

图解BERT模型-读书摘要
今天读的这篇文章:
《图解BERT模型:从零开始构建BERT》
https://cloud.tencent.com/developer/article/1389555
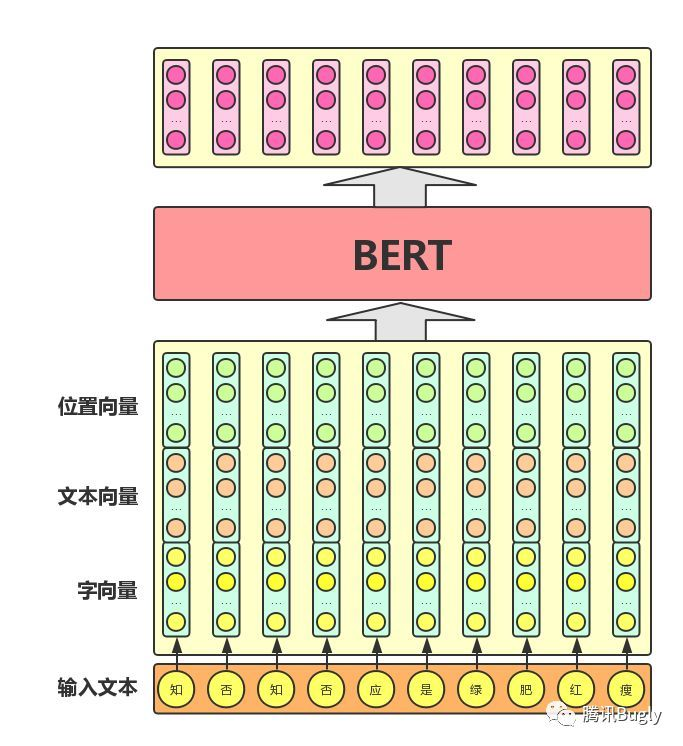
- 单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
![]()
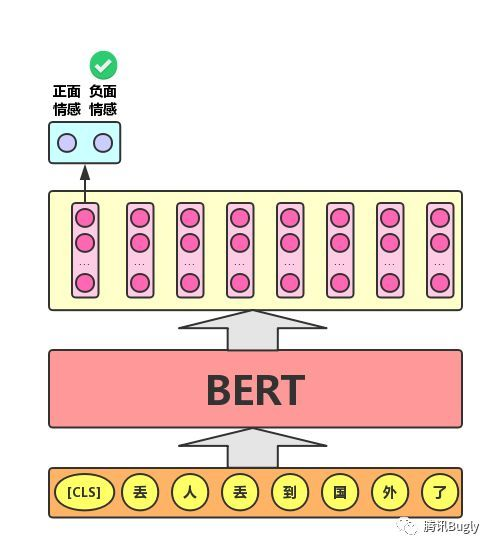
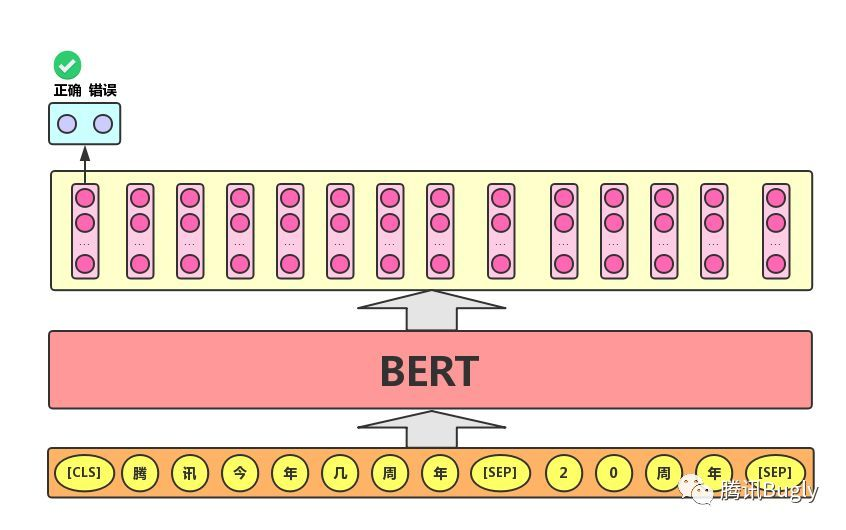
- 语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
![]()
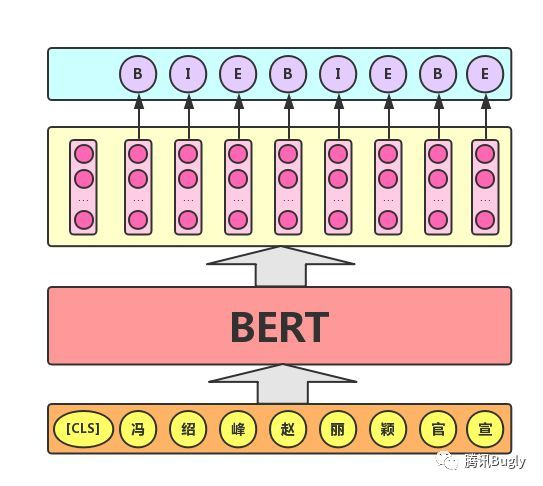
- 序列标注任务:该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注(分类),如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
![]()
- 为了达到这个目的,BERT文章作者提出了两个预训练任务:Masked LM和Next Sentence Prediction。
- 对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
BERT模型通过对Masked LM任务和Next Sentence Prediction任务进行联合训练,使模型输出的每个字/词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
Attention机制
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。
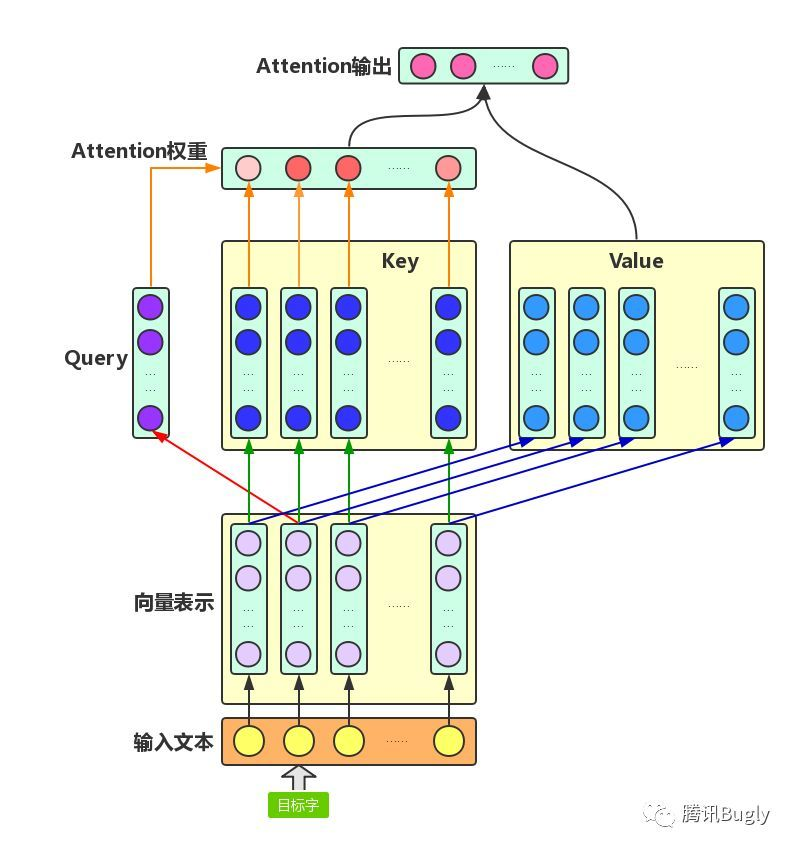
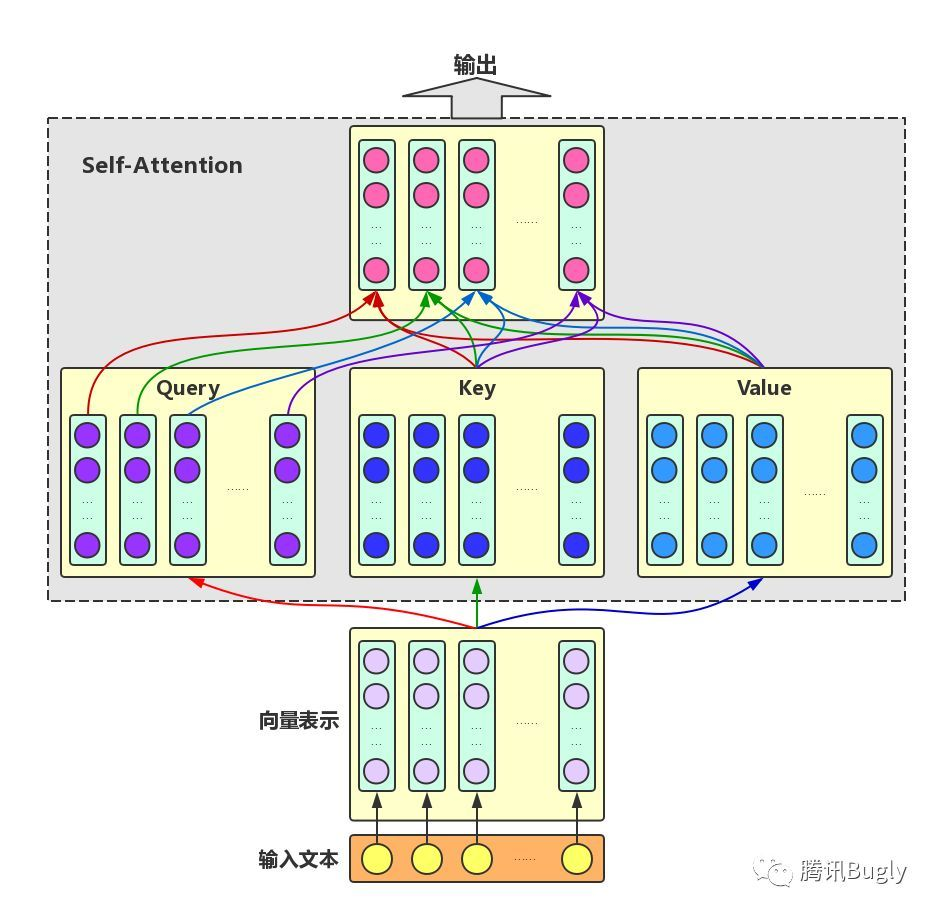
Self-Attention:对于输入文本,我们需要对其中的每个字分别增强语义向量表示,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表示均来自于同一输入文本,因此,该Attention机制也叫Self-Attention。
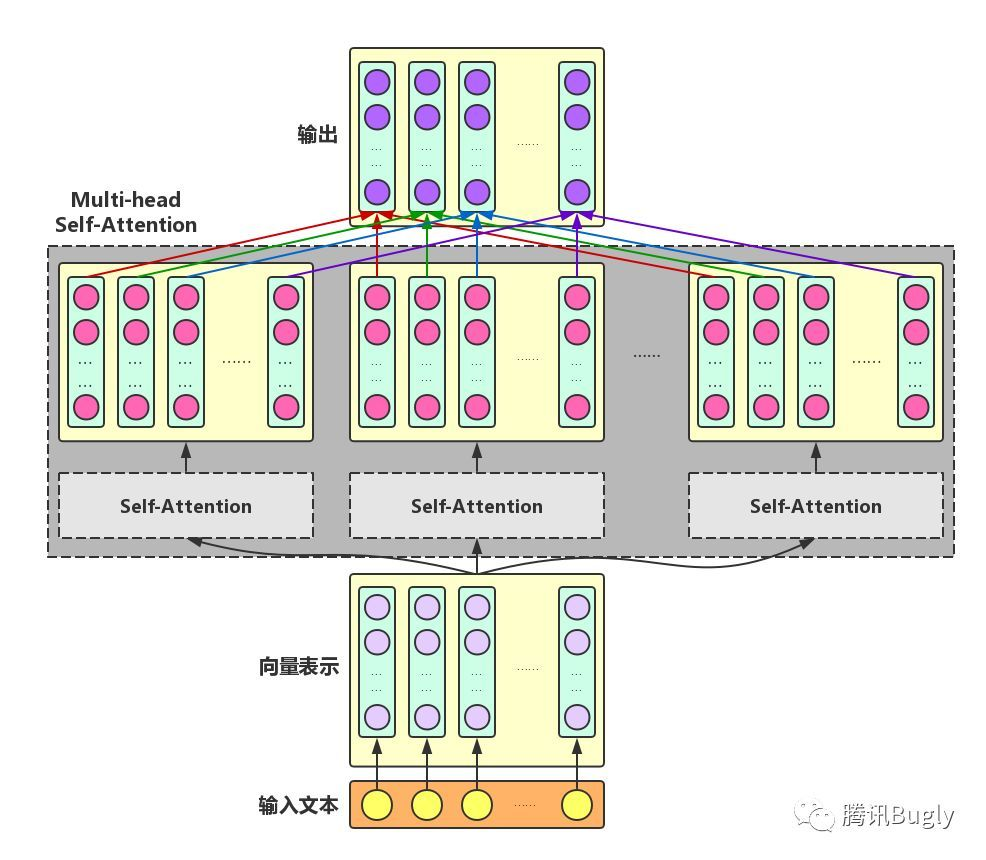
Multi-head Self-Attention
Transformer模型还包含一个Decoder模块用于生成文本,但由于BERT模型中并未使用到Decoder模块,因此这里对其不作详述。
Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
- 残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本考虑是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
- Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。
- 线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度相同。
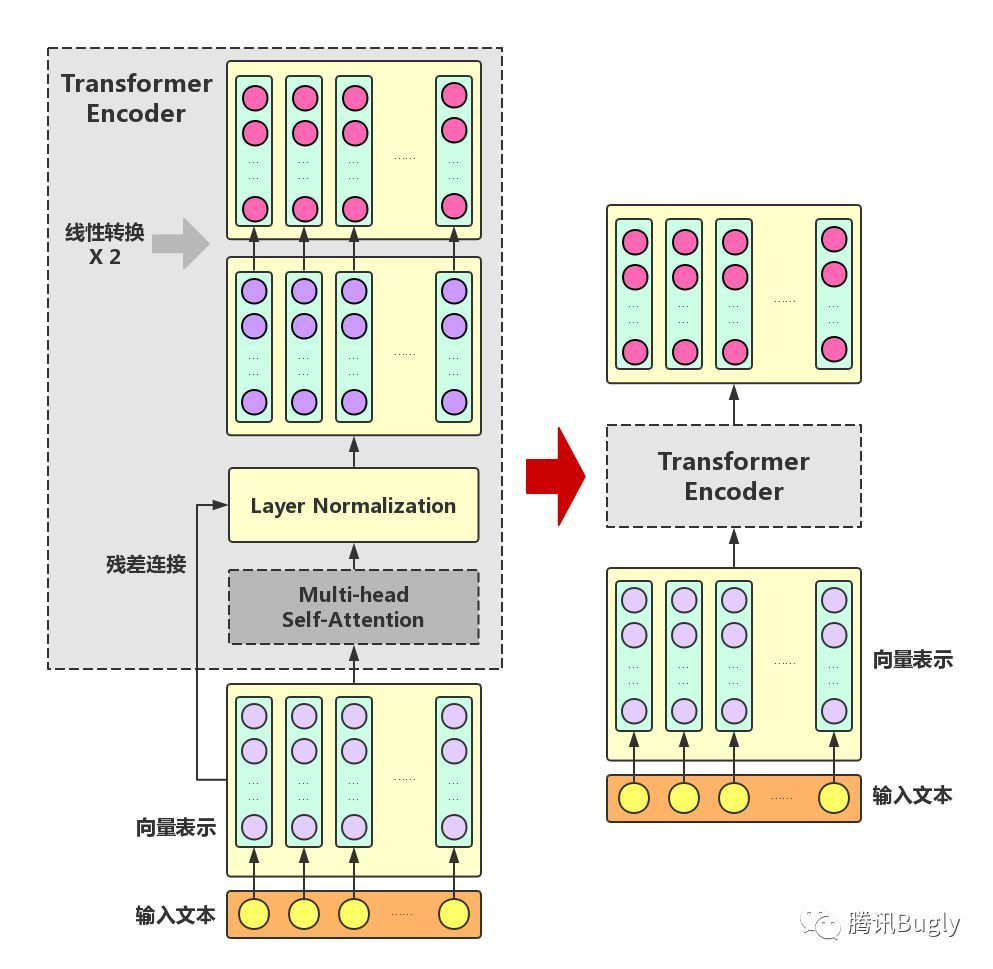
在论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
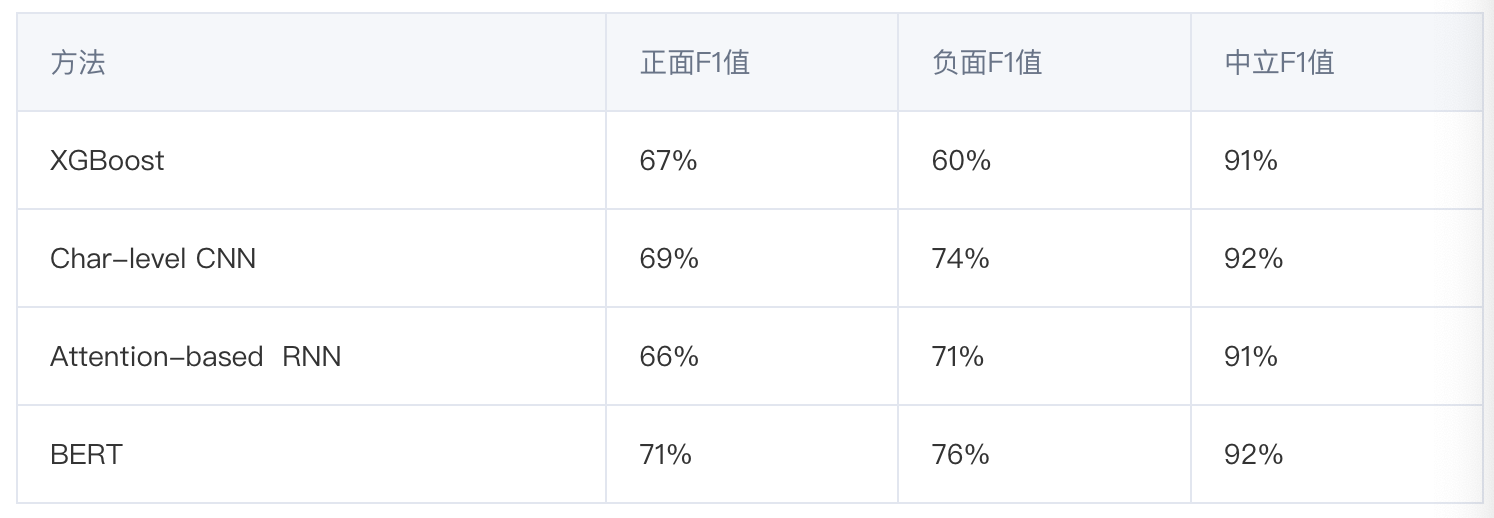
4.1 商品评论情感分析
该数据集旨在分析微博中表达的对特定商品的情感倾向:正面、负面或中立。我们选择了三种方法与BERT模型进行对比:
- XGBoost:NGram特征+XGBoost分类器
- Char-level CNN:将未分词的文本直接输入卷积神经网络(已对比发现Word-level CNN效果略差)
- Attention-based RNN:将分词后的文本输入循环神经网络(已对比发现Char-level RNN效果略差),并且在最终分类前采用Attention机制融合输入各个词对应的hidden states
BERT模型与三种对比方法的正面、负面、中立情感分类F1值如下:
4.2 Sentiment_XS
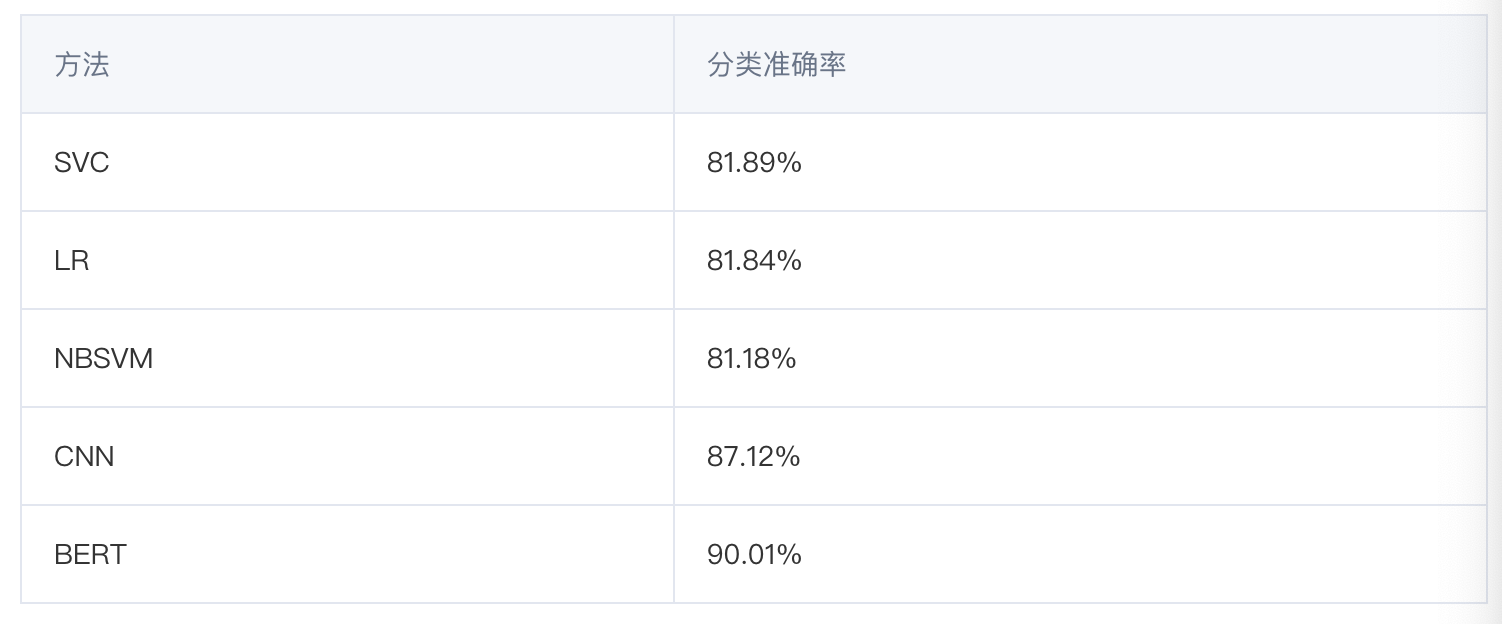
该数据集来自于论文“SentimentClassification with Convolutional Neural Networks: an Experimental Study on aLarge-scale Chinese Conversation Corpus” (DOI:10.1109/CIS.2016.0046),旨在对短文本进行正/负面情感极性分类。我们选择论文中的部分代表性对比方法与BERT模型进行对比,包括:支持向量机分类器(SVC)、逻辑回归(LR)、Naive Bayes SVM(NBSVM)和卷积神经网络(CNN),分类准确率如下表所示(对比方法的实验数据来自于论文)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号