
模型蒸馏Distillation
今天参考这篇文章:
https://zhuanlan.zhihu.com/p/71986772
transformer系列模型的进展,从BERT到GPT2再到XLNet。然而随着模型体积增大,线上性能也越来越差,所以决定开一条新线,开始follow模型压缩之模型蒸馏的故事线。
0. 名词解释
- teacher - 原始模型或模型ensemble
- student - 新模型
- transfer set - 用来迁移teacher知识、训练student的数据集合
- soft target - teacher输出的预测结果(一般是softmax之后的概率)
- hard target - 样本原本的标签
- temperature - 蒸馏目标函数中的超参数
- born-again network - 蒸馏的一种,指student和teacher的结构和尺寸完全一样
- teacher annealing - 防止student的表现被teacher限制,在蒸馏时逐渐减少soft targets的权重
1.1 为什么蒸馏可以work
好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让student学习到teacher的泛化能力,理论上得到的结果会比单纯拟合训练数据的student要好。另外,对于分类任务,如果soft targets的熵比hard targets高,那显然student会学习到更多的信息。
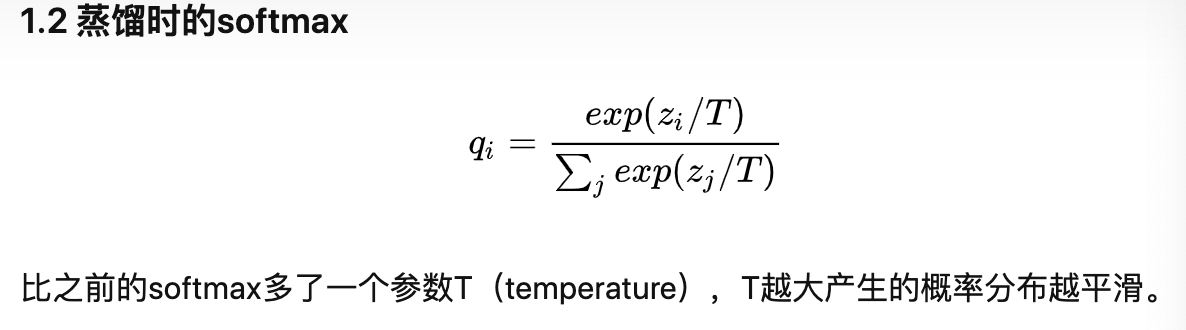

 浙公网安备 33010602011771号
浙公网安备 33010602011771号