
来几道大数据的面试题吧
http://www.cnblogs.com/CheeseZH/p/5283390.html
这个思路还是正确的:
首先处理大数据的面试题,有些基本概念要清楚:
(1)1Gb = 109bytes(1Gb = 10亿字节):1Gb = 1024Mb,1Mb = 1024Kb,1Kb = 1024bytes;
(2)基本流程是,分解大问题,解决小问题,从局部最优中选择全局最优;(当然,如果直接放内存里就能解决的话,那就直接想办法求解,不需要分解了。)
(3)分解过程常用方法:hash(x)%m。其中x为字符串/url/ip,m为小问题的数目,比如把一个大文件分解为1000份,m=1000;
(4)解决问题辅助数据结构:hash_map,Trie树,bit map,二叉排序树(AVL,SBT,红黑树);
(5)top K问题:最大K个用最小堆,最小K个用最大堆。(至于为什么?自己在纸上写个小栗子,试一下就知道了。)
(6)处理大数据常用排序:快速排序/堆排序/归并排序/桶排序
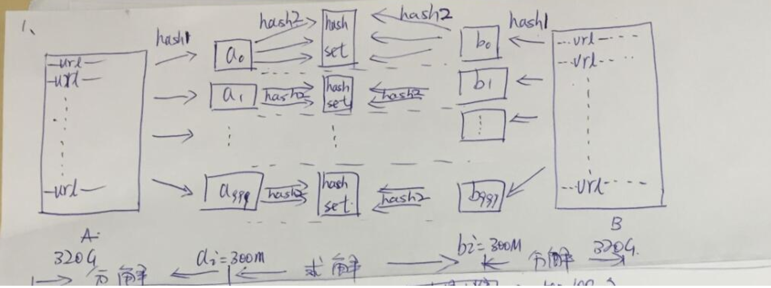
1. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
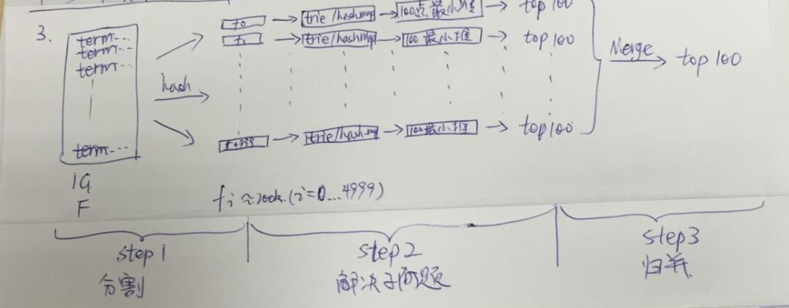
2. 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M,要求返回频数最高的100个词。
其实看这里,用Spark来处理: 《Spark实践 & spark-submit map/filter演示程序 & 计算词频示例》
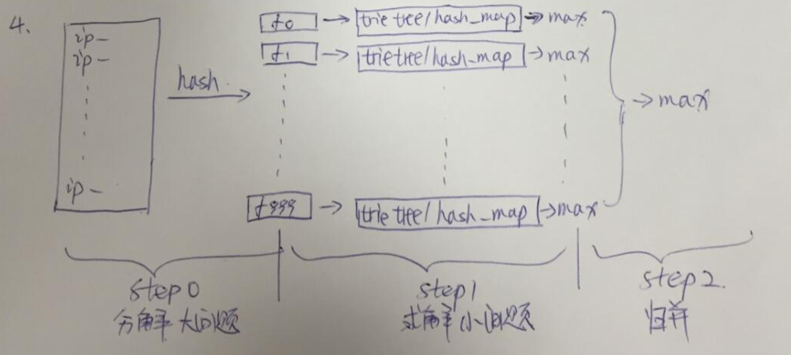
3. 现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP。
用Spark也可以,但是需要排序。
Spark里面有sortBy sortByKey等函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号