
DSSM的一些题目
DSSM中的负样本为什么是随机采样得到的,而不用“曝光未点击”当负样本?
召回是将用户可能喜欢的item,和用户根本不感兴趣的海量item分离开来,他面临的数据环境相对于排序来说是鱼龙混杂的。
所以我们希望召回训练数据的正样本是user和item匹配度最高的那些样本,也即用户点击样本,负样本是user和item最不匹配的那些样本,但不能拿“曝光未点击”作为召回模型的负样本,因为我们从线上日志获得的训练样本,已经是上一版本的召回、粗排、精排替用户筛选过的,即已经是对用户“匹配度较高”的样本了,即推荐系统以为用户会喜欢他们,但用户的行为又表明的对他的嫌弃。拿这样的样本训练出来的模型做召回,并不能与线上环境的数据分布保持一致。也就是说曝光未点击既不能成为合格的正样本,也不能成为合格的负样本。
所以一般的做法是拿点击样本做正样本,拿随机采样做负样本,因为线上召回时,候选库里大多数的物料是与用户没有关系的,随机抽样能够很好地模拟这一分布。
请简述一下DSSM的优缺点
先说说 DSSM 模型的优点:
- 解决了 LSA、LDA、Autoencoder 等方法存在的字典爆炸问题,从而降低了计算复杂度。因为英文中词的数量要远远高于字母 n-gram 的数量;
- 中文方面使用字作为最细切分粒度,可以复用每个字表达的语义,减少分词的依赖,从而提高模型的泛化能力;
- 字母的 n-gram 可以更好的处理新词,具有较强的鲁棒性;
- 使用有监督的方法,优化语义 embedding 的映射问题;
- 省去了人工特征工程;
- 采用有监督训练,精度较高。传统的输入层使用 embedding 的方式(比如 Word2vec 的词向量)或者主题模型的方式(比如 LDA 的主题向量)做词映射,再把各个词的向量拼接或者累加起来。由于 Word2vec 和 LDA 都是无监督训练,会给模型引入误差。
再说说 DSSM 模型的缺点:
- Word Hashing 可能造成词语冲突;
- 采用词袋模型,损失了上下文语序信息。这也是后面会有 CNN-DSSM、LSTM-DSSM 等 DSSM 模型变种的原因;
- 搜索引擎的排序由多种因素决定,用户点击时 doc 排名越靠前越容易被点击,仅用点击来判断正负样本,产生的噪声较大,模型难以收敛;
- 效果不可控。因为是端到端模型,好处是省去了人工特征工程,但是也带来了端到端模型效果不可控的问题。
介绍一下DSSM和他的损失函数
2013年由微软提出,用于信息检索,具体的应用场景可以是搜索引擎的排序,根据query去寻找最相似的documents(论文中的验证数据为query-title对)。与主题模型不同,DSSM是一个监督模型。
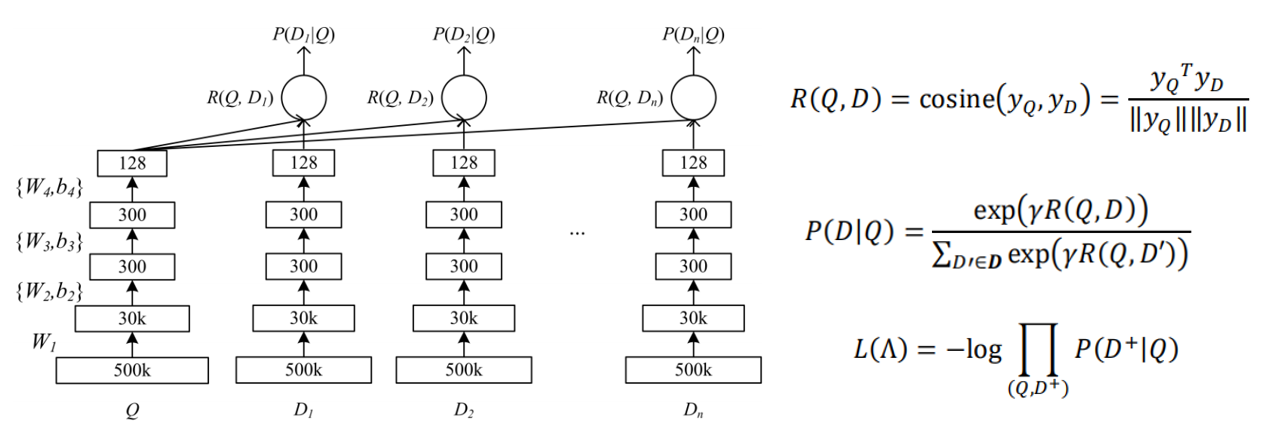
其损失函数的构建过程为:
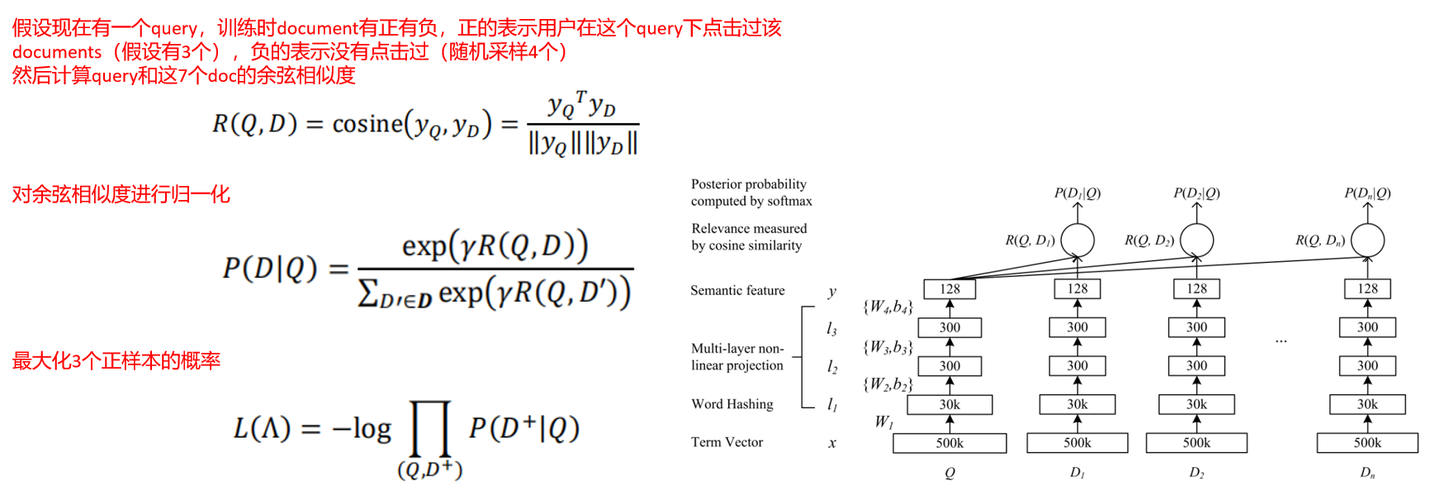
使用SGD进行优化。
DSSM正负样本如何构建
每个query对应几个正样本,随机再采样4个没点击的负样本
DSSM是如何解决输入稀疏的
使用word hashing,可以将高维的bag-of-words转为更低维度的向量,可能会稍有hash冲突。
DSSM如何做推理
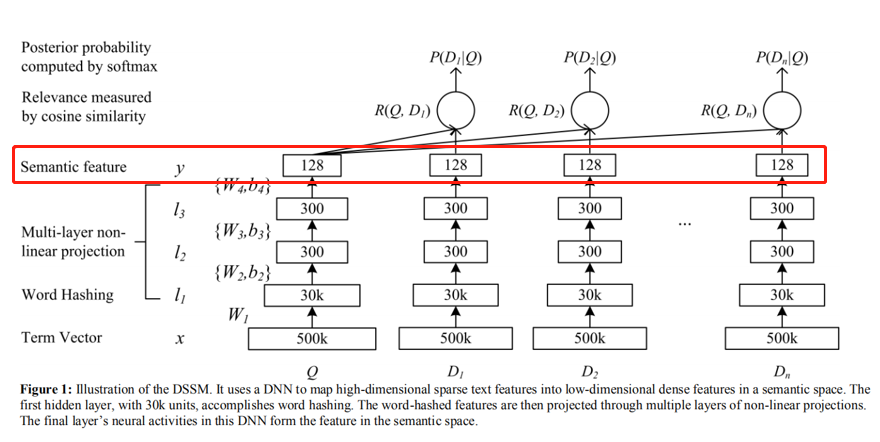
训练好的模型可以计算出所有doc的语义特征,先进行存储。
当有新的query的时候,就直接生成对应的语义特征,然后计算和全量doc的余弦相似度,然后倒排展示,期间可以使用facebook的fasis加速索引过程。
DSSM的缺点
词袋表示法:没有考虑上下文的特征,难以捕获文本的真正意图。可以考虑CLSM之类的模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号