hive join 优化
common join : 即reducer join,瓶颈在shuffle阶段,会产生较大的网络io;
map join:即把小表放前面,扫描后放入每个节点的内存,在map阶段进行匹配;
开启map join:
set hive.auto.convert.join = true;
hive.mapjoin.smalltable.filesize 默认值是25mb
执行时任务信息:

当两个表都很大时,采用cluster sort join:
懒的敲了: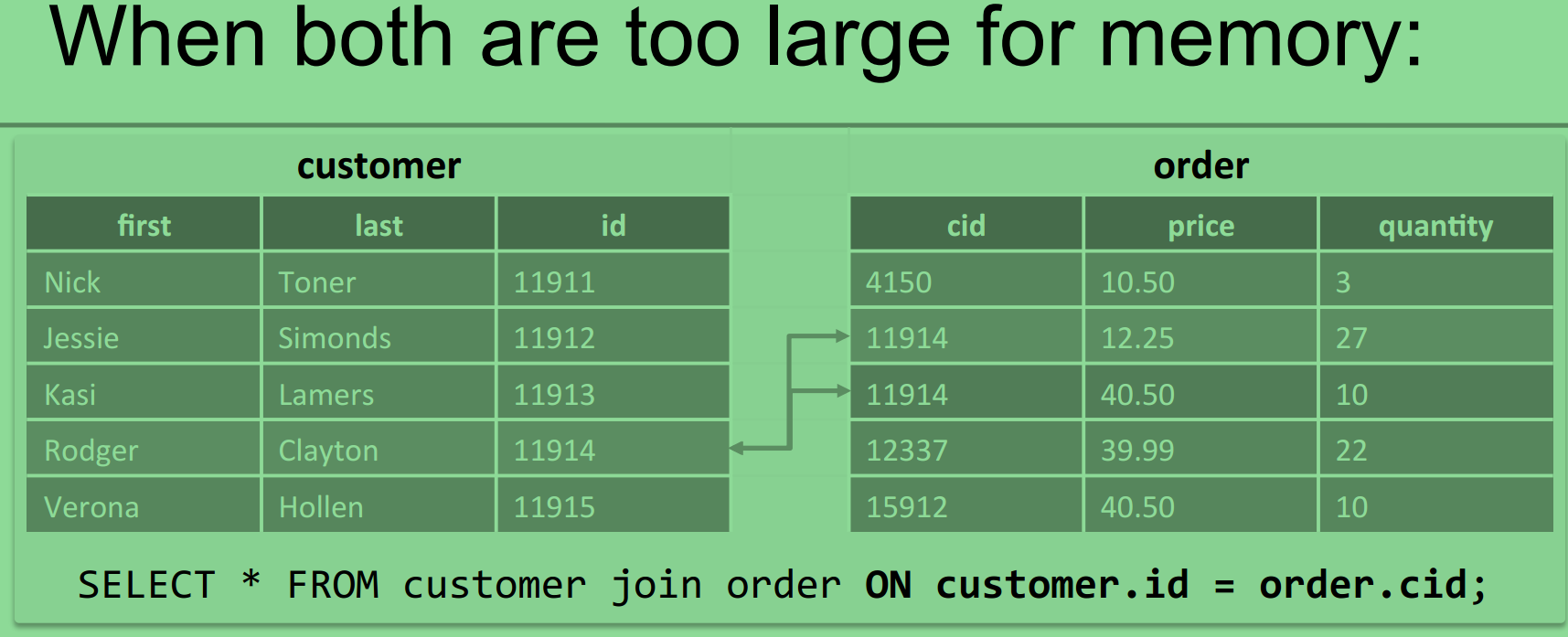
实现:
优点:

采用hint实现: explain select /*+mapjoin(b)*/ a.test1,b.provincecode, a.test3, a.test4, a.test5 from test_libc_x a join (select * from tbl_zone) b on (a.test2=b.provincename);
验证:执行计划中出现字样: