
tensorflow的分布式训练
参考这篇文章:
https://zhuanlan.zhihu.com/p/56991108
一文说清楚Tensorflow分布式训练必备知识
模型并行
在tensorflow的术语中,模型并行称之为"in-graph replication"。
数据并行
在tensorflow的术语中,数据并行称之为"between-graph replication"。
分布式并行模式
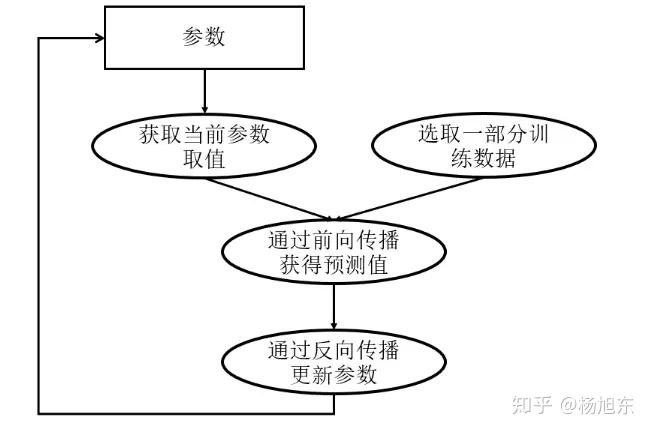
异步训练
异步训练中,各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数。
异步训练总体会训练速度会快很多,但是异步训练的一个很严重的问题是梯度失效问题(stale gradients)。由于梯度失效问题,异步训练可能陷入次优解(sub-optimal training performance)。
在tensorflow中异步训练是默认的并行训练模式。
同步训练
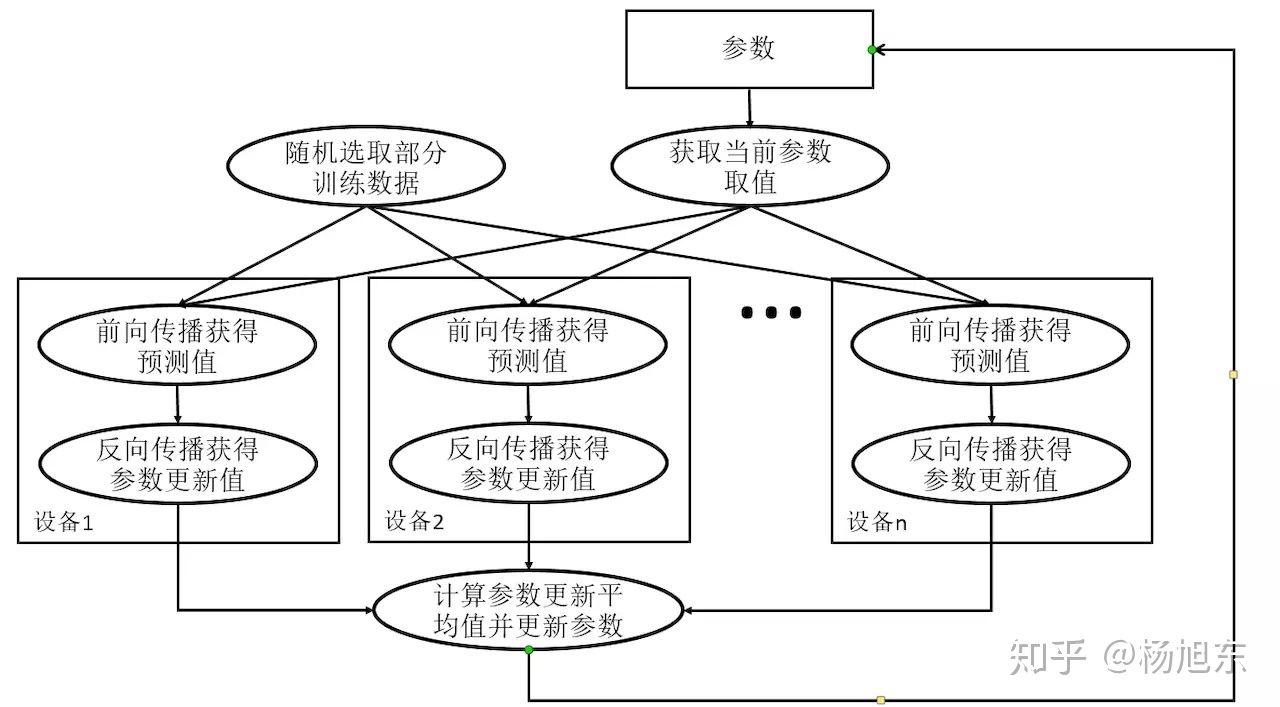
小结
下图可以一目了然地看出同步训练与异步训练之间的区别。
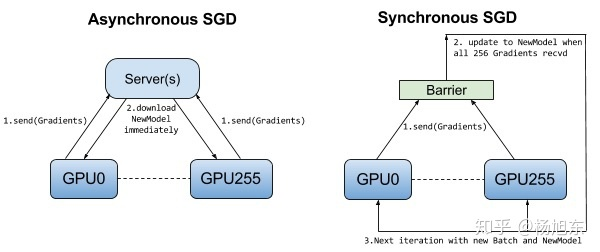
同步训练看起来很不错,但是实际上需要各个设备的计算能力要均衡,而且要求集群的通信也要均衡,类似于木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步训练方式相对来说训练速度会慢一些。
虽然异步模式理论上存在缺陷,但因为训练深度学习模型时使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优值。在实际应用中,在相同时间内使用异步模式训练的模型不一定比同步模式差。所以这两种训练模式在实践中都有非常广泛的应用。
分布式训练架构
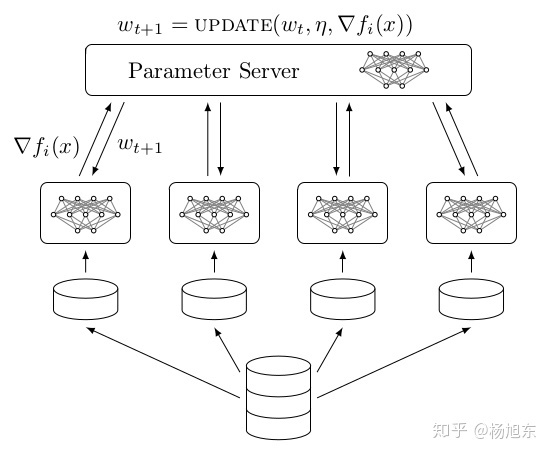
Parameter Server架构
Parameter server架构(PS架构)是深度学习最常采用的分布式训练架构。在PS架构中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。
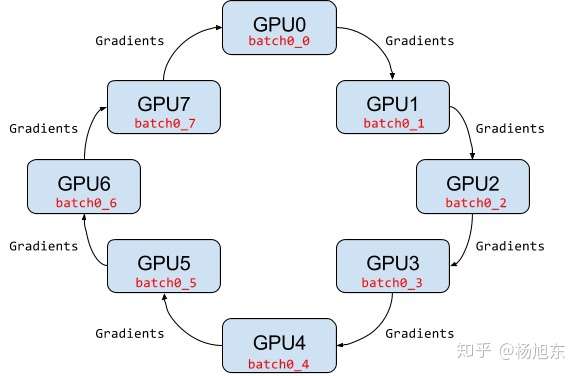
Ring AllReduce架构
PS架构中,当worker数量较多时,ps节点的网络带宽将成为系统的瓶颈。
Ring AllReduce架构中各个设备都是worker,没有中心节点来聚合所有worker计算的梯度。Ring AllReduce算法将 device 放置在一个逻辑环路(logical ring)中。每个 device 从上行的device 接收数据,并向下行的 deivce 发送数据,因此可以充分利用每个 device 的上下行带宽。
分布式tensorflow
推荐使用 TensorFlow Estimator API 来编写分布式训练代码
要让tensorflow分布式运行,首先我们需要定义一个由参与分布式计算的机器组成的集群,如下:
cluster = {'chief': ['host0:2222'],
'ps': ['host1:2222', 'host2:2222'],
'worker': ['host3:2222', 'host4:2222', 'host5:2222']}集群中一般有多个worker,需要指定其中一个worker为主节点(cheif),chief节点会执行一些额外的工作,比如模型导出之类的。在PS分布式架构环境中,还需要定义ps节点。
可以参考下面的资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号