
多任务学习算法在推荐系统中的应用
今天学习这篇文章:
https://zhuanlan.zhihu.com/p/441233636
有了预估的CTR和CVR之后,我们就可以按照如下公式来对候选商品排序:
1. 模型选择
通过前文的分析,我们确定了要在统一模型中同时建模CTR预估和CVR预估,这么做一个明显的好处是在推荐链路上只需要一个精排model,而不需要串联两个精排model。因此我们需要一个多任务学习模型。
Multi-Task Learning (MTL) is a learning paradigm in machine learning and its aim is to leverage useful information contained in multiple related tasks to help improve the generalization performance of all the tasks.
多任务学习之所以能改善各个任务单独建模的效果,是因为以下几个原因:
- 隐式数据增强。为某任务训练模型,目标是为该任务学习一个好的特征表示,然而通常训练数据中或多或少都包含一些噪音,只学习当前任务会面临过拟合的风险,如果同时学习多个任务则可以通过平均化不同任务的噪音得到一个适用于多个任务的更好的表示。
- 注意力聚焦。如果某任务的训练数据噪音很多,或者训练数据有限,并且特征维数很高,则模型很难区分相关特征与不相关特征。MTL能够帮助模型把注意力聚焦到真正有用的特征上,因为其他学习任务可以提供额外的证据。
- 窃听。一些特征在任务A上很难被学习,而在任务B上很容易被学习。可能的原因是在任务A与该特征存在更加复杂的交互关系,或者其他特征影响了模型学习这些特征的能力。
- 表示偏置。每个机器学习模型都存在某种程度的归纳偏置,MTL的归纳偏置是偏好那些适用于多个任务的特征表示。
- 正则化。MTL相当于给各个子任务添加了正则项参数约束,可以防止过拟合。
这里介绍几个常用的多目标排序模型:NavieMultiTask,ESMM,MMoE,DBMTL,PLE。
NavieMultiTask
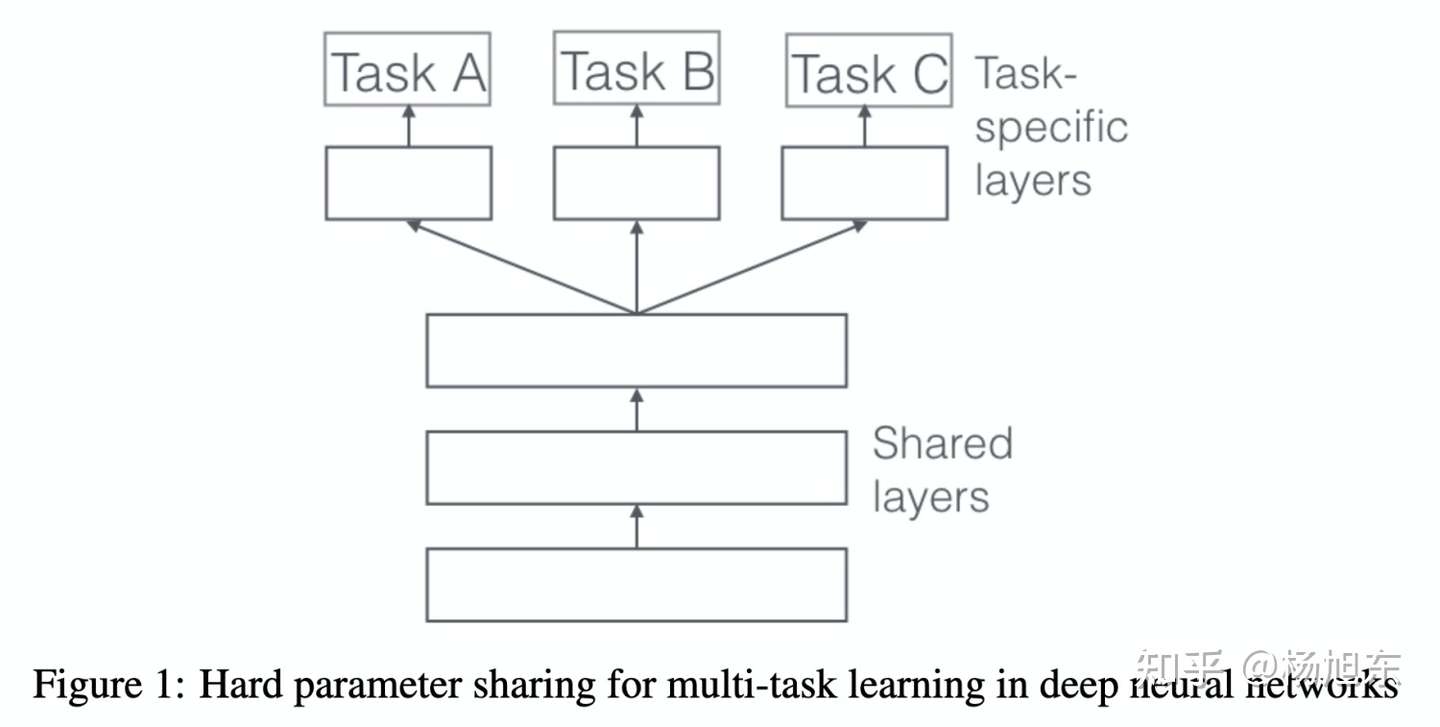
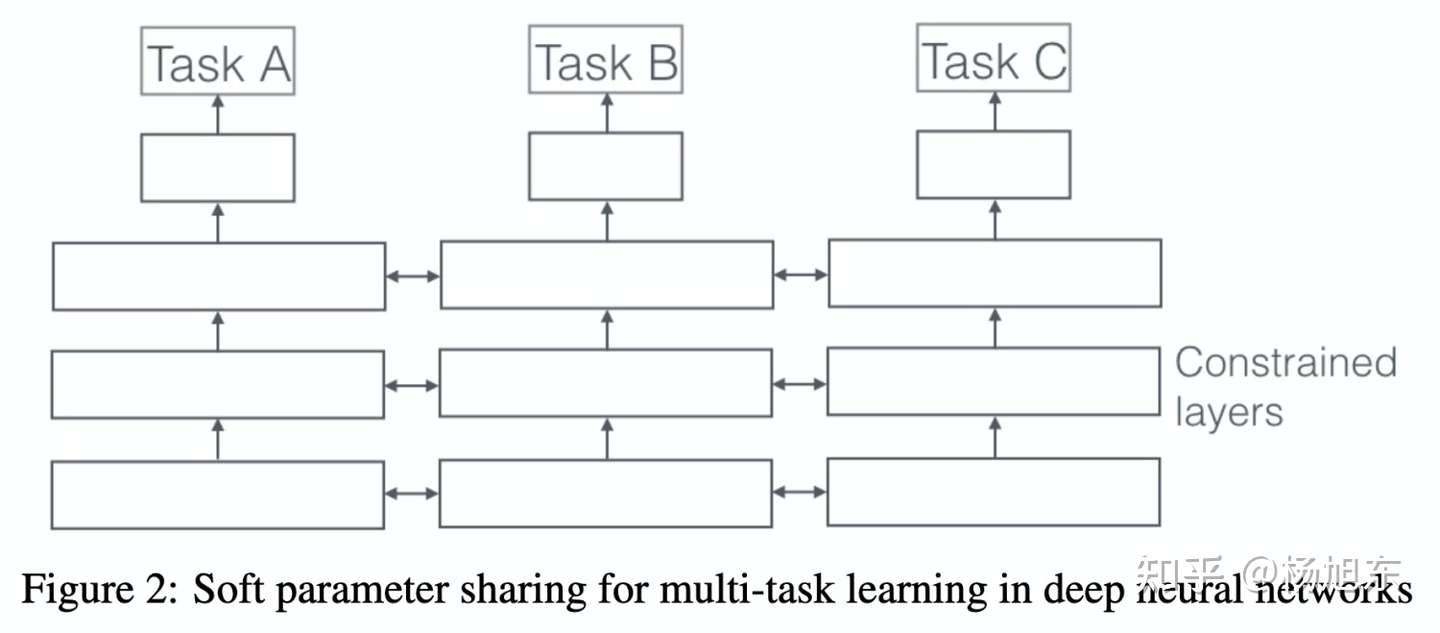
在深度学习领域,MTL通常通过共享隐层的参数来实现,具体有两种共享参数的方法:hard parameter sharing 和 soft parameter sharing。
在soft parameter sharing模式中,每个任务有自己的模型和参数,各任务模型参数的一部分通过正则化的方式使得彼此距离接近,比如通过 L2 正则化。
② ESMM
“完整空间多任务模型”(Entire Space Multi-Task Model,ESMM),下文简称为ESMM模型,创新地利用用户行为序列数据,在完整的样本数据空间同时学习点击率和转化率(post-view clickthrough&conversion rate,CTCVR),解决了传统CVR预估模型难以克服的样本选择偏差(sample selection bias)和训练数据过于稀疏(data sparsity )的问题。
以电子商务平台为例,用户在观察到系统展现的推荐商品列表后,可能会点击自己感兴趣的商品,进而产生购买行为。换句话说,用户行为遵循一定的顺序决策模式:impression → click → conversion。CVR模型旨在预估用户在观察到曝光商品进而点击到商品详情页之后购买此商品的概率,即 。

③ MMoE
MMOE模型的结构图如下:
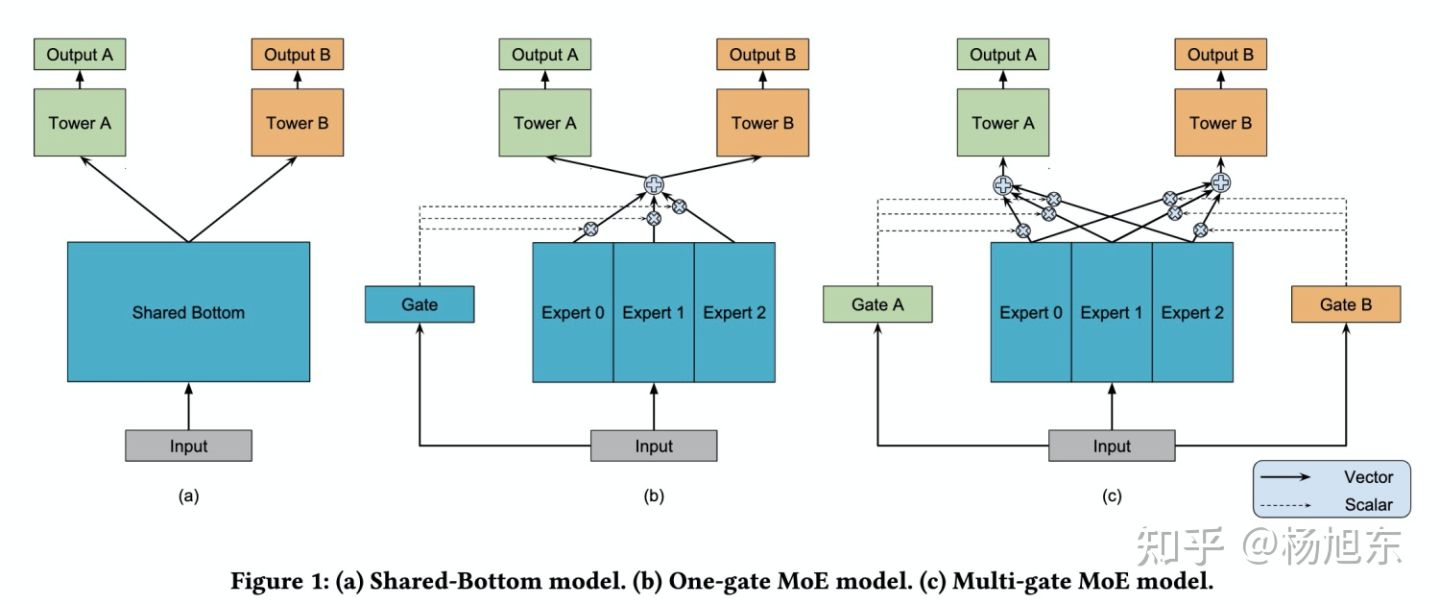
模型 (a) 最为常见,也就是上文所说的NavieMultiTask方法的架构,两个任务直接共享模型的 bottom 部分,只在最后处理时做区分,图 (a) 中使用了 Tower A 和 Tower B,然后分别接损失函数。函数表达式:
模型 (b) 是常见的多任务学习模型。将 input 分别输入给三个 Expert,但三个 Expert 并不共享参数。同时将 input 输出给 Gate,Gate 输出每个 Expert 被选择的概率,然后将三个 Expert 的输出加权求和,输出给 Tower。有点 attention 的感觉。函数表达式:
- k 表示k个任务;
- n 表示n个expert network;
模型 (c) 是作者新提出的方法,对于不同的任务,模型的权重选择是不同的,所以作者为每个任务都配备一个 Gate 模型。对于不同的任务,特定的 Gate k 的输出表示不同的 Expert 被选择的概率,将多个 Expert 加权求和,得到 ,并输出给特定的 Tower 模型,用于最终的输出。函数表达式:
其中: 表示 gate 门的输出,为多层感知机模型,实现时为简单的线性变换加 softmax 层。
3. 特征工程
通常排序模型的特征由三部分构成:
- 用户侧特征:包括用户画像信息、用户粒度统计信息(过于一段时间窗口内用户各种行为的统计值)、用户偏好信息(用户-物品或用户-物品属性粒度的交叉统计信息)
- 物品侧特征:物品基础内容信息、物品粒度的统计信息、物品偏好信息(物品-用户画像、物品-人群画像粒度的统计信息)
- 上下文特征:地理位置、访问设备、天气、时间、是否节假日等
在商品详情页这样的场景下,我们还需要加入主商品维度的特征,具体如下:
- Trigger侧特征:trigger-item 交叉统计特征; trigger的属性与item的属性交叉统计特征;
上文提到了很多统计特征,这里详细说明下具体是如何统计的,得到一个统计量一般需要考虑如下几个维度:
- 统计对象:包括user、item、<user, item>、<trigger, item>、<user, properties of item>、<trigger, properties of item>、<user profile,item>、<properties of trigger, properties of item> 等;
- 统计窗口:最近1天、3天、7天、14天、30天等;
- 行为类型:曝光、点击、收藏、加购、购买等
- 统计量:绝对值、排名、比率(点击率、加购率等)、加权和等
一般从上面几个维度组合来考虑如何生成统计特征不容易有遗漏。
对应数值型的特征,我们一般还需要做离散化或者标准化。离散化包括:等频分箱、等宽分箱、自适应分箱(类似决策树寻找特征分裂点的做法)。标准化方法包括:z-score、min-max等。
简单介绍一下EasyRec推荐算法框架。基于EasyRec框架用户可直接用自己的数据训练内置的算法模型,也可以自定义新的算法模型。目前,已经内置了多个排序模型,如 DeepFM / MultiTower / Deep Interest Network / DSSM / DCN / WDL 等,以及 DBMTL / MMoE / ESMM / PLE 等多目标模型。另外,EasyRec兼容odps/oss/hdfs等多种输入,支持多种类型的特征,损失函数,优化器及评估指标,支持大规模并行训练。使用EasyRec,只需要配置config文件,通过命令调用的方式就可以实现训练、评估、导出、推理等功能,无需进行代码开发,帮您快速搭建推广搜算法。
相比NLP和CV领域的模型,推荐模型的特定是输入的field特别多,可能有几百个,并且各个field的类型和语义也各不相同,需要不同的处理,比如,有的field当成原始特征值使用,有的field需要转embedding之后再接入model,因此,对输入数据的处理通常是开发推荐模型时需要很多重复劳动、易出错、又没有多少技术含量的部分,这让算法工程师头疼不已。EasyRec工具对输入特征的处理进行了自动化,只需要简单的配置即可省去很多重复性劳动。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号