
在单机Hadoop上面增加Slave
之前的文章已经介绍了搭建单机Hadoop, HBase, Hive, Spark的方式:link
现在希望在单机的基础上,加一个slave。
首先需要加上信任关系,加信任关系的方式,见前一篇文章:link
把05和06这两台机器,分别和对方添加上信任关系。
把05上面的目录 /home/work/data/installed/hadoop-2.7.3/ 拷贝到06机器,
把 etc/hadoop 里面的 IP 10.117.146.12 都改成 11
然后06机器 要安装 jumbo 和 Java1.8
安装好之后,JAVA_HOME应该和05机器上配置的一样:
export JAVA_HOME=/home/work/.jumbo/opt/sun-java8
另外要创建这个目录 /home/work/data/hadoop/dfs
然后启动下面这些服务:
首先格式化hdfs:
./bin/hdfs namenode -format myclustername 16/11/04 16:00:44 INFO util.ExitUtil: Exiting with status 0
在slave上面要部署的服务有 datanode, node_manager(没有namenode)
启动datanode
$ ./sbin/hadoop-daemon.sh --script hdfs start datanode starting datanode, logging to /home/work/data/installed/hadoop-2.7.3/logs/hadoop-work-datanode-gzns-ecom-baiduhui-201605-m42n06.gzns.baidu.com.out
启动node manager
$ ./sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /home/work/data/installed/hadoop-2.7.3/logs/yarn-work-nodemanager-gzns-ecom-baiduhui-201605-m42n06.gzns.baidu.com.out
在master上面增加slave (etc/hadoop/slaves) :
localhost 10.117.146.11
然后看下master的几个管理平台:
Overview: http://10.117.146.12:8305
Yarn: http://10.117.146.12:8320
Job History: http://10.117.146.12:8332/jobhistory
Spark:http://10.117.146.12:8340/
上网搜了一个,用root帐号将两台机器的 /etc/hosts都改成了
127.0.0.1 localhost.localdomain localhost 10.117.146.12 master.Hadoop 10.117.146.11 slave1.Hadoop 以下一样: 127.0.0.1 localhost.localdomain localhost 10.117.146.12 master.Hadoop 10.117.146.11 slave1.Hadoop
然后把 etc/hadoop/slaves里的内容都改成:
slave1.Hadoop
加了一个文件 etc/hadoop/masters
master.Hadoop
但是,还是始终发现master和slave是各自独立的,然后在slave上起了namenode 和 yarn之后,slave就知看到自己一个live node了。
看了一下,把所有的服务都停掉,看是否能用 ./sbin/start-all.sh ,跑了一下,发现有提示输入 work@localhost密码的,然后grep了一下localhost,发现在core-site.xml有localhost的配置:
<name>fs.defaultFS</name> <value>hdfs://localhost:8390</value>
感觉需要把slave的这里也改掉。然后试了一下,把master和slave的这个地方都改成如下:
<name>fs.defaultFS</name> <value>hdfs://master.Hadoop:8390</value>
然后,在slave启动datanode报错,错误日志:
2016-11-04 17:44:39,160 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/work/data/hadoop/dfs/data/ java.io.IOException: Incompatible clusterIDs in /home/work/data/hadoop/dfs/data: namenode clusterID = CID-9808571a-21c3-4aeb-a114-19b99b4722d2; datanode clusterID = CID-c2a59c40-0a4b-4aba-bbab-31ec15b8d64d
貌似是namenode和datanode冲突了。用 rm -rf /home/work/data/hadoop/dfs/data/ 把data node目录整体删掉。
重新启动master上面的所有服务。
然后在slave上面重新启动datanode:
./sbin/hadoop-daemon.sh --script hdfs start datanode
在日志里能看到heartbeat的内容,看起来通信成功了。
再打开master的管理界面:
http://10.117.146.12:8305/dfshealth.html 能够看到两台node了:
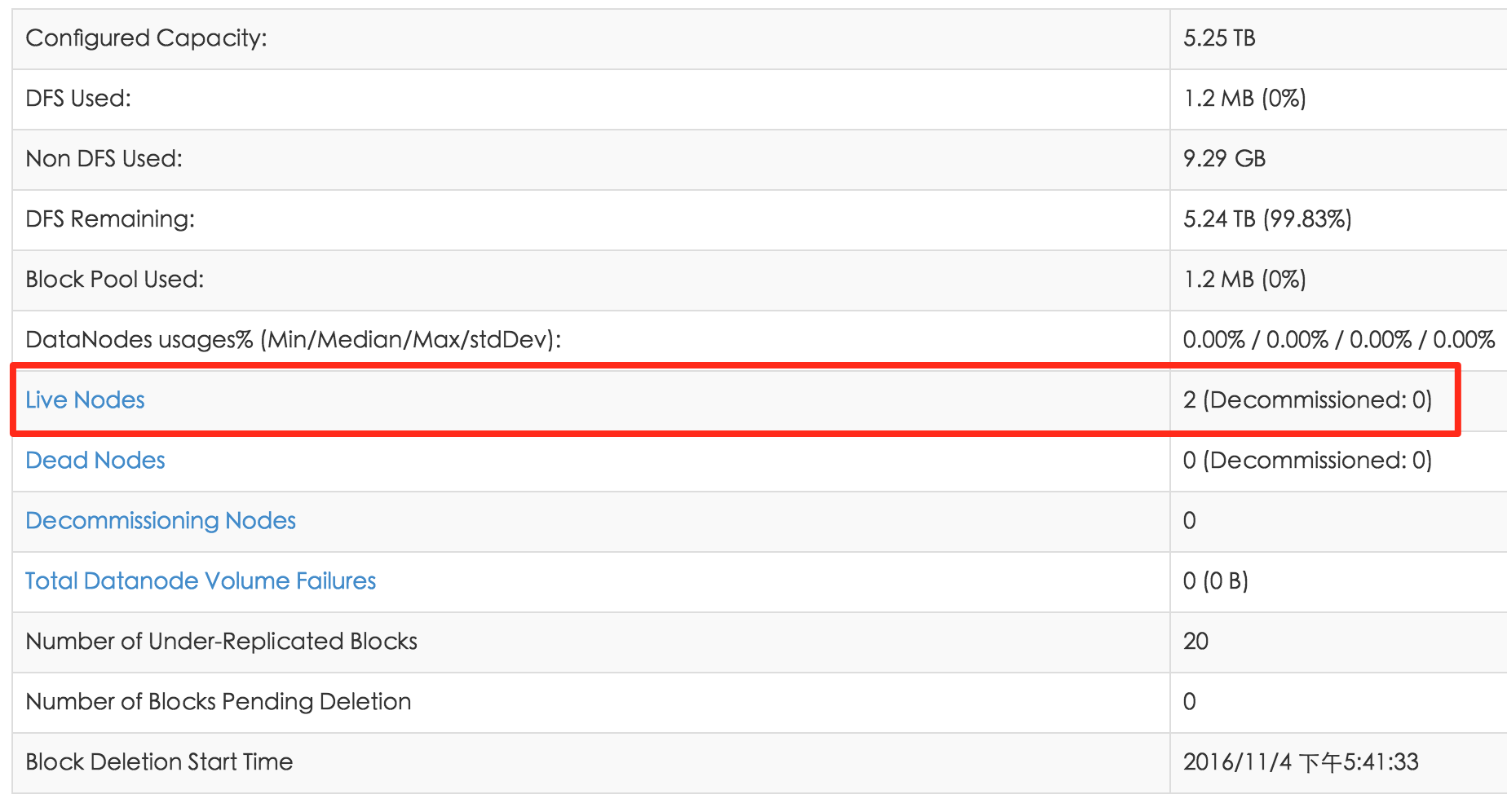
现在再把slave的node manager也启动:
$ ./sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /home/work/data/installed/hadoop-2.7.3/logs/yarn-work-nodemanager-gzns-ecom-baiduhui-201605-m42n06.gzns.baidu.com.out
然后观察下管理界面的各个指标。
发现yarn里面还是只看到一台机器。感觉还是配置的地方有问题。
首先master和slave的配置应该是一样的。改了如下的地方:
hdfs-site.xml
<property>
<name>dfs.namenode.http-address</name>
<value>master.Hadoop:8305</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.Hadoop:8310</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.Hadoop:8330</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.Hadoop:8332</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.Hadoop</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.Hadoop:8320</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master.Hadoop:8325/jobhistory/logs/</value>
</property>
然后重启master和slave的所有服务。
启动完成之后,在以上各个管理界面能够正常看到两个节点啦。
http://10.117.146.12:8305/dfshealth.html#tab-overview
http://10.117.146.12:8332/jobhistory
http://10.117.146.12:8320/cluster/nodes
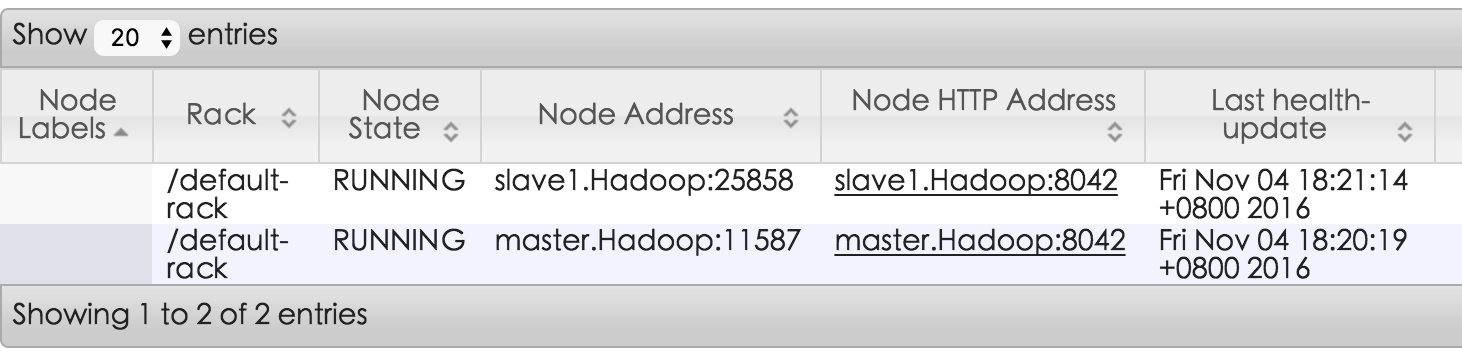
跑一条命令试试:
$ ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar -input /input -output /output -mapper cat -reducer wc packageJobJar: [/tmp/hadoop-unjar8343786587698780884/] [] /tmp/streamjob8627318309812657341.jar tmpDir=null 16/11/04 18:21:44 INFO client.RMProxy: Connecting to ResourceManager at master.Hadoop/10.117.146.12:8032 16/11/04 18:21:45 INFO client.RMProxy: Connecting to ResourceManager at master.Hadoop/10.117.146.12:8032 16/11/04 18:21:45 ERROR streaming.StreamJob: Error Launching job : Output directory hdfs://master.Hadoop:8390/output already exists Streaming Command Failed!
发现失败。要删除output目录,但是像以前那样删不行,要加上hdfs的前缀:
$ ./bin/hadoop fs -rm output rm: `output': No such file or directory $ ./bin/hadoop fs -rm -r hdfs://master.Hadoop:8390/output 16/11/04 18:22:54 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted hdfs://master.Hadoop:8390/output
然后重新跑:
$ ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar -input /input -output /output -mapper cat -reducer wc 命令成功 $ ./bin/hadoop fs -ls hdfs://master.Hadoop:8390/output Found 2 items -rw-r--r-- 3 work supergroup 0 2016-11-04 18:32 hdfs://master.Hadoop:8390/output/_SUCCESS -rw-r--r-- 3 work supergroup 25 2016-11-04 18:32 hdfs://master.Hadoop:8390/output/part-00000 $ ./bin/hadoop fs -cat hdfs://master.Hadoop:8390/output/part-00000 5 5 15
得到了结果。也不太看的出来是哪台机器上跑的。
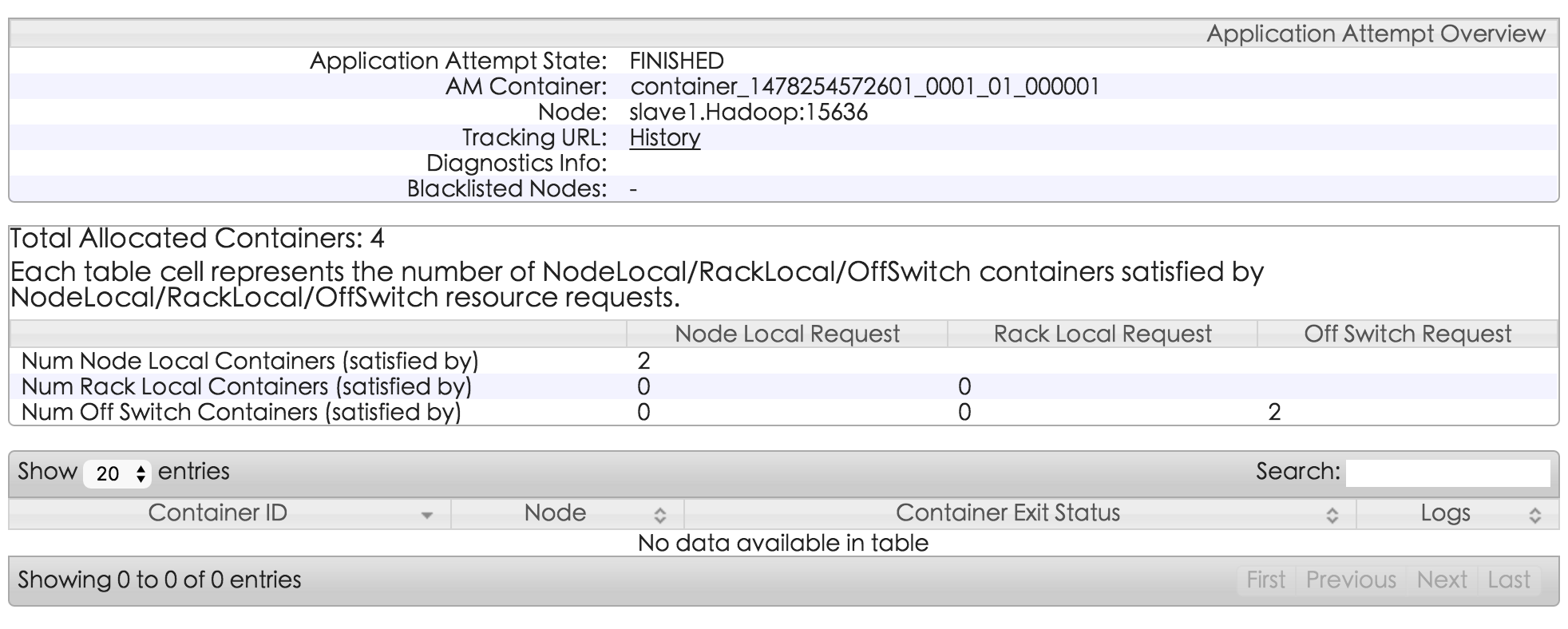

 浙公网安备 33010602011771号
浙公网安备 33010602011771号