
如何使用TensorFlow中的高级API:Estimator、Experiment和Dataset
参考这篇文章:
https://blog.csdn.net/shuibuzhaodeshiren/article/details/88648517
《如何使用TensorFlow中的高级API:Estimator、Experiment和Dataset》
《Higher-Level APIs in TensorFlow》的文章,通过实例详细介绍了如何使用 TensorFlow 中的高级 API(Estimator、Experiment 和 Dataset)训练模型。值得一提的是 Experiment 和 Dataset 可以独立使用。这些高级 API 已被最新发布的 TensorFlow1.3 版收录。
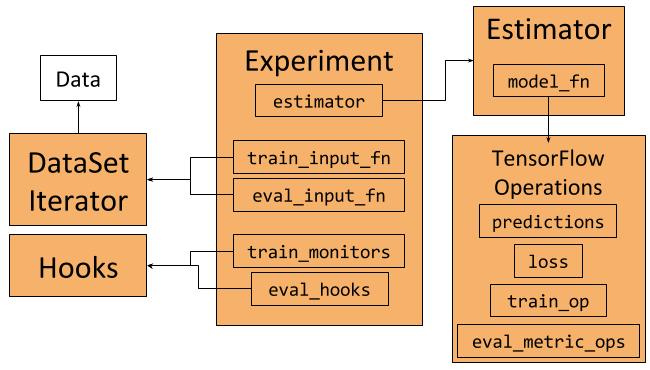
TensorFlow 中有许多流行的库,如 Keras、TFLearn 和 Sonnet,它们可以让你轻松训练模型,而无需接触哪些低级别函数。目前,Keras API 正倾向于直接在 TensorFlow 中实现,TensorFlow 也在提供越来越多的高级构造,其中的一些已经被最新发布的 TensorFlow1.3 版收录。
stimator
Estimator(评估器)类代表一个模型,以及这些模型被训练和评估的方式。我们可以这样构建一个评估器
为了构建一个 Estimator,我们需要传递一个模型函数,一个参数集合以及一些配置。
- 参数应该是模型超参数的集合,它可以是一个字典,但我们将在本示例中将其表示为 HParams 对象,用作 namedtuple。
- 该配置指定如何运行训练和评估,以及如何存出结果。这些配置通过 RunConfig 对象表示,该对象传达 Estimator 需要了解的关于运行模型的环境的所有内容。
- 模型函数是一个 Python 函数,它构建了给定输入的模型。
Experiment
Experiment(实验)类是定义如何训练模型,并将其与 Estimator 进行集成的方式。
Experiment 作为输入:
- 一个 Estimator(例如上面定义的那个)。
- 训练和评估数据作为第一级函数。这里用到了和前述模型函数相同的概念,通过传递函数而非操作,如有需要,输入图可以被重建。我们会在后面继续讨论这个概念。
- 训练和评估钩子(hooks)。这些钩子可以用于监视或保存特定内容,或在图形和会话中进行一些操作。例如,我们将通过操作来帮助初始化数据加载器。
- 不同参数解释了训练时间和评估时间。
一旦我们定义了 experiment,我们就可以通过 learn_runner.run 运行它来训练和评估模型。
Dataset
我们将使用 Dataset 类和相应的 Iterator 来表示我们的训练和评估数据,并创建在训练期间迭代数据的数据馈送器。在本示例中,我们将使用 TensorFlow 中可用的 MNIST 数据,并在其周围构建一个 Dataset 包装器。
为了使用Dataset,我们需要三个步骤:
1)导入数据:从一些数据中创建一个Dataset实例;
2)创建一个迭代器:通过使用创建的数据集来制作一个迭代器实例迭代遍历数据集;
3)使用数据:通过使用创建的迭代器,我们可以得到数据集的元素馈送给模型;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号