
《深度学习思考》的读书笔记
这篇文章还不错,有一些值得继续思考的地方。
《周志华教授:关于深度学习的一点思考》
https://mp.weixin.qq.com/s/DlJZII9yKtgskcjTBfZCtQ
Hinton 等通过“逐层训练后联合微调”来缓解梯度消失,使人们看到训练深层神经网络是可能的,由此激发了后来的研究,使得深度神经网络得以蓬勃发展。
例如该领域一个重要技术进步就是用图 2 右边的 ReLU 函数来代替以往常用的 Sigmoid 函数,由于前者在零值附近的导数比后者更“平缓”,使得梯度不会因下降得太快而导致梯度消失。
有人可能会问,既然机器学习界早就知道能通过把神经网络模型加深来提升学习能 力,为什么以往不这样做呢?除了前面提到的“梯度消失”这个技术障碍,这还涉及另外一个问题:因为存在“过拟合”(overfitting)。
小结一下,这套对“为什么深”的“复杂度解释”主要强调三点:第一,今天有大数据;第二,有强力的计算设备;第三,有很多有效的训练技巧。
但这套解释有个重要问题没解决:为什么扁平的(宽的)网络不如深度神经网络?
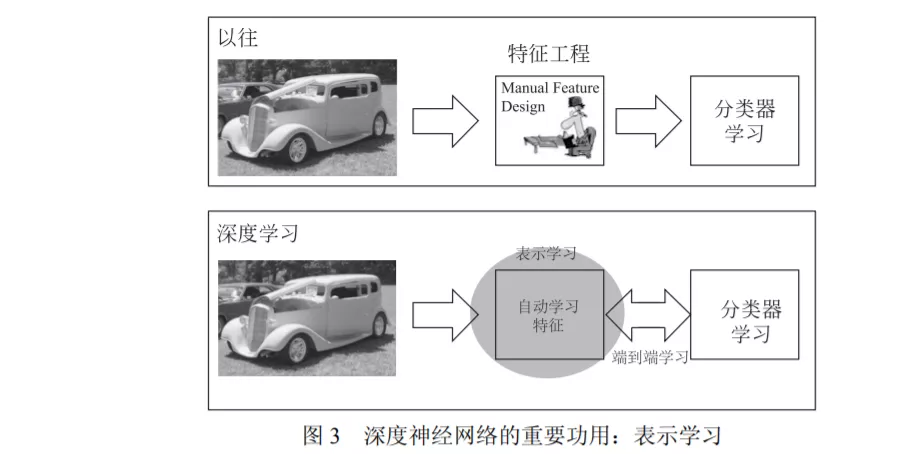
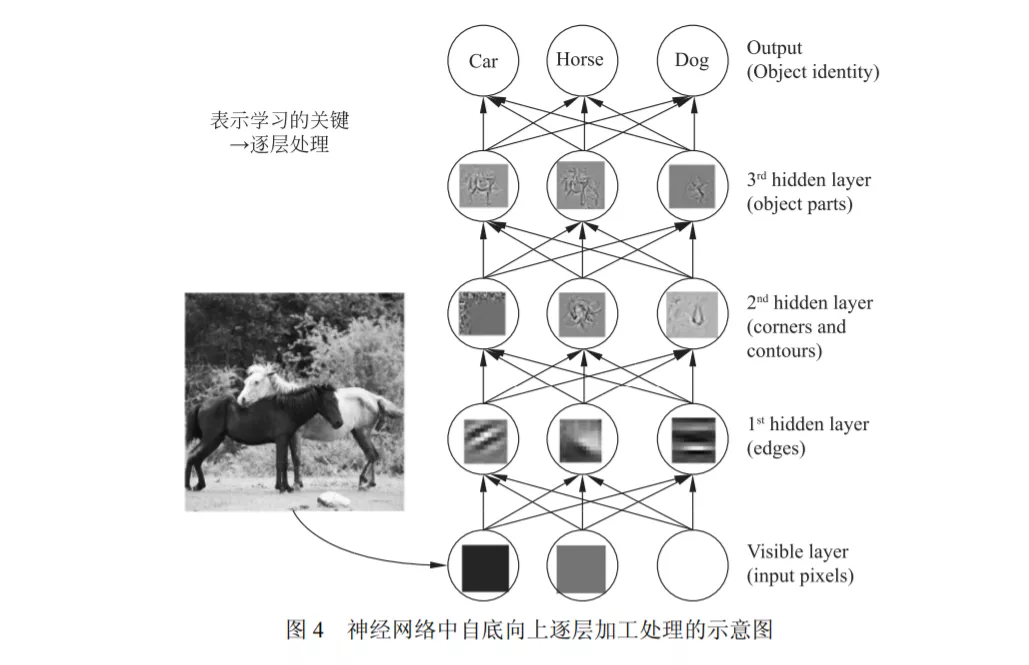
进一步我们再问:对表示学习来说最关键的是什么?我们的答案是:逐层加工处理。
虽然在真实的神经网络中未必有这么清晰的分层,但总体上确有自底向上不断抽象的趋势。
我们认为,“逐层加工处理”正是表示学习的关键,也是深度学习成功的关键因素之一。
以前已经有很多技术是在进行逐层 加工处理。例如决策树、Boosting 都是“逐层加工处理”模型,但是与深度神经网络相 比,它们有两个弱点:一是模型复杂度不够。
二是在学习过程中缺乏特征变换,学习过程始终在同一个特征空间中进行。
有三个关键因素:
逐层加工处理
内置特征变换
模型复杂度够
这是我们认为深度神经网络能够成功的关键原因
深度神经网络的一些最新研究进展,例如网络剪枝、权重二值化、模型压缩等,实质上都是试图在训练过程中适当减小网络复杂度。
深度神经网络的其他缺陷例如小数据上难以使用、黑箱模型、理论分析困难等就不赘述了。
机器学习领域有一个著名的“没有免费的午餐”定理[2],它告诉我们,没有任何一个模型在所有任务上都优于其他模型。
以往我们以为深度学习就是深度神经网络,只能基于可微构件搭建,现在我们知道了这里有更多的可能性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号