
负载均衡策略导致后端程序访问异常
起因:
最近新部署了openshift集群,由于使用了自签证书,浏览器访问集群的https服务会报告警(如下图),在使用浏览器(特别是IE)访问openshift master暴露的服务时,选择继续访问时,出现了尝试很多次才能登陆成功的情况。

问题排查:
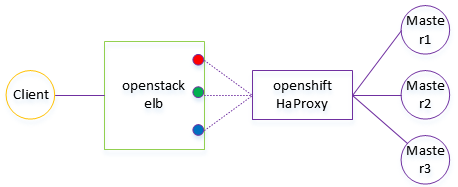
访问流程如下,client(浏览器)会直接访问到openstack的elb,elb使用FullNat模式,将流量导入到openshift集群的route节点(为便于问题定位,route减少为1个)的HaProxy上,再由其按照规则将流量导到3个master中的某一个。注:openshift部署在华为openstack之上。

在client抓包发现client在访问https服务之前会进行证书交互,但在client发出client hello报文,且server回了server hello,certificate,server key exchange,hello done报文之后,client就没有再回tls报文给server端。查看tcp报文,发现client端主动发起fin断链。随后的报文也一直在重复上述交互过程。

从上述所看就是证书交互没有正常完成出了问题,将openshift集群的ca证书手动加载到client端浏览器的可信任证书后,该现象消失,浏览器可以正常访问。起初以为是证书生成有问题,因为server端已经正常回复了tls报文(经排查,交互的tcp报文以及dns解析都正常),而client端在接收到server的报文之后并没有进行回复,而是选择断开链接,该操作是由浏览器产生的,不明白为什么浏览器一直会发出tcp fin报文。
为方便定位,简化模型如下,去掉了openstack的elb,发现此时浏览器可以正常访问,此时基本确认是elb的问题。
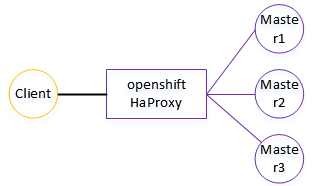
经过沟通和尝试,发现该elb后端部署了多个ip(为了支持更多服务的NAT需求),一开始该elb的负载均衡策略为轮询,而openshfit的haproxy的负载均衡策略为ip hash,因此相同client的不同tcp链接可能经过不同的虚拟IP nat到openshift集群。
这样问题就比较清楚了:当浏览器访问后端服务时,首先经过elb,由elb的某个IP传输到openshift的haproxy,再由haproxy hash到某个master节点。在单条tcp条件下是没有问题的,这也是为什么浏览器添加ca到信任证书列表之后可以正常访问了,因为此时ssl协商不会被浏览器中断;而在ca未添加到浏览器信任证书列表时,当client访问后端服务时,浏览器会弹出“站点不安全“告警,此时浏览器会发出tcp fin断链报文,当选择继续访问时,此时client会允许使用该证书进行访问,但此时会重新进行tcp建链,由于elb使用了轮询模式,该tcp可能会选择跟前面不一样的ip出去,而openshift haproxy使用的又是ip hash模式,当源ip不一致时会选择不一样的master。这样原证书会和新节点不匹配,就出现了前面浏览器尝试多次无法链接的情况,特殊情况下二者正好匹配到,此时浏览器可以正常访问。
证书不匹配时,客户端(浏览器)会发出Fatal级别的alert
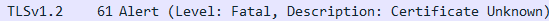
在rfc5246的 7.2.2. Error Alerts 章节中有如下表述,即当接收到fatal级别的消息时,server和client会断开并清空与该链接相关的信息(如证书),因此后续浏览器会重新初始化链接,导致无法使用允许的自签证书通信
Upon transmission or receipt of a fatal alert message, both parties immediately close the connection. Servers and clients MUST forget any session-identifiers, keys, and secrets associated with a failed connection. Thus, any connection terminated with a fatalalert MUST NOT be resumed.
解决方法:
- 将CA证书拷贝到浏览器信任证书列表,或使用非自签证书
- openstack的elb使用ip hash模式,这样相同client的tcp不会nat到elb的多个虚拟ip
注:
由于使用2个lb其实有点多余,后期进行了优化,删除了openshift的haproxy
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/10678306.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号