
实时推荐一些思考
最近在做实时推荐,分成三个阶段来做:
第一步,先利用相似推荐补充到实时数据流
第二步,加入实时特征应用到线上推荐模型
第三步,针对模型进行实时训练学习改造
实时推荐的各种模型,可以看一下:
https://zhuanlan.zhihu.com/p/385709488
1.Lambda架构
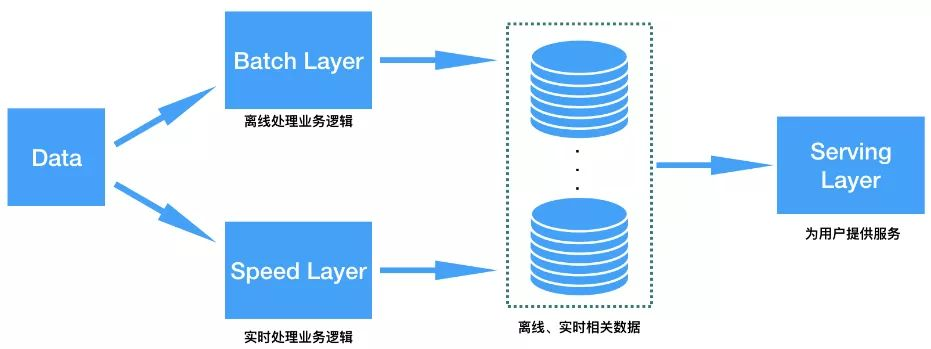
Lambda架构(见参考文献1)就是上面这种思路的高度抽象,它是著名的流式处理框架Storm的作者Nathan Marz最先提出来的。Lambda架构一般分为3个模块:Batch Layer、Speed Layer、Serving Layer,Batch Layer负责处理离线的大规模数据,Speed Layer负责处理实时收集到的用户行为数据,而Serving Layer将离线和实时两部分结果基于一定的规则或算法进行汇集、排序,并最终对用户(既可以是终端用户也可以是公司内部的其他业务部门)提供服务,下图即是Lambda架构的抽象业务处理逻辑。

2.Kappa架构
Kappa 架构是LinkedIn的Jay Kreps结合实际经验和个人体会,针对Lambda架构进行深度剖析,分析其优缺点并采用的替代方案(读者可以查看参考文献2,对Kappa架构进行更深入了解)。Lambda 架构的一个很明显的问题是需要维护两套分别跑在批处理和实时计算系统上面的代码,而且这两套代码需要紧密配合,对增量求和统计还得产出一样的结果。
Kappa架构通过剔除Lambda架构中的批处理部分简化了Lambda架构。为了取代批量处理,数据只需通过流式计算系统快速加工处理。Kappa体系结构中的规范数据存储不是使用类似于SQL的关系数据库或类似于Cassandra的键值存储,而是一个只能追加数据的不可变日志系统。从日志中,数据通过计算系统流式传输,并输入辅助存储器作为字典库供服务使用。典型的Kappa架构如下图:

1.实时协同过滤算法
《协同过滤推荐算法》第四节“近实时协同过滤算法的工程实现”对实时协同过滤算法进行了详细讲解,这里采用的是利用Spark Streaming和HBase作为算法实现和存储的工具。
2.实时矩阵分解算法
《矩阵分解推荐算法》第五节“近实时矩阵分解算法”对腾讯在2016年发表的一篇基于Storm来实现的近实时矩阵分解的算法原理及工程实现细节进行了介绍。
3.实时因子分解机
《因子分解机》第六节“近实时分解机”有对分解机实时实现的简单介绍,其中给了很多参考文献,可以作为读者学习的参考资料。
4.基于内容推荐的实时算法
基于内容的推荐,不需要其他用户的行为,只需学习到待推荐用户的兴趣偏好特征就可以给用户进行推荐了,相比协同过滤类算法更简单更容易实现,因此也是非常适合做实时推荐的。业界比较出名的在线学习算法FTRL(Google最早提出,见参考文献6),可以实时训练很多机器学习算法(如logistic回归),可以与推荐系统的排序阶段。当前比较热门的深度学习技术也可以进行在线学习,读者可以阅读参考文献4、5进行了解。在工业界,蚂蚁金服的AI团队对TensorFlow的底层架构进行了修改优化(见参考文献9),使之适应实时学习,并在支付宝的推荐业务中得到了很好的应用。参考文献7、8分别介绍了凤凰新闻和爱奇艺的实时推荐的工程实现细节,读者可以参考。另外参考文献3比较详细介绍了Netflix的推荐系统的工程实现介绍,其中也包括实时实现部分,采用的是Lambda架构的模式。Netflix推荐系统是业界做得非常好的典范,值得读者深入了解。从这篇参考文献也可以看到要做好实时推荐系统是非常复杂的,需要面临非常多的技术、工程挑战,在下一节我们就会对这方面进行详细介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号