JS_4DOM
认识DOM
文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法。DOM 将HTML文档呈现为带有元素、属性和文本的树结构(节点树)。
先来看看下面代码:

将HTML代码分解为DOM节点层次图:
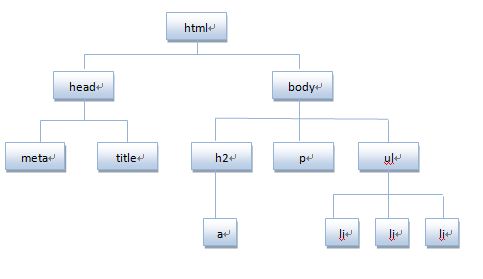
HTML文档可以说由节点构成的集合,DOM节点有:
1. 元素节点:上图中<html>、<body>、<p>等都是元素节点,即标签。
2. 文本节点:向用户展示的内容,如<li>...</li>中的JavaScript、DOM、CSS等文本。
3. 属性节点:元素属性,如<a>标签的链接属性href="http://www.imooc.com"。
节点属性:

遍历节点树:

以上图ul为例,它的父级节点body,它的子节点3个li,它的兄弟结点h2、P。
DOM操作:
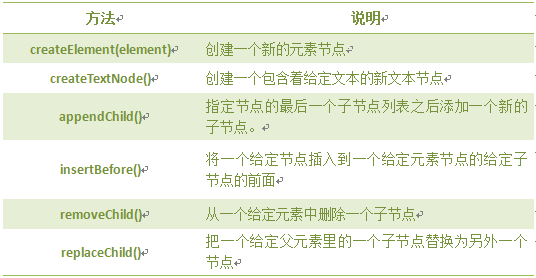
注意:前两个是document方法。
--------------------------------------------------------------------------
<h2 id="con">I love JavaScript</H2>
<p> JavaScript使网页显示动态效果并实现与用户交互功能。</p>
<script type="text/javascript">
var x=document.getElementById("con");
x.style.color="red";
x.style.backgroundColor="#CCC";
x.style.display;
</script>
===========================
getElementsByName()方法
返回带有指定名称的节点对象的集合。
语法:
document.getElementsByName(name)
与getElementById() 方法不同的是,通过元素的 name 属性查询元素,而不是通过 id 属性。
注意:
1. 因为文档中的 name 属性可能不唯一,所有 getElementsByName() 方法返回的是元素的数组,而不是一个元素。
2. 和数组类似也有length属性,可以和访问数组一样的方法来访问,从0开始。
看看下面的代码:
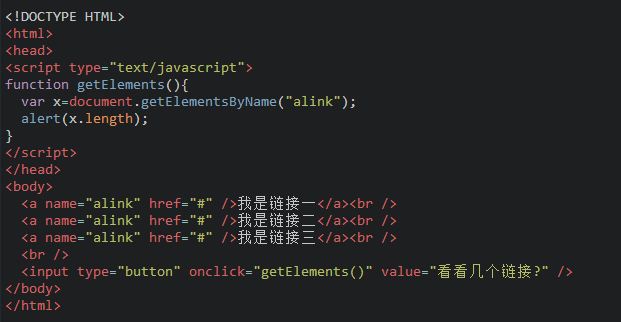
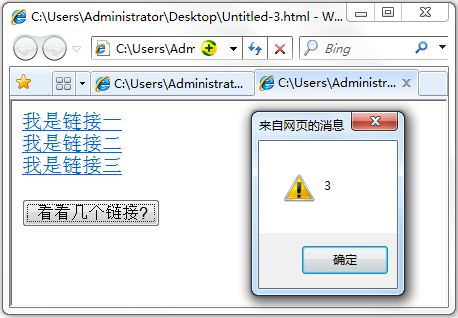
运行结果:
========================================
getElementsByTagName()方法
返回带有指定标签名的节点对象的集合。返回元素的顺序是它们在文档中的顺序。
语法:
document.getElementsByTagName(Tagname)
说明:
1. Tagname是标签的名称,如p、a、img等标签名。
2. 和数组类似也有length属性,可以和访问数组一样的方法来访问,所以从0开始。
看看下面代码,通过getElementsByTagName()获取节点。
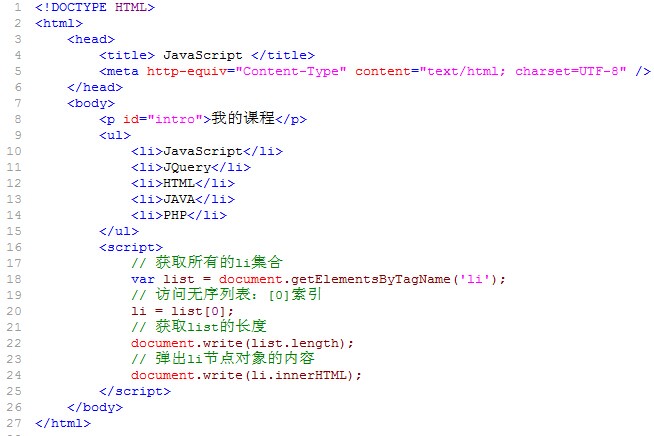
=====================================
区别getElementByID,getElementsByName,getElementsByTagName
以人来举例说明,人有能标识身份的身份证,有姓名,有类别(大人、小孩、老人)等。
1. ID 是一个人的身份证号码,是唯一的。所以通过getElementById获取的是指定的一个人。
2. Name 是他的名字,可以重复。所以通过getElementsByName获取名字相同的人集合。
3. TagName可看似某类,getElementsByTagName获取相同类的人集合。如获取小孩这类人,getElementsByTagName("小孩")。
把上面的例子转换到HTML中,如下:
<input type="checkbox" name="hobby" id="hobby1"> 音乐
input标签就像人的类别。
name属性就像人的姓名。
id属性就像人的身份证。
方法总结如下:

注意:方法区分大小写
通过下面的例子(6个name="hobby"的复选项,两个按钮)来区分三种方法的不同:
<input type="checkbox" name="hobby" id="hobby1"> 音乐 <input type="checkbox" name="hobby" id="hobby2"> 登山 <input type="checkbox" name="hobby" id="hobby3"> 游泳 <input type="checkbox" name="hobby" id="hobby4"> 阅读 <input type="checkbox" name="hobby" id="hobby5"> 打球 <input type="checkbox" name="hobby" id="hobby6"> 跑步 <input type="button" value = "全选" id="button1"> <input type="button" value = "全不选" id="button1">
1. document.getElementsByTagName("input"),结果为获取所有标签为input的元素,共8个。
2. document.getElementsByName("hobby"),结果为获取属性name="hobby"的元素,共6个。
3. document.getElementById("hobby6"),结果为获取属性id="hobby6"的元素,只有一个,"跑步"这个复选项。
======================================================
getAttribute()方法
通过元素节点的属性名称获取属性的值。
语法:
elementNode.getAttribute(name)
说明:
1. elementNode:使用getElementById()、getElementsByTagName()等方法,获取到的元素节点。
2. name:要想查询的元素节点的属性名字
看看下面的代码,获取h1标签的属性值:

运行结果:
h1标签的ID :alink
h1标签的title :getAttribute()获取标签的属值
---------------------------------------------
setAttribute()方法
setAttribute() 方法增加一个指定名称和值的新属性,或者把一个现有的属性设定为指定的值。
语法:
elementNode.setAttribute(name,value)
说明:
1.name: 要设置的属性名。
2.value: 要设置的属性值。
注意:
1.把指定的属性设置为指定的值。如果不存在具有指定名称的属性,该方法将创建一个新属性。
2.类似于getAttribute()方法,setAttribute()方法只能通过元素节点对象调用的函数。
===========================================
在文档对象模型 (DOM) 中,每个节点都是一个对象。DOM 节点有三个重要的属性 :
1. nodeName : 节点的名称
2. nodeValue :节点的值
3. nodeType :节点的类型
一、nodeName 属性: 节点的名称,是只读的。
1. 元素节点的 nodeName 与标签名相同
2. 属性节点的 nodeName 是属性的名称
3. 文本节点的 nodeName 永远是 #text
4. 文档节点的 nodeName 永远是 #document
二、nodeValue 属性:节点的值
1. 元素节点的 nodeValue 是 undefined 或 null
2. 文本节点的 nodeValue 是文本自身
3. 属性节点的 nodeValue 是属性的值
三、nodeType 属性: 节点的类型,是只读的。以下常用的几种结点类型:
元素类型 节点类型
元素 1
属性 2
文本 3
注释 8
文档 9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号