
模型蒸馏工作 & logit & Bert面试点
接上一篇文章:
https://www.cnblogs.com/charlesblc/p/15965479.html
今天重点看这篇文章:
https://mp.weixin.qq.com/s/tKfHq49heakvjM0EVQPgHw
Distilled BiLSTM/BERT-PKD/DistillBERT/TinyBERT/MobileBERT/MiniLM六大经典模型
在蒸馏的过程中,我们将原始大模型称为教师模型(teacher),新的小模型称为学生模型(student),训练集中的标签称为hard label,教师模型预测的概率输出为soft label,temperature(T)是用来调整soft label的超参数。
蒸馏这个概念之所以work,核心思想是因为好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让学生模型学习到教师模型的泛化能力,理论上得到的结果会比单纯拟合训练数据的学生模型要好。
那对于简单的二分类任务来说,直接拿教师预测的0/1结果会与训练集差不多,没什么意义,那拿概率值是不是好一些?于是Hinton采用了教师模型的输出概率q,同时为了更好地控制输出概率的平滑程度,给教师模型的softmax中加了一个参数T。
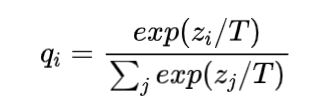
有了教师模型的输出后,学生模型的目标就是尽可能拟合教师模型的输出,新loss就变成了:
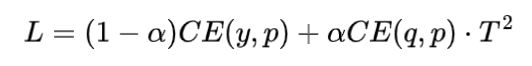
因为在求梯度时新的目标函数会导致梯度是以前的 ,所以要再乘上,不然T变了的话hard label不减小(T=1),但soft label会变。
有同学可能会疑惑:如果可以拟合prob,那直接拟合logits可以吗?
当然可以,Hinton在论文中进行了证明,如果T很大,且logits分布的均值为0时,优化概率交叉熵和logits的平方差是等价的。
BERT蒸馏
在BERT提出后,如何瘦身就成了一个重要分支。主流的方法主要有剪枝、蒸馏和量化。量化的提升有限,因此免不了采用剪枝+蒸馏的融合方法来获取更好的效果。
从各个研究看来,蒸馏的提升一方面来源于从精调阶段蒸馏->预训练阶段蒸馏,另一方面则来源于蒸馏最后一层知识->蒸馏隐层知识->蒸馏注意力矩阵。
DistillBERT (NIPS2019)
最终损失函数由MLM loss、教师-学生最后一层的交叉熵、隐层之间的cosine loss组成。从消融实验可以看出,MLM loss对于学生模型的表现影响较小,同时初始化也是影响效果的重要因素:
TinyBERT(EMNLP2019)
TinyBERT[5]就提出了two-stage learning框架,分别在预训练和精调阶段蒸馏教师模型,得到了参数量减少7.5倍,速度提升9.4倍的4层BERT,效果可以达到教师模型的96.8%,同时这种方法训出的6层模型甚至接近BERT-base,超过了BERT-PKD和DistillBERT。
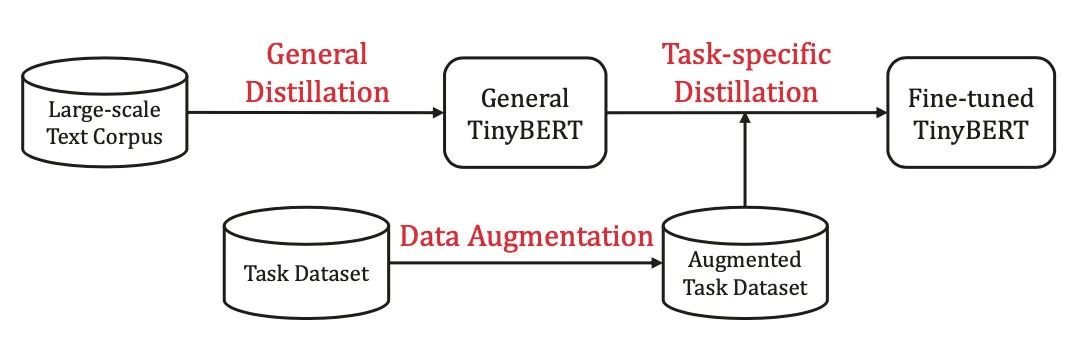
TinyBERT的教师模型采用BERT-base。作者参考其他研究的结论,即注意力矩阵可以捕获到丰富的知识,提出了注意力矩阵的蒸馏,采用教师-学生注意力矩阵logits的MSE作为损失函数(这里不取attention prob是实验表明前者收敛更快)。另外,作者还对embedding进行了蒸馏,同样是采用MSE作为损失。
BERT蒸馏技巧
介绍了BERT蒸馏的几个经典模型之后,真正要上手前还是要把几个问题都考虑清楚,下面就来讨论一些蒸馏中的变量。
剪层还是减维度?
这个选择取决于是预训练蒸馏还是精调蒸馏。预训练蒸馏的数据比较充分,可以参考MiniLM、MobileBERT或者TinyBERT那样进行剪层+维度缩减。
对于针对某项任务、只想蒸馏精调后BERT的情况,则推荐进行剪层,同时利用教师模型的层对学生模型进行初始化。从BERT-PKD以及DistillBERT的结论来看,采用skip(每隔n层选一层)的初始化策略会优于只选前k层或后k层。
T和如何设置?
超参数主要控制soft label和hard label的loss比例,Distilled BiLSTM在实验中发现只使用soft label会得到最好的效果。个人建议让soft label占比更多一些,一方面是强迫学生更多的教师知识,另一方面实验证实soft target可以起到正则化的作用,让学生模型更稳定地收敛。
超参数T主要控制预测分布的平滑程度,TinyBERT实验发现T=1更好,BERT-PKD的搜索空间则是{5, 10, 20}。因此建议在1~20之间多尝试几次,T越大越能学到teacher模型的泛化信息。比如MNIST在对2的手写图片分类时,可能给2分配0.9的置信度,3是1e-6,7是1e-9,从这个分布可以看出2和3有一定的相似度,这种时候可以调大T,让概率分布更平滑,展示teacher更多的泛化能力。
面试点
包括可能遇到的概率题、leetcode题型归纳、机器学习、深度学习的方方面面。
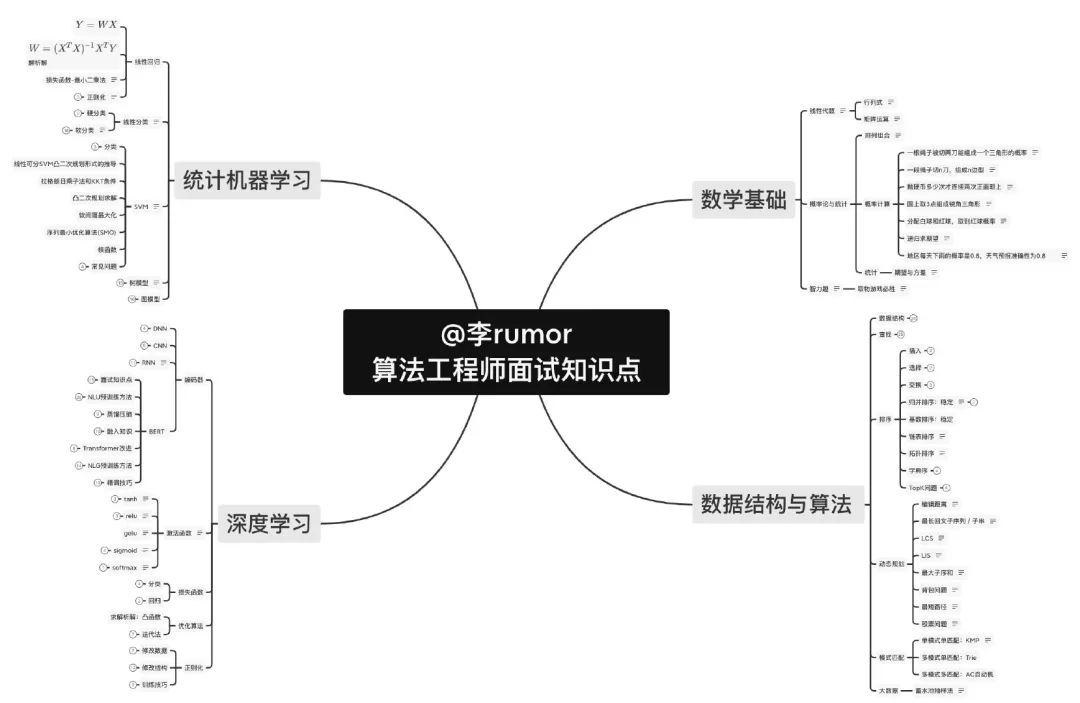
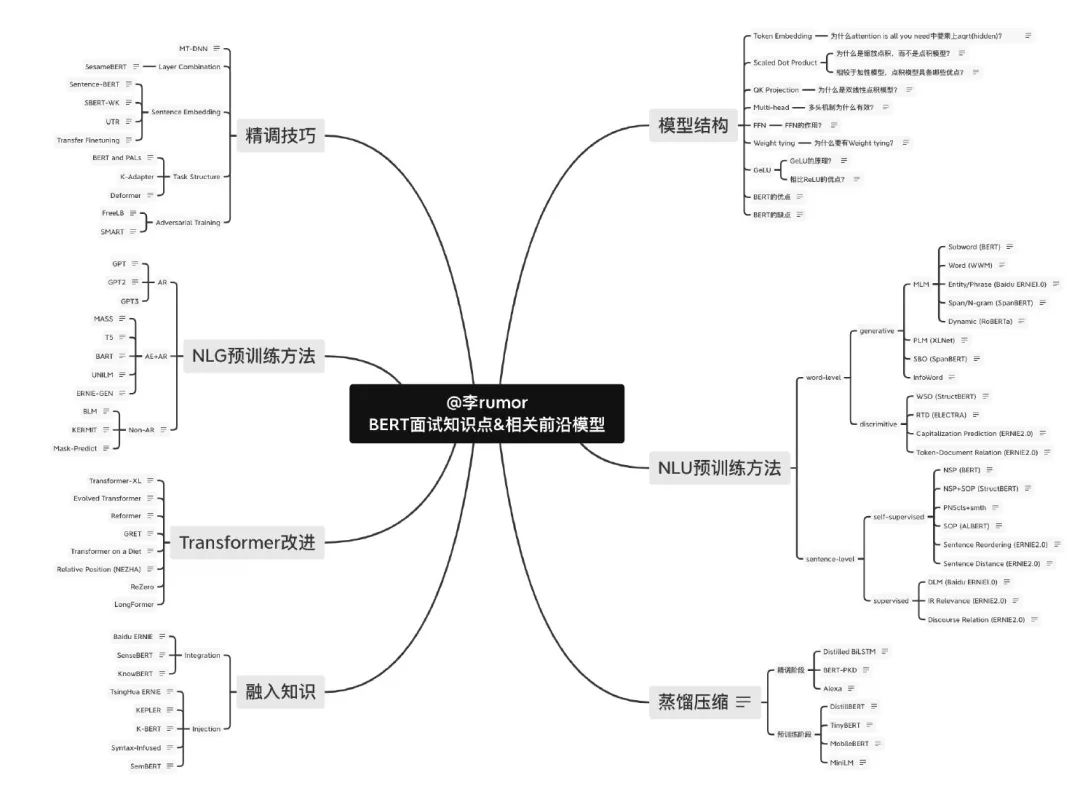
就拿其中的深度学习-编码器-BERT节点来说,包含了基础的模型结构、精调技巧、预训练方法以及衍生的蒸馏压缩、生成模型与训练、Transformer结构改进以及知识融入,都是NLP算法工程师的刚需知识点:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号