


cfs浅析
之前的调度器
cfs之前的linux调度器一般使用用户设定的静态优先级,加上对于进程交互性的判断来生成动态优先级,再根据动态优先级决定进程被调度的顺序,以及调度后可以运行的时间片。
反过来,随着进程的运行,内核可能发现其交互性发生改变,从而调整其动态优先级(奖励睡眠多的交互式进程、惩罚睡眠少的批处理进程)。
cfs原理
cfs定义了一种新的模型,它给cfs_rq(cfs的run queue)中的每一个进程安排一个虚拟时钟,vruntime。
如果一个进程得以执行,随着时间的增长(也就是一个个tick的到来),其vruntime将不断增大。没有得到执行的进程vruntime不变。
而调度器总是选择vruntime跑得最慢的那个进程来执行。这就是所谓的“完全公平”。
为了区别不同优先级的进程,优先级高的进程vruntime增长得慢,以至于它可能得到更多的运行机会。
如下图所示(注意,图中的tick、load、vruntime只是个示意):
vruntime标准化
随着系统的不断运行,进程的vruntime不断增长。如果溢出了怎么办呢?
cfs给cfs_rq也设置了一个vruntime(cfs_rq->min_vruntime),这个时钟有两个特性:1)单调递增;2)如果满足第1点,让它等于cfs_rq中最小的虚拟时钟。(cfs_rq->min_vruntime一般情况下总是等于队列中最小的vruntime,不过下面会提到进程睡眠唤醒的情况,这时新唤醒的进程的vruntime可能小于cfs_rq->min_vruntime。而cfs_rq->min_vruntime并不会因此而减小,依然保持单调递增。)
选择进程时,总是以进程的vruntime与cfs_rq->min_vruntime之差来作为判断依据的。而这个差值基本上是不可能溢出的。这个差值被称作normalized vruntime(标准化的虚拟时钟)。
有了这个normalized vruntime,在进程enqueue/dequeue、或者是在cfs_rq间迁移、等情况下,进程的vruntime就有了统一的描述。
当进程dequeue时,其vruntime -= cfs_rq->min_vruntime。而当它再次enqueue时,vruntime += cfs_rq->min_vruntime(注意,两个cfs_rq可能不是同一个)。
处理睡眠进程
linux的调度器一直认为,应该对交互式进程(也就是睡眠多的进程)给予奖励。这个在cfs里面是怎么表现的呢?
区别于其他的情况,如果进程因为睡眠而dequeue,这时vruntime继续保持原值,并不做normalize。那么,等它被唤醒的时候,vruntime仍旧是一个较小的值,相当于得到了奖励。
但是,如果只是简单的不做normalize,睡眠进程由于得不到运行,其虚拟时钟不增长,那么一个进程就可以在漫长的睡眠之后,进行报复性的满载运行。这显然是不合理的。
所以,进程在被唤醒之后,需要对其vruntime进行修正。vruntime=max(vruntime, cfs_rq->min_vruntime - thresh)。
即,分两种情况:
1、如果进程只是短暂睡眠,其vruntime > cfs_rq->min_vruntime - thresh,则vruntime保持原样;
2、长时间睡眠,其vruntime <= cfs_rq->min_vruntime - thresh,则vruntime修改为cfs_rq->min_vruntime - thresh。
这里的thresh可以认为等于一个调度延迟。
调度延迟
那么,什么是调度延迟呢?
cfs的原理是选择vruntime最小的那个进程来运行。而如果cfs_rq中有两个旗鼓相当的进程呢?可能导致每个tick都会触发一次switch。(A进程运行一个tick之后,vruntime超过B进程,于是switch到B进程;而B进程运行一个tick之后,vruntime又超过A进程,于是又switch到A进程;如此反复……)
这样做虽然很公平,但是无疑带来了很大的调度开销,是不可接受的。
于是cfs为权衡公平性与性能,引入了调度延迟的概念。有人将调度延迟定义为:保证cfs_rq中的每个进程至少运行一次的时间间隔。但是我觉得这并不准确,因为cfs并不提供“至少运行一次”这样的保证。在我看来,调度延迟就是提供一个延迟,使得cfs并不是每个tick都去检查是否需要re-schedule,而是要延迟到一定程度再re-schedule。
对于不同的进程,当它在执行的时候,这个re-schedule的延迟是不一样的。如果把调度延迟视作一个时间片,那么cfs_rq中的每个进程将以其优先级为权重,瓜分这个时间片。进程分得的时间片大小跟其优先级是成正比的,也就是说,优先级高的进程能够执行更多的时间,然后才会被re-schedule。
在cfs_rq稳定的情况下(也就是没有进程enqueue/dequeue、也没有进程修改优先级、等),因为vruntime的增长率也是跟进程的优先级成正比的,所以随着进程按优先级权重瓜分调度延迟,这些进程在各自用完一个时间片之后vruntime将得到同等的增长,并且在一个调度延迟内,每个进程都将被执行一次(这也就是为什么调度延迟会被定义为“保证每个进程至少运行一次”)。
但是当cfs_rq发生变化,情况就有所不同。随着不断有进程enqueue/dequeue、或者改变优先级,正在执行的进程的时间片是随时在变化的。如果某一时刻,cfs发现正在执行的进程用完了它的时间片,就会re-schedule;或者当正在执行的进程的vruntime与cfs_rq中最小的vruntime之差大于它的时间片时,也会re-schedule。
对应到前面讨论的睡眠唤醒,长时间睡眠的进程在被唤醒之后,vruntime修改为cfs_rq->min_vruntime减去一个调度延迟。那么这个被唤醒的进程很有可能会将正在执行的进程抢占掉。被唤醒的进程很可能优先得到执行,并且一开始会得到更多的cpu时间,以使其vruntime追赶上其他进程。但是之后它便不能再得到这样的优待,因为对于vruntime相同的进程来说,能分得多少cpu时间决定于它的优先级,而优先级并不因为睡眠唤醒而改变。
通常,调度延迟是一个固定的值,比如20ms。而如果cfs_rq中的进程过多,每个进程就会分得很小的时间片,这也可能频繁的触发调度。于是,这种情况下调度延迟会按cfs_rq中的进程数线性扩展。(注意,如这里所描述的,调度延迟其实是一个跟cfs_rq相对应的概念。不同的cfs_rq进程数可能不同,则它们的调度延迟也不相同。)
load balance
在cfs之前,进程的优先级通常用nice、priority这样的单词来表示。而在cfs中则通常使用load(负载)这个词。进程有进程的load、cfs_rq有cfs_rq的load。
一开始感觉这个“load”用得很奇怪,不过后来慢慢有了些体会:nice、priority是站在进程的角度,描述了其自身的优先级;而load则是站在cfs_rq的角度,描述了进程给cfs_rq带来的负载。
对于进程的load,一方面它隐含了进程的优先级。进程的load越高,vruntime也就跑得越慢,为了增长同等的vruntime所获得的执行时间也就越多;另一方面,进程的load也体现了它给cfs_rq施加的负载。对于load越高的进程,为了给它增长同等的vruntime,需要花费越多的cpu时间。
而cfs_rq的load则体现了cfs_rq中的进程给它施加的总的负载。cfs_rq中的进程越多、进程的优先级越高,增长同等的cfs_rq->min_vruntime所花费的时间就越多。
再来说说load_balance,也就是负载均衡。详见:《linux内核SMP负载均衡浅析》。
其目的把需要做的事情均匀分配到系统中的每个cpu上。假设所有cfs_rq中的进程的load之和为M,cpu个数为n,在负载均衡的情况下,对于一个load为a的进程来说,它将分得a*n/M的cpu时间。
load_balance是怎么做的呢?顾名思义,它所要做的事情就是将进程的load均匀分布在每一个cpu所对应的cfs_rq中(通过在cfs_rq之间迁移一些进程来实现)。
那么为什么load均匀分布在每个cfs_rq中就能实现负载均衡呢?
继续前面的例子,其实只要每个cfs_rq的load都等于M/n,无论这个load为a的进程处于哪个cfs_rq中,它分得的cpu时间都是a*n/M。
组调度
关于组调度,详见:《linux组调度浅析》。简单来说,引入组调度是为了实现做一件事的一组进程与做另一件事的另一组进程的隔离。每件“事情”各自有自己的权重,而不管它需要使用多少进程来完成。
在cfs中,task_group和进程是同等对待的,task_group的优先级也由用户来控制(通过cgroup文件cpu.shares)。
实现上,task_group和进程都被抽象成schedule_entity(调度实体,以下简称se),上面说到的vruntime、load、等这些东西都被封装在se里面。
而task_group除了有se之外,还有cfs_rq。属于这个task_group的进程就被装在它的cfs_rq中(“组”不仅是一个被调度的实体,也是一个容器)。
组调度引入以后,一系列task_group的cfs_rq组成了一个树型结构。树根是cpu所对应的cfs_rq(也就是root group的cfs_rq)、树的中间节点是各个task_group的cfs_rq、叶子节点是各个进程。
在一个task_group的两头,是两个不同的世界,就像《盗梦空间》里不同层次的梦境一样。
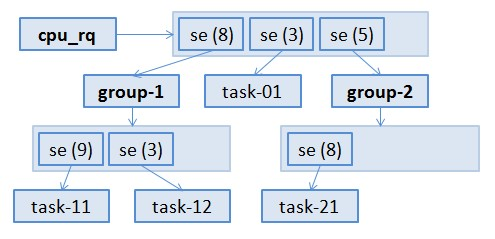
以group-1为例,它所对应的se被加入到父组(cpu_rq)的cfs_rq中,接受调度。这个se有自己的load(由对应的cpu.shares文件来配置),不管group-1下面有多少个进程,这个load都是这个值。父组看不到、也不关心group-1下的进程。父组只会根据这个se的load和它执行的时间来更新其vruntime。
当group-1被调度器选中后,会继续选择其下面的task-11或task-12来执行。这里又是一套独立的体系,task-11与task-12的vruntime、load、等这些东西只影响它们在group-1的cfs_rq中的调度情况。
树型结构中的每一个cfs_rq都是独立完成自己的调度逻辑。不过,从cpu配额上看,task_group的配额会被其子孙层层瓜分。
例如上图中的task-11,它所在的group-1对应se的load是8,而group-1下两个进程的load是9和3,task-11占其中的3/4。于是,在group-1所对应的cfs_rq内部看,task-11的load是9,而从全局来看,task-11的load是8*3/4=6。
而task_group下的进程的时间片也是这样层层瓜分而来的,比如说group-1的cfs_rq下只有两个进程,计算得来的调度延迟是20ms。但是task-11并非占其中的3/4(15ms)。因为group-1的se的load占总额的8/(8+3+5)=1/2,所以task-11的load占总额的1/2*3/4=3/8,时间片是20ms*3/8=7.5ms。
这样的瓜分有可能使得task_group里面的进程分得很小的时间片,从而导致频繁re-schedule。不过好在这并不影响task_group外面的其他进程,并且也可以尽量让task_group里面的进程在每个调度延迟内都执行一次。
cfs曾经有过时间片不层层瓜分的实现,比如上图中的task-11,时间片算出来是15ms就是15ms,不用再瓜分了。这样做的好处是不会有频繁的re-schedule。但是task_group里的进程可能会很久才被执行一次。
瓜分与不瓜分两种方案的示例如下(还是继续上图的例子,深蓝色代表task-11、浅蓝色是task-12,空白是其他进程):

两种方案好像很难说清孰优孰劣,貌似cfs也在这两种方案间纠结了好几次。
在进程用完其时间片之前,有可能它所在的task_group的se先用完了时间片,而被其父组re-schedule掉。这种情况下,当这个task_group的se再一次被其父组选中时,上次得到执行、且尚未用完时间片的那个进程将继续运行,直到它用完时间片。(cfs_rq->last会记录下这个尚未用完时间片的进程。)
组调度与load balance
在SMP情况下,按cpu的个数,一个task_group拥有多个se及其对应的cfs_rq。属于这个task_group的进程可能出现在这些不同的cfs_rq之中(意味着这些进程运行在不同cpu上)。这些cfs_rq可能存在load不均的情况。
为了解决这个问题,大致有两种方法:
1、在load_balance的时候,为每一个task_group都执行一遍load_balance逻辑,使得每个task_group内部都趋于load均衡;
2、load_balance只针对root group。然后如果task_group内部的load不均,则load高的那个cfs_rq所对应的se的load得到提升,从而使得这个cfs_rq分得更多时间、或者引发root group的load_balance;
第一种方法貌似更完美,但是代价更大。不过其实它并非真正完美,比如task_group下只有两个RUNNING状态的进程,一个load很高、一个load很低,那么无论如何也没法在这个task_group内做到balance。并且,在对一个task_group进行load_balance的时候,并不知道其他task_group imbalance的情况,所以全局的balance也很难做到。
所以内核选择了方法二。下面再仔细分析下:
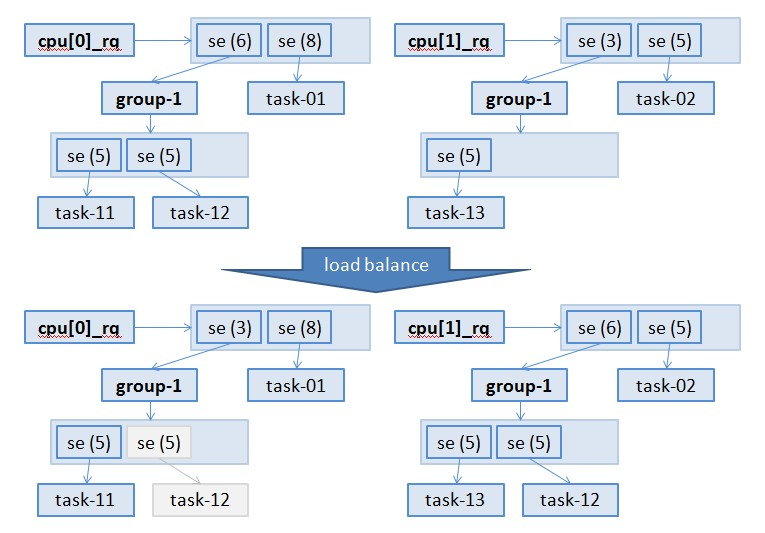
方法二有两个要素:
1、针对task_group内部的load不均,修正task_group在不同cpu上的se的load;
task_group在每个cpu上的se的load是以其对应cfs_rq的load为权重,瓜分cpu.shares而得来。
如图,group-1在cpu-0上的cfs_rq的load为5+5=10,在cpu-1上的cfs_rq的load为5,而设group-1的cpu.shares为9,则cpu-0上的se的load为:9*10/(10+5)=6。
2、因为task_group内部的load不均可能引起task_group对应各个cpu上的se的load不均,从而引起父组的load不均,继而引起root group的load_balance,所以load_balance在做进程迁移的时候,需要考虑task_group内的进程;
在触发进程迁移的时候,对于cpu上的每个task_group的cfs_rq都会试图进行一定量的进程迁移。
如图,load_balance之前两个cpu的load是不均的(6+8 > 3+5)。而load_balance之后,通过迁移group-1下的task-12,使得两个cpu的load均衡(3+8 = 6+5)。
task_group下的进程迁移,并不会影响进程所分得的load。比如task-12,在它被迁移之前,它所在的cfs_rq所对应的se的load是6,而它在这个cfs_rq中能分得一半的load,全局来看,load是3;迁移之后,task-12同样分得6*5/(5+5)=3的load。类似的,在task-12迁移前后,task-11和task-13所能分得的load也是相同的。

