
Python基础知识:模块
目录
JSON模块&pickle模块
requests模块
time模块
datetime模块
logging模块
os模块
sys模块
hashlib模块
re模块、正则表达式
configparser模块
XML模块
shutil模块
subprocess 模块
JSON模块&pickle模块
1、安装模块的两种方法:
第一种:pip install 模块名
第二种:源码安装:先到官网下载模块的源码(选择download the tarball)----》先解压(解压文件夹中有一个setup.py文件)----》cd 目录----》pip setup.py install
2、JSON(JavaScript Object Notation)格式最初是JavaScript开发的,但随后成为一种常见格式,被包括Python在内的众多语言使用。模块json能够将简单的Python数据结构存储到文件中,并在程序再次运行时加载该文件中的数据;不仅可以在Python程序之间分享数据,还可以与使用其他编程语言的人分享,而且所有的.json类型的文件内容都是字符串形式的。
json.load() 读取文件内容,并将字符串转为基本数据类型;
json.dump()把基本类型数据存储到文件中;适用于所有的语言,适合跨平台使用,只支持Python中的基本数据类型;函数接受两个实参:要存储的数据以及可用于存储数据的文件对象;
pickle模块:功能同上,但是只能针对Python使用,会以字节的形式将数据存储到文件,但是支持Python中所有的数据类型,包括复杂的类等等。
#json.dump()存储,json.load()读取 import json filename = r'json_file\favor_number.json' with open(filename, 'r') as f_obj: favor_number = json.load(f_obj) print('I know your favorite number is %d.'%int(favor_number)) love_number = input('enter your favorite number:') with open(filename,'w') as f_obj: json.dump(love_number,f_obj)
#json.loads()将字符串形式的字典或列表,转为字典或列表 import json s = "[1,2,3]" li = json.loads(s) print(li,type(li))#[1, 2, 3] <class 'list'> #json.dumps()将字典或列表转为字符串 s = {"k":"v"} dic = json.dumps(s) print(dic,type(dic))#{"k": "v"} <class 'str'> #如果字符串内部是字典,字典内部一定要用双引号,外部用单引号 n = '{"k":"v"}' print(json.loads(n))
requests模块
#访问URL获取北京天气 import requests import json response = requests.get("http://wthrcdn.etouch.cn/weather_mini?city=北京") response.encoding = "utf-8" r = json.loads(response.text) print(r)
time模块
import time time.time()#返回系统当前时间戳,从1970年Unix(Linux的前身)正式商用开始算起(秒); time.ctime()#返回系统当前时间,字符串格式#Tue Nov 27 09:07:55 2018 print(time.gmtime())#将时间戳转换为struct_time格式,按0时区算,跟本地时间差8小时 #time.struct_time(tm_year=2018, tm_mon=11, tm_mday=27, tm_hour=1, # tm_min=12, tm_sec=46, tm_wday=1, tm_yday=331, tm_isdst=0) print(time.localtime())#将时间戳转换为struct_time格式,返回本地时间 #与time.localtime()功能相反,将struct_time格式转为时间戳格式 print(time.mktime(time.localtime())) time.sleep(0.1)#程序睡眠0.1秒 #将本地时间转换成特定格式 tm =time.strftime("%Y-%m-%d %H-%M-%S",time.localtime()) print(tm) tm = time.strptime("2018-11-27 09:33","%Y-%m-%d %H:%M") print(tm)#将特定时间格式转换为struct_time格式,如果没有写秒,默认从0开始
datetime模块
import datetime
#获取系统当前日期 print(datetime.date.today())#2018-11-27 #将时间戳转换为日期格式 print(datetime.date.fromtimestamp(time.time()))#2018-11-27 #返回系统当前准确时间 current_time = datetime.datetime.now() print(current_time)#2018-11-27 09:48:21.483993 #将时间转换为struct_time格式 print(current_time.timetuple()) #时间运算 print(datetime.datetime.now() + datetime.timedelta(days=10)) #替换当前时间,可单独替换年月日 print(current_time.replace(2014,12,12)) #日期格式的时间可以比较大小 old_time = current_time.replace(2014) print(type(old_time))#<class 'datetime.datetime'> print(current_time>old_time)#True
logging模块
1、用于便捷记录日志且线程安全的模块
2、日志等级:
CRITICAL = 50 (危险的) FATAL = CRITICAL ERROR = 40 WARNING = 30 WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0
3、输出到屏幕
import logging logging.warning("user [alex] attempted wrong password more than 3 times") logging.critical("server is down")
4、写入文件
#把日志写到文件里,level值表示只写入这个等级或以上等级 import logging logging.basicConfig(filename='text_file\example.log',level=logging.INFO) logging.debug('This message should go to the log file')#等级不够,不写入 logging.info('So should this') logging.warning('And this, too') #日志格式加上时间 logging.basicConfig(filename='text_file\example.log',level=logging.INFO, format='%(asctime)s%(message)s', datefmt='%Y-%m-%d %I-%M-%S %p') logging.warning(" It's time to go home.")
5、日志同时输出屏幕和将日志类型分别写入多个文件
注:只有【当前写等级】大于【日志等级】时,日志文件才被记录。
import logging #创建日志类型 logger = logging.getLogger("测试日志") #创建全局日志等级,全局等级为最低限制,局部只能高不能低,以全局等级为准 logger.setLevel(logging.DEBUG) #创建输出屏幕对象和等级 sh = logging.StreamHandler() sh.setLevel(logging.INFO) #创建写入文件对象和等级 fh = logging.FileHandler("text_file\warning.log",'a',encoding='utf-8') fh.setLevel(logging.WARNING) #创建输出格式 formater1 = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') formater2 = logging.Formatter('%(asctime)s-%(filename)s-%(levelname)s-%(message)s') #给输出对象添加输出格式 sh.setFormatter(formater1) fh.setFormatter(formater2) #将输出对象添加到logger logger.addHandler(sh) logger.addHandler(fh) #执行输出命令 logger.debug('debug message') logger.info('info message') logger.warning('warn message') logger.error('error message') logger.critical('critical message')
6、日志记录格式:
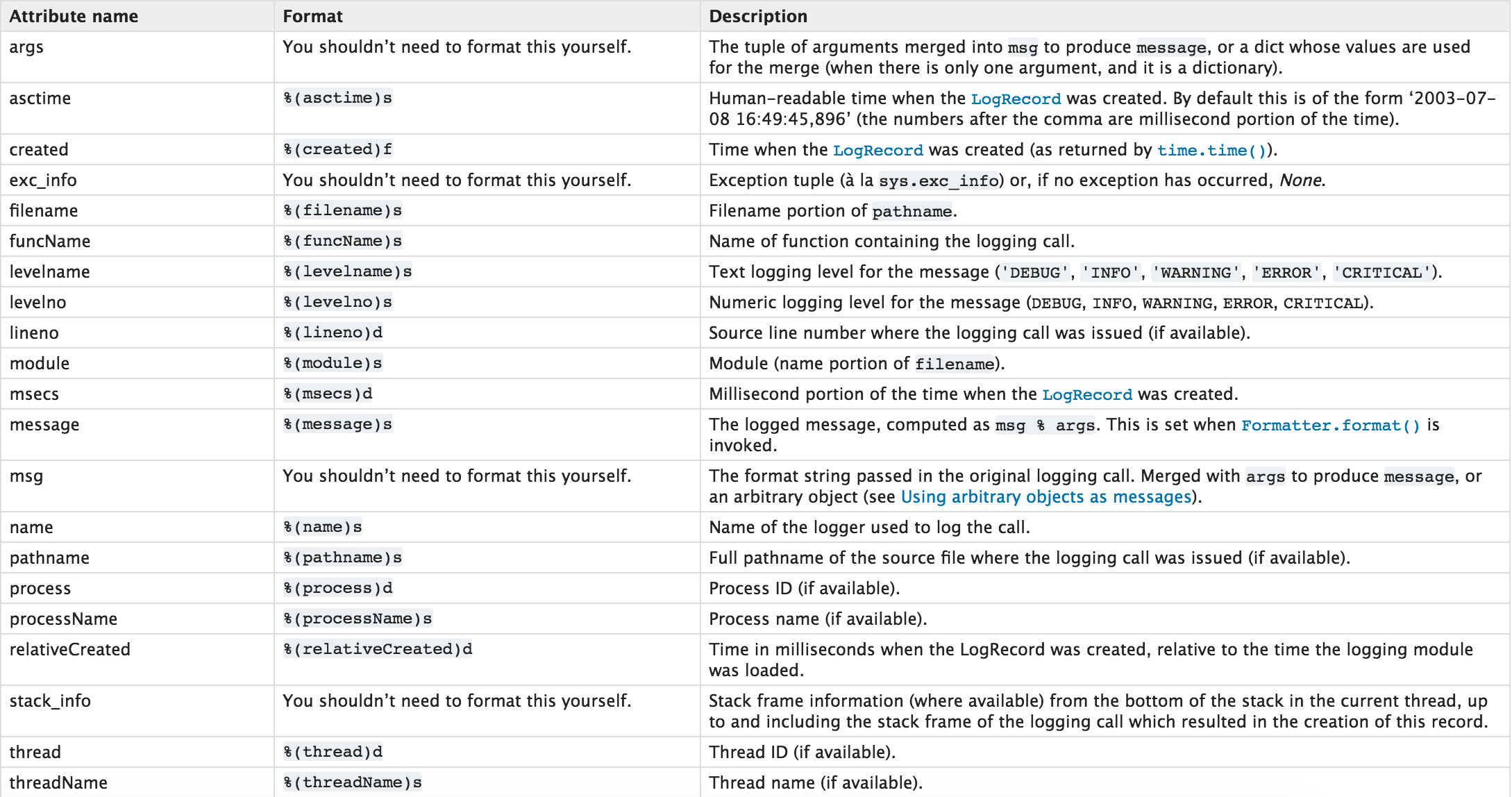
os模块
1、获取当前文件的绝对路径
import os print(os.path.abspath(__file__)) #C:\Users\Administrator\Desktop\Pycharm_Projects\basic_knowledge\模块.py
2、获取当前路径的上一级路径
import os print(os.path.dirname(os.path.abspath(__file__))) #C:\Users\Administrator\Desktop\Pycharm_Projects\basic_knowledge
3、调用另一个文件夹下的模块
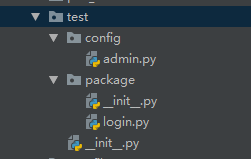
import sys import os s = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(s) #package为Python Package类型的文件夹 #不能使用import.login调用 from package import login login.log()
4、当一个py文件中末尾加入下面的代码时,只有执行当前文件的时候,当前文件的特殊变量__name__ == "__main__",也即是说直接运行当前文件,就会直接执行函数;如果是导入到另一个文件中,只调用文件不会执行,只有执行文件时才会执行;如果py文件中没有if语句,直接在文件末尾调用了函数,也就是可以直接运行该文件,如果此时该文件被另一个文件调用了,函数会直接运行,不需要使用文件名.函数名的格式来执行函数。
if __name__ == "__main__": main()
5、调用一个函数中的全局变量
import test print(test.NAME)
6、模块中的特殊变量
#__doc__返回文件开头的注释 #__cached__字节码存放的位置 #__file__当前py文件的路径 #__package__当前模块所在的包
7、创建文件夹、子文件夹以及文件夹中的文件;
import os #生成多层递归目录 os.makedirs('user_db/6225021542120/record') os.makedirs('user_db/6225021542120/basic_info') #另一种方法 card_num = "6225021542120" #"user_db"为第一级文件夹名,依次二级,三级目录 os.makedirs(os.path.join("user_db",card_num,"record")) #再次在card_num目录下新建文件夹 os.makedirs(os.path.join("user_db",card_num,"basic_info"))
8、模块中用于提供系统级别的操作
os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd
os.curdir #返回当前目录: ('.')
os.pardir #获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') #可生成多层递归目录
os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() #删除一个文件
os.rename("oldname","new") #重命名文件/目录
os.stat('path/filename') #获取文件/目录信息
os.sep #操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep #当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep #用于分割文件路径的字符串
os.name #字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") #运行shell命令,直接显示
os.environ #获取系统环境变量
os.path.abspath(path) #返回path规范化的绝对路径
os.path.split(path) #将path分割成目录和文件名二元组返回
os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) #如果path是绝对路径,返回True
os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
sys模块
1、sys模块中的基本操作
sys.argv #命令行参数List,第一个元素是程序本身路径 sys.exit(n) #退出程序,正常退出时exit(0) sys.version #获取Python解释程序的版本信息 sys.maxint #最大的Int值 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform #返回操作系统平台名称 sys.stdin #输入相关 sys.stdout #输出相关 sys.stderror #错误相关
2、view_bar(num,total)制作一个进度条
import sys import time def view_bar(num,total): rate = num / total #求出每次给的num占总数的比例 rate_num = int(rate * 100) #转换成百分比形式,取整 r = "\r%s%d%%" % (">" * rate_num, rate_num) #\r表示重新回到当前行的初始位置 sys.stdout.write(r) #重新输出r if __name__ == "__main__": for i in range(0,101): time.sleep(0.001) view_bar(i,100) #>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%
hashlib模块
1、对密码123进行双层加密
import hashlib obj = hashlib.md5(bytes("asfdfdfdf",encoding="utf-8")) obj.update(bytes('123',encoding='utf-8')) ret = obj.hexdigest() print(ret)
re模块、正则表达式
1、python中re模块提供了正则表达式相关操作
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
正则分组:从已经匹配到的数据中再提取数据
import re #精准匹配 print(re.findall('alex','alexfkalexslalwxlp'))#['alex', 'alex'] #'.'能匹配到换行符以外的所有字符 print(re.findall('al.x','alexfkalexshalwxkp'))#['alex', 'alex', 'alwx'] #'^'从字符串初始位置匹配 print(re.findall('^alex','alexfkalexslalwxlp'))#['alex'] #'$'从字符串末尾位置匹配,只有在末尾才能匹配到 print(re.findall('^alex','alexfkalexslalwalex'))#['alex'] #'*'表示x前面的字符匹配0到多次 print(re.findall('al.*x','alexfkalexshalwxkp'))#['alexfkalexshalwx'] print(re.findall('ale*x','alexfkalexshalwxkp'))#['alex', 'alex'] print(re.findall('al*x','fkalxshalwx'))#['alx'] #'+'表示x前面的字符匹配1到多次 print(re.findall('al.+x','fkalxshuulw'))#[] #'?'表示x前面的字符匹配0或1次 print(re.findall('al.?x','fkalxshuulw'))#['alx'] #{}表示匹配的范围 print(re.findall('al.{0,5}x','fkalrrrrxshuulw'))#['alrrrrx'] #[]表示字母的范围,以上元字符在中括号内不再有原有的意义 print(re.findall('al[a-z]x','alqx'))#['alqx'] #"^"在中括号内表示否的意思,只要不是z,都可以匹配到 print(re.findall('al[^z]x','alqx'))#['alqx'] #[/d]表示数字 print(re.findall('al[\d]x','al3x'))#['al3x'] #\b匹配一个单词边界,也就是指单词和空格间的位置,空白和非字母数字都可以匹配到 print(re.findall(r'I\b','I%am a cat.'))#['I'] #split()以什么为界分割字符串 print(re.split('\d+','ane1two2three3four4')) #['ane', 'two', 'three', 'four', '']
2、match(pattern, string, flags=0) 从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
# pattern: 正则模型 # string : 要匹配的字符串 # falgs : 匹配模式 #匹配模式: #re.I--使匹配对大小写不敏感 #re.L--做本地化识别匹配 #re.M--多行匹配,影响^和$ #re.S--是.匹配包括换行符在内的所有字符
# 无分组 origin = "hello alex bcd abcd lge acd 19" r = re.match("h\w+", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 # 有分组 # 为何要有分组?提取匹配成功的指定内容(先匹配成功全部正则,再匹配成功的局部内容提取出来) r = re.match("h(\w+).*(?P<name>\d)$", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
3、findall(pattern, string, flags=0) 获取非重复的匹配列表;如果有一个组则以列表形式返回,且每一个匹配均是字符串;如果模型中有多个组,则以列表形式返回,且每一个匹配均是元祖;空的匹配也会包含在结果中。
# 无分组 r = re.findall("a\w+",origin) print(r) # 有分组 origin = "hello alex bcd abcd lge acd 19" r = re.findall("a((\w*)c)(d)", origin) print(r)
#[('bc', 'b', 'd'), ('c', '', 'd')]
#如果需要调用很多次,使用下面的方法更快速 s = "hello alex bcd alex lge alex acd 19" obj = re.compile(r'a\w+') print(obj.findall(s)) #['alex', 'alex', 'alex', 'acd']
4、search(pattern, string, flags=0) 浏览整个字符串去匹配第一个,未匹配成功返回None
# 无分组 origin = "hello alex bcd abcd lge acd 19" r = re.search("a\w+", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组结果 # 有分组 r = re.search("a(\w+).*(?P<name>\d)$", origin) print(r.group()) # 获取匹配到的所有结果 print(r.groups()) # 获取模型中匹配到的分组结果 print(r.groupdict()) # 获取模型中匹配到的分组中所有执行了key的组
#正则表达式两个\匹配到一个\ import re r = re.search(r"\\", 'ori\gin') print(r.group())
5、sub( ) 替换匹配成功的指定位置字符串
sub(pattern, repl, string, count=0, flags=0) # pattern: 正则模型 # repl : 要替换的字符串或可执行对象 # string : 要匹配的字符串 # count : 指定匹配个数 # flags : 匹配模式
# 与分组无关 origin = "hello alex bcd alex lge alex acd 19" r = re.sub("a\w+", "999", origin, 2) print(r)
6、subn( ) 替换匹配成功的指定位置字符串,并返回替换次数
# 与分组无关 import re origin = "hello alex bcd alex lge alex acd 19" r = re.subn(r"a\w+", "999", origin) print(r) #('hello 999 bcd 999 lge 999 999 19', 4)
7、split( ) 根据正则匹配分割字符串
split(pattern, string, maxsplit=0, flags=0) # pattern: 正则模型 # string : 要匹配的字符串 # maxsplit:指定分割个数 # flags : 匹配模式
# 无分组 origin = "hello alex bcd alex lge alex acd 19" r = re.split("alex", origin, 1) print(r) #['hello ', ' bcd alex lge alex acd 19'] # 有分组 origin = "hello alex bcd alex lge alex acd 19" r1 = re.split("(alex)", origin, 1) print(r1) #['hello ', 'alex', ' bcd alex lge alex acd 19'] r2 = re.split("(al(ex))", origin, 1) print(r2) #['hello ', 'alex', 'ex', ' bcd alex lge alex acd 19']
print(re.split('\d+','ane1two2three3four4')) #['ane', 'two', 'three', 'four', '']
8、常用正则表达式
IP: ^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$ 手机号: ^1[3|4|5|8][0-9]\d{8}$ 邮箱: [a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+ 必须是字母和数字组合: (?!^[a-zA-Z]+$)(?!^\d+$)[0-9a-zA-Z]{3,} 字母、数字、下划线: (?!^[a-zA-Z]+$)(?!^\d+$)(?!^_+$)[0-9a-zA-Z_]{3,}
9、练习题:正则表达式实现计算器的+ - * /运算
需求分析:
表达式 = 8*5-2+(10-(8*5+6)/10+5)*(3-2)+8*(9-4)
1、从前到后找,找到第一个以(开始)结尾,中间不含有括号的表达式
2、正则表达式:\([^()]\)
定义两个函数:
1、def 处理加减乘除(表达式):
return 结果
2、def 处理括号(表达式):
while True:
#先找到第一个,分割成三部分,得到括号内的表达式,不要括号
re.split('\( [^()] \)',表达式,1)
#8*5-2+(10- 8*5+6 /10+5)*(3-2)+8*(9-4)
ret = 加减乘除(8*5+6)
#再把表达式连起来
8*5-2+(10- ret /10+5)*(3-2)+8*(9-4)
#再返回给函数,知道没有括号,直接给运算函数,得到最终结果
import re
import sys
def no_bracket_rules(expression):
'''计算没有括号的乘除运算'''
md_check = re.search(r'\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*',expression)
if md_check:#乘除存在
#得到第一个*或/运算表达式
data = md_check.group()
if len(data.split("*")) > 1:# 当可以用乘号分割,证明有乘法运算
part1, part2 = data.split("*") # 用乘号分割
result = float(part1)*float(part2)
else:
part1, part2 = data.split("/")# 用除号分割
if part2 == 0:
sys.exit("计算过程中有被除数为0的存在,计算表达式失败!")
else:
result = float(part1) / float(part2)
# 获取第一个匹配到的乘除计算结果value,将value放回原表达式
# 以第一个*或/组成的表达式为界分割表达式
s1, s2 = re.split('\d+\.*\d*[\*\/]+[\+\-]?\d+\.*\d*', expression, 1)
# 将计算结果和剩下的表达式组合成新的字符串
new_exp = "%s%s%s" % (s1, result, s2)
return no_bracket_rules(new_exp)#递归表达式
else:#乘除不存在,在判断加减是否存在
expression = expression.replace('+-', '-') # 替换表达式里的所有'+-'
expression = expression.replace('--', '+') # 替换表达式里的所有'--'
expression = expression.replace('-+', '-') # 替换表达式里的所有'-+'
expression = expression.replace('++', '+') # 替换表达式里的所有'++'
as_check = re.search('\d+\.*\d*[\+\-]{1}\d+\.*\d*', expression)#匹配加减号
if not as_check: # 如果不存在加减号,则证明表达式已计算完成,返回最终结果
return expression
else:
#得到第一个+或-运算表达式
data = re.search('[\-]?\d+\.*\d*[\+\-]{1}\d+\.*\d*', expression).group()
if len(data.split("+")) > 1: #以加号分割成功,有加法计算
part1, part2 = data.split('+')
value = float(part1) + float(part2) # 计算加法
elif data.startswith('-'): # 如果是以'-'开头则需要单独计算,因为是负数
#分割为三部分,分别为'',正数,正数
part1, part2, part3 = data.split('-')
value = -float(part2) - float(part3) # 计算以负数开头的减法
else: #正数的减法运算
part1, part2 = data.split('-')
value = float(part1) - float(part2) # 计算减法
# 以第一个+或-分割表达式
s1, s2 = re.split('[\-]?\d+\.*\d*[\+\-]{1}\d+\.*\d*', expression, 1)
# 将计算后的结果替换回表达式,生成下一个表达式
new_exp = "%s%s%s" % (s1, value, s2)
return no_bracket_rules(new_exp) # 递归运算表达式
def bracket_rules(expression):
'''找到括号内的表达式,返回给计算函数'''
while True:
#验证表达式内是否含有以括号开始和结尾,且中间不含括号的
if re.findall(r"\(([^()]+)\)",expression):
# 找到第一个以(开始,以)结尾,且中间不含()的表达式
s_split = re.split(r"\(([^()]+)\)",expression,1)
ret = no_bracket_rules(s_split[1])#分割为三部分,中间为得到的表达式
# 将先前得到的表达式的计算结果和剩下的表达式组合成新的字符串
new_exp = "%s%s%s" % (s_split[0], ret, s_split[2])
return bracket_rules(new_exp)#返回函数,继续查找表达式
else:
#如果表达式内没有括号,就直接调用加减乘除函数进行计算
result = no_bracket_rules(expression)
return result
s = "8*5-2+(10-(8*5+6)/10+5)+6*(3-2)+8*9-4"
ret = bracket_rules(s)
print(ret)#122.4
configparser模块
-
configparser用于处理配置文件,其本质上是利用open来操作文件。每个节点相当于一个key,下面的键值对相当于value;
-
首先创建config对象,然后读取文件config.read(文件),写入文件config.write(文件)
[section1] # 节点 k1 = v1 # 值 k2:v2 # 值 [section2] # 节点 k1 = v1 # 值
1、获取所有节点
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.sections() print(ret)
2、获取指定节点下所有的键值对
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.items('section1') print(ret)
3、获取指定节点下所有的建
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.options('section1') print(ret)
4、获取指定节点下指定key的值
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') #get函数可以将得到的字符串转换为相应类型数据,前提是可以转 v = config.get('section1', 'k1') # v = config.getint('section1', 'k1')#转换为整数 # v = config.getfloat('section1', 'k1')#转换为浮点型 # v = config.getboolean('section1', 'k1')#转换为布尔值 print(v)
5、检查、删除、添加节点
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') # 检查 has_sec = config.has_section('section1') print(has_sec) # 添加节点 config.add_section("SEC_1") config.write(open('xxxooo', 'w')) # 删除节点 config.remove_section("SEC_1") config.write(open('xxxooo', 'w'))
6、检查、删除、设置指定组内的键值对
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') # 检查 has_opt = config.has_option('section1', 'k1') print(has_opt) # 删除 config.remove_option('section1', 'k1') config.write(open('xxxooo', 'w')) # 设置 config.set('section1', 'k10', "123") config.write(open('xxxooo', 'w'))
XML模块
1、浏览器返回的数据类型:
a.HTML
b.Json
c.XML(XML是实现不同语言或程序之间进行数据交换的协议)
- 页面上做展示(字符串类型,一个XML格式数据)
- 配置文件(文件类型,内部数据XML格式)
2、操作XML:XML格式类型是节点嵌套节点,对于每一个节点均有以下功能,以便对当前节点进行操作:
from xml.etree import ElementTree as ET # 直接解析XML文件 tree = ET.parse('xml_file\country.xml') # 获取xml文件的根节点 root = tree.getroot() #每一个节点都是一个Element对象 print(root)#<Element 'data' at 0x0000001E46461138> print(root.tag)#获取当前节点的名字 print(root.attrib)#获取当前节点的属性{'title': 'total', 'age': '12'} #遍历所有子节点,text获取节点中间的内容 for child in root: print(child.tag,'-',child.attrib) for grandchild in child: print(grandchild.tag, grandchild.text) # makeelement(tag,attrib)添加节点 # append(subelement)添加一个节点 # extend(elements)为当前节点扩展n个节点 # insert(index,subelement)为当前节点创建子节点,然后插入指定位置 # find(path)获取第一个寻找到的子节点 # findtext()获取第一个寻找到的子节点的内容 # findall(path)获取所有的子节点 # iterfind(path)获取所有子节点,并创建一个迭代器 # clear()清空所有节点 # get(key)获取当前节点的属性值 # print(root.attrib.get('title'))#total # keys()获取当前节点的所有属性的key # print(root.attrib.keys())#dict_keys(['title', 'age']) # items()获取当前节点的所有属性值,每个属性都是一个键值对 # print(root.attrib.items())# dict_items([('title', 'total'), ('age', '12')]) # iter()在当前节点的子节点中根据节点名称寻找所有指定节点,并返回一个迭代器 # itertext()在当前节点的子孙中根据节点名称寻找所有指定的节点的内容,并返回一个迭代器
3、由于修改节点时,均是在内存中进行,其不会影响文件中的内容,所以,如果想要保存文件,则需要重新将内存中的内容写到文件。
############ 解析方式一 ############ from xml.etree import ElementTree as ET # 利用ElementTree.parse将文件直接解析成XML对象 tree = ET.parse('xml_file\country.xml')#ElementTree类型 # 获取xml文件的根节点 root1 = tree.getroot()#element类型 #循环所有year节点,修改节点内容 for node in root1.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) #设置属性set(key,value) node.set("name","charlie") node.set("age","20") #删除属性 del del node.attrib["name"] #写入文件 tree.write(r'xml_file\country2.xml',encoding='utf-8') ############ 解析方式二 ############ # 利用ElementTree.XML将字符串解析成XML对象 str_xml = open('xml_file\country.xml', 'r').read() # 将字符串解析成xml特殊对象,root代指xml文件的根节点 root2 = ET.XML(str_xml)#element类型 #循环所有year节点,修改节点内容 for node in root2.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) #设置属性set(key,value) node.set("name","charlie") node.set("age","20") #删除属性 del del node.attrib["name"] #写入文件,只有ElementTree类型的对象有写入功能 tree = ET.ElementTree(root2) tree.write(r'xml_file\country3.xml',encoding='utf-8')
4、创建一个XML文件:<neighbor direction="W" name="Costa Rica" />如果节点没有内容,会进行自闭和
############ 创建方式一 ############ # #创建根节点 root_family = ET.Element('family') #创建大儿子 son1 = ET.Element('son',{'name':'大儿子'}) #创建小儿子 son2 = ET.Element('son',{'name':'小儿子'}) #在大儿子中创建两个孙子 grandson1 = ET.Element('grandson',{'name':'大孙子'}) grandson2 = ET.Element('grandson',{'name':'二孙子'}) son1.append(grandson1) son1.append(grandson2) #把儿子添加到根目录 root_family.append(son1) root_family.append(son2) #写入文件 family_tree = ET.ElementTree(root_family) family_tree.write(r'xml_file\family.xml',encoding='utf-8', xml_declaration=True,short_empty_elements=False) ############ 创建方式二 ############ # 创建大儿子 son1 = root.makeelement('son', {'name': '儿1'}) grandson1 = son1.makeelement('grandson',{'name':'大孙子'}) ########### 创建方式三 ############ #创建节点大儿子 son1 = ET.SubElement(root, "son", attrib={'name': '儿1'}) grandson1 = ET.SubElement(son1,'grandson',attrib={'name':'大孙子'})
5、由于原生保存的XML时默认无缩进,如果想要设置缩进的话,需要修改保存方式,所以先定义一个保存方式:
from xml.dom import minidom def prettify(elem): """将节点转换成字符串,并添加缩进。 """ rough_string = ET.tostring(elem, 'utf-8') reparsed = minidom.parseString(rough_string) return reparsed.toprettyxml(indent="\t") root_family = ET.Element('family') son1 = ET.Element('son',{'name':'大儿子'}) son2 = ET.Element('son',{'name':'小儿子'}) grandson1 = ET.Element('grandson',{'name':'大孙子'}) grandson2 = ET.Element('grandson',{'name':'二孙子'}) son1.append(grandson1) son1.append(grandson2) root_family.append(son1) root_family.append(son2) #调用方法写入文件 raw_str = prettify(root_family) f = open(r"xml_file\family.xml",'w',encoding='utf-8') f.write(raw_str) f.close()
shutil模块
1、文件、文件夹基本操作
import shutil #将文件内容拷贝到另一个文件中 shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w')) #拷贝文件 shutil.copyfile('f1.log', 'f2.log') #仅拷贝权限,内容、组、用户均不变 shutil.copymode('f1.log', 'f2.log') #仅拷贝状态的信息,包括:mode bits, atime, mtime, flags shutil.copystat('f1.log', 'f2.log') #拷贝文件和权限 shutil.copy('f1.log', 'f2.log') #拷贝文件和状态信息 shutil.copy2('f1.log', 'f2.log') #递归的去拷贝文件夹 shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #递归的去删除文件 shutil.rmtree('folder1') #递归的去移动文件,它类似mv命令,其实就是重命名。 shutil.move('folder1', 'folder3')
2、压缩文件操作
shutil.make_archive(base_name, format,...)创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录 import shutil ret = shutil.make_archive("wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test') #将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录 import shutil ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')
3、shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile # 压缩 z = zipfile.ZipFile('laxi.zip', 'w')#创建压缩文件 z.write('a.log')#添加单个压缩文件 z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('laxi.zip', 'r')#打开压缩包 z.namelist()#查看所有文件 z.extract(member)#解压单个文件 z.extractall()#解压所有文件 z.close()
import tarfile # 压缩 tar = tarfile.open('xml_file\your.tar','w') #可以通过arcname来修改文件在压缩包中的名字 tar.add(r'xml_file\family.xml', arcname='son.xml') tar.add(r'xml_file\country.xml', arcname='city.xml') tar.close() # 解压 tar = tarfile.open('your.tar','r') tar.getmembers()#获取压缩包所有成员,得到一个特殊对象 #解压单个成员,需要传递一个对象 obj = tar.getmember('text.py') tar.extract(obj) tar.extractall() # 可设置解压地址 tar.close()
subprocess 模块
1、call 、check_call、check_output
import subprocess #call执行命令,返回状态码 ret = subprocess.call(["ls", "-l"], shell=False) ret = subprocess.call("ls -l", shell=True) #check_call执行命令,如果执行状态码是 0 ,则返回0,否则抛异常 subprocess.check_call(["ls", "-l"]) subprocess.check_call("exit 1", shell=True) #check_output执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常 subprocess.check_output(["echo", "Hello World!"]) subprocess.check_output("exit 1", shell=True)
2、subprocess.Popen(...)用于执行复杂的系统命令
参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
- 所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。
- shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
- startupinfo与createionflags只在windows下有效
- 将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
#执行普通命令 import subprocess ret1 = subprocess.Popen(["mkdir","t1"]) ret2 = subprocess.Popen("mkdir t2", shell=True)
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
import subprocess obj = subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") obj.stdin.close() cmd_out = obj.stdout.read() obj.stdout.close() cmd_error = obj.stderr.read() obj.stderr.close() print(cmd_out) print(cmd_error)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") out_error_list = obj.communicate() print(out_error_list)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) out_error_list = obj.communicate('print("hello")') print(out_error_list)

