


openshift pod对外访问网络解析
openshift封装了k8s,在网络上结合ovs实现了多租户隔离,对外提供服务时报文需要经过ovs的tun0接口。下面就如何通过tun0访问pod(172.30.0.0/16)进行解析(下图来自理解OpenShift(3):网络之 SDN,删除了原图的IP)
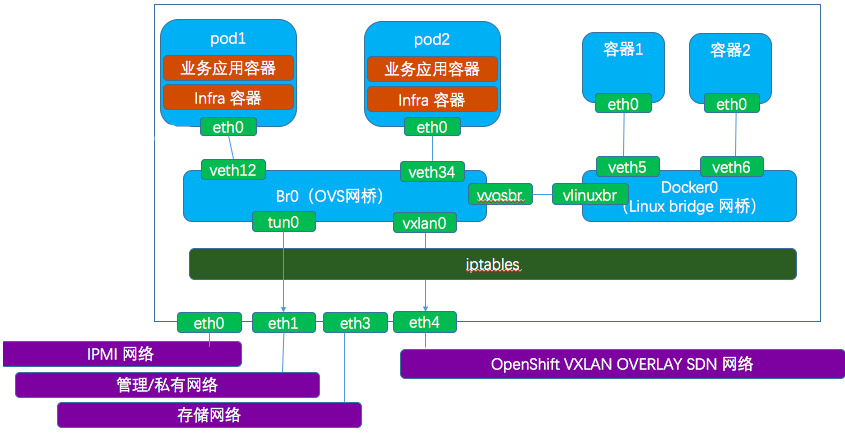
openshift版本如下:
# openshift version openshift v3.6.173.0.5 kubernetes v1.6.1+5115d708d7 etcd 3.2.1
首先在查看openshift上pod(该pod为elasticsearch)的路由,默认网关为10.131.2.1,出接口为eth0(IP:10.131.2.45)
sh-4.2$ ip route
default via 10.131.2.1 dev eth0
10.128.0.0/14 dev eth0
10.131.2.0/23 dev eth0 proto kernel scope link src 10.131.2.45
224.0.0.0/4 dev eth0
其次查看node节点的路由,到达pod service的cluster ip(172.30.229.30)的网段(172.30.0.0)出接口为tun0,因此外部流量首先会达到tun0,然后通过tun0转发到pod
[root@dt-infra1 home]# ip route
default via 10.122.70.1 dev eth0 proto static metric 100
10.122.70.0/24 dev eth0 proto kernel scope link src 10.122.70.72 metric 100
10.128.0.0/14 dev tun0 proto kernel scope link
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.30.0.0/16 dev tun0 scope link
查看node节点的接口信息如下(已删减无关接口信息),可以看到vethd0d3571b就是pod中eth0接口的对端,tun0 IP地址也为pod中的默认网关,
[root@dt-infra1 home]# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 50:6b:8d:d4:25:db brd ff:ff:ff:ff:ff:ff
inet 10.122.70.72/24 brd 10.122.70.255 scope global dynamic eth0
valid_lft 2137631556sec preferred_lft 2137631556sec
inet6 fe80::748f:487f:6bf1:685c/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::8fab:527e:43dd:f1b1/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::f2d6:994f:f43:cce5/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
5: br0: <BROADCAST,MULTICAST> mtu 1450 qdisc noop state DOWN qlen 1000
link/ether 8e:13:86:1d:ab:43 brd ff:ff:ff:ff:ff:ff
9: vxlan_sys_4789: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65470 qdisc noqueue master ovs-system state UNKNOWN qlen 1000
link/ether d6:48:30:3a:bb:d0 brd ff:ff:ff:ff:ff:ff
inet6 fe80::d448:30ff:fe3a:bbd0/64 scope link
valid_lft forever preferred_lft forever
10: tun0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN qlen 1000
link/ether a6:02:fb:84:24:d0 brd ff:ff:ff:ff:ff:ff
inet 10.131.2.1/23 scope global tun0
valid_lft forever preferred_lft forever
inet6 fe80::a402:fbff:fe84:24d0/64 scope link
valid_lft forever preferred_lft forever
53: vethd0d3571b@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master ovs-system state UP
link/ether 0e:7d:3a:9f:ff:6e brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::c7d:3aff:fe9f:ff6e/64 scope link
valid_lft forever preferred_lft forever
查看该pod的接口信息,可以看出eth0为一对veth pair,对应所在node节点编号为if53的veth
sh-4.2$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if53: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT link/ether 0a:58:0a:83:02:2d brd ff:ff:ff:ff:ff:ff link-netnsid 0
从上图中可以看到tun0和pod的veth pair是连接到了一个bridge上,该bridge使用ovs创建的(ip link show type bridge 不可见),使用如下命令可以查看位于br0的ports信息,上面连接了tun0和pod veth的对端
[root@dt-infra1 home]# ovs-vsctl show b9e6f9ba-efb4-4d5f-97f0-e53191ccf174 Bridge "br0" fail_mode: secure Port "vxlan0" Interface "vxlan0" type: vxlan options: {key=flow, remote_ip=flow} Port "br0" Interface "br0" type: internal Port "vethd0d3571b" Interface "vethd0d3571b" Port "tun0" Interface "tun0" type: internal ovs_version: "2.7.2"
使用如下命令可以查看该环境上的ovs bridge,当前环境只有一个br0
[root@dt-infra1 home]# ovs-vsctl list-br
br0
使用如下命令查看当前环境的port编号,该编号在openflow处理时用于指定接口
[root@dt-infra1 home]# ovs-ofctl -O OpenFlow13 dump-ports-desc br0 OFPST_PORT_DESC reply (OF1.3) (xid=0x2): 1(vxlan0): addr:aa:fd:ab:96:85:ed config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 2(tun0): addr:a6:02:fb:84:24:d0 config: 0 state: 0 speed: 0 Mbps now, 0 Mbps max 10(vetha739667c): addr:9e:14:13:9c:6e:73 config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 37(veth6c630c72): addr:2e:f7:70:40:b6:fb config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max 45(vethd0d3571b): addr:0e:7d:3a:9f:ff:6e config: 0 state: 0 current: 10GB-FD COPPER speed: 10000 Mbps now, 0 Mbps max LOCAL(br0): addr:8e:13:86:1d:ab:43 config: PORT_DOWN state: LINK_DOWN speed: 0 Mbps now, 0 Mbps max
与上述pod相关的iptables如下,在进入tun0之前会将ip DNAT为10.131.2.45:9200,即Container IP:ContainerPort
-A KUBE-SERVICES -d 172.30.229.30/32 -p tcp -m comment --comment "logging/logging-es: cluster IP" -m tcp --dport 9200 -j KUBE-SVC-BWSQUABZDDFLJOKN -A KUBE-SVC-BWSQUABZDDFLJOKN -m comment --comment "logging/logging-es:" -j KUBE-SEP-H2SZLG7QT6WVYISM -A KUBE-SEP-H2SZLG7QT6WVYISM -s 10.131.2.45/32 -m comment --comment "logging/logging-es:" -j KUBE-MARK-MASQ -A KUBE-SEP-H2SZLG7QT6WVYISM -p tcp -m comment --comment "logging/logging-es:" -m tcp -j DNAT --to-destination 10.131.2.45:9200
从pod中出来的报文会传输到br0进行流表处理,然后选择出接口tun0。ovs流表在处理时有如下规则:
table 0: 根据输入端口(in_port)做入口分流,来自VXLAN隧道的流量转到表10并将其VXLAN VNI 保存到 OVS 中供后续使用,从tun0过阿里的(来自本节点或进本节点来做转发的)流量分流到表30,将剩下的即本节点的容器(来自veth***)发出的流量转到表20; table 10: 做入口合法性检查,如果隧道的远端IP(tun_src)是某集群节点的IP,就认为是合法,继续转到table 30去处理; table 20: 做入口合法性检查,如果数据包的源IP(nw_src)与来源端口(in_port)相符,就认为是合法的,设置源项目标记,继续转到table 30去处理;如果不一致,即可能存在ARP/IP欺诈,则认为这样的的数据包是非法的; table 30: 数据包的目的(目的IP或ARP请求的IP)做转发分流,分别转到table 40~70 去处理; table 40: 本地ARP的转发处理,根据ARP请求的IP地址,从对应的端口(veth)发出; table 50: 远端ARP的转发处理,根据ARP请求的IP地址,设置VXLAN隧道远端IP,并从隧道发出; table 60: Service的转发处理,根据目标Service,设置目标项目标记和转发出口标记,转发到table 80去处理; table 70: 对访问本地容器的包,做本地IP的转发处理,根据目标IP,设置目标项目标记和转发出口标记,转发到table 80去处理; table 80: 做本地的IP包转出合法性检查,检查源项目标记和目标项目标记是否匹配,或者目标项目是否是公开的,如果满足则转发;(这里实现了 OpenShift 网络层面的多租户隔离机制,实际上是根据项目/project 进行隔离,因为每个项目都会被分配一个 VXLAN VNI,table 80 只有在网络包的VNI和端口的VNI tag 相同才会对网络包进行转发) table 90: 对访问远端容器的包,做远端IP包转发“寻址”,根据目标IP,设置VXLAN隧道远端IP,并从隧道发出; table 100: 做出外网的转出处理,将数据包从tun0发出。
该pod对应有如下两条规则,对应arp和ip协议的处理。第一条为arp处理,直接转发到port 45,即pod的veth0对端;后两条为ip处理,第二条首先对目的地址进行判断,然后将0x2d加载到NXM_NX_REG2中,第三条接着处理,对源地址10.131.2.1(即tun0)的报文转发到NXM_NX_REG2[](即0x2d,十进制值为45,为pod的veth对端)
1 cookie=0x0, duration=1876880.378s, table=40, n_packets=30185, n_bytes=1267770, priority=100,arp,arp_tpa=10.131.2.45 actions=output:45 2 cookie=0x0, duration=1876880.373s, table=70, n_packets=743139978, n_bytes=738498091589, priority=100,ip,nw_dst=10.131.2.45 actions=load:0->NXM_NX_REG1[],load:0x2d->NXM_NX_REG2[],goto_table:80 3 cookie=0x0, duration=9851088.683s, table=80, n_packets=29879646, n_bytes=113936915873, priority=300,ip,nw_src=10.131.2.1 actions=output:NXM_NX_REG2[]
总结:
报文从外部到pod的整个流程为:node route->iptables->ovs流表->pod。需要注意的是pod内部通信走的是vxlan。全流程参见SDN Flows Inside a Node
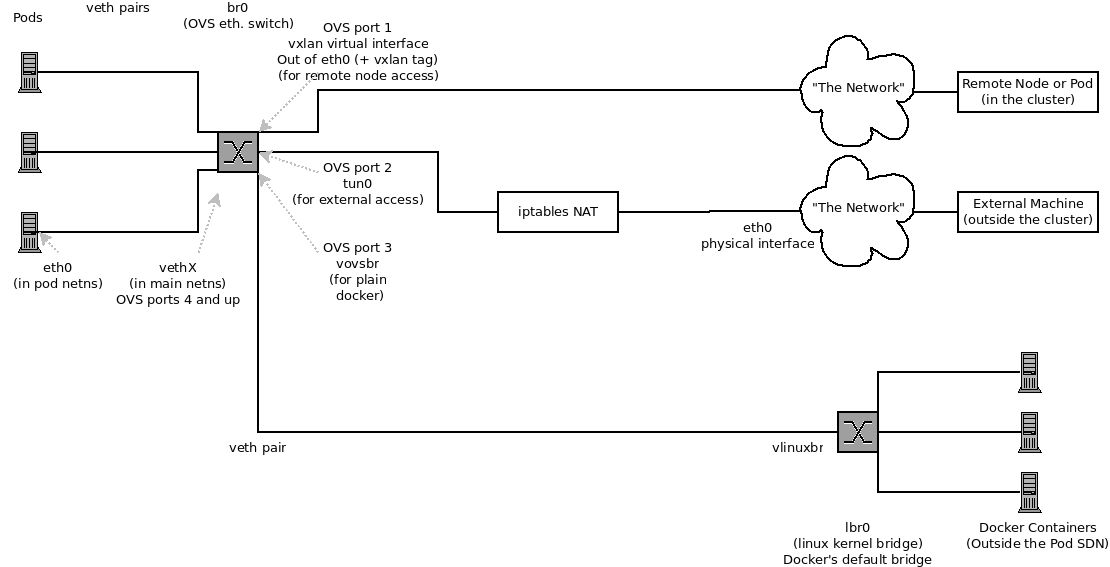
TIPS:
- pod间通信是通过vxlan进行的,ovs网桥中会进行vxlan的封包,到达pod的报文转发到vxlan端口中,将目的node IP作为报文外部目的地址(tun_dst表示outer ip dst),参见OpenShift SDN
- 外部访问pod是通过router接受流量转换为内部pod之间的通信,即vxlan方式
- 本机访问本机的pod根据路由转发到tun0
参考:
https://cloud.tencent.com/developer/article/1070415
https://blog.51cto.com/c2014/1829179
http://www.cnblogs.com/sammyliu/p/10064450.html
http://www.openvswitch.org/support/dist-docs-2.5/ovs-ofctl.8.html
http://www.openvswitch.org/support/dist-docs/ovs-fields.7.txt
https://www.ibm.com/developerworks/cn/cloud/library/1401_zhaoyi_openswitch/index.html
https://www.ibm.com/developerworks/cn/linux/l-tuntap/
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/10566425.html

