


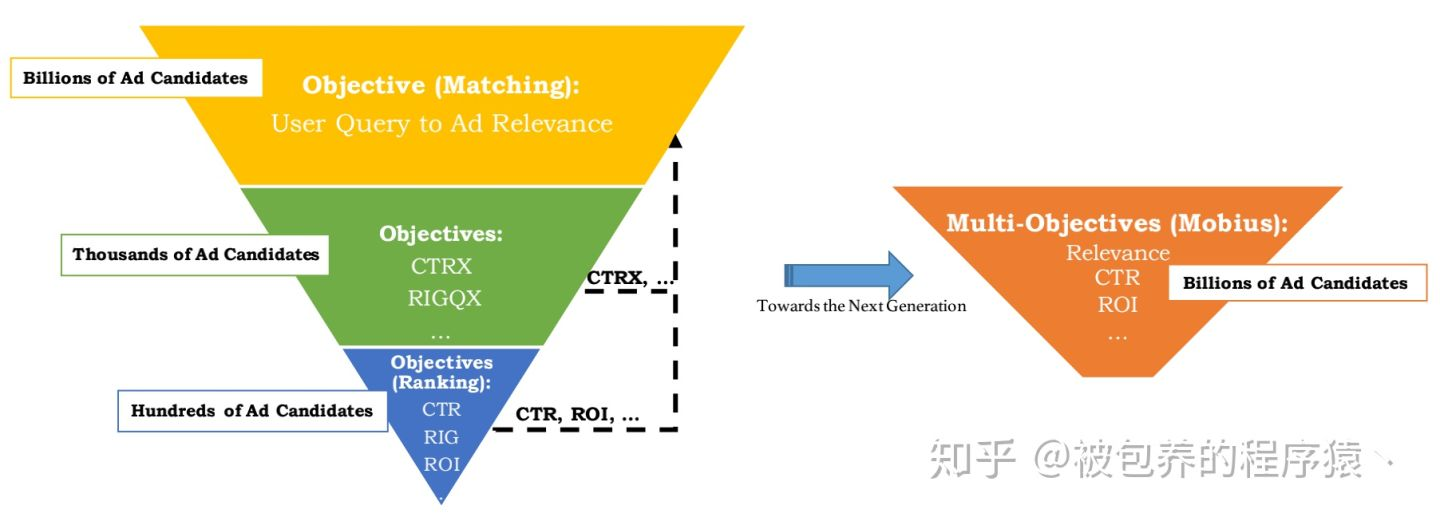
baidu搜索广告的召回系统
参考这篇文章:
https://zhuanlan.zhihu.com/p/146210155
《百度凤巢新一代广告召回系统——“莫比乌斯”》
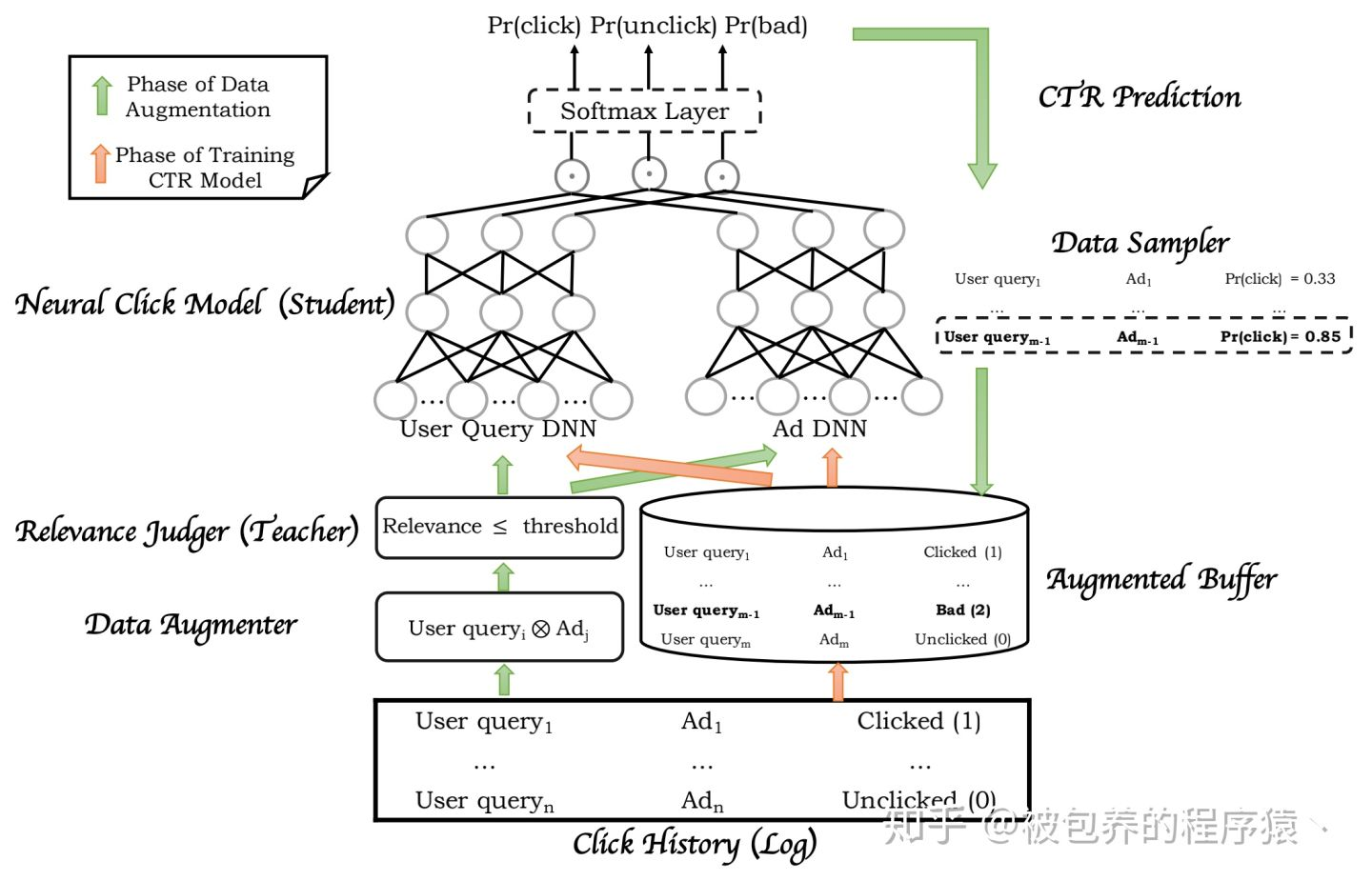
从上面的训练流程图可以大致归结为如下几步:
(1)首先从点击日志中加载一个batch的数据
(2)利用这一个batch的数据构建两个集合,即query集合和广告集合
(3)对构建好的query集合和广告集合两两配对,构建augmented data,即query集合大小为N,广告集合大小为M,则生成的样本集合大小为N*M
(4)利用传统的召回阶段的相关性模型对每一个query-ad的pair进行相关性打分,筛选出其中相关性比较低的的pair
(5)利用CTR预估模型(T-2)对相关性较低的pair进行CTR预估得到pctr
(6)利用采样器根据PCTR值对这批低相关性的pair进行采样,同时对这批数据打上对应的label——badcase,得到增强的样本数据
(7)将增强的样本数据补充到CTR模型的训练样本中,并且单独设计一个类别badcase,也就是将传统的CTR模型的二分类任务扩展到了三分类任务
在大部分公司的商业广告系统架构中,都会采用经典的“漏斗”结构,即召回——粗排——精排——重排序等模块
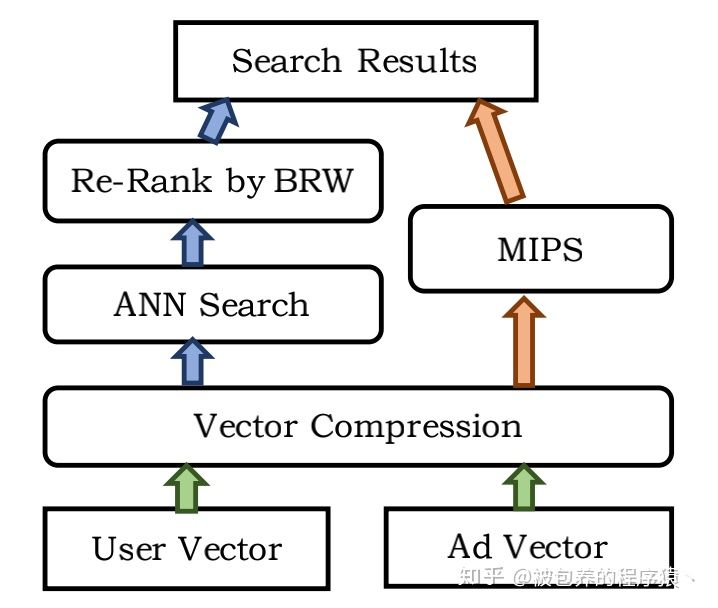
在线上进行广告检索召回的时候,当收到一个用户请求(query)时,线上计算可以得到用户的query embedding,利用query embedding需要在保证相关性的前提下筛选出变现能力最高的一批候选广告,这时就需要利用query embedding去进行检索,暴力的全库检索基本是不可实现的(线上计算开销太大,根本无法满足耗时的要求),所以比较常用的是近似最近邻(ANN)检索(开源库比较多,例如ANNOY,FAISS,HNSW等)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2020-02-24 浅谈分词算法(3)基于字的分词方法(HMM)
2020-02-24 浅谈分词算法(2)基于词典的分词方法
2018-02-24 用Tensorflow训练 Cifar10 数据库 - python打印进度的代码
2018-02-24 今天继续训练迁移网络 - 针对老虎和小猫的体长的训练
2017-02-24 字符串去重并且获得最小字典序的我的一个思路
2017-02-24 关于算术表达式以及乘法优先级的处理
2017-02-24 sort函数自定义compare方法