
一些杂七杂八文章的记录
https://mp.weixin.qq.com/s/SCFzFIshY9a2wdsPnfffVA
从美团这篇推荐文章里看看一些信息
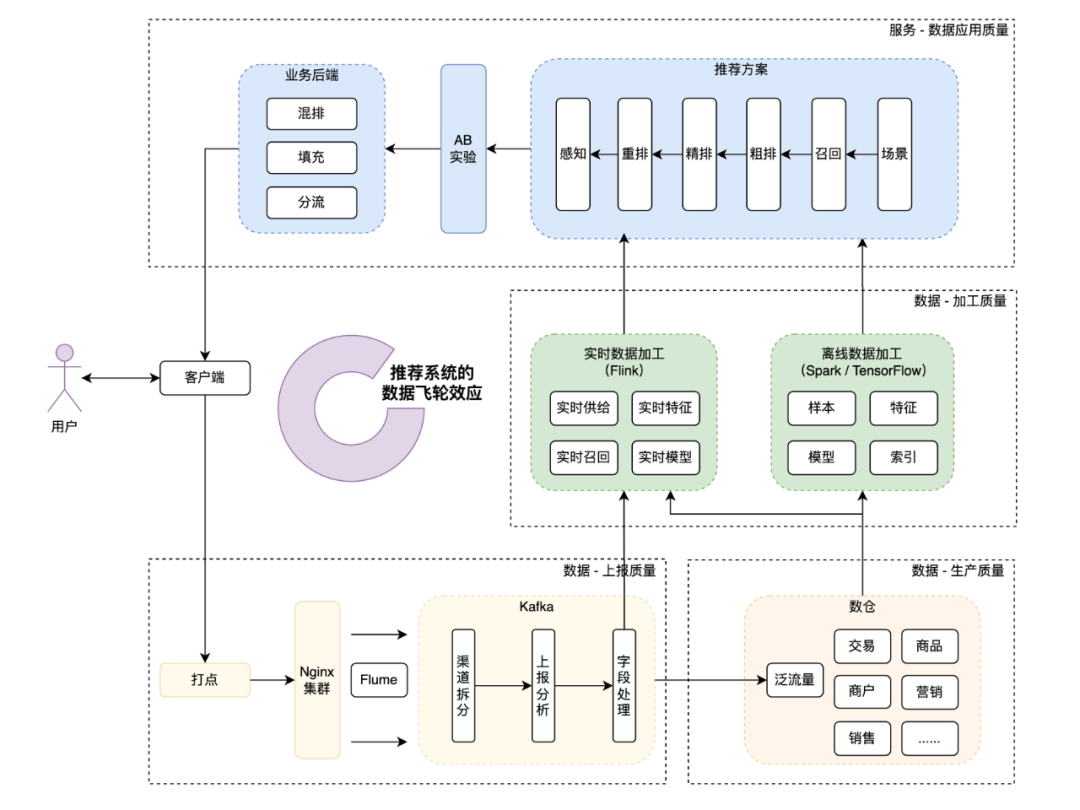
https://mp.weixin.qq.com/s/axgC09tpzx2p4tb0p7-fPA
NLP 的 不可能三角
对模型规模(缺 P1):
- 一般在超大模型显示出极好的 zero/few-shot 能力和微调后强大的性能时发生。
- 常用的方法是「知识蒸馏」。
- 有两个问题:学生模型几乎不能达到教师模型的效果;模型太大会阻碍有效推理,使其作为教师模型不方便。
对较差的 zero/few-shot 能力(缺 P2):
- 这是中等模型较为常见的:可以通过微调达到 SOTA,但 zero/few-shot 能力相对不足。
- 方法是「通过其他模型生成伪标签和样例,或噪声注入扩充数据」。
- 不过,伪数据质量的变化和不同任务中数据类型的多样性对普遍适用的解决方案提出了挑战。
对较差的有监督训练表现(缺 P3):
- 这在超大模型微调时很典型,其中计算资源有限或训练数据量不足以对其进行微调。
- 典型的策略是「Prompt 学习」,可以使用硬提示(离散文本模板)或软提示(连续模板),以便在微调期间仅更新硬提示词或软提示的参数。
- 不过,该方法对 Prompt 的选择和训练数据格外敏感,依然不如中等大小 PLM(预训练语言模型) + 有监督。
https://mp.weixin.qq.com/s/S8um7f8hz1sdBFCWQccs1g
《知识图谱和NLP的入门建议》
没什么有用的东西。
https://blog.csdn.net/weixin_42392454/article/details/109891791
MAML Model-Agnostic Meta-Learning 元学习
小样本学习
要解决的问题
- 小样本问题
- 模型收敛太慢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号