
tensorflow的高阶API学习
参考下面的资料:
参考这篇文章:
https://zhuanlan.zhihu.com/p/38470806
《基于Tensorflow高阶API构建大规模分布式深度学习模型系列: 开篇》
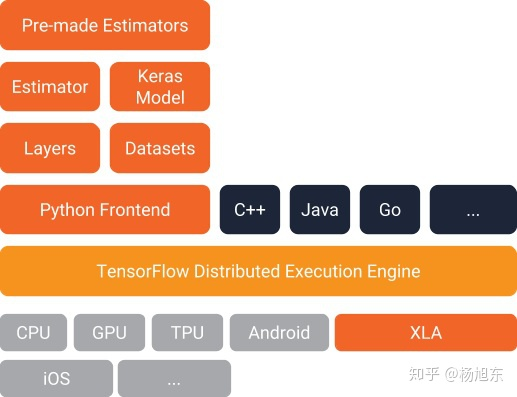
Estimator类是机器学习模型的抽象,其设计灵感来自于典典大名的Python机器学习库Scikit-learn。
Estimator允许开发者自定义任意的模型结构、损失函数、优化方法以及如何对这个模型进行训练、评估和导出等内容,同时屏蔽了与底层硬件设备、分布式网络数据传输等相关的细节。
tf.estimator.Estimator( model_fn=model_fn, # First-class function params=params, # HParams config=run_config # RunConfig )
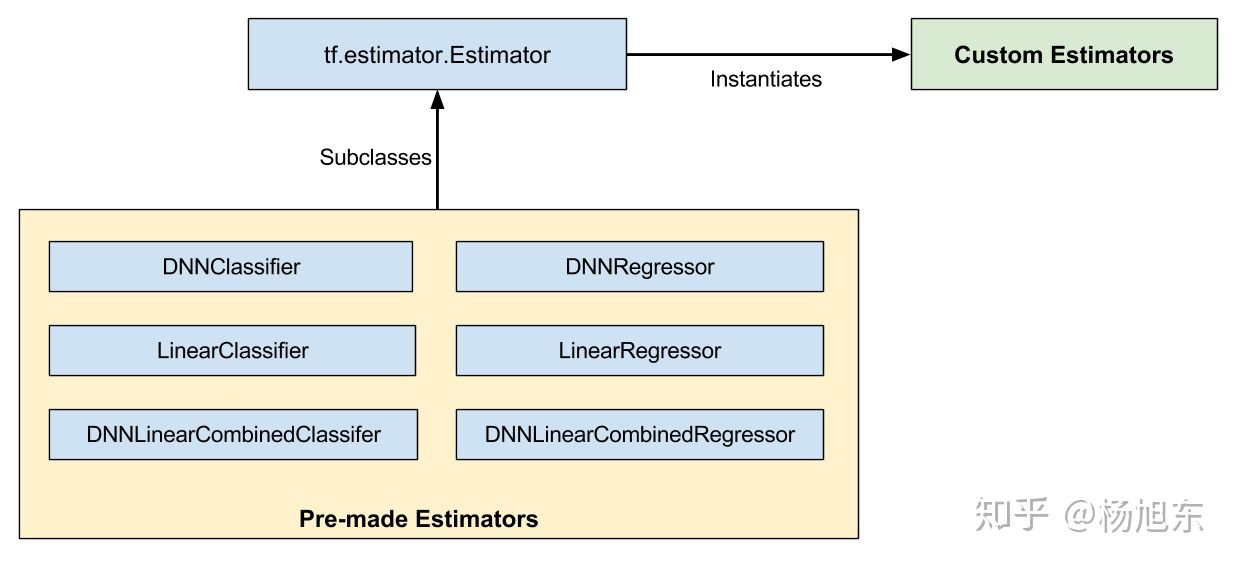
要创建Estimator,需要传入一个模型函数、一组参数和一些配置。
- 传入的参数应该是模型超参数的一个集合,可以是一个dictionary。
- 传入的配置用于指定模型如何运行训练和评估,以及在哪里存储结果。这个配置是一个RunConfig对象,该对象会把模型运行环境相关的信息告诉Estimator。
- 模型函数是一个Python函数,它根据给定的输入构建模型。
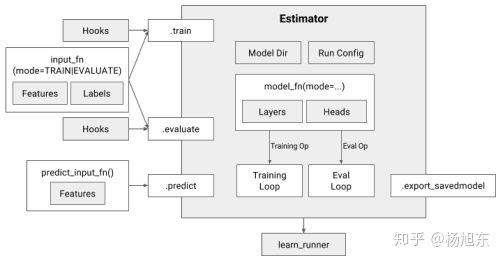
Estimator类有三个主要的方法:train/fit、evaluate、predict,分别表示模型的训练、评估和预测。三个方法都接受一个用户自定义的输入函数input_fn,执行input_fn获取输入数据。
2. 模型函数
模型函数是用户自定义的一个python函数,它定义了模型训练、评估和预测所需的计算图节点(op)。
mode是tf.estimator.ModeKeys对象,它有三个可取的值:TRAIN、EVAL、PREDICT。模型函数的最后一个参数是超参数集合,它们与传递给Estimator的超参数集合相同。
模型函数返回一个EstimatorSpec对象,该对象定义了一个完整的模型。EstimatorSpec对象用于对操作进行预测、损失、训练和评估,因此,它定义了一个用于训练、评估和推理的完整的模型图。
def model_fn(features, target, mode, params) predictions = tf.stack(tf.fully_connected, [50, 50, 1]) loss = tf.losses.mean_squared_error(target, predictions) train_op = tf.train.create_train_op( loss, tf.train.get_global_step(), params[’learning_rate’], params[’optimizer’]) return EstimatorSpec(mode=mode, predictions=predictions, loss=loss, train_op=train_op)
3. Dataset(数据集)
Dataset是对训练、评估、预测阶段所用的数据的抽象表示,其提供了数据读取、解析、打乱(shuffle)、过滤、分批(batch)等操作,是构建模型输入管道的利器,我将会在另外一篇文章《基于Tensorflow高阶API构建大规模分布式深度学习模型系列:基于Dataset API处理Input pipeline》中详细介绍。
4. Feature Columns(特征列)
提供了一些常用的数据变换操作,如特征交叉、one-hot编码、embedding编码等。
5. Layers
Layer是一组简单的可重复利用的代码,表示神经网络模型中的“层”这个概念。Tensorflow中的layer可以认为是一系列操作(op)的集合,与op一样也是输入tensor并输出tensor的(tensor-in-tensor-out)。Tensorflow中即内置了全连接这样的简单layer,也有像inception网络那样的复杂layer。使用layers来搭建网络模型会更加方便。
6. Head
Head API对网络最后一个隐藏层之后的部分进行了抽象,它的主要设计目标是简化模型函数(model_fn)的编写。Head知道如何计算损失(loss)、评估度量标准(metric)、预测结果(prediction)。
为了支持不同的模型,Head接受logits和labels作为参数,并生成表示loss、metric和prediction的张量。有时为了避免计算完整的logit张量,Head也接受最后一个隐藏的激活值作为输入。
总结
Tensorflow高阶API简化了模型代码的编写过程,大大降价了新手的入门门槛,使我们能够用一种标准化的方法开发出实验与生产环境部署的代码。使用Tensorflow高阶API能够使我们避免走很多弯路,提高深度学习的实践效率,我们应该尽可能使用高阶API来开发模型。
以下是这篇文章:
https://zhuanlan.zhihu.com/p/38421397
在TensorFlow 1.3版本之前,读取数据一般有两种方法:
- 使用placeholder + feed_dict读内存中的数据
- 使用文件名队列(string_input_producer)与内存队列(reader)读硬盘中的数据
Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以是向量,也可以是字符串、图片,甚至是tuple或者dict。
析TFRECORD文件
Tfrecord是tensorflow官方推荐的训练数据存储格式,它更容易与网络应用架构相匹配。
Tfrecord本质上是二进制的Protobuf数据,因而其读取、传输的速度更快。Tfrecord文件的每一条记录都是一个tf.train.Example的实例。tf.train.Example的proto格式的定义如下:
message Example { Features features = 1; }; message Features { map<string, Feature> feature = 1; }; message Feature { oneof kind { BytesList bytes_list = 1; FloatList float_list = 2; Int64List int64_list = 3; } };
使用tfrecord文件格式的另一个好处是数据结构统一,屏蔽了底层的数据结构。在类似于图像分类的任务中,原始数据是各个图片以单独的小文件的形式存在,label又以文件夹的形式存在,处理这样的数据比较麻烦,比如随机打乱,分batch等操作;而所有原始数据转换为一个或几个单独的tfrecord文件后处理起来就会比较方便。
大规模的训练数据用这种方式转换格式会比较低效,更好的实践是用hadoop或者spark这种分布式计算平台,并行实现数据转换任务。这里给出一个用Hadoop MapReduce编程模式转换为tfrecord文件格式的开源实现:Hadoop MapReduce InputFormat/OutputFormat for TFRecords。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号