

IO多路复用
同步io和异步io,阻塞io和非阻塞io分别是什么,有什么样的区别?
io模式
对于一次io 访问(以read为例),数据会先拷贝到操作系统内核的缓冲区,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1.等待数据准备
2.将数据从内核拷贝到用户的进程中
在linux中系统产生了下面五种网络模式的方案:
1.阻塞i/o 2.非阻塞i/o 3.i/o多路复用 4.信号驱动i/o(实际应用中不多) 5.异步i/o
阻塞i/o
在linux中,默认情况下所有的socket都是阻塞的(blocking),一个经典的读操作流程大概是这个样的:
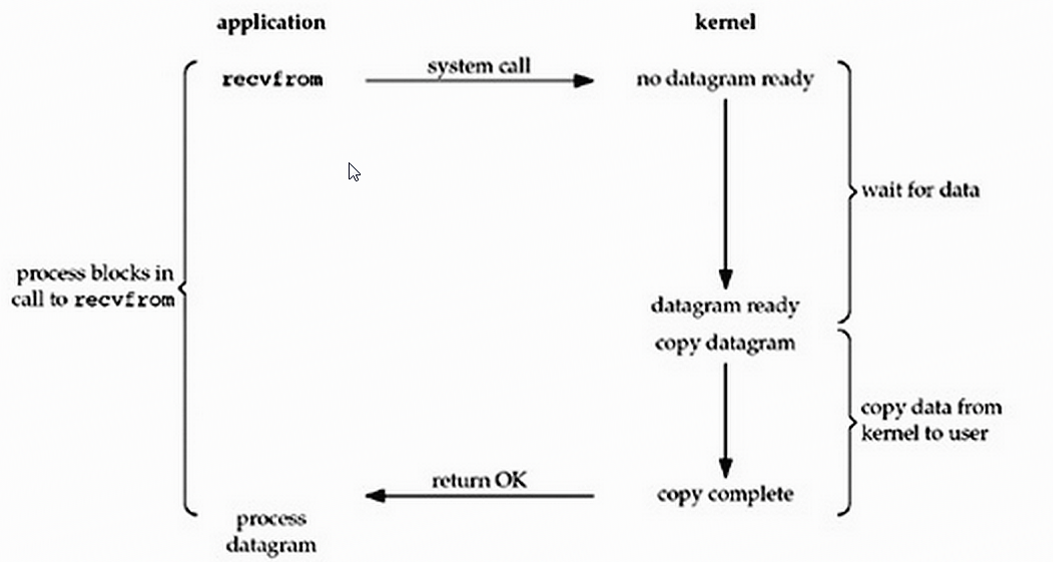
当用户进程调用recvfrom是,kernel就开始了第一阶段的io,准备数据,这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的,而在用户进程那,整个进程会被阻塞。当kernel一直等待数据准备好了,就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除阻塞状态,重新运行起来
即它的特点就是:在io执行的两个阶段都被block了
非阻塞I/O
linux下,可以通过设置socket使其变成了非阻塞,对一个非阻塞的socket执行读操作流程如下:
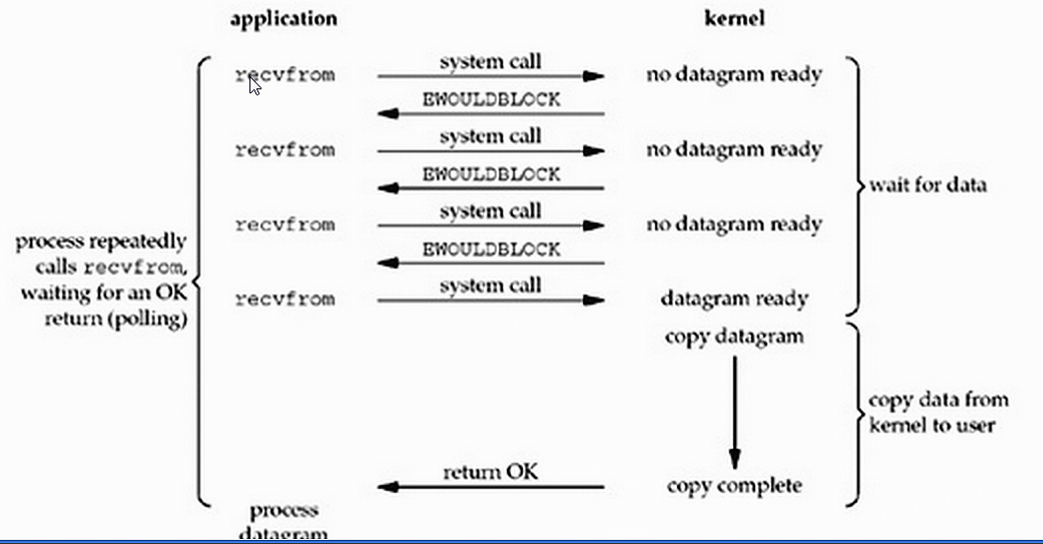
在用户进程发出read操作的时候,如果kernel中的数据还没有准备好的话,它不会阻塞用户进程,而是立刻返回一个error,从用户进程角度来说,它发起一个read操作之后,并不需要等待,而是马上得到了一个结果。用户进程判断结果如果是一个error,就知道了数据没有准备好,于是再次发送read操作,一旦kernel中数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到用户内存,然后返回
即它的特点就是:用户进程需要不断的主动的询问kernel数据准备好了没有
相当于我们第一次调用recv时,如果没有数据,我们可以去干其他的事情,从这个层面上来看,它比阻塞io要好,但仅仅只是非阻塞,下面我们看另外的模式:
I/O多路复用
io多路复用就是我们所说的select,poll,epoll,有些地方也称这种io方式为event driven io(事件驱动),select/epoll的好处就是在于单个process就可以同时处理多个网络连接的io。它的基本原理就是select ,poll,epoll这个function会不断的轮询所负责的所有的socket,当socket有数据的时候,就通知用户进程。
在单线程下,如果我们采取阻塞io,一收数据就卡住,我们就没有办法实现在一个单线程下操作多个socket连接,即单线程下阻塞io模式下是没有办法实现操作多路io
如果变成单线程下,非阻塞模式,建立100个连接,我们不知道哪个socket会发送数据,我们循环收取,100连接可能有5个发送了数据,95个没有发数据,但是没有关系,没有数据就直接走下一个循环不会卡住,最终把这5个数据收到,这种情况下我们已经实现了操作多个socket,在用户看来就已经是多并发了。不过有一个小问题,在从内核态到用户态发送的时候还是会卡住,等待一个copy时间,如果数据量小的话没有什么大问题,如果数据量大的话就会卡很久。虽然多并发,但是还是会卡
对于I/O多路复用:当用户进程调用了select,那么整个进程就会被block,同时,kernel会“监视”所有select负责所有的socket,当有一个socket中数据准备好,selct就会返回,这个时候用户进程再调用read,将数据从kernel拷贝到用户进程
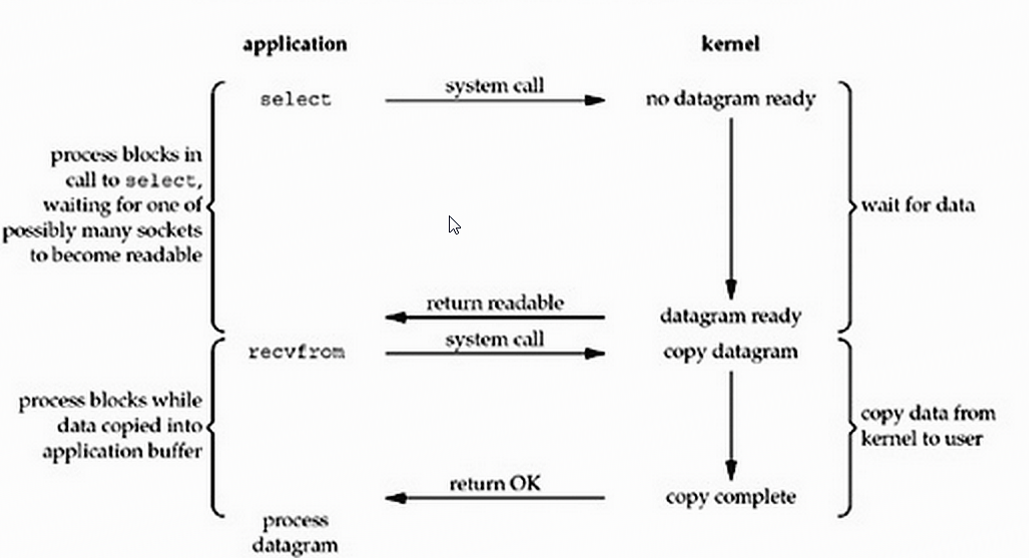
即它的特点就是:通过一种机制一个进程能同时等待多个文件描述符(可以理解为socket连接),而这些文件描述符其中的任意一个进入读就绪状态,select()函数局可以返回
和阻塞io的区别就是:一开始是一个socket调用recv卡住了,而io多路复用是,一开始可能有很多个socket调用select()
异步I/O

用户进程发起read操作之后,立刻就可以去干其他的事情,另一方面,从kernel角度,他们收到一个异步的read操作之后,首先会立刻返回(用户就可以在这个时候去操作其他的东西),所以不会对用户进程产生任何的block。然后kernel会等待数据准备完成,再将数据拷贝到用户内存,当这一切完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了
就相当于在最后从内核态拷贝到用户态那个环节也不会卡住
下面我们就详细了解一下多路复用的select,poll,epoll:
select:
select目前支持所有的平台,其良好的跨平台是是他的一个优点,缺点就是单个进程能够监视的文件描述符的数量是存在最大限制的,在linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升,
另外,select()所维护的存储大量的文件描述符的数据结构,随着文件miaoshu描述符的数量增大,其复制的开销也就不断的增大。同时,由于网络响应时间的延迟使得大量tcp连接处于非活跃状态,但调用select()会对所有的socket进行一次线性扫描,所以在一定程度上造成了浪费
poll:
和select没有多大的区别,但是poll没有最大文件描述符数量的限制,缺点也差不多,
epoll:
epoll是由内核直接支持的实现方法,几乎具备了之前的一切优点。windows不支持epoll,linux支持
简单的说, 如果有100socket交给内核去检测,只不过当100里面有一个链接活跃了,这个内核会告诉用户哪一个链接有数据,所以用户直接取到这个链接去读数据就行了,这就是epoll最主要的有点。如果我们有6万个链接里面有两个活跃,只要循环去这两个就可以了。
epoll也可以同时支持水平触发和边缘触发(水平触发就是说100个连接中有两个有数据,活跃了,内核返回给用户的程序,用户去取数据,但是这个时候用户有其他的事情,没有来得及去处理,没有去取数据,那数据还在内核态,除非用户主动的去取数据,这个数据才会从内核态拷贝到用户态。下一次可以继续监测再通知这个有数据的连接里;边缘触发就是说如果数据来了,告诉用户数据准备好了可以来取了,如果用户没有去取数据,那就数据就一直存储在内核中,但是下次不会再次通知,所以数据对于用户来说就没有了)
epoll没有最大socket数的限制,依然是io多路复用,不是异步io
上面讲了这么多,我们用代码来看看这个selec,poll,epoll,看看实现出来是什么样子的,
select:
python的select()方法直接调用操作系统的io调用,它监控sockets,open files,and pipes何时变成readable,writeable,或者通信错误,select()使得同时监控多个连接变的简单,并且这个比写一个长循环来等待和监控客户端连接更加的高效,因为select直接通过操作系统提供的c的网络接口进行操作的。而不是python解释器
下面我们就用echo server例子来了解select是如何通过单进程实现同时处理多个非阻塞的socket连接的
import select import socket import queue server = socket.socket() server.bind(('localhost',9999)) server.listen(1000) server.setblocking(False)#设置成非阻塞 inputs = [server,] outputs = [] msg_dic = {} while True: readable,writeable,exceptional = select.select(inputs,outputs,inputs) print(readable,writeable,exceptional) for r in readable: if r is server:#代表来了一个新连接 conn,addr = server.accept() print("来了一个新连接",addr) #是因为这个新建立的连接还没有发送数据过来,现在接受数据的话程序就会报错,所以要想实现这个客户端发数据来时,server端能够知道,就需要让 #select再检测这个conn inputs.append(conn) msg_dic[conn] = queue.Queue()#初始化一个队列,后面存要返回给这个客户端的数据 else: data = r.recv(1024) print("recv: ",data) msg_dic[r].put(data) #在下一次循环的时候发送数据 outputs.append(r)#放入返回的连接队列中 # r.send(data) # print("send done....") for w in writeable:#要返回给客户端的连接列表 data_to_client = msg_dic[w].get() w.send(data_to_client)#返回给客户端原数据 outputs.remove(w)#确保下次循环的时候writeable不返回已经处理完的连接 for e in exceptional: if e in outputs: outputs.remove(e) inputs.remove(e) del msg_dic[e]
首先我们要用到的是server.setblocking(False)把他设置成非阻塞模式,
然后我们设置了inputs,outputs两个列表,我们想要内核帮我们监测100个连接,我们要传一个列表,有多少个连接就把他都放在inputs中,
使用select.select(),里面有3个参数,rlist,wlist,xlist,分别是你想要监测的连接,想要输出的数据,100个中如果有5个断开了操作系统就会把这些放到xlist

如果运行出现了这个错误的话,这个就是说在inputs这个列表中没有放入你要监测的连接,这里我们自己server本身就是一个监测对象,所以可以写入inputs,监测自己,然后运行就没有问题了:inputs[server,]
select.select()返回三个数据:readable,writeable,exceptional
如果我们在select.select()直接server.accept(),这样连接客户端之后server端就直接结束运行,所以我们要在前面用for循环,循环readable
在接受数据的时候我们可能会遇到这样的错误:(直接用recv方法接受数据,就是说在accept()之后直接用conn.recv(1024)接受数据)

这个是由于连接过来之后客户端没有发送数据,server端没有收到数据但是不阻塞,所以就会报错,那么我们怎么知道他发数据的时候知道,那我们就可以把这个连接加入到inputs列表,这样在下一次检测的时候,如果活动了,说明有数据过来了:inputs.append(conn),这个时候相当于inputs这个列表里有server,conn两个连接,如果是返回活动的是server说明是又来了一个新连接,加入到inputs中,如果返回活动的是conn,那我们就可以直接接收数据,所以要用if判断。
在接收数据和发送数据的时候,我们接受数据可以放在一个队列字典中,等一会发送给客户端。所以我们在建立连接 的时候就可以给这个连接建立一个queue,然后在接受的数据之后可以先存到这个连接的字典中,那我们什么时候发送呢?
我们是在下一次循环发送数据,怎么实现呢,需要用我们刚才的outputs列表,你往outputs中放什么数据,你就会输出什么数据。所以就用到上面代码中的循环等,在用完之后要删除。
当然上述代码还不是很完善,当我们在关闭一个客户端运行的时候,我们server端也就停止运行了:

服务器端:
1 import queue 2 import select 3 import socket 4 5 server = socket.socket() 6 server.bind(("localhost",9999)) 7 server.setblocking(False) 8 server.listen(1000) 9 10 inputs = [server,] 11 outputs = [] 12 msg_dic = {} 13 14 while True: 15 print("waiting for next event....") 16 readable,writeable,exceptional = select.select(inputs,outputs,inputs) 17 #print(readable,writeable,exceptional) 18 for r in readable:#每个r就是一个新的连接 19 if r is server:#这里判断如果是server就表明有新的连接进入,之前我们就已经把我们自己server放在了inputs中 20 conn,addr = r.accept() 21 conn.setblocking(False) 22 inputs.append(conn)#为了不阻塞整个程序,我们不会立刻在这里开始接收客户端发来的数据, 把它放到inputs里, 下一次loop时,这个新连接 23 #就会被交给select去监听,如果这个连接的客户端发来了数据 ,那这个连接的fd在server端就会变成就续的,select就会把这个连接返回,返回到 24 #readable 列表里,然后你就可以loop readable列表,取出这个连接,开始接收数据了, 下面就是这么干的 25 msg_dic[conn] = queue.Queue()#接受到的客户端的数据之后,不立刻返回,而是存在消息队列中,以后发送 26 else:#如果r不是server的话,那就说明没有新的连接进入,我们需要接受客户端传过来的数据, 27 data = r.recv(1024) 28 if data: 29 print("收到来自[%s]发过来的数据:%s" %(r.getpeername()[0],data)) 30 msg_dic[r].put(data) 31 if r not in outputs: 32 outputs.append(r)#为了不影响处理与其他客户端的连接,这里不立刻返回数据 33 else:#如果收不到数据,代表客户端断开 34 print("客户端断开",r) 35 #清理已经断开的连接 36 if r in outputs: 37 outputs.remove(r) 38 inputs.remove(r) 39 del msg_dic[r] 40 for w in writeable: 41 try: 42 next_msg = msg_dic[w].get_nowait() 43 44 except queue.Empty: 45 print("client [%s]" % w.getpeername()[0], "queue is empty..") 46 outputs.remove(w) 47 48 else: 49 print("sending msg to [%s]" % w.getpeername()[0], next_msg) 50 w.send(next_msg.upper()) 51 for e in exceptional: 52 print("handling exception for ",e.getpeername()) 53 inputs.remove(e) 54 if e in outputs: 55 outputs.remove(e) 56 e.close() 57 58 del msg_dic[e]
客户端:
1 import socket 2 3 messages = [ b'This is the message. ', 4 b'It will be sent ', 5 b'in parts.', 6 ] 7 server_address = ('localhost', 9999) 8 9 socks = [ socket.socket(socket.AF_INET, socket.SOCK_STREAM), 10 socket.socket(socket.AF_INET, socket.SOCK_STREAM), 11 ] 12 for s in socks: 13 s.connect(server_address) 14 15 for message in messages: 16 17 # Send messages on both sockets 18 for s in socks: 19 print('%s: sending "%s"' % (s.getsockname(), message) ) 20 s.send(message) 21 22 # Read responses on both sockets 23 for s in socks: 24 data = s.recv(1024) 25 print( '%s: received "%s"' % (s.getsockname(), data) ) 26 if not data: 27 print('closing socket', s.getsockname() )
这样可以在客户端中多并发的执行多个socket
selector模块
直接上代码:
1 import selectors 2 import socket 3 4 sel = selectors.DefaultSelector() 5 6 7 def accept(sock, mask): 8 conn, addr = sock.accept() 9 print('accepted', conn, 'from', addr) 10 conn.setblocking(False) 11 sel.register(conn, selectors.EVENT_READ, read) 12 13 14 def read(conn, mask): 15 data = conn.recv(1000) 16 if data: 17 print('echoing', repr(data), 'to', conn) 18 conn.send(data) 19 else: 20 print('closing', conn) 21 sel.unregister(conn) 22 conn.close() 23 24 25 sock = socket.socket() 26 sock.bind(('localhost', 9999)) 27 sock.listen(100) 28 sock.setblocking(False) 29 sel.register(sock, selectors.EVENT_READ, accept) 30 31 while True: 32 events = sel.select()#默认是阻塞,有活动连接就返回活动的连接列表 33 for key, mask in events: 34 callback = key.data#相当于调用accept 35 callback(key.fileobj, mask)#key.fileobj就是文件句柄,相当于上面程序的r
selector.DefaultSelector()和select.select()差不多,生成一个select对象,然后下面用sel.register(sock,selectors.Event_READ,accept)注册一个事件,让它监听,只要来一个新的连接就调用accept函数
events = sel.select()这句话也有可能调用的是epoll,看你系统支持什么
然后在结合客户端代码,就可以了,速度很快:

初次学习,做做笔记,用于加深印象,如果有错误的话,希望大家积极纠正,在此谢过大家啦

