
linux线程调度策略
linux线程调度策略
这是一篇非常好的关于线程调度的资料,翻译自shed
从Linux 2.6.23开始,默认的调度器为CFS,即"完全公平调度器"(Completely Fair Scheduler)。CFS调度器取代了之前的"O(1)"调度器。
CFS的实现细节可以参见sched-design-CFS。cgroup的CPU调度也属于CFS扩展的一部分。
Scheduling policies
内核模块使用调度器来决定下一个CPU时钟周期执行的线程。每个线程都包含一个调度策略以及一个静态的调度优先级sched_priority,调度器根据系统上所有线程的调度策略和静态优先级来决定如何进行调度。
对于使用普通调度策略(SCHED_OTHER, SCHED_IDLE, SCHED_BATCH)的线程来说,sched_priority并不会影响调度结果,且必须设置为0。
对于使用实时策略(SCHED_FIFO,SCHED_RR)的进程,其sched_priority取值为1到99(1为最低值)。实时线程的调度优先级总是高于普通线程。注:POSIX.1的系统在实现中,会要求实时调度策略有32个优先级设置,因此,为了可移植性,可以使用sched_get_priority_min和sched_get_priority_max来查找调度策略所支持的优先级范围。
调度器会为每个sched_priority值维护一个可运行的线程列表。调度器通过查看非空且静态优先级最高的列表,并选择该列表首部的元素作为下一个运行的线程。
线程的调度策略决定了如何根据静态优先级来将一个线程插入到同静态优先级的线程列表(list of runnable threads)中,以及如何在该列表中调整线程的位置。
所有的调度都具有抢占性:如果一个具有更高静态优先级的线程准备运行,当前运行的线程会被抢占并返回到其静态优先级对应的等待列表中。调度策略仅根据具有相同静态优先级的可运行线程列表来决定调度顺序。
进程调度中使用了2个队列:进程一开始会进入ready队列等待调度;当进程执行中遇到I/O阻塞,等待子进程结束或软中断等原因会进入wait队列,等阻塞结束后会返回到ready队列
SCHED_FIFO: First in-first out scheduling(实时线程)
SCHED_FIFO仅适用于静态优先级大于0的线程,即当一个SCHED_FIFO的线程变为可运行(runnable)状态时,它会立即抢占所有当前运行的SCHED_OTHER, SCHED_BATCH或SCHED_IDLE 线程。SCHED_FIFO不使用时间片进行调度,所有使用SCHED_FIFO调度策略的线程应该遵守如下规则:
-
当一个运行中的
SCHED_FIFO线程被其他有更高优先级的线程抢占后,该线程会返回到其优先级对应的列表的首部,当所有更高优先级的线程阻塞后,该线程将会立即恢复运行; -
当一个阻塞的
SCHED_FIFO线程变为可运行状态时,该线程会返回到其优先级对应的列表末尾; -
如果调用 sched_setscheduler(2),sched_setparam(2),sched_setattr(2),pthread_setschedparam(3),pthread_setschedprio(3) (通过pid)修改了正在运行或可运行状态的
SCHED_FIFO线程的优先级时,该线程在列表中的位置取决于优先级的变动:-
如果线程优先级增加了,它将会放置到新优先级对应的列表末尾,同时可能抢占正在运行的具有相同优先级的线程;
-
如果线程优先级没变,其在运行列表中的位置不变;
-
如果线程优先级减小了,它将会放置到新优先级对应的列表的前面。
根据POSIX.1-2008,通过非 pthread_setschedprio(3)方式来修改线程的优先级,可能会导致其放置到对应优先级列表的末尾。
-
-
调用了sched_yield(2) (用于释放CPU)的线程将会放置到列表末尾
SCHED_FIFO 线程将会一直运行,直到被更高优先级的线程抢占,或调用了sched_yield(2) 。
SCHED_RR: Round-robin scheduling(轮询调度)
SCHED_RR对SCHED_FIFO做了简单增强。除每个线程仅允许运行在一个最大时间段下外,SCHED_FIFO中的所有规则都适用于SCHED_RR。如果一个SCHED_RR线程已经运行了等于或大于该最大时间段时,该线程会被放置到其优先级列表的末尾。当一个SCHED_RR线程被更高优先级的线程抢占,并在后续恢复运行后,会在先前未过期的时间段下运行。最大时间段可以通过sched_rr_get_interval(2)获得。
SCHED_DEADLINE: Sporadic task model deadline scheduling
3.14版本之后的Linux提供了一个新的调度策略SCHED_DEADLINE。该策略结合了GEDF(Global Earliest Deadline First)和 CBS (Constant Bandwidth Server)。必须通sched_setattr(2)和sched_getattr(2)来设置和获取该策略。
一个Sporadic task被定义为一系列任务,且每个任务每次仅激活一次。每个任务都有一个relative deadline(该任务应该在该相对时间前停止运行),以及一个computation time(执行该任务需要的CPU时间,对应下图的comp. time)。一个新的任务开始执行时会唤醒(wakeup)一个Sporadic task,该时间点被称为arrival time,start time为一个任务开始执行的时间,absolute deadline(绝对截止时间)为arrival time加上relative deadline的时间点。
arrival/wakeup absolute deadline
| start time |
| | |
v v v
-----x--------xooooooooooooooooo--------x--------x---
|<- comp. time ->|
|<------- relative deadline ------>|
|<-------------- period ------------------->|
当使用sched_setattr(2)给一个线程设置SCHED_DEADLINE 策略时,可以设置3个参数:Runtime, Dead‐line和Period,对于上面提到的场景来说,通常的做法是将Runtime设置为大于平均计算时间的值(或更坏的场景下,设置为硬实时任务的执行时间);将Deadline设置为对应的dead-line,将Period设置为任务的周期,此时对于SCHED_DEADLINE的调度如下:
Runtime对应上图中的comp.time,Dead-line对应上图的relative deadline
arrival/wakeup absolute deadline
| start time |
| | |
v v v
-----x--------xooooooooooooooooo--------x--------x---
|<-- Runtime ------->|
|<----------- Deadline ----------->|
|<-------------- Period ------------------->|
3个deadline调度参数对应sched_attr结构体中的sched_run‐time, sched_deadline, 和sched_period字段,参见sched_setattr(2)。这些字段的单位为纳秒。如果sched_period的值为0,则它与sched_deadline相同。
内核要求:
sched_runtime <= sched_deadline <= sched_period
此外,在当前实现中,所有参数的值至少为1024(即,大于1微秒),小于2^63。如果有效性校验失败,sched_setattr(2)返回EINVAL错误。
CBS通过阻止线程超出其运行时间Runtime来保证任务间不互相干扰。
为了确保deadline调度,当SCHED_DEADLINE线程在给定的条件下不可运行时,此时内核必须阻止这些线程的运行。内核必须在设置或修改SCHED_DEADLINE策略和属性时执行准入测试。准入测试用于计算这些修改是否可行,如果不可行,sched_setattr(2)将返回EBUSY错误。
例如,总的CPU利用率应该小于或等于总的可用的CPU。由于每个线程可以在每个Period中最大运行Runtime时间,线程的CPU时间片使用率为Runtime除以Period。
为了满足SCHED_DEADLINE的条件,使用SCHED_DEADLINE策略的线程的优先级是系统中最高的。当一个SCHED_DEADLINE线程运行时,该线程会抢占其他策略下调度的线程。
对SCHED_DEADLINE策略调度的线程调用fork(2)会返回EAGAIN错误(除非该线程设置了reset-on-fork标记)。
当一个SCHED_DEADLINE线程调用了sched_yield(2)将会停止当前任务,并等待新的周期。
SCHED_OTHER: Default Linux time-sharing scheduling(默认策略)
SCHED_OTHER只能在静态优先级为0时使用(普通线程)。SCHED_OTHER是标准的Linux分时调度策略(不需要实时机制)。
如何从静态优先级为0的列表中选择运行的线程取决于列表中的dynamic优先级。dynamic优先级基于nice值,且在每次线程准备运行时增加。这种机制保证公平处理所有的SCHED_OTHER线程。
在Linux内核源码中,SCHED_OTHER被称为SCHED_NORMAL。
The nice value
nice值用于影响CPU调度器对进程的调度偏好。适用于SCHED_OTHER和SCHED_BATCH调度处理。可以通过nice(2),setpriority(2)或sched_setattr(2)修改nice值。
根据POSIX.1,nice值是一个单进程属性,即进程中的所有线程共享一个nice值。然而,在Linux中,nice值是一个单线程属性,相同进程中的不同线程可能使用不同的nice值。
nice值的取值范围根据UNIX系统的不同而不同。在现代Linux系统中,取值为-20(高优先级)到+19(低优先级),而一些系统中的取值为-20..20。在一些非常早期的Linux 内核(Linux 2.0之前)中的取值为-infinity..15。
nice值对相应的SCHED_OTHER 进程的影响根据UNIX系统和Linux内核版本的不同而不同。
2.6.23版本的Linux内核中引入了CFS调度,并采用了一种能根据nice的差值产生更显著影响的算法。在当前的实现下,两个进程的nice差值中,每单位的nice差值对CFS调度的影响因子为1.25 (参见how-is-nice-working,CFS根据vruntime进行CPU调度:vruntime = 实际运行时间 * 1024 / 进程权重,进程权重为1.25 ^ nice_value)。这种算法使得在有高优先级负载运行的情况下,只能给低nice值(+19)的负载提供很小的CPU;而为高nice值(-20)的负载提供其运行应用需要的绝大部分CPU(如音频应用)。
权重表示是该程序需要的cpu时间的一种表现,如果一个程序需要大量cpu进行处理,可以提高其权重,反之减小其权重。CFS的思想就是让每个调度实体的vruntime互相追赶,而每个线程的vruntime增加速度不同,权重越大的增加的越慢,这样就能获得更多的cpu执行时间。系统将会根据每个线程的vruntime排序(实际上是基于红黑树算法),vruntime最小的线程会最早获得调度。而一旦vruntime的次序发生变化(vruntime的大小与实际运行时间有关,运行时间越长,其值越大),系统将尝试触发下一次调度。也就是说调度器尽可能的保证所有线程的vruntime都一致,权重高的线程vruntime提升的慢(进程权重小,即分子小),容易被优先调度;权重低,同样的时间上vruntime上升的快,反而容易被轮空。一个线程的vruntime可以通过
/proc/<PID>/sched中的se.vruntime选项查看:grep vruntime /proc/<PID>/sched。vruntime的增加与进程占用的CPU有关,如果一个线程一直处于sleep状态,其vruntime是不会增加的。那么如果一个sleep的线程被唤醒之后,是否会立即抢占vruntime比它大的线程?答案是否定的,其最少需要在cpu的run队列中等待sched_min_granularity_ns的时间,sched_min_granularity_ns的计算方式如下:If number of runnable tasks does not exceed sched_latency_ns/sched_min_granularity_ns scheduler period = sched_latency_ns else scheduler period = number_of_running_tasks * sched_min_granularity_ns可以使用
top命令查看系统上的nice值和优先级。如下PR表示优先级,NI表示nice值,前者为内核角度看的进程的实际优先级,后者为用户空间看到的进程的nice值。两者的关系为:PR = 20 + NIPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1145 root 20 0 602236 60888 25096 S 0.7 1.2 0:09.70 containerd 61 root 20 0 0 0 0 I 0.3 0.0 0:02.91 kworker/1:1-eve 1 root 20 0 193736 8288 5644 S 0.0 0.2 0:01.15 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd 3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp 5 root 20 0 0 0 0 I 0.0 0.0 0:00.23 kworker/0:0-ata 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-ev 7 root 20 0 0 0 0 I 0.0 0.0 0:00.17 kworker/u256:0- 8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq 9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0 10 root 20 0 0 0 0 I 0.0 0.0 0:00.42 rcu_sched 11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 ...
Linux系统可以使用RLIMIT_NICE资源来限制非特权进程的nice值的上限,参见setrlimit(2)。
更多nice值的用法,参见下面的autogroup。
SCHED_BATCH: Scheduling batch processes
从Linux 2.6.16开始,SCHED_BATCH可以用于静态优先级为0的线程。该策略类似SCHED_OTHER,并根据动态优先级(nice值)进行调度。区别是使用该策略时,调度器会假设线程是CPU密集型的,因此,该调度器会根据线程的唤醒行为施加调度惩罚,因此这种调度策略比较不受欢迎。
该策略比较适用于非交互且不期望降低nice值的负载,以及需要不因为交互而(在负载之间)造成额外抢占的调度策略的负载。下面引用自PHP-FPM on Linux, SCHED_BATCH or SCHED_OTHER?,更多参见[batch/idle priority scheduling, SCHED_BATCH](batch/idle priority scheduling, SCHED_BATCH)
SCHED_BATCH was clearly designed for very long running (hours or even days) compute-intensive jobs. Your jobs are only compute-intensive for seconds or fractions of seconds.
This pretty much makes it a no-go for a web server. And it would be worse if the database is on the same machine, as they might contend for one of those extra-long timeslices.
SCHED_IDLE: Scheduling very low priority jobs
从Linux 2.6.23开始,SCHED_IDLE可以用于静态优先级为0的线程。nice值不会影响该策略。
该策略用于运行非常低优先级的任务(低于nice值为+19的SCHED_OTHER或SCHED_BATCH策略)。
Resetting scheduling policy for child processes
每个线程都有一个reset-on-fork调度标识。当设置该标识后,使用fork(2)创建的子进程不会继承特权调度策略。可以通过如下方式设置reset-on-fork:
- 在调用sched_setscheduler(2)时,将SCHED_RESET_ON_FORK 标识作为
policy参数,或 - 在调用sched_setattr(2)时,将SCHED_FLAG_RESET_ON_FORK 设置为
attr.sched_flags
注意上面两个函数的常量名称不一样。使用sched_getscheduler(2)和sched_getattr(2)获取reset-on-fork状态的用法与上面类似。
reset-on-fork特性用于媒体播放的应用,可以防止应用在创建多个子进程时规避RLIMIT_RTTIME设置的资源限制。
更精确地讲,如果设置了reset-on-fork,后续创建地子进程会遵循下面规则:
- 如果正在运行的线程使用了
SCHED_FIFO或SCHED_RR调度策略,子进程地策略或被设置为SCHED_OTHER; - 如果正在运行的进程的nice值为负值,子进程的nice值会被设置为0。
在设置reset-on-fork之后,只有线程拥有CAP_SYS_NICE的capability时才能重置reset-on-fork。使用fork(2)创建的子进程会disable reset-on-fork标识。
Privileges and resource limits
在Linux 2.6.12之前,只有拥有特权(CAP_SYS_NICE)的线程才能设置非0的静态优先级(即设置实时调度策略)。后续版本对如下实现进行了修改:非特权的线程仅在调用者的effective user ID(EID)与目标线程的real或effective user ID相同的情况下才能且仅能设置SCHED_OTHER策略。
为了设置或修改SCHED_DEADLINE策略。线程必须是特权(CAP_SYS_NICE)的。
从Linux 2.6.12开始,RLIMIT_RTPRIO(可以使用ulimit -e设置)资源限制定义了非特权线程设置SCHED_RR 和SCHED_FIFIO策略的静态优先级的上限。修改调度策略和优先级的规则如下:
- 如果非特权线程有一个非0的RLIMIT_RTPRIO 软限制(soft limit),则该线程对调度策略和优先级的修改限制为:优先级的不能高于当前优先级且不能高于RLIMIT_RTPRIO。
- 如果RLIMIT_RTPRIO 为0,则仅允许降低优先级,或切换到非实时策略。
- 遵从上述规则的前提下,只要执行修改的线程的effective user ID等于目标线程的effective user ID就可以执行相应的修改。
- SCHED_IDLE策略有特殊的约束。在Linux 2.6.39之前,在该策略下创建的非特权线程无法修改该策略(与RLIMIT_RTPRIO 资源限制无关)。从Linux 2.6.39开始,只要nice值在RLIMIT_RTPRIO 资源限制所允许的范围内,非特权线程可以切换到SCHED_BATCH或SCHED_OTHER策略。
特权(CAP_SYS_NICE)线程会忽略RLIMIT_RTPRIO限制。在一些老的内核中,特权线程可以任意修改策略和优先级。参见 getrlimit(2)获取更多信息。
Limiting the CPU usage of real-time and deadline processes(限制实时进程或deadline进程)
SCHED_FIFO, SCHED_RR或SCHED_DEADLINE策略下调度的线程中的非阻塞无限循环处理可能会阻塞其他线程获取CPU。在Linux 2.6.25之前,阻止实时进程冻结系统的唯一方式是通过shell启动一个静态优先级更高的程序,如通过这种方式来停止实施程序,并释放CPU资源。
从Linux 2.6.25开始,引进了其他技术手段来处理实时(SCHED_FIFO,SCHED_RR)和deadline(SCHED_DEADLINE)进程。一种方式是通过RLIMIT_RTTIME 来限制实时进程可能使用到的CPU的上限。参见 getrlimit(2)获取更多信息。
从Linux 2.6.25开始,Linux提供了2个/proc文件来为非实时进程保留CPU时间。保留的CPU也可以为shell预留资源来停止正在允许的进程。两个文件中的值对应的单位为微秒:
-
/proc/sys/kernel/sched_rt_period_us该文件中的值指定了等同于100% CPU的调度周期。取值范围为1到INT_MAX,即1微秒到35分钟。默认值为1000,000(1秒)。定义了一个CPU使用周期,周期越短,可以越快开始下一个周期
-
/proc/sys/kernel/sched_rt_runtime_us该文件中的值指定了实时和deadline调度的进程可以使用的"period"。取值范围为-1到INT_MAX-1,设置为-1标识运行时间等同于周期,即没有给非实时进程预留任何CPU。默认值为950,000(0.95秒),表示给非实时或deadline调度策略保留5%的CPU。该参数需要结合
sched_rt_period_us使用
Response time
一个阻塞的高优先级的线程(在调度前)等待I/O时会有一个确定的响应时间。设备驱动作者可以使用"slow interrupt"中断句柄来减少响应时间
Miscellaneous
子进程会通过fork(2)继承调度策略和参数。可以使用execve(2)来保存调度策略和参数。
实时进程通常会使用memory locking特性来防止内存页的延迟。可以使用mlock(2) 或mlockall(2)设置memory locking。
The autogroup feature
从Linux 2.6.38开始,内核提供了一种被称为autogrouping的特性来为多进程和CPU密集型负载(如Linux内核中的大量并行进程)提升交互式桌面性能。
该特性结合CFS调度策略,需要内核设置CONFIG_SCHED_AUTOGROUP。在一个运行的系统中,该特性可以通过文件/proc/sys/kernel/sched_autogroup_enabled使能或去使能,值0表示去使能,1表示使能。默认值为1(除非内核使用noautogroup参数启动内核)。
当通过setsid(2) (setsid会将一个进程脱离父进程)创建一个新的会话时会创建一个新的autogroup,这种情况可能发生在一个新的终端窗口启动时。使用fork(2)创建的进程会继承父辈的autogroup成员。因此,一个会话中的所有进程都属于同一个autogroup。当最后一个进程结束后,autogroup会被自动销毁。
当使能autogrouping时,一个autogroup中的所有成员都属于同一个内核调度器"任务组"。CFS调度器使用了在任务组间均衡分配CPU时钟周期的算法。可以使用下面例子进行展示提升交互式桌面性能的好处。
假设有2个竞争相同CPU的autogroup(即,单核系统或使用taskset设置所有SMP系统的进程使用相同的CPU),第一个group包含10个用于构建内核的CPU密集型进程make -j10CPU;另外一个包含一个CPU密集型的视频播放器进程。autogrouping的影响为:每个group各自分配到一半的CPU时钟周期,即视频播放器会分配到50%的CPU时钟周期,而非9%的时钟周期(该情况下可能会导致降低视频播放质量)。在SMP系统上会更加复杂,但整体的表现是一样的:调度器会在任务组之间分配CPU时钟周期,包含大量CPU密集型进程的autogroup并不会以牺牲系统上的其他任务为代价占用CPU周期。
进程的autogroup成员可以通过/proc/[pid]/autogroup查看:(下面进程隶属于autogroup-1,autogroup-1的nice值为0)
$ cat /proc/1/autogroup
/autogroup-1 nice 0
该文件可以通过为autogroup设置nice值来修改分配给一个autogroup的CPU带宽(bandwidth,即可使用的CPU时间),nice值范围为+19(低优先级)到-20(高优先级),设置越界的值会导致write(2)返回EINVAL错误。
autogroup的nice值的意义与进程的nice值意义相同,区别是前者为将autogroup作为一个整体,并基于相对其他autogroups设置的nice值来分配CPU时钟周期。对于一个autogroup内的进程,其CPU时钟周期为autogroup(相对于其他autogroups)的nice值和进程的nice值(相对于其他进程)的产物(即首先根据autogroup的nice值计算该autogroup所占用的CPU,然后根据进程的nice值计算该进程所占用的(属于其autogroup的)CPU)。
可以使用cgroups(7) CPU控制器来设置(非root CPU cgroup的)cgroups中的进程所占用的CPU,该设置会覆盖掉autogrouping。
所有的cgroup都由可选择的内核配置CONFIG_CGROUPS控制。在Linux 3.2引入了CPU带宽控制(bandwidth control)。cgroup对CFS的扩展有如下三种:
CONFIG_CGROUP_SCHED :运行任务以组的方式(在组之间)公平使用CPU
CONFIG_RT_GROUP_SCHED :用于支持实时任务组(SCHED_FIFO和SCHED_RR)
CONFIG_FAIR_GROUP_SCHED :用于支持CFS任务组(SCHED_NORMAL和SCHED_BATCH)
可以用如下方式查看是否启用了cgroup
# zgrep -i cgroup /boot/config-3.10.0-693.el7.x86_64
CONFIG_CGROUPS=y
# CONFIG_CGROUP_DEBUG is not set
CONFIG_CGROUP_FREEZER=y
CONFIG_CGROUP_PIDS=y
CONFIG_CGROUP_DEVICE=y
CONFIG_CGROUP_CPUACCT=y
CONFIG_CGROUP_HUGETLB=y
CONFIG_CGROUP_PERF=y
CONFIG_CGROUP_SCHED=y
CONFIG_BLK_CGROUP=y
...
autogroup特性仅用于非实时调度策略(SCHED_OTHER, SCHED_BATCH和SCHED_IDLE)。它不会为实时和deadline策略分组。
The nice value and group scheduling
当调度非实时进程时,CFS调度器会使用一种称为"group scheduling"的技术(如果内核设置了CONFIG_FAIR_GROUP_SCHED 选项)
在group scheduling下,进程以"任务组"方式进行调度。任务组间有继承关系,会继承系统上被称为"root任务组"的初始化任务组。任务组遵循以下条件(按顺序):
- CPU cgroup中的所有线程为一个任务组。该任务组的父辈为对应的父cgroup
- 如果使能了autogrouping,则一个autogroup(即,使用setsid(2)创建的相同的会话)中的所有线程为一个任务组。每个新的autogrouping为独立的任务组。root任务组为所有任务组的父辈。
- 如果使能了autogrouping,那么包含所有root CPU cgroup进程的root任务组不会(隐式地)放到一个新的autogroup中。
- 如果使能了autogrouping,那么root任务组包含所有root CPU croup中的进程。
- 如果去使能autogrouping(即内核不配置CONFIG_FAIR_GROUP_SCHED),那么系统中所有的进程都会被放到一个任务组中
在group调度下,线程的nice值仅会影响到相同任务组的其他线程的调度。这会在一些使用传统nice语义的UNIX系统上会导致惊人的后果。实践中,如果使能了autogrouping,则会使用setpriority(2)或nice(1)来影响相同会话(通常为相同的终端窗口)中的一个进程相对于其他进程的调度。
相反的,对于不同会话(如,不同的终端窗口,这些任务都绑定到不同的autogroups)中绑定了唯一的CPU的2个进程,修改一个会话中的进程的nice值不会影响其他会话中的进程的调度。使用如下命令可以修改一个终端会话中所有进程对于的autogroup nice值。
$ echo 10 > /proc/self/autogroup
autogroup和进程都有一个nice值,autogroup的nice值用于在autogroup之间分配CPU;autogroup内的进程的nice值用于在进程间分配autogroup的CPU。cgroup的配置会覆盖autogroup
Real-time features in the mainline Linux kernel
从Linux 2.6.18开始,Linux逐渐具备实时功能,其中大部分来源于realtime-preempt补丁集。在这些补丁最终合并到内核主线之前,它们必须通过安装才能达到实时性能。这些补丁命名为:
patch-kernelversion-rtpatchversion
可以从这里下载。
如果没有补丁且在这些补丁完全合并到主线之前的内核提供了3中抢占类,CONFIG_PREEMPT_NONE,CONFIG_PREEMPT_VOLUNTARY和CONFIG_PREEMPT_DESKTOP,分别表示没有,部分,和考虑降低最坏情况下的调度延迟。
如果没有补丁且在这些补丁完全合并到主线之前的内核还提供了额外的配置表项CONFIG_PREEMPT_RT,如果选择该表项,Linux会转变为正式的实时操作系统。FIFO和RR调度策略会用于运行具有实时优先级且最小调度延迟的线程。
TIPS:
-
使用
ps -eLfc可以在CLS一栏中查看进程的调度策略,最下面为最新内核中定义的调度策略(5.5)TS SCHED_OTHER FF SCHED_FIFO RR SCHED_RR B SCHED_BATCH ISO SCHED_ISO IDL SCHED_IDLE/* * Scheduling policies */ #define SCHED_NORMAL 0 #define SCHED_FIFO 1 #define SCHED_RR 2 #define SCHED_BATCH 3 /* SCHED_ISO: reserved but not implemented yet */ #define SCHED_IDLE 5 #define SCHED_DEADLINE 6 -
可以在/proc/sched_debug中查看各个cpu core的调度情况,其中包含每个cgroup 服务的调度情况,如下面为docker服务在core1上的调度情况
cfs_rq[1]:/system.slice/docker.service .exec_clock : 0.000000 .MIN_vruntime : 0.000001 .min_vruntime : 2723538.752185 .max_vruntime : 0.000001 .spread : 0.000000 .spread0 : -780278343.308552 .nr_spread_over : 0 .nr_running : 0 .load : 0 .runnable_load_avg : 0 .blocked_load_avg : 1 .tg_load_avg : 1 .tg_load_contrib : 1 .tg_runnable_contrib : 3 .tg->runnable_avg : 8 .tg->cfs_bandwidth.timer_active: 0 .throttled : 0 .throttle_count : 0 .se->exec_start : 7432565479.124290 .se->vruntime : 560032308.234830 .se->sum_exec_runtime : 7762399.141979 .se->load.weight : 2 .se->avg.runnable_avg_sum : 147 .se->avg.runnable_avg_period : 47729 .se->avg.load_avg_contrib : 1 .se->avg.decay_count : 7088246803可以在/proc/$pid/sched中查看特定进程的调度情况
# cat sched docker-proxy-cu (77992, #threads: 8) ------------------------------------------------------------------- se.exec_start : 7179182946.125343 se.vruntime : 1843988.364695 se.sum_exec_runtime : 6.017643 se.nr_migrations : 2 nr_switches : 6 nr_voluntary_switches : 4 nr_involuntary_switches : 2 se.load.weight : 1024 policy : 0 prio : 120 clock-delta : 34 mm->numa_scan_seq : 0 numa_migrations, 0 numa_faults_memory, 0, 0, 1, 0, -1 numa_faults_memory, 1, 0, 0, 0, -1 -
一个线程可以通过系统分配的时间片在各个CPU core上允许,但一个线程不能同时在多个core上运行。如果一个系统有N个core,那么可以同时在这些core上允许N个线程。将CPU core上线程切换到另外一个线程时,会涉及到上下文切换,上下文切换时需要保存PCB中的CPU寄存器信息,进程状态以及内存管理等信息,在进程恢复时还原这些信息。
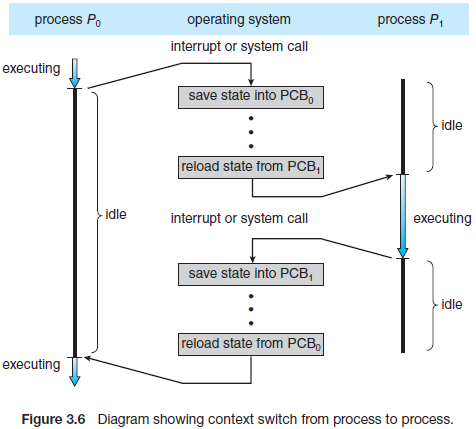
-
可以通过/proc/$pid/status查看进程上下文切换的情况,如下表示自发(如I/O等待)的上下文切换为1,非自发(如时间片超时会被更高优先级进程抢占)的上下文切换为10。
voluntary_ctxt_switches: 1 nonvoluntary_ctxt_switches: 10 -
实时调度发生的情况可能是软件(如定时器超时)或硬件引发的
-
容器也会使用CFS在各个cgroup中进行调度,更多细节参见understanding-linux-container-scheduling
-
可以将1个CPU分为1000份,即1 CPU = 1000m。但在CFS中,会将1 CPU分为1024份,称为1024 CPU shares,即分配500m的CPU等同于分配了512 CPU shares。
CFS的调度周期由cpu.cfs_period_us定义,默认100m。意味着,如果cpu.cfs_period_us为100m,则1CPU就是100ms,而2500m CPU就是250ms,CFS会将一个周期切分为多个时间片,最小时间片由sched_cfs_bandwidth_slice_us定义,默认5ms。
参考
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/12133100.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号