10/21
今日考题
1.说说数据分析的整体工作流程
明确需求
收集数据
数据清洗
数据分析
数据报告+可视化
2.针对数据清洗核心流程及常用方法有哪些
读取数据 read_sql read_excel read_html read_csv
数据概览 index info columns shape...
简单处理 移除行列标签首尾空格.. # 这个要先做不然后面不好处理
重复值处理 drop_duplicates()
缺失值处理 dropna() fillna() isnull notnull
异常值处理 删除或者填充
文本字符处理 正则 分隔 切片索引
时间数据 转 Y m d H M S
3.说说去哪儿网实战案例中截止目前都清洗了哪些数据各自如何做的
列字段移除收尾空格 [i.strip() for i in data.columns]
重复值处理 df.drop_duplicates(inplace=True)
异常值处理
先通过公式筛选异常值 (df['价格'] - df['价格'].mean()) / df['价格'].std()
然后找到明显的不合理处df[df['节省'] > df['价格']]
一并删除
删除无用字段 df.drop(columns='',inplace = True)
出发地缺失 通过正则从路线中拿到缺失的出发地 然后加入缺失的地方
目的地缺失 与上面同理 先筛选然后用列表生成式一次性一行代码解决
数字类缺失 通过平均值 中位数等填充
复习巩固
- 数据清洗工作流程
- 数据清洗概念
- 数据清洗基本操作
- 去哪儿网实战案例
内容概要
主体:机械学习算法模型
要求:掌握基本推导流程和核心理论即可
- 线性回归模型
一元线性回归模型
多元线性回归模型
详细讲解
线性回归模型
# 如何查找变量之间的线性关系
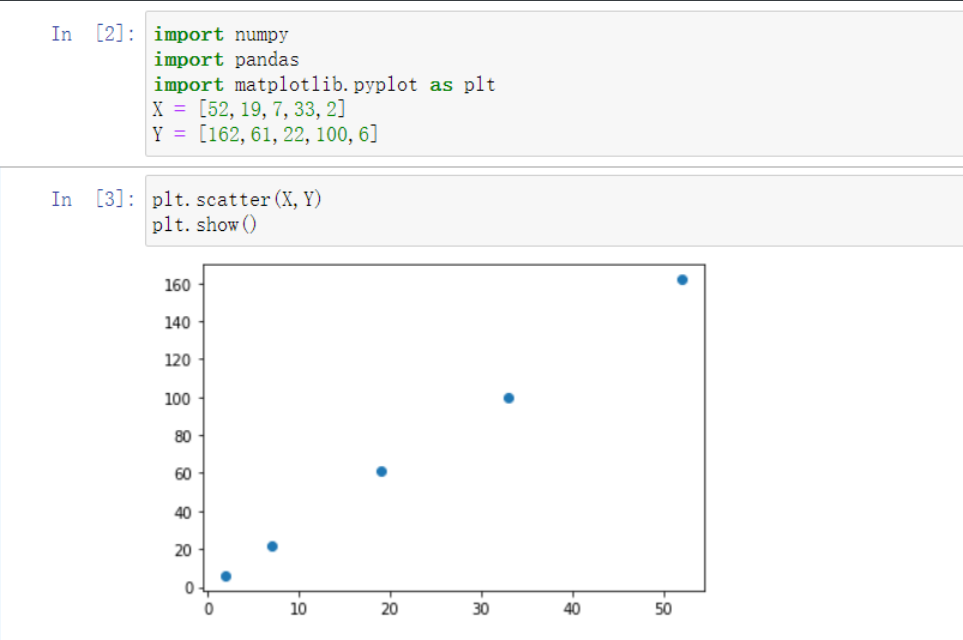
方式一:散点图
方式二:公式计算 # 得到的计算结果
绝对值大于等于0.8表示高度相关
绝对值大于等于0.5小于等于0.8表示中度相关
绝对值大于等于0.3小于0.5表示弱相关
绝对值小于0.3表示几乎不相关
'''需要注意这里的不相干指的是没有线性关系 可能两者之间有其他关系'''
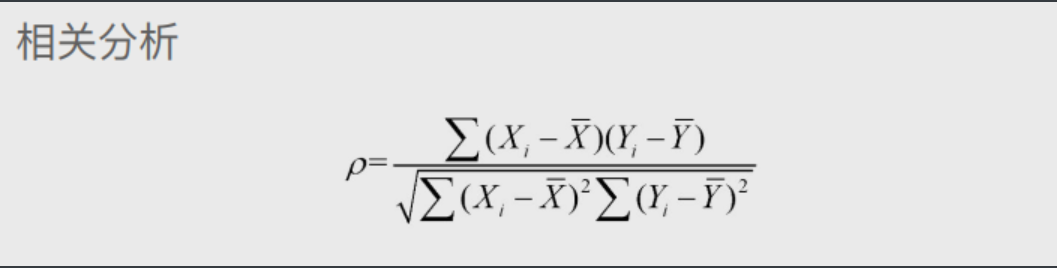
import numpy
import pandas
X = [52,19,7,33,2]
Y = [162,61,22,100,6]
# 1.公式计算#均值
XMean = numpy.mean(X)
YMean = numpy.mean(Y)
# 标准差
XSD = numpy.std(X)
YSD = numpy.std(Y)
# z分数
ZX = (X-XMean)/XSD
ZY = (Y-YMean)/YSD
# 相关系数
r = numpy.sum(ZX*ZY)/(len(X))
'''上述代码做起来是最复杂的但是numpy和pandas里面直接内置了方法'''
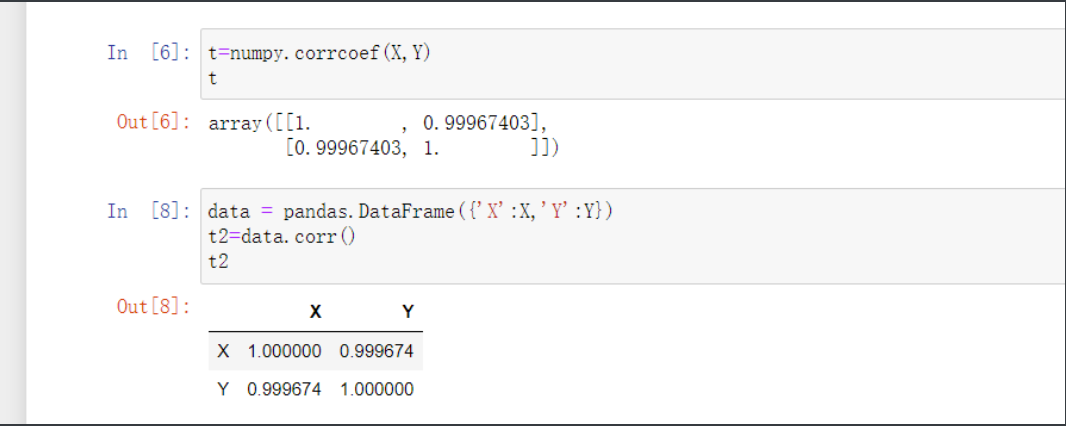
# 2.numpy中的corrcoef方法直接计算
t=numpy.corrcoef(X,Y)
# 3.pandas中的corr方法直接计算
data = pandas.DataFrame({'X':X,'Y':Y})
t2=data.corr()
线性回归模型
df1 = pd.read_csv(r'Salary_Data.csv')
plt.scatter(x=df1['YearsExperience'],y=df1['Salary'])
先搂一眼数据
x即x轴上数据是自变量
y即y轴上面数据为应变量
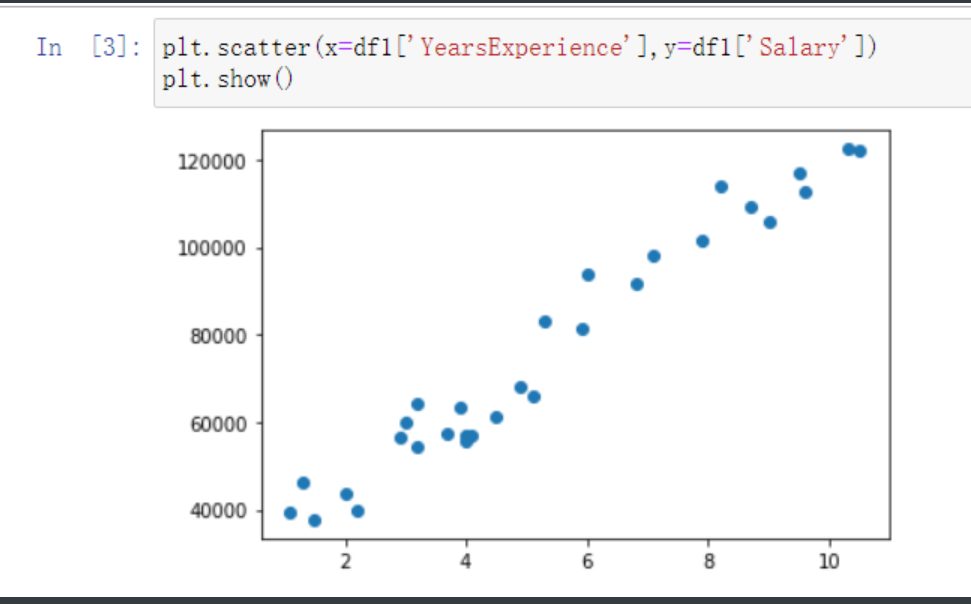
随后就带入数据你喜欢的方法直接套数据
np.corrcoef(df1['YearsExperience'],df1['Salary'])

机器学习模块
import statsmodels.api as sm
# 建立模型专用模块

然后通过机器学习来构建模型
fit = sm.formula.ols('Salary~YearsExperience',data=df1).fit()
调用模块里的方法然后第一个参数里 先给应变量 用~连接自变量
第二个参数则是数据在哪里
最后通过fit拟合生成公式
最后赋值给一个变量fit
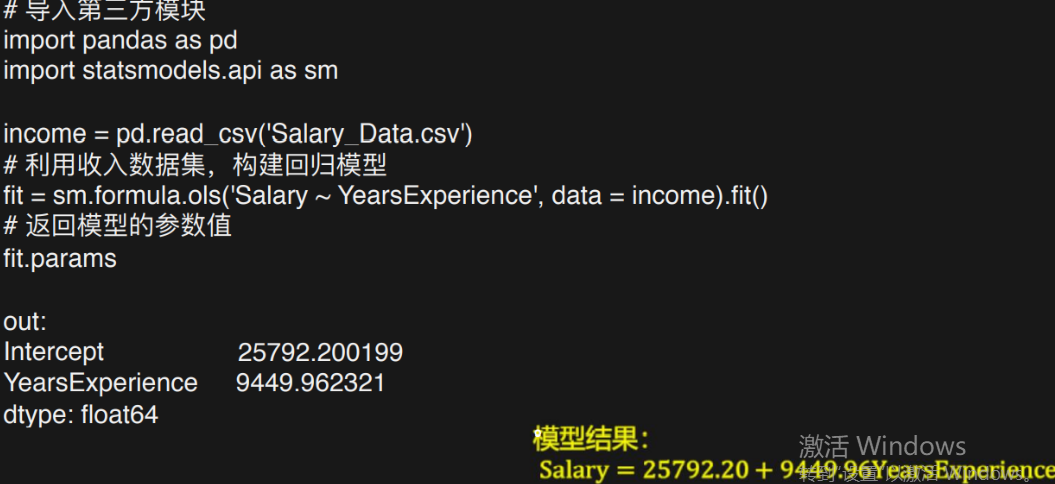
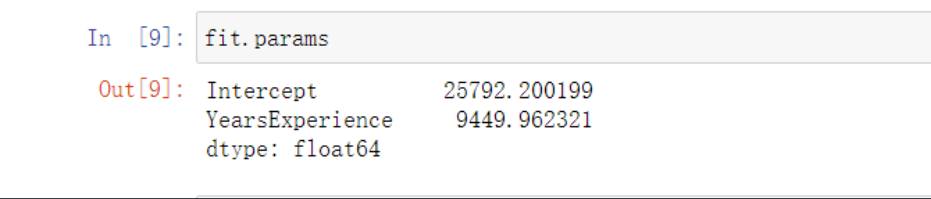
通过params关键字查看一下公式的样式
fit.params
# 结果
Intercept 25792.200199
YearsExperience 9449.962321
即 Salary = 25792.20 + 9449.96YearsExperience
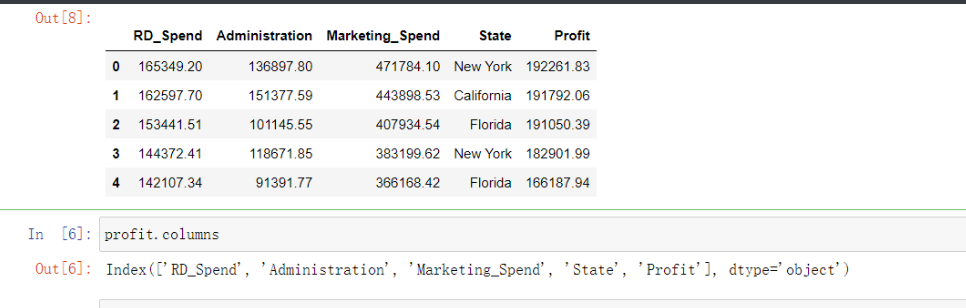
多元线性回归
还是一样先看一眼数据
profit = pd.read_excel(r'Predict to Profit.xlsx')
profit.head()
profit.columns
from sklearn import model_selection # 让模块选择模型
# 目前高端领域比如 人工智能 机器学习...等等
如果是通过python实现的一定会用到这个模块
数据分组
# 要先将数据分成下面两个集合 训练集与测试集
训练集用于模型的训练创建 测试集用于模型的测试检验
一般情况下训练集占总数据的80%、测试集占总数占20%
'''简单理解就是大部分数据用来构建模型
然后再要预留一小部分用来测试'''
# 将数据划分为训练集和测试集
train,test = model_selection.train_test_split(profit,test_size=0.2,random_state=1234)
# 这个代码关键字够见名知意了train_test_split 就是把训练和测试分隔开
前面profit是应变量
然后test_size=0.2 就是训练集和测试集82开
最后的参数指定取用的随机取法 直接固定的照抄就行了

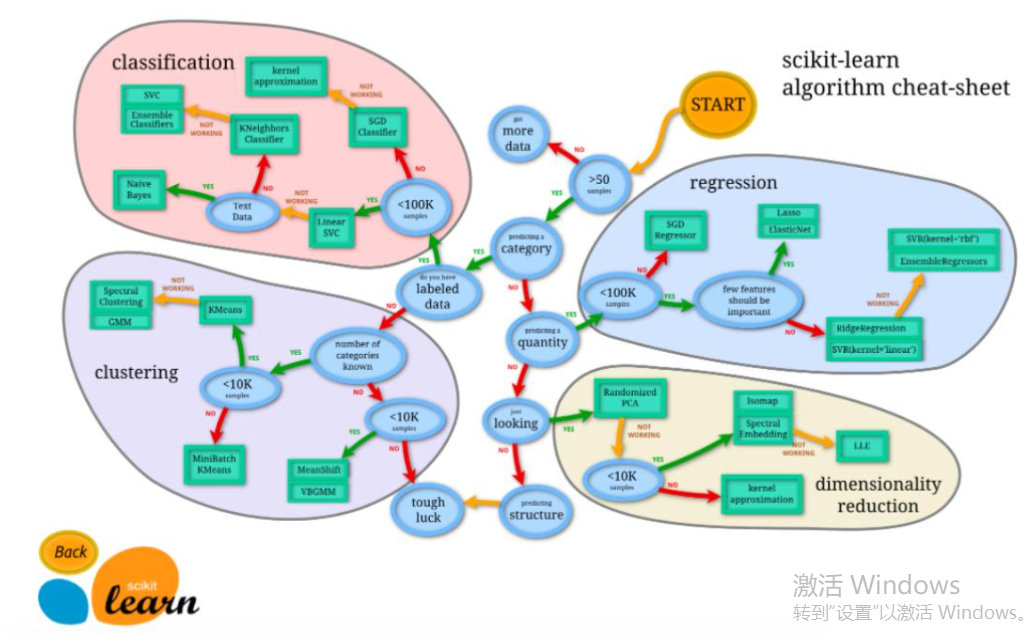
model = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+C(State)',data=train).fit()
和前面一样前面放应变量~后面放自变量
States由于是字符串肯定不能参与到公式运算里面
# 哑变量
在生成算法模型的时候有些变量可能并不是数字无法直接带入公式计算
此时可以构造哑变量 >>> C(State)
即只要在前面加上一个C()即可
model.params # 通过params查看
但是这里参数会有些不同
# 参数之间不能有联系
而哑变量的创造基准则类似于一个矩阵
N F C
0 0 1
0 1 0
1 0 0
通过这样区分开N、F、C三个州
但是这样有了前两个州的数据第三个数据就会直接推导得出
所以根据前面的原则这边哑变量C的那个州就被优化掉扔了
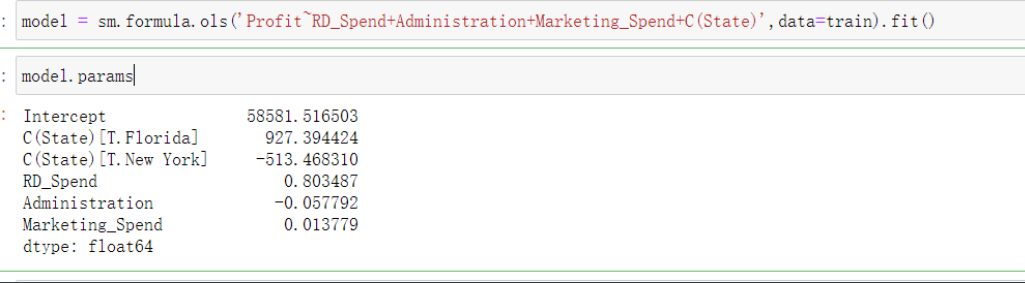
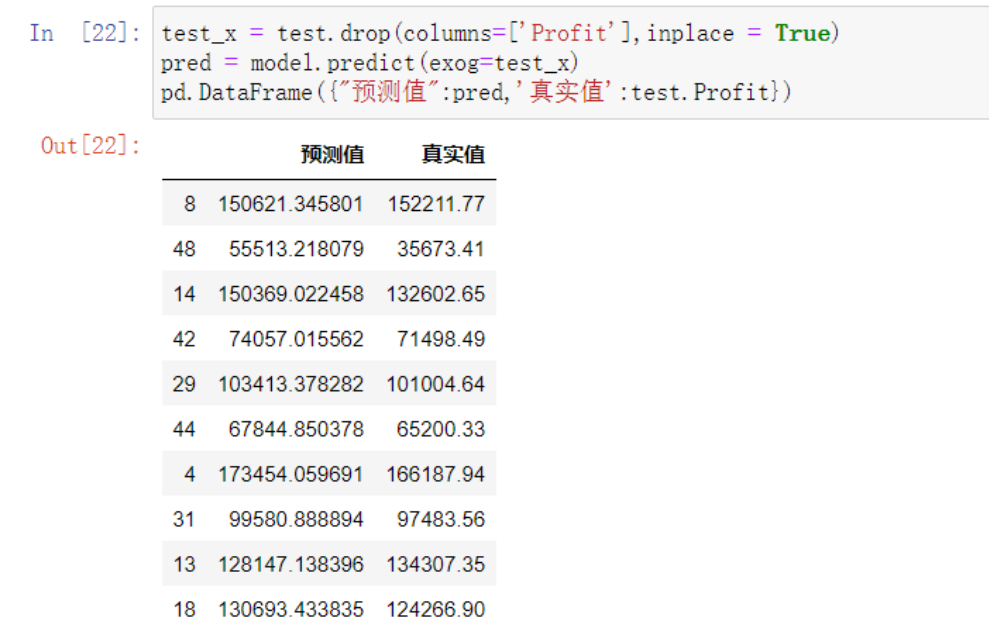
# 模型构建完了之后就要通过测试集去测试数据了
test_x = test.drop(columns=['Profit'],inplace = True)
先要将test中由训练集得到的数据删除
然后再去比对预测值和真实值
# 预测的代码中predict就是预测的意思 ()中exog=放上删除应变量之后的模型
pred = model.predict(exog=test_x)
# 这样pre就是预测值的Series了 接下来将两个结果放在一起比对
补充:自定义哑变量
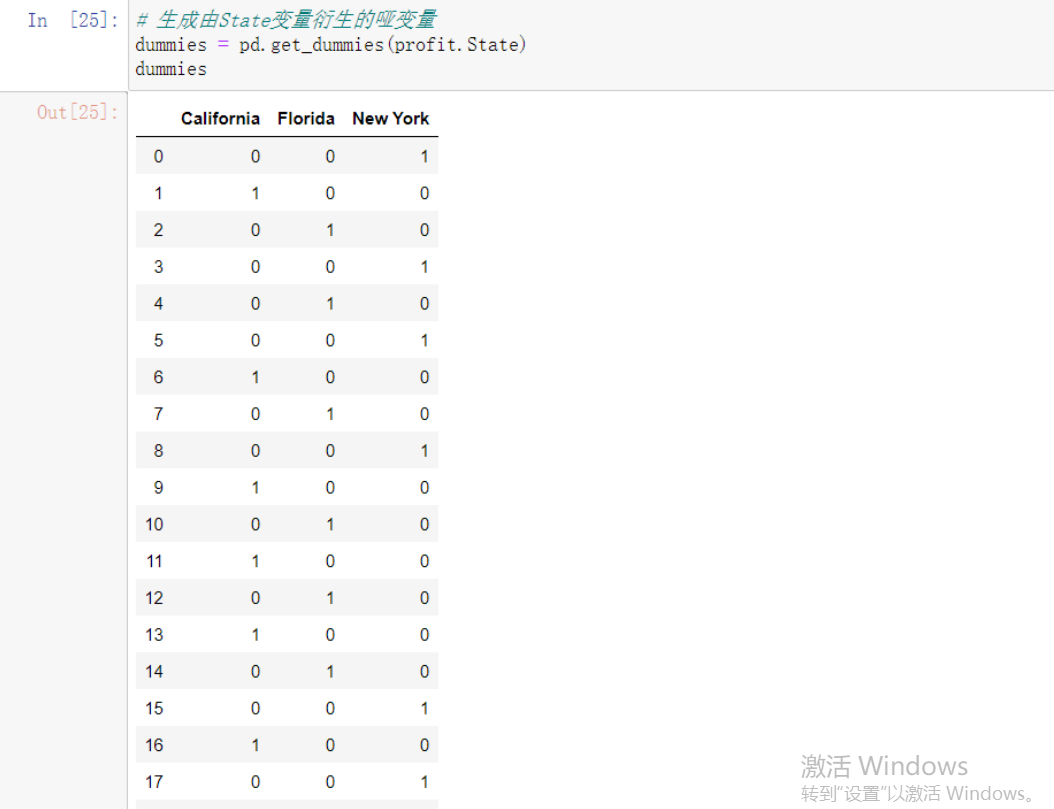
# 生成由State变量衍生的哑变量
dummies = pd.get_dummies(Profit.State)
# 将哑变量与原始数据集水平合并
Profit_New = pd.concat([Profit,dummies], axis = 1)
# 删除State变量和California变量(因为State变量已被分解为哑变量,New York变量需要作为参照组)
Profit_New.drop(labels = ['State','New York'], axis = 1, inplace = True)
# 拆分数据集Profit_New
train, test = model_selection.train_test_split(Profit_New, test_size = 0.2, random_state=1234)
# 建模
model2 = sm.formula.ols('Profit~RD_Spend+Administration+Marketing_Spend+Florida+California', data = train).fit()
print('模型的偏回归系数分别为:\n', model2.params)
################################################
哑变量这部分操作也不需要掌握
代码都是现成的只要将里面的参数换掉就行了
到时候只要会用就行
################################################