

Contextualized Word Embedding-ELMO/BERT/GPT
参考这篇文章:
https://www.cnblogs.com/dogecheng/p/11615750.html
我们期望每一个 word token 都有一个 embedding。每个 word token 的 embedding 依赖于它的上下文。这种方法叫做 Contextualized Word Embedding。
BERT 是 Transformer 的 Encoder,GPT则是 Transformer 的 Decoder。GPT 输入一些词汇,预测接下来的词汇。其计算过程如下图所示。
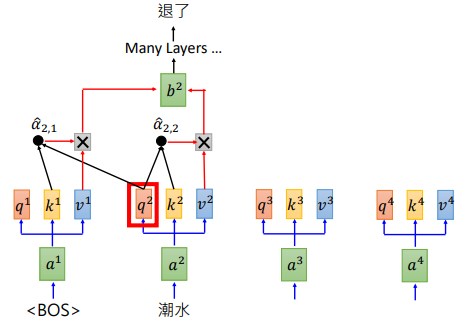
先记到这里吧,其他好像也没有特别需要记录的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2018-02-16 这道题目还是很难得- 剑指Offer - 正则表达式
2018-02-16 剑指Offer - 做过的一道题目- 之字形打印
2018-02-16 剑指Offer - 做出来了- 字符流中第一个不重复的字符
2018-02-16 哇,好厉害,做出来啦 - 剑指Offer - 找出排序二叉树中第K大的节点
2018-02-16 剑指Offer - 经典的按照行来打印节点
2018-02-16 好厉害啊 - 剑指Offer - 二叉树的下一个结点
2018-02-16 又做出来一道题目 - 不错的 - 想了一会儿- 剑指Offer - 对称的二叉树