。当一个报文进入一条链后,会按照顺序逐一检查链中的每条规则,如果这条规则不匹配,则检查下一条规则。如果一个规则匹配报文,那么就会按照规则中的目标/判定指定的动作来处理该报文,执行的结果可能会允许或拒绝继续在链中处理报文。由于匹配包含了报文检测的条件,因此其占了规则集的绝大部分。这些匹配场景可能发生在OSI模型的任何层,例如——mac-source和-p tcp——dport参数,此外也可以包含独立于协议的匹配规则,如-m时间。
报文会继续在链中处理,直到发生下面任意一种情况:
- 匹配到一条规则(且该规则决定了报文的最终命运,如调用了
ACCEPT或DROP),或使用了一个决定报文最终命运的模块。 - 规则调用了
RETURN,导致处理返回到调用链 - 到达链尾,后续会在父链中继续处理(如果使用了RETURN),或基于链策略处理。
目标也会返回类似ACCEPT(NAT模块会这么做)或DROP(如REJECT模块)的判定,但也可能会暗示CONTINUE(如LOG模块;CONTINUE是一个内部名称)来继续处理下一个规则(如果没有指定任何目标/判定)。
5.5 IMQ,中间队列设备
中间队列设备并不是qdisc,但它的用法与qdiscs紧密相关。在Linux中,qdisc会附加到网络设备上,任何要进入设备的报文,首先会进入qdisc,然后才会进入驱动队列。从这个观点看,会有两个限制:
- 只能做egress整流(虽然存在ingress qdisc,但相对于classful qdisc来说,其功能非常有限)
- 一个qdisc只能看到一个接口的流量,无法做全局限制
IMQ用于解决这两大限制。简单地说,可以将任意选定的内容放到一个qdisc中。特殊标记的报文会在netfilter NF_IP_PRE_ROUTING 和NF_IP_POST_ROUTING 钩子中被拦截,并通过附加的qdisc传递给imq设备。iptables目标可以用于标记报文。
这种方式允许对ingress流量进行整流,只要标记来自某处的报文,并/或将接口当作类来设置全局的限制。此外做很多其他的事情,比如把http流量放到qdisc中,把新的连接请求放到qdisc中等。
5.5.1 配置示例
下面使用ingress整流来授权一个高带宽。对其他接口的配置类似:
tc qdisc add dev imq0 root handle 1: htb default 20
tc class add dev imq0 parent 1: classid 1:1 htb rate 2mbit burst 15k
tc class add dev imq0 parent 1:1 classid 1:10 htb rate 1mbit
tc class add dev imq0 parent 1:1 classid 1:20 htb rate 1mbit
tc qdisc add dev imq0 parent 1:10 handle 10: pfifo
tc qdisc add dev imq0 parent 1:20 handle 20: sfq
tc filter add dev imq0 parent 10:0 protocol ip prio 1 u32 match \ ip dst 10.0.0.230/32 flowid 1:10
本例使用u32来分类。此外还可以使用其他分类器,后续的流量将会被选择并打上标记,最后入队列到imq0。
iptables -t mangle -A PREROUTING -i eth0 -j IMQ --todev 0
ip link set imq0 up
在iptables的mangle表的PREROUTING 和POSTROUTING 链中可以配置IMQ目标。语法为:
IMQ [ --todev n ] n : number of imq device
也支持ip6tables目标。
注意,流量不是在目标被匹配时进入队列,而是在匹配之后。当流量进入imq设备之后的具体位置取决于流量的方向(进/出)。这些位置由iptables预定义的netfilter 钩子决定。
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_LAST = INT_MAX,
};
对于ingress流量,imq会使用NF_IP_PRI_MANGLE + 1 的优先级,意味着在处理完PREROUTING 链之后,报文会直接进入imq设备。
对于使用NF_IP_PRI_LAST 的egress流量,意味着,被过滤表丢弃的报文将不会占用带宽。
5.6 ethtool,驱动队列
ethtool 命令用于控制以太接口的驱动队列大小。ethtool 也提供了底层接口的信息以及启用/禁用IP栈和驱动特性的能力。
ethtool 的-g标志可以展示驱动队列(ring)的参数:
$ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 16384
RX Mini: 0
RX Jumbo: 0
TX: 16384
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 256
可以看到该NIC的驱动的输出队列为256个描述符。为了减少延迟,通常建议降低驱动队列的大小。在引入BQL(假设NIC驱动支持)之后,就不需要修改驱动队列了。
ethtool还可以管理如 TSO, UFO 和GSO这样的优化特性。-k表示展示了当前设置的卸载,可以使用-K进行修改。
$ethtool -k eth0
Offload parameters for eth0:
rx-checksumming: off
tx-checksumming: off
scatter-gather: off
tcp-segmentation-offload: off
udp-fragmentation-offload: off
generic-segmentation-offload: off
generic-receive-offload: on
large-receive-offload: off
rx-vlan-offload: off
tx-vlan-offload: off
ntuple-filters: off
receive-hashing: off
由于TSO, GSO, UFO和GRO通常会增加驱动队列中的报文字节数,如果需要优化延迟(而非吞吐量),建议关闭这些特性。除非系统正在处理非常高速率的数据,否则禁用这些特性时,可能不会注意到任何CPU影响或吞吐量下降。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/13983515.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号