
Contextual Bandit(LinUCB)
https://zhuanlan.zhihu.com/p/35753281
参考这篇文章。这篇还是讲得不错的。
推荐系统选择商品展现给用户,并期待用户的正向反馈(点击、成交)。然而推荐系统并不能提前知道用户在观察到商品之后如何反馈,也就是不能提前获得本次推荐的收益,唯一能做的就是不停地尝试,并实时收集反馈以便更新自己试错的策略。目的是使得整个过程损失的收益最小。
多臂赌博机问题(Multi-armed bandit problem, MAB)。
Bandit算法是一类用来实现Exploitation-Exploration机制的策略。根据是否考虑上下文特征,Bandit算法分为context-free bandit和contextual bandit两大类。
Context-free Bandit算法有很多种,比如 、softmax、Thompson Sampling、UCB(Upper Confidence Bound)等。
UCB这样的context-free类算法,忽略了用户作为一个个活生生的个体本身的兴趣点、偏好、购买力等因素都是不同的。

LinUCB是处理Contextual Bandit的一个方法,在LinUCB中,设定每个arm的期望收益为该arm的特征向量(context)的线性函数,如下:
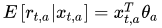

LinUCB与相对于传统的在线学习(online learning)模型(比如ftrl)相比,主要有2点区别:
- 每个arm学习一个独立的模型(context只需要包含user-side和user-arm interaction的特征,不需要包含arm-side特征);而传统在线学习为整个业务场景学习一个统一的模型
- 传统的在线学习采用贪心策略,尽最大可能利用已学到的知识,没有exploration机制(贪心策略通常情况下都不是最优的);LinUCB则有较完善的E&E机制,关注长期整体收益
在我们的电商平台App首页,有一个商品瀑布流推荐场景,每次大概展示30个商品左右。商品候选集都是运营人工精选的历史销售情况较好,在更多流量刺激下有可能成为爆款的商品,并且每天都会汰换掉一部分,加入一些新品进来。
通过实现LinUcb算法,系统会对每个商品做充分的exploration和exploitation,从而发掘出真正有销售潜力的商品,逐渐淘汰掉不够理想的商品,纠正运营人工选品的局限。经过考验的商品,说明在一段时间内销量还是不错的,这些商品运营可以深度控价,要求商家提供更多的优惠和让利给用户,从而形成良性循环,同时也给其他商家树立标杆,促进平台更加健康地发展。
业务效果
经过线上充分的A/B测试,最终测得LinUCB算法的UV CTR相对基准桶提升25%+,UV价值提升20%+。并且算法能够很好地支持商品动态上下架。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号