本地Pycharm将spark程序发送到远端spark集群进行处理
前言
最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置,spark集群安装并集成到hadoop集群,没有配置的朋友可以参考文章搞一搞.
本篇博客主要说明,如何通过pycharm将程序发送到远端spark集群上进行操作处理.
注意:本地环境与远端的集群必须可以互相通信(建议配置内网虚拟机,同一网段).不然的话本地程序在接收spark集群发来的数据会报连接超时.如果本地与远端不在同一网段,这篇博客可能无法给你解决问题,仅供参考
说明
本地环境:指本人开发环境,即pycharm运行的电脑
远端集群:指服务端spark集群
Python环境:本地与远端python相同 Python3.5.6(不知道版本不同是否会有问题)
配置流程
配置本地环境spark
将远端集群中master服务器上的spark打包,并复制到本地环境中
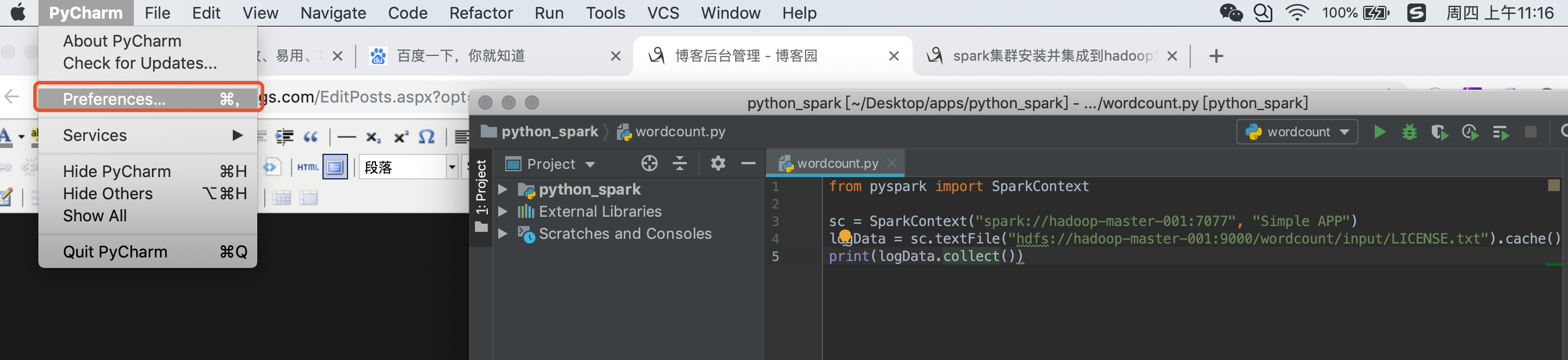
配置pycharm
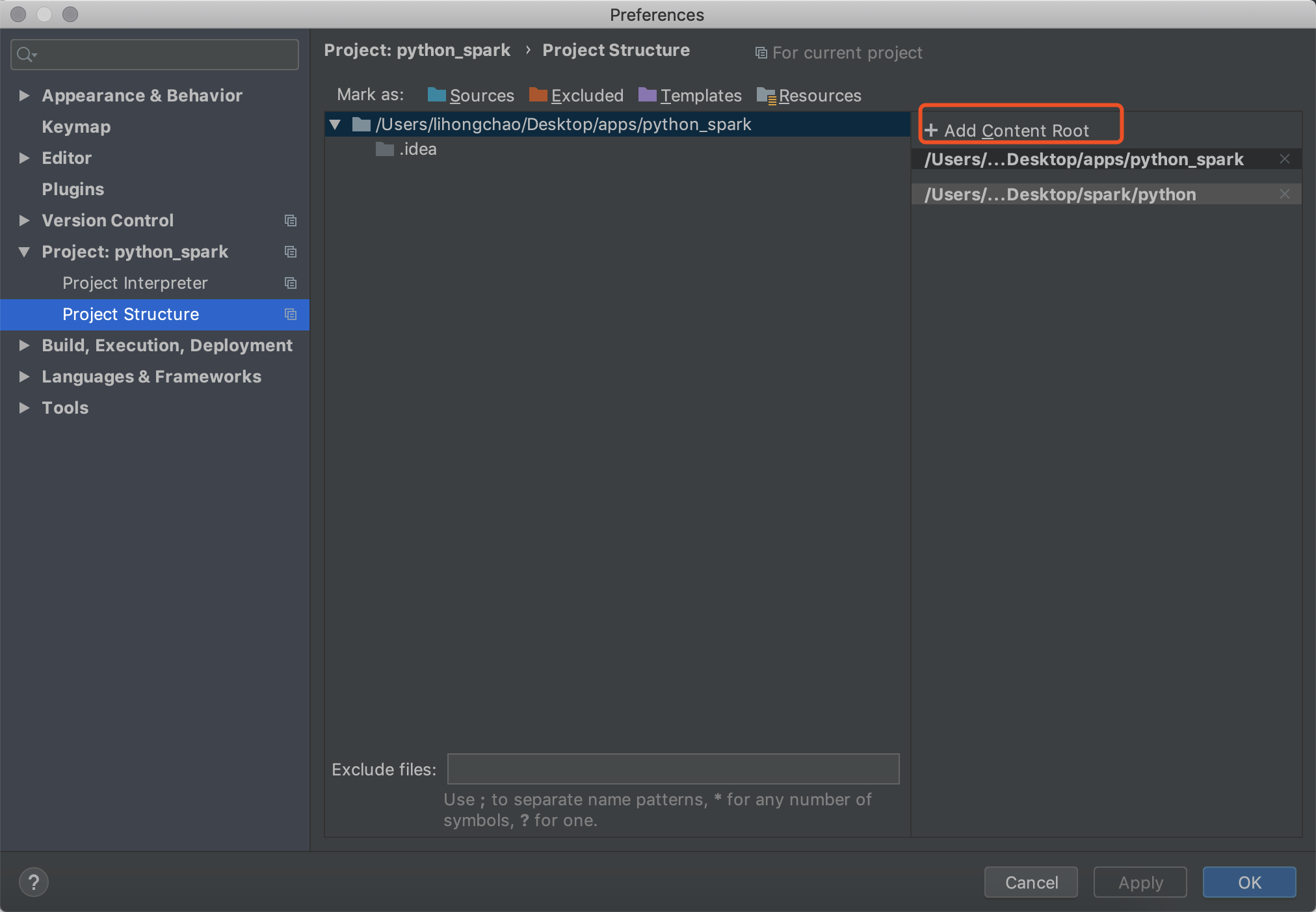
添加新的路径
新的路径地址是你本地spark路径下的python文件夹
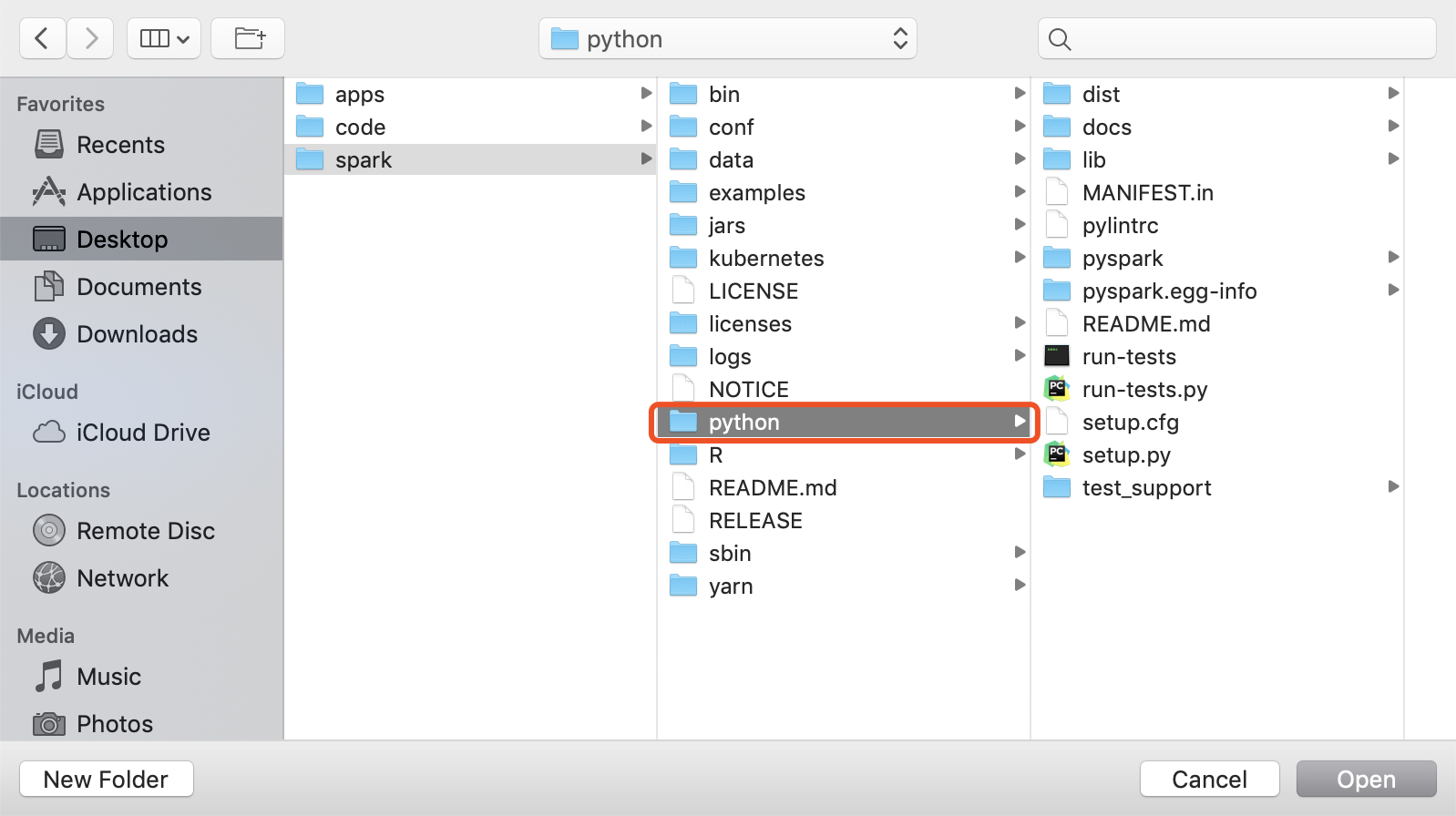
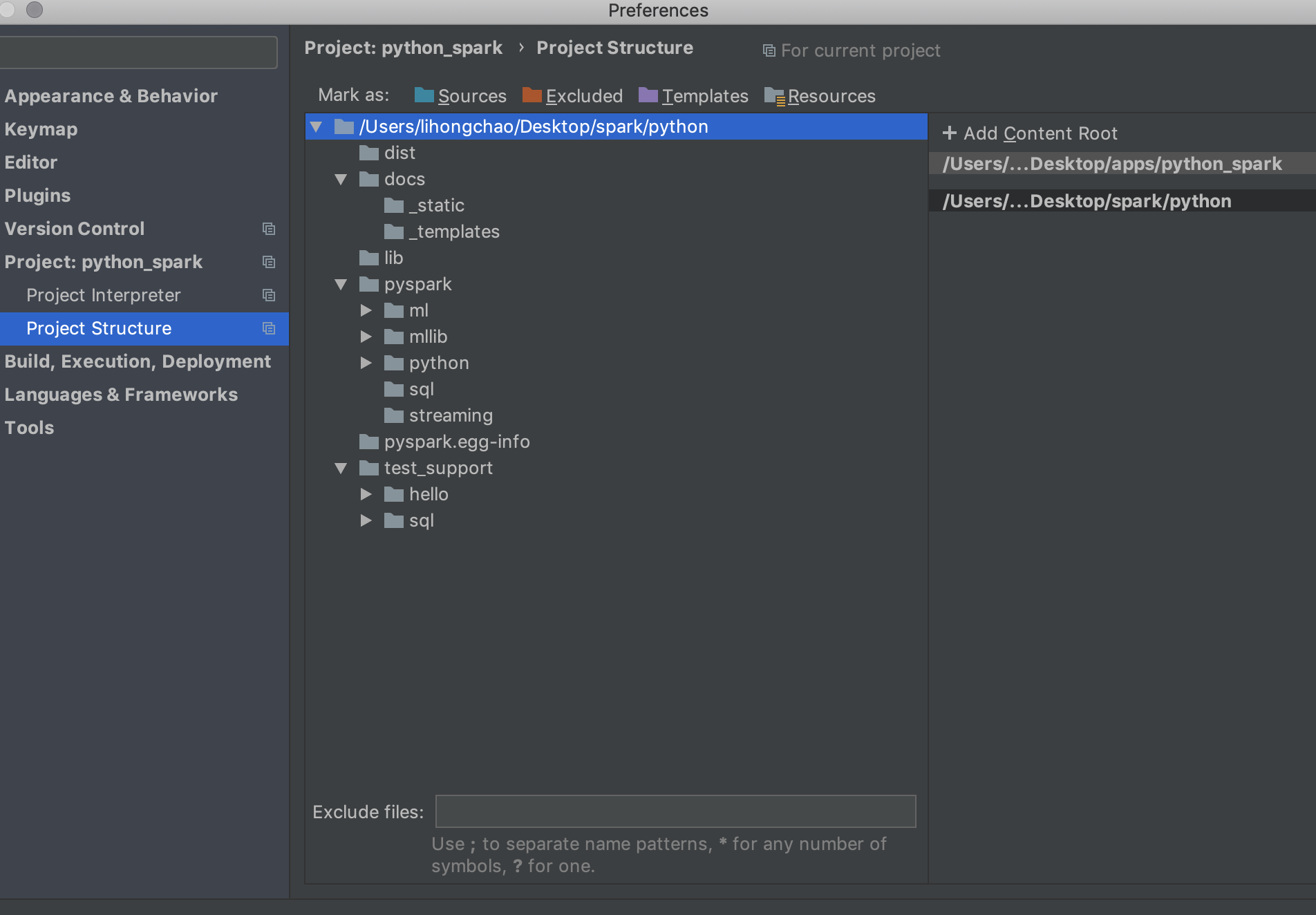
指定这个路径后,我们在编写程序的时候导入SparkContext才不会报错
配置环境变量
新建一个文件,配置Edit Configurations
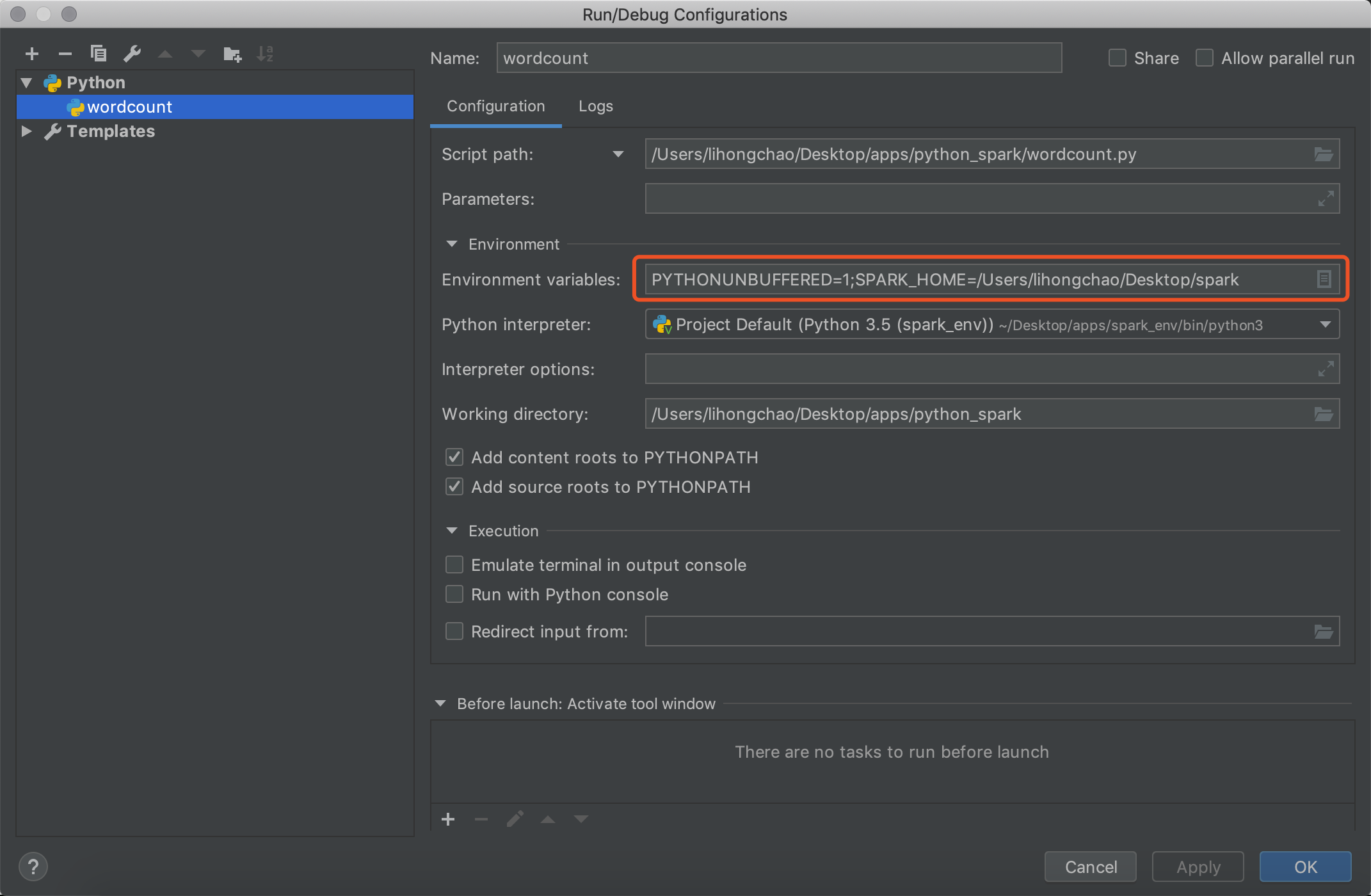
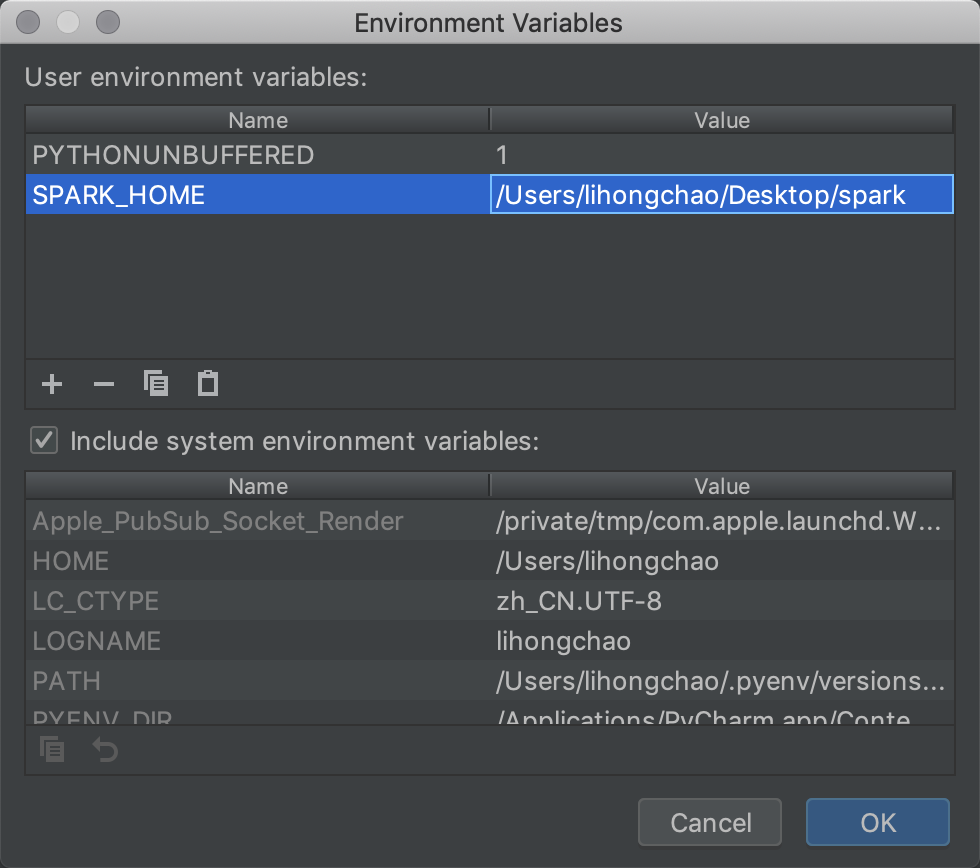
上图红框中是我已经配置好的,添加SPARK_HOME变量
Value表示你本地spark的绝对路径
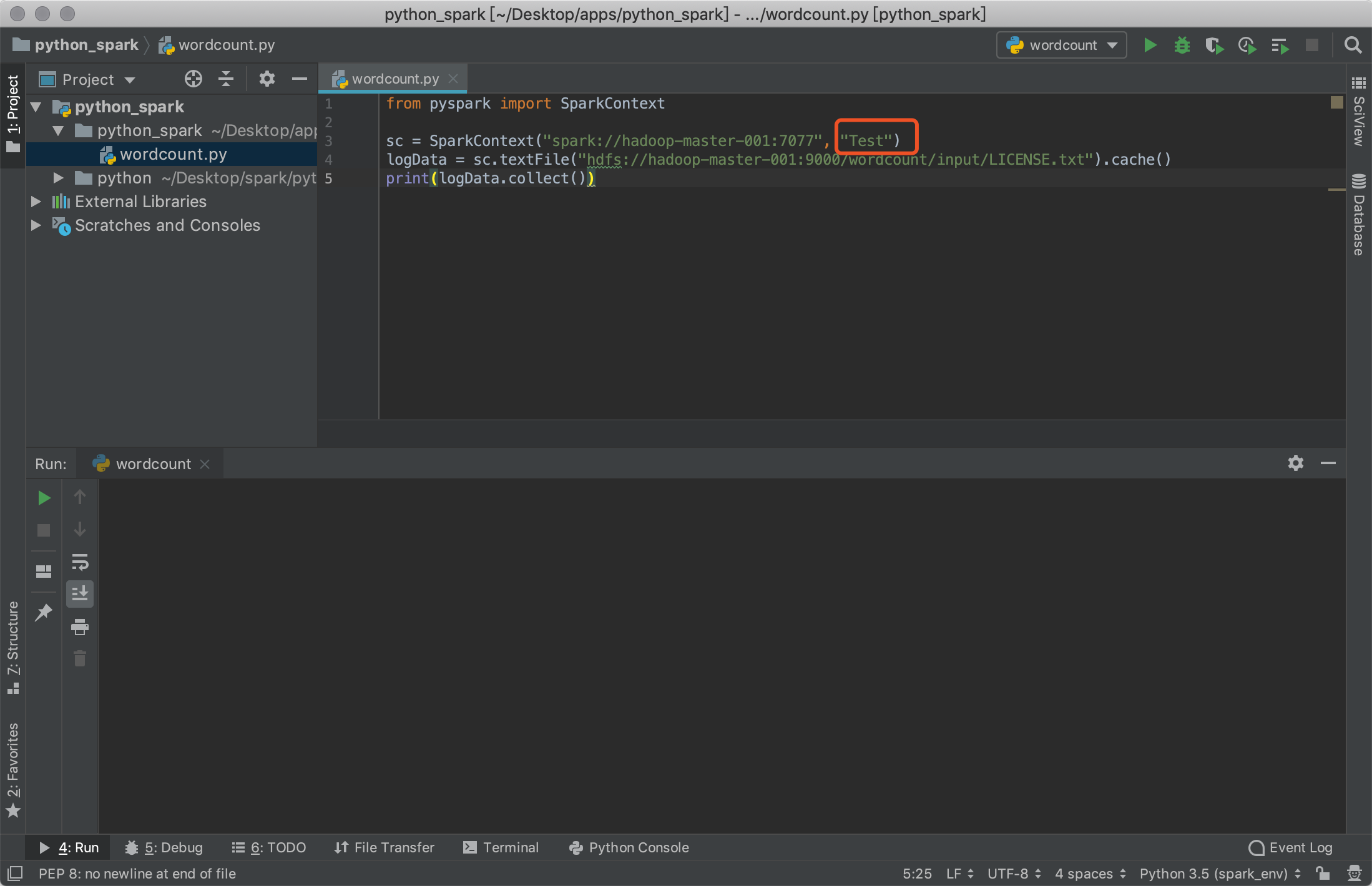
测试
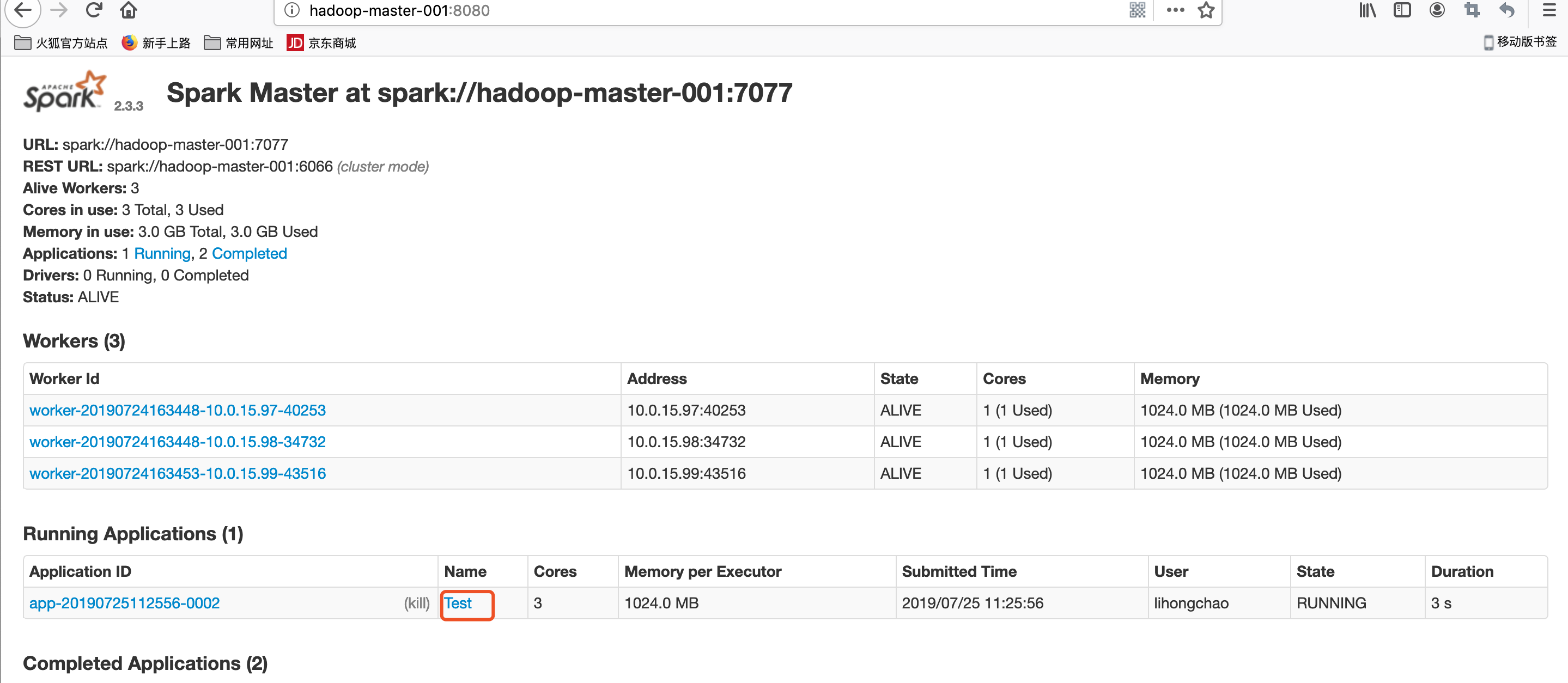
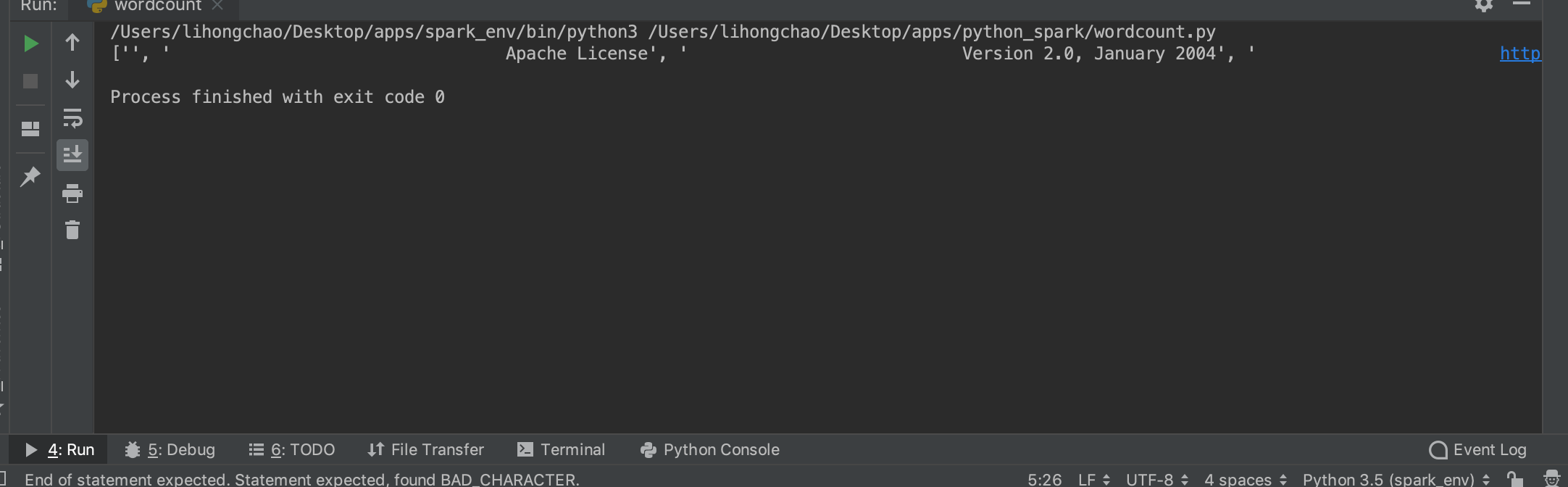
参考地址
https://blog.csdn.net/mycafe_/article/details/79430320#commentsedit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号