第四章笔记——并发编程
知识总结
本章中首先介绍了并行计算的发展历史和重要地位,分析了顺序算法与并行算法的区别;介绍了线程的概念以及线程的优缺点,介绍了如何进行线程操作;简短的介绍了线程同步和死锁的概念;引出了信号量、屏障等概念;最后举例了Linux中线程编程的实例。
并行计算:
要求解某个问题,先要设计一种算法,描述如何一步步地解决问题,然后用计算机程序以串行指令流的形式实现该算法。在只有一个CPU的情况下,每次只能按顺序执行某算法的一个指令和步骤。但是,基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。并行计算是一种计算方案,它尝试使用多个执行并行算法的处理器更快速地解决问题。
并行与顺序的差别:
begin-end代码块中的顺序算法可能包含多个步骤。所有步骤都是通过单个任务依次执行的,每次执行一个步骤。当所有步骤执行完成时,算法结束。相反,并行算法使用cobegin-coend代码块来指定并行算法的独立任务。在cobegin-coend块中,所有任务都是并行执行的。紧接着cobegin-coend代码块的下一个步骤将只在所有这些任务完成之后执行。
线程:
在进程模型中,进程是独立的执行单元。
所有进程均在内核模式或用户模式下执行。在内核模式下,各进程在唯一地址空间上执行,与其他进程是分开的。虽然每个进程都是一个独立的单元,但是它只有一个执行路径。
当某进程必须等待某事件时,例如 I/O完成事件,它就会暂停,整个进程会停止执行。线程是某进程同一地址空间上的独立执行单元。创建某个进程就是在一个唯一地址空间创建一个主线程。当某进程开始时,就会执行该进程的主线程。如果只有一个主线程,那么进程和线程实际上并没有区别。但是,主线程可能会创建其他线程。每个线程又可以创建更多的线程等。某进程的所有线程都在该进程的相同地址空间中执行,但每个线程都是一个独立的执行单元。在线程模型中,如果一个线程被挂起,其他线程可以继续执行。除了共享共同的地址空间之外,线程还共享进程的许多其他资源,如用户id、打开的文件描述符和信号等。打个简单的比方,进程是一个有房屋管理员(主线程)的房子。线程是住在进程房子里的人。房子里的每个人都可以独立做自己的事情,但是他们会共用一些公用设施,比如同一个信箱、厨房和浴室等。过去,大多数计算机供应商都是在自己的专有操作系统中支持线程。不同系统之间的实现有极大的区别。
线程的优点:
(1)线程创建和切换速度更快∶进程的上下文复杂而庞大。其复杂性主要来自管理进程映像的需要。例如,在具有虚拟内存的系统中。进程映像可能由叫作页面的许多内存单元组成。在执行过程中,有些页面在内存中,有些则不在内存中。操作系统内核必须使用多个页表和多个级别的硬件辅助来跟踪每个进程的页面。要想创建新的进程,操作系统必须为进程分配内存并构建页表。若要在某个进程中创建线程,操作系统不必为新的线程分配内存和创建页表。因为线程与进程共用同一个地址空间。所以创建线程比创建进程更快。
另外,由于以下原因,线程切换比进程切换更快。进程切换涉及将一个进程的复杂分页环境替换为另一个进程的复杂分页环境,需要大量的操作和时间。相比之下。同一个进程中的线程切换要简单得多、也快得多,因为操作系统内核只需要切换执行点,而不需要更改进程映像。
(2)线程的响应速度更快:一个进程只有一个执行路径。当某个进程被挂起时、整个进程都将停止执行。相反,当某个线程被挂起时,同一进程中的其他线程可以继续执行。这使得有多个线程的程序响应速度更快。例如,在一个多线程的进程中.当一个线程被阻塞以等待I/O时,其他线程仍可在后台进行计算。在有线程的服务器中,服务器可同时服务多个客户机。
(3)线程更适合并行计算∶并行计算的目标是使用多个执行路径更快地解决问题。基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性。可通过使用并行或并发执行来提高计算速度。这种算法通常要求执行实体共享公用数据。在进程模型中,各进程不能有效共享数据,因为它们的地址空间都不一样。为了解决这个问题,进程必须使用进程间通信(IPC)来交换数据或使用其他方法将公用数据区包含到其地址空间中。相反. 同一进程中的所有线程共享同一地址空间中的所有(全局)数据。因此,使用线程编写并行执行的程序比使用进程编写更简单、更自然。
线程的缺点:
(1)由于地址空间共享,线程需要来自用户的明确同步。
(2)许多库函数可能对线程不安全,例如传统 strtok()函数将一个字符串分成一连串令牌。通常,任何使用全局变量或依赖于静态内存内容的函数,线程都不安全。为了使库函数适应线程环境,还需要做大量的工作。
(3)在单CPU系统上,使用线程解决问题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
线程函数管理:
- 创建线程
- 使用pthread_create()函数
int pthread_create (pthread_t *pthread_id, pthread_attr_t *attr, void (func)(void *), void *arg);
如果成功则返回0,如果失败则返回错误代码。pthread_create()函数的参数为 - pthread_id是指向pthread_t类型变量的指针。它会被操作系统内核分配的唯一线程ID填充。在POSIX中,pthread_t是一种不透明的类型。程序员应该不知道不透明对象的内容,因为它可能取决于实现情况。线程可通过pthread_self()函数获得自己的ID。在 Linux 中,pthread_t类型被定义为无符号长整型,因此线程ID可以打印为%lu。
- attr是指向另一种不透明数据类型的指针,它指定线程属性,下面将对此进行更详细的说明。
- func是要执行的新线程函数的入口地址。 arg是指向线程函数参数的指针,可写为:void *func(void *arg)
- attr参数
(1)定义一个pthread属性变量pthread_attr_t attr。
(2)用pthread_attr_init (&attr)初始化属性变量。
(3)设置属性变量并在pthread_create()调用中使用。
(4)必要时,通过pthread_attr_destroy (&attr)释放attr资源。
-
线程ID
线程ID是一种不透明的数据类型,取决于实现情况。因此,不应该直接比较线程ID。如果需要,可以使用
pthread_equal()函数对它们进行比较。
int pthread_equal (pthread_t t1, pthread_t t2);
如果是不同的线程,则返回0,否则返回非0。 -
线程终止
线程函数结束后,线程即终止。或者,线程可以调用函数int pthread_exit (void *status);
进行显式终止,其中状态是线程的退出状态。通常,0退出值表示正常终止,非0值表示异常终止。 -
线程连接
一个线程可以等待另一个线程的终止,通过:
int pthread_join (pthread_t thread, void **status ptr);终止线程的退出状态以status_ptr返回。
线程同步
- 互斥量
最简单的同步工具是锁,它允许执行实体仅在有锁的情况下才能继续执行。在Pthread中,锁被称为互斥量。在使用之前必须对他们进行初始化。
- 静态方法
点击查看代码
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER
- 动态方法
点击查看代码
pthread_mutex_init(pthread_mutex_t *m,pthread_mutexattr_t,*attr);
有多种方法可以解决可能的死锁问题,其中包括死锁预防、死锁规避、死锁检测和恢复等。
在实际系统中,唯一可行的方法是死锁预防,试图在设计并行算法时防止死锁的发生。一种简单的死锁预防方法是对互斥量进行排序,并确保每个线程只在一个方向请求互斥量,这样请求序列中就不会有循环。

- 条件变量:
作为锁,互斥量仅用于确保线程只能互斥地访问临界区中的共享数据对象。条件变量提供了一种线程协作的方法。在Pthread中,使用类型pthread_cond_t来声明条件变量,而且必须在使用前进行初始化。
使用pthread_cond_init()函数,通过attr参数设置条件变量。
在互斥量的临界区中,线程可通过以下函数使用条件变量来相互协作。
pthread_cond_wait(conditlon,mutex):该函数会阻塞调用线程,直到发出指定条件的信号。当互斥量被加锁时、应调用该例程。它会在线程等待时自动释放互斥量。互斥量将在接收到信号并唤醒阻塞的线程后自动锁定。
pthread cond signal(condition);该函数用来发出信号,即唤醒正在等待条件变量的线程或解除阻塞。它应在互斥量被加锁后调用,而且必须解锁互斥量才能完成pthread_cond_wait ()。
pthread cond broadcast(condition)∶该函数会解除被阻塞在条件变量上的所有线程阻塞。所有未阻塞的线程将争用同一个互斥量来访问条件变量。它们的执行顺序取决于线程调度。
编程实践
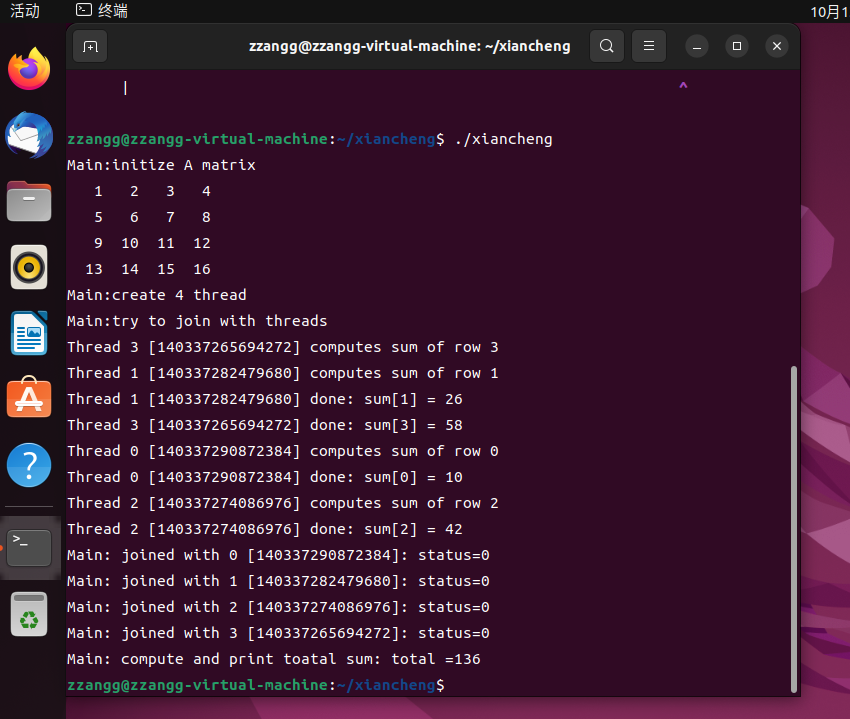
用线程计算矩阵的和
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define N 4
int A[N][N], sum[N];
void *func(void *arg){
int j,row;
pthread_t tid = pthread_self();
row = (int)arg;
printf("Thread %d [%lu] computes sum of row %d\n",row,tid,row);
for (j=0;j<N;j++)
sum[row]+=A[row][j];
printf("Thread %d [%lu] done: sum[%d] = %d\n",row,tid,row,sum[row]);
pthread_exit((void *)0);
}
int main(int argc,char *argv[]){
pthread_t thread[N];
int i,j,r,total=0;
void *status;
printf("Main:initize A matrix\n");
for (i=0;i<N;i++){
sum[i]=0;
for(j=0;j<N;j++){
A[i][j] = i*N +j+1;
printf("%4d",A[i][j]);
}
printf("\n");
}
printf("Main:create %d thread\n",N);
for(i=0;i<N;i++){
pthread_create(&thread[i],NULL,func, (void *)i);
}
printf("Main:try to join with threads\n");
for(i=0;i<N;i++){
pthread_join(thread[i],&status);
printf("Main: joined with %d [%lu]: status=%d\n",i,thread[i],(int)status);
}
printf("Main: compute and print toatal sum: ");
for(i=0;i<N;i++)
total+=sum[i];
printf("total =%d\n",total);
pthread_exit(NULL);
}
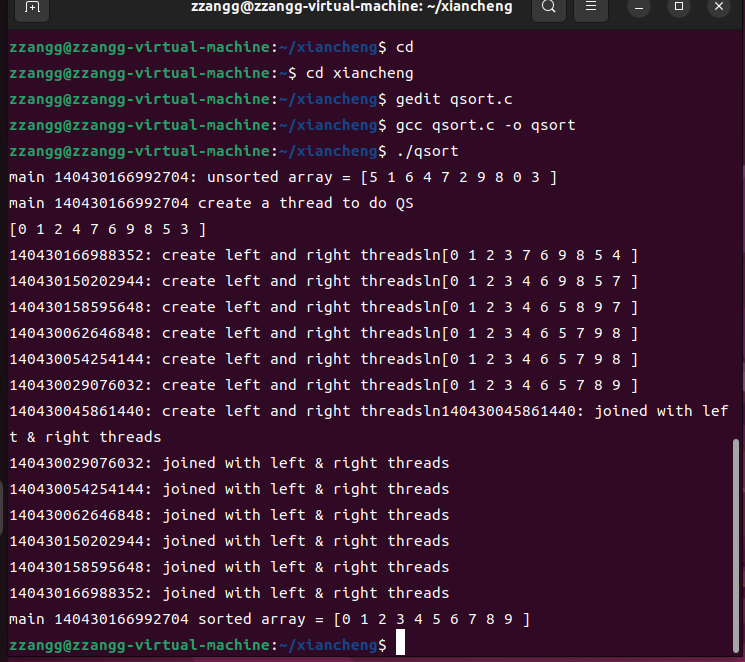
用线程快速排序
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
typedef struct{
int upperbound;
int lowerbound;
}PARM;
#define N 10
int a[N]={5,1,6,4,7,2,9,8,0,3};
int print(){//print current a[] contents
int i;
printf("[");
for(i=0;i<N;i++)
printf("%d ",a[i]);
printf("]\n");
}
void *Qsort(void *aptr){
PARM *ap, aleft, aright;
int pivot, pivotIndex,left, right,temp;
int upperbound,lowerbound;
pthread_t me,leftThread,rightThread;
me = pthread_self();
ap =(PARM *)aptr;
upperbound = ap->upperbound;
lowerbound = ap->lowerbound;
pivot = a[upperbound];//pick low pivot value
left = lowerbound - 1;//scan index from left side
right = upperbound;//scan index from right side
if(lowerbound >= upperbound)
pthread_exit (NULL);
while(left < right){//partition loop
do{left++;} while (a[left] < pivot);
do{right--;}while(a[right]>pivot);
if (left < right ) {
temp = a[left];a[left]=a[right];a[right] = temp;
}
}
print();
pivotIndex = left;//put pivot back
temp = a[pivotIndex] ;
a[pivotIndex] = pivot;
a[upperbound] = temp;
//start the "recursive threads"
aleft.upperbound = pivotIndex - 1;
aleft.lowerbound = lowerbound;
aright.upperbound = upperbound;
aright.lowerbound = pivotIndex + 1;
printf("%lu: create left and right threadsln", me) ;
pthread_create(&leftThread,NULL,Qsort,(void * )&aleft);
pthread_create(&rightThread,NULL,Qsort,(void *)&aright);
//wait for left and right threads to finish
pthread_join(leftThread,NULL);
pthread_join(rightThread, NULL);
printf("%lu: joined with left & right threads\n",me);
}
int main(int argc, char *argv[]){
PARM arg;
int i, *array;
pthread_t me,thread;
me = pthread_self( );
printf("main %lu: unsorted array = ", me);
print( ) ;
arg.upperbound = N-1;
arg. lowerbound = 0 ;
printf("main %lu create a thread to do QS\n" , me);
pthread_create(&thread,NULL,Qsort,(void * ) &arg);//wait for Qs thread to finish
pthread_join(thread,NULL);
printf ("main %lu sorted array = ", me);
print () ;
}