
Focal Loss的学习和理解
Focal Loss for Dense Object Detection 是ICCV2017的Best student paper,文章思路很简单但非常具有开拓性意义,效果也非常令人称赞。 GHM(gradient harmonizing mechanism) 发表于 “Gradient Harmonized Single-stage Detector",AAAI2019,是基于Focal loss的改进,也是个人推荐的一篇深度学习必读文章。
Focal Loss的引入主要是为了解决难易样本数量不平衡(注意,有区别于正负样本数量不平衡)的问题
正负样本数量非常不平衡。我们在计算分类的时候常用的损失——交叉熵的公式如下:
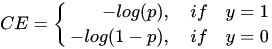
为了解决正负样本不平衡的问题,我们通常会在交叉熵损失的前面加上一个参数 ,即:
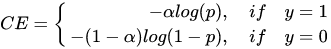
但这并不能解决全部问题。根据正、负、难、易,样本一共可以分为以下四类
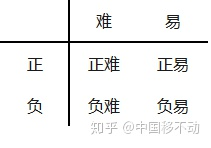
尽管 平衡了正负样本,但对难易样本的不平衡没有任何帮助。而实际上,目标检测中大量的候选目标都是像下图一样的易分样本。
这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。而Focal Loss的作者认为,易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注那些难分样本(这个假设是有问题的,是GHM的主要改进对象)
一个简单的思想:把高置信度(p)样本的损失再降低一些
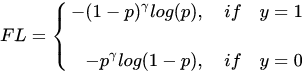
举例, 取2时,如果
,
,损失衰减了1000倍
最终的Focal Loss形式如下:
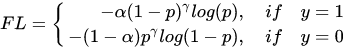
实验表明 取2,
取0.25的时候效果最佳。
训练过程关注对象的排序为正难>负难>正易>负易。
这就是Focal Loss,简单明了但特别有用。
def py_sigmoid_focal_loss(pred, target, weight=None, gamma=2.0, alpha=0.25, reduction='mean', avg_factor=None): pred_sigmoid = pred.sigmoid() target = target.type_as(pred) pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target) focal_weight = (alpha * target + (1 - alpha) * (1 - target)) * pt.pow(gamma) loss = F.binary_cross_entropy_with_logits( pred, target, reduction='none') * focal_weight loss = weight_reduce_loss(loss, weight, reduction, avg_factor) return loss
第二部分 GHM
Focal Loss存在什么问题呢?
首先,让模型过多关注那些特别难分的样本肯定是存在问题的,样本中有离群点(outliers),可能模型已经收敛了但是这些离群点还是会被判断错误,让模型去关注这样的样本,怎么可能是最好的呢?
其次, 与
的取值全凭实验得出,且
和
要联合起来一起实验才行(也就是说,
和
的取值会相互影响)。
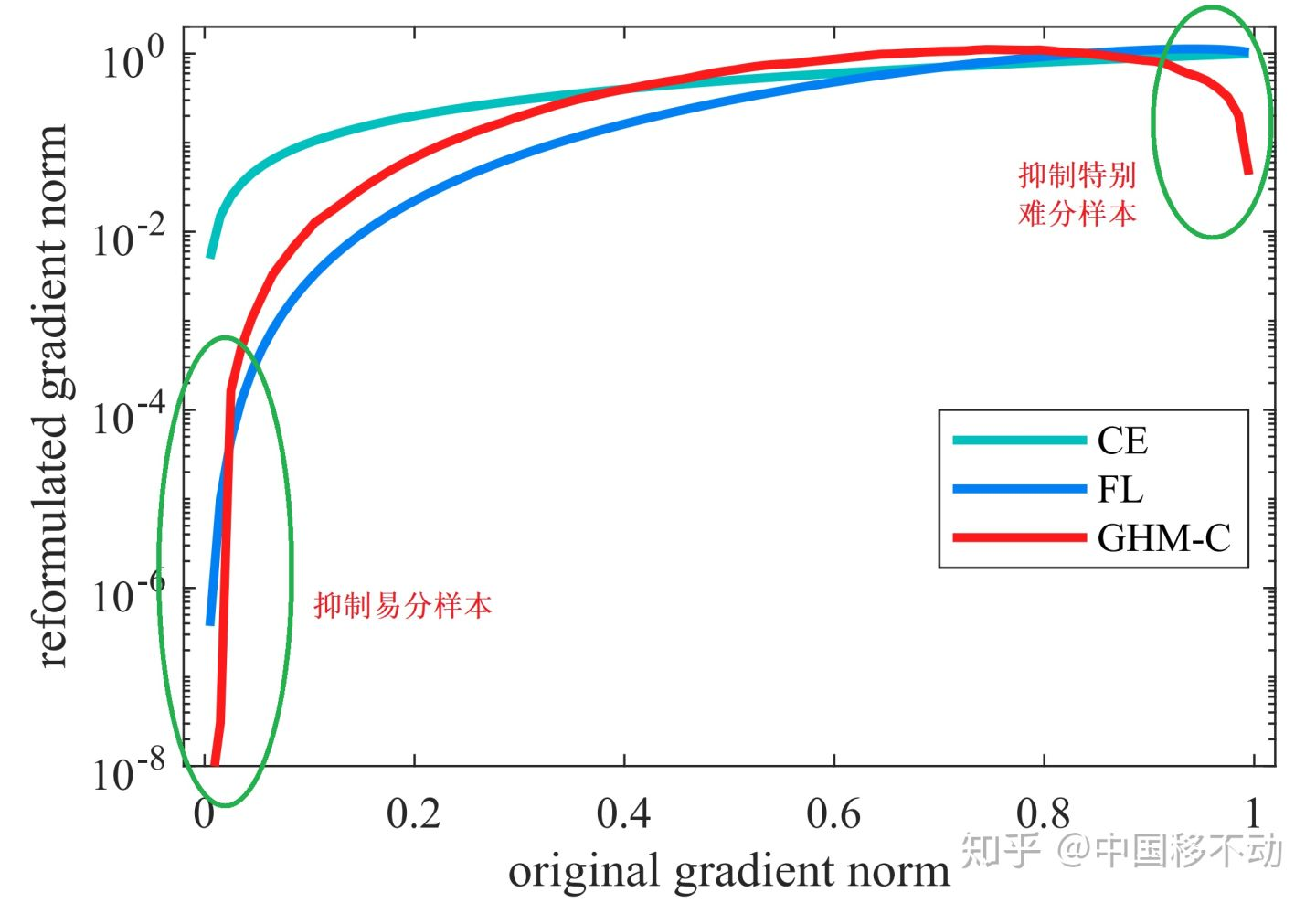
参考这篇文章:https://zhuanlan.zhihu.com/p/80594704

 浙公网安备 33010602011771号
浙公网安备 33010602011771号