10/20
今日考题
1.说说你所知道的统计学图形及各自擅长点
饼图
用于查看数据占比
条形图
用于数据之间直观比较
直方图
用于查看数据分布特性
散点图
用于观察两个数据之间联系
气泡图
基于散点图的数据上有了第三个参数的情况
折线图
对于时间变化 用折线图能展示数据变化趋势
热力图
展示两个参数组合之后对另一个参数的影响关系
箱线图
比起直方图更专业的体现出数据的分布 还能捕获出异常值
2.针对图形可视化都有哪些实现方式
1.matplotlib
2.seaborn
3.highcharts
4.echarts # 比较重点
pyecharts # 可以通过python代码直接调用
5.ds.js
3.简述数据分析三剑客各自功能
# numpy
进行科学计算 所有和数字打交道的活基本都是他来做
# pandas
有Series和DataFrame两大得力数据结构
Series类似带索引的一维数组
DataFrame相当于Series的组合
最大的作用就是操作表格
这里操作包括制作 生成 查看 透视 读取 等等
# matplotlib
可视化模块
配合前面的pandas可以将表数据转化成你想要的图案
复习巩固
- 水平条形图
- 交叉条形图
- 直方图
- 箱线图
- 散点图和气泡图
- 热力图
- 组合图
内容概要
- 数据清洗
在数据分析之前对数据进行各项处理以达到分析的要求
- 概念
- 实操
详细讲解
什么是数据清洗
数据清洗是从记录表、表格、数据库中检测、纠正、或删除不准确记录的过程
# 简单来说 数据清洗就是把'脏数据'变成'干净数据'
脏数据:残缺数据 错误数据 重复数据 不合规的数据...
干净数据:可以直接带入模型的数据

数据清洗流程
通俗来理解可以将整个流程当成是在做菜
# 第一步明确需求
我要做麻辣香锅
# 第二步收集采集
去菜场买蔬菜干货海鲜肉等等
# 第三步数据清洗
菜买回来得洗菜 切菜 配菜
# 第四步数据分析
下锅炒菜
# 第五步数据报告+可视化
拍照发朋友圈

常见方法
# 1.读取外部数据
read_csv read_excel read_sql read_html
# 2.数据探索与描述(概览)
index columns head tail shape desceibe dtypes info
# 3.数据简单处理
移除首尾空格 大小写转换...
# 4.重复值的处理
duplicated() 查看是否有重复数据
drop_duplicates() 删除重复数据
# 5.缺失值处理
就4个方法 然后删除异常值 或者 填充缺失值
# 6.异常值处理
删除异常值 修正异常值
# 7.文本字符串处理
正则筛选 切割 切片取值
# 8.时间格式序列处理
Y m d H M S 年月日时分秒
'''3到8没有固定顺序 按照你的喜好擅长来都行'''
旅游数据清洗案例(重头戏后面都围绕这个来)
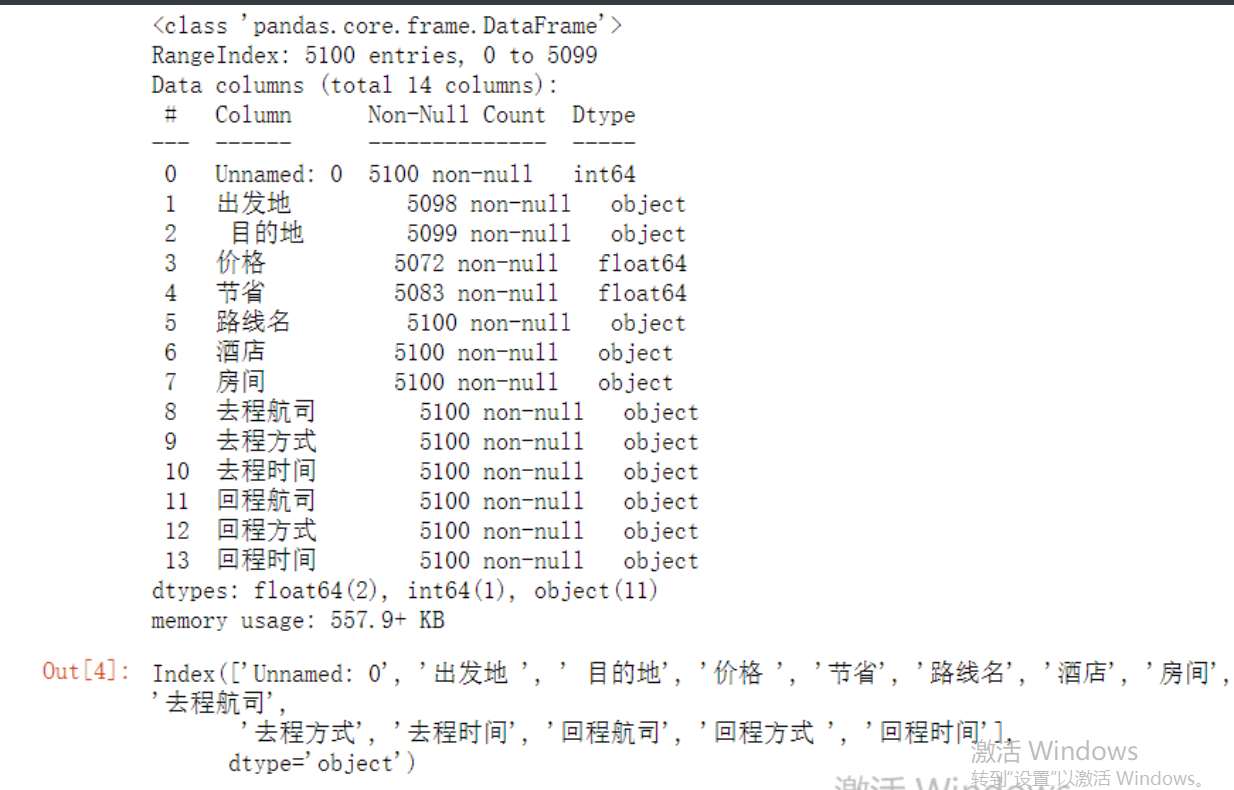
数据概览
拿到大量数据之后可以先做一个宏观把控 稍微看一眼数据能够有个大概的概念
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(r'qunar_freetrip.csv')
# 1.查看前五条数据 掌握大概
df.head()
# 2.查看表的行列总数
df.shape
# 3.查看所有的列字段
df.columns # 发现列字段有一些是有空格的
# 4.查看数据整体信息
df.info() # 发现去程时间和回程时间是字符串类型需要做日期类型转换
这个方法非常好用 基本所有整体信息都在里面了
# 5.快速统计
df.describe()
# 查看一下表头
df.columns
重复值处理
其实不管有没有重复值都可以直接走一遍下面的程序
df.drop_duplicates(inplace=True) # 删除重复项
df.duplicated() # 再看一眼确认删除了
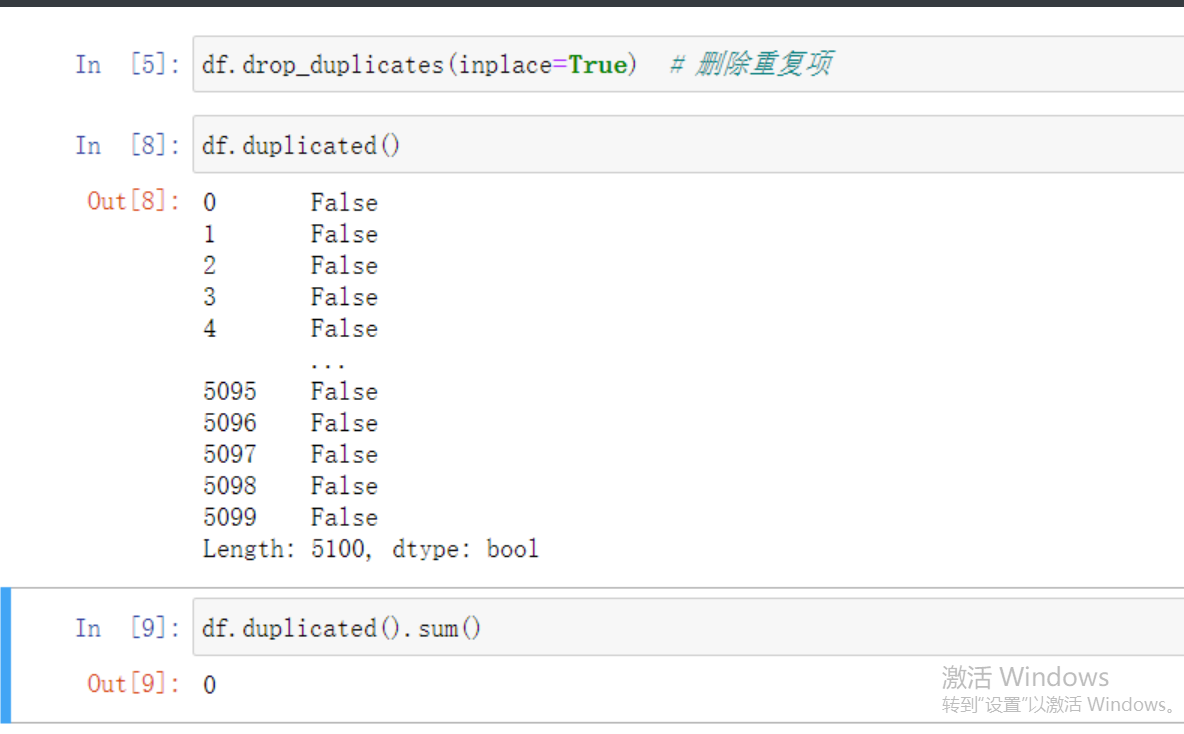
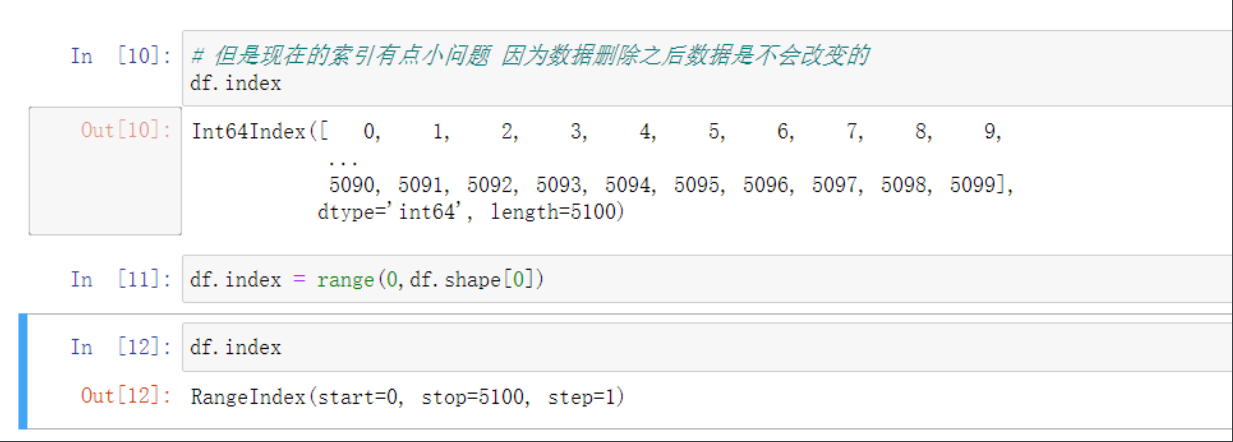
# 但是现在的索引有点小问题 因为数据删除之后数据是不会改变的
df.index
# 按顺序改一下索引 可以通过创建新索引再删除旧索引
data.reset_index(inplace=True)
data.drop(columns=['index'],inplace=True)
# 也可以直接修改原来的索引
df.index = range(0,df.shape[0])
重复值小补充
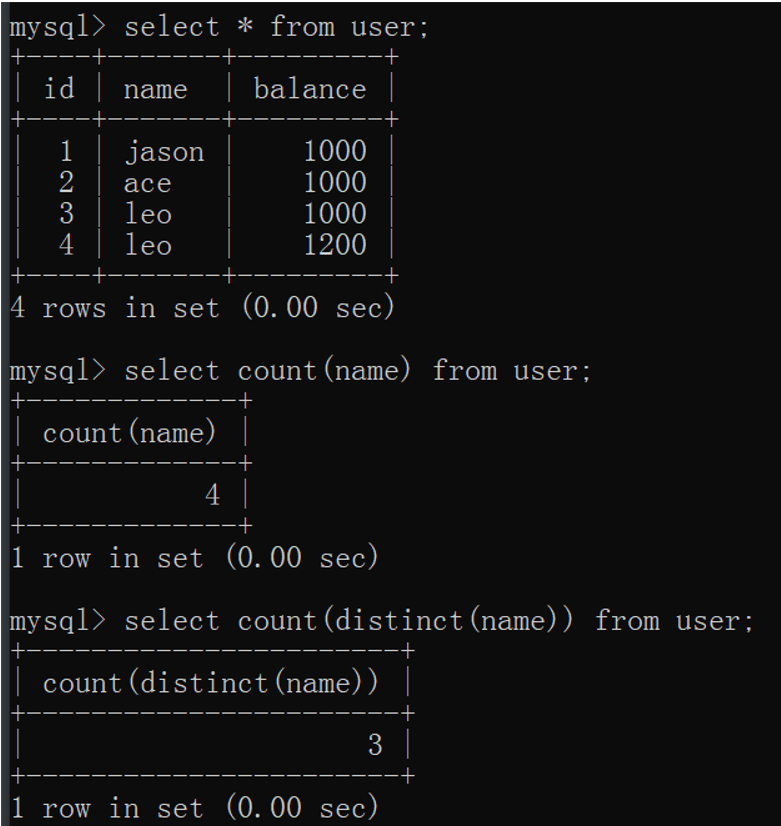
"""MySQL中如何快速判断某列是否含有重复的数据"""
# 思路:就是统计某个字段下数据的个数 在利用去重操作 两者结合判断
select count(name) from userinfo;
select count(distinct(name)) from userinfo;
# 如果两者数字相同表示name列没有重复的数据
# 不同则表示含有重复的数据
列字段处理
'''字段首尾有空格 很容易忽略导致无法排错'''
new_columns = [] # 把就表头变成空字符串
for col in data.columns: # for循环拿到每一个列字段名词之后 使用strip()方法移除首尾空格即可
new_columns.append(col.strip()) # 列表插入元素 即一一插入表头
# 上述代码用列表生成式可以精简成一行
data.columns = [col.strip() for col in data.columns] # 直接将新列表赋值给旧列表的列标签(也就是表头)

异常值处理
# 利用快速统计筛选一下大致看一眼
df.describe() # 价格小于节省 那么可能是价格有问题或者节省有问题

# 这里就要借助数学公式来看看我们的猜想
"""
公式计算:(列数据 - 列数据均值)/列数据标准差
绝对值(不考虑正负号):abs()
"""
error_num = (df['价格'] - df['价格'].mean()) / df['价格'].std()
# 结果里面有负的所以要加上关键字abs取绝对值
error_num = abs(df['价格'] - df['价格'].mean()) / df['价格'].std()
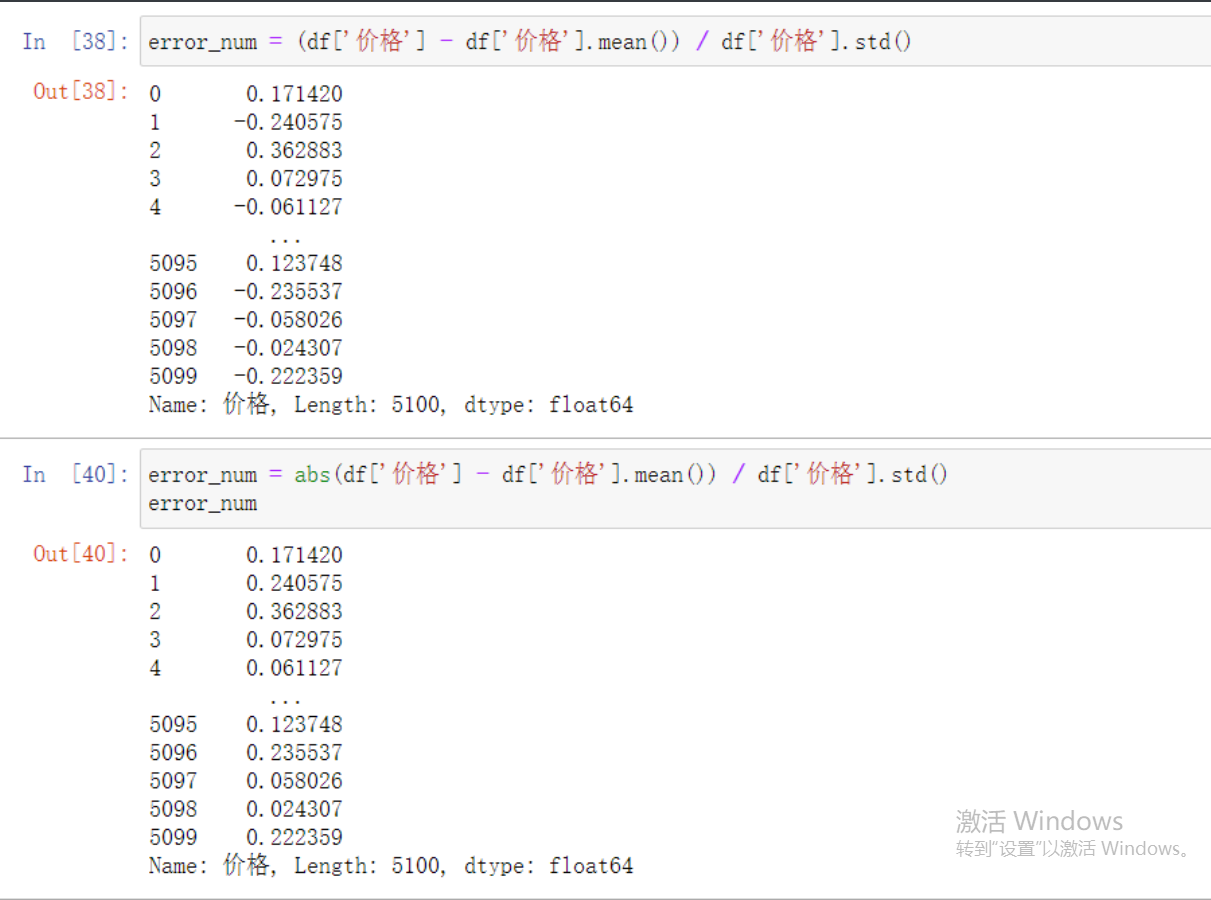
df[error_num > 3] # 通过索引找到有问题的数据

用同样的方法找到节省有异常的数据
error_num1 = abs(df['节省'] - df['节省'].mean()) / df['节省'].std()
df[abs(error_num1) > 3]
'''但是这种情况很可能是什么促销活动所以就先不删'''
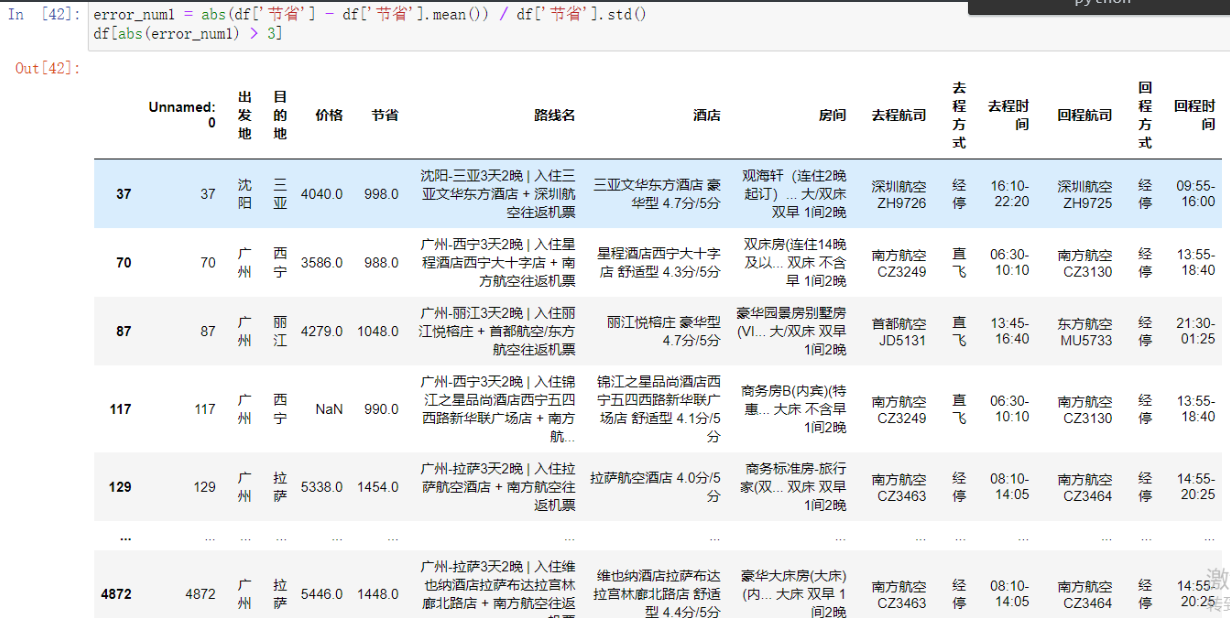
# 然后再简单粗暴的找到节省大于价格的数据
df[df['节省'] > df['价格']]

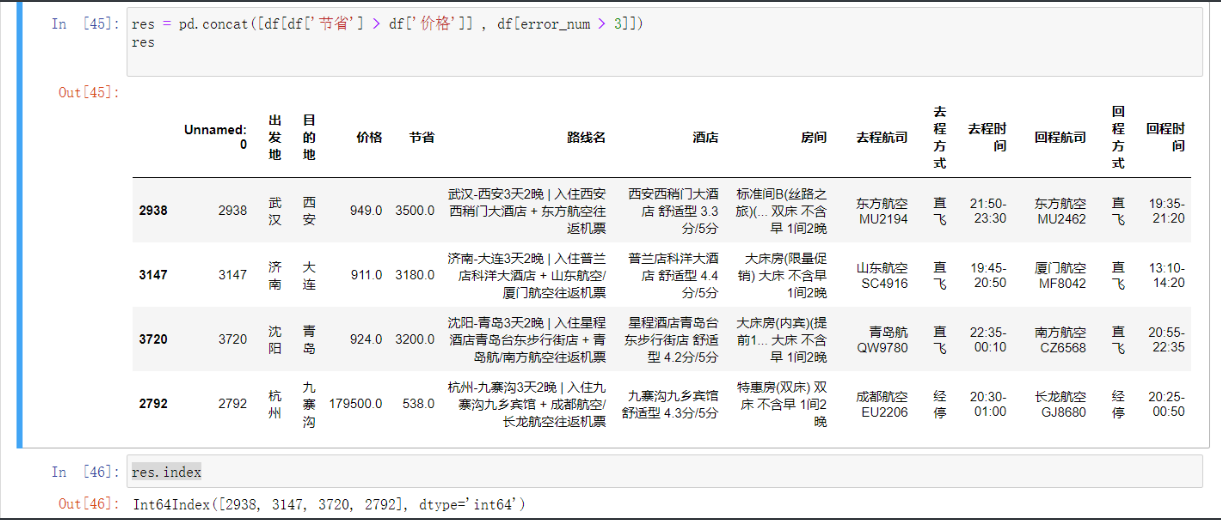
然后把所有有问题的数据 即价格有问题还有节省大于价格的合并
res = pd.concat([df[df['节省'] > df['价格']] , df[error_num > 3]])
res.index # 现在这个索引就是所有有问题的索引了只需要直接删掉就行
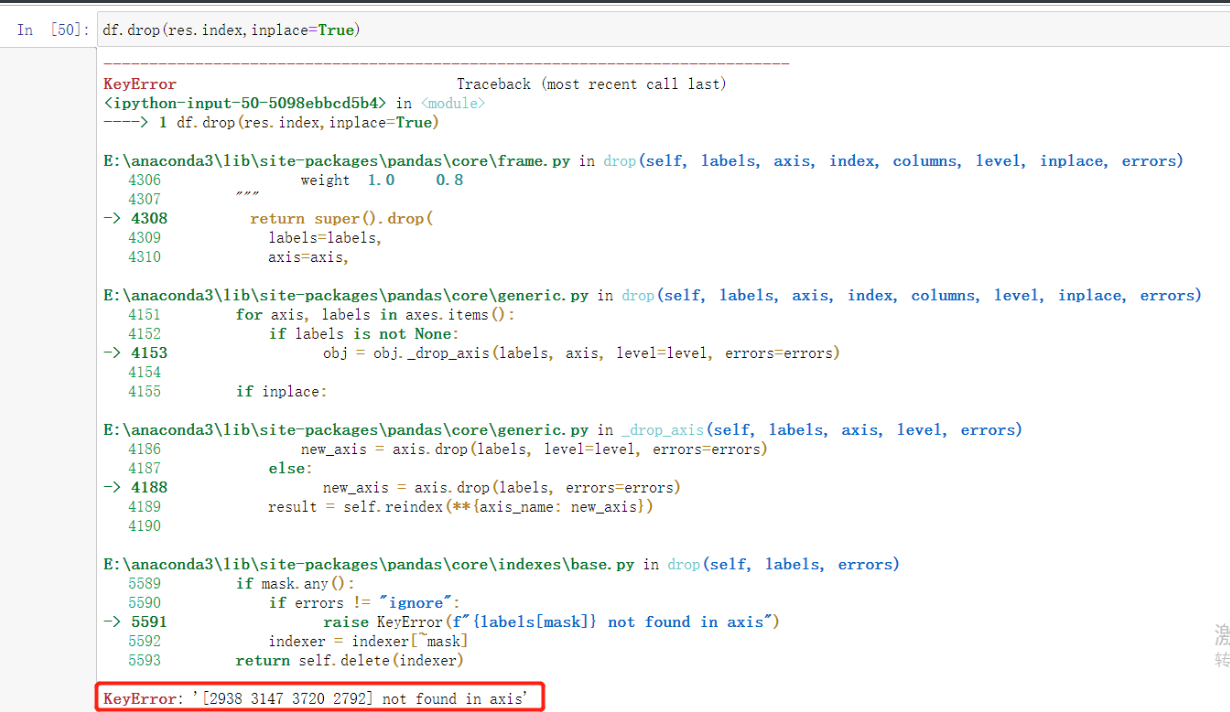
df.drop(res.index,inplace=True) # 然后删除索引对应的字段就行了
'''小技巧: 怎么知道删除成功了呢
再运行一遍看报错提示就行了'''
删除无用列字段
现在表里面有个部分没有用的 和索引一样的部分
放着碍眼就删了把
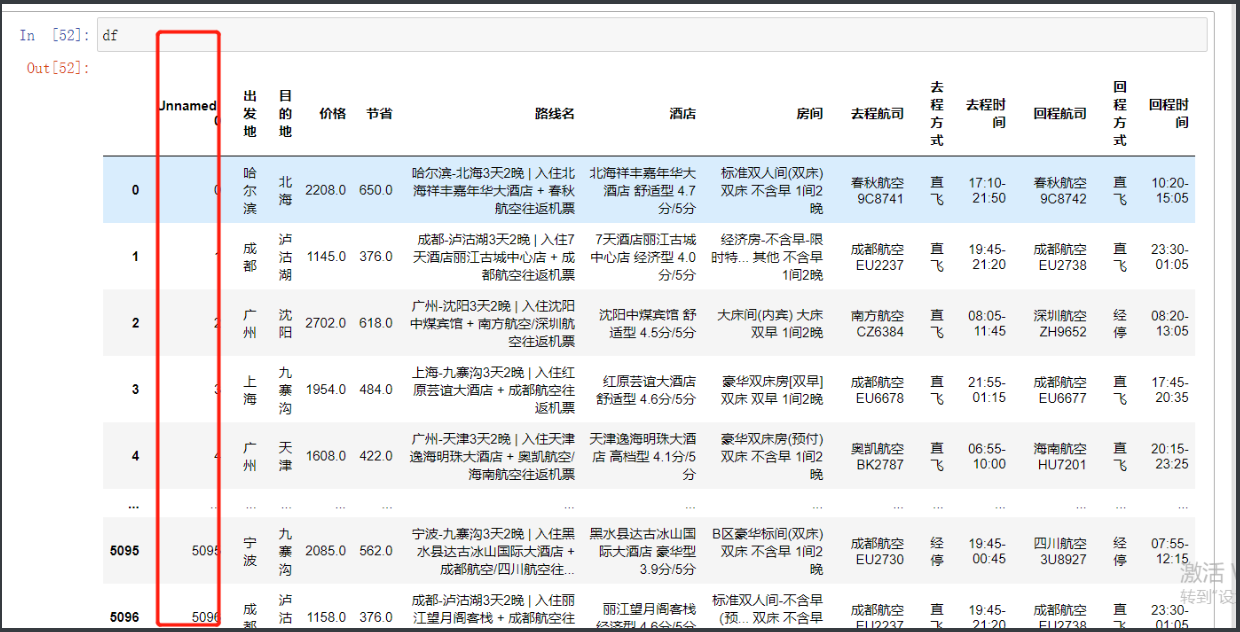
df.drop(columns='Unnamed: 0',inplace=True) # 下图是没加inplace参数的
出发地缺失
df.isnull().sum() # 先整体看一下都有哪些数据缺失
# 然后再通过布尔值索引筛选出出发地有缺失的数据
df[df.出发地.isnull()]
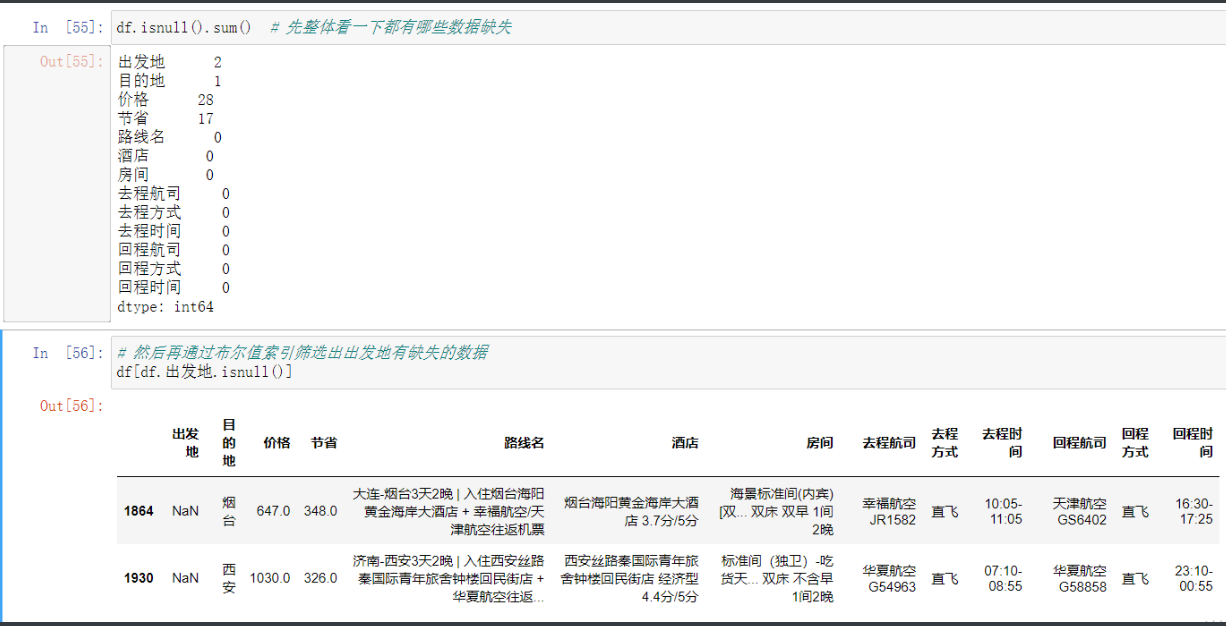
# 虽然出发地的数据没有 但是在路线里是有的 可以想办法取出
df.loc[df.出发地.isnull(),'路线名'].values # 先拿到字符

和前面一样通过列表生成式
df.loc[df.出发地.isnull(),'出发地'] = [i.split('-')[0] for i in df.loc[df.出发地.isnull(),'路线名'].values]
# 这样就直接把列表替换上了
df.loc[df.出发地.isnull(),'路线名'].values # 再走一遍这个代码看看是否成功

'''处理要点小计'''
################################
# 操作数据的列字段需要使用loc方法
################################
# 针对缺失值的处理
# 1.采用数学公式依据其他数据填充
# 2.缺失值可能在其他单元格中含有
# 3.如果缺失值数量很小很小可删除
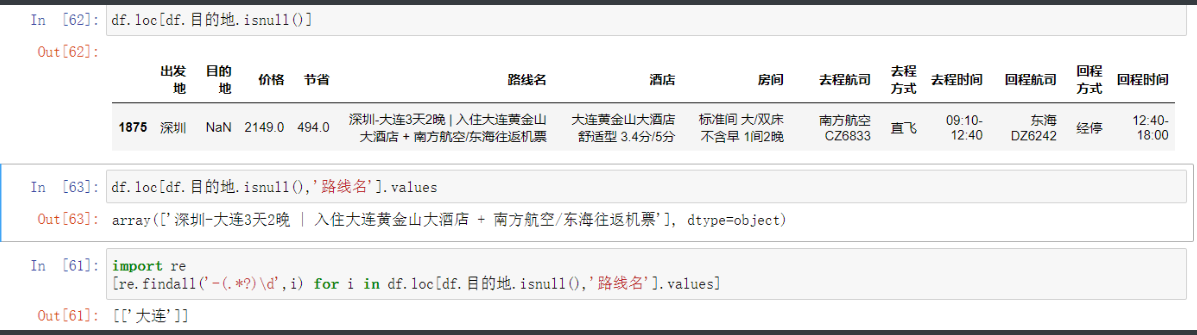
目的地缺失值处理
'''这不就和上面出发地一样一样的 就文本筛选稍微复杂一点'''
df.loc[df.目的地.isnull(),'路线名'].values # 拿到缺失数据的路线名中数据
# 文本筛选的时候总有个办法考虑 那就是正则
import re
# 用正则这个也不难筛选了
[re.findall('-(.*?)\d',i) for i in df.loc[df.目的地.isnull(),'路线名'].values]
df.loc[df.目的地.isnull(),'目的地'] = [re.findall('-(.*?)\d',i)[0] for i in df.loc[df.目的地.isnull(),'路线名'].values]
# 将结果传入原本空的位置即可
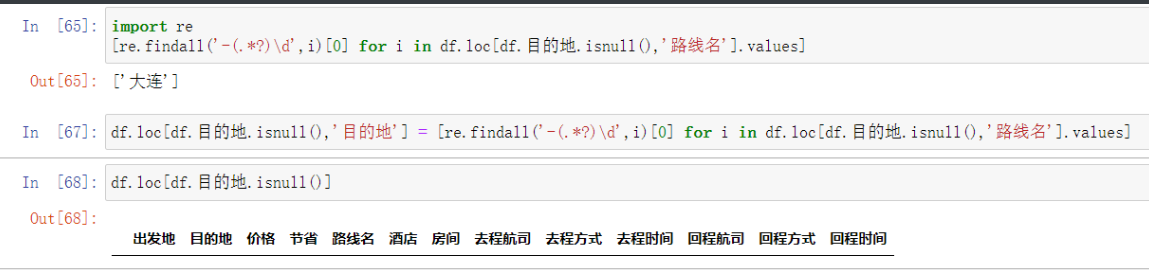
数字类缺失值处理
这个老熟人了呀
# 首先计算一下缺失的数据占比
df.isnull().sum()/df.shape[0]
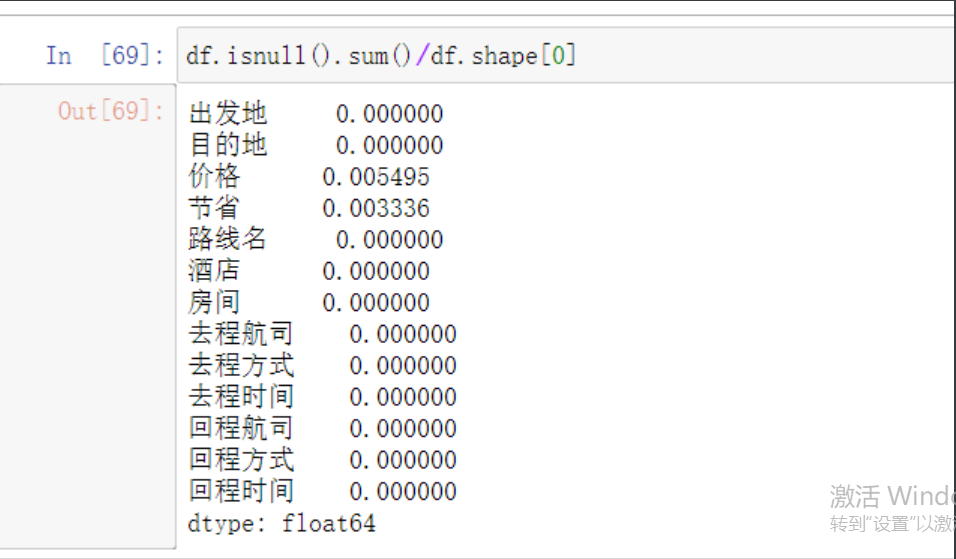
经过我们不屑的努力现在只剩数字类的有缺失了
# 这里就不得不再提一嘴关于数据缺失的方法
"""
1.占比过小可以直接删除
2.利用均值、统一值直接填充
3.根据不同的情况采用不同的计算公式填充
常用的四个方法
isnull
notnull
fillna
dropna
保留几位小数
round(数据,保留位数)
"""
接下来我们筛选一下缺失数据
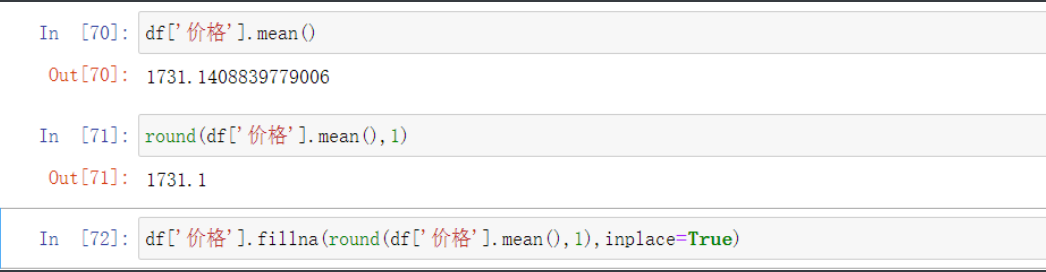
df['价格'].mean() # 计算价格平均值
round(df['价格'].mean(),1) # 将平均值四舍五入
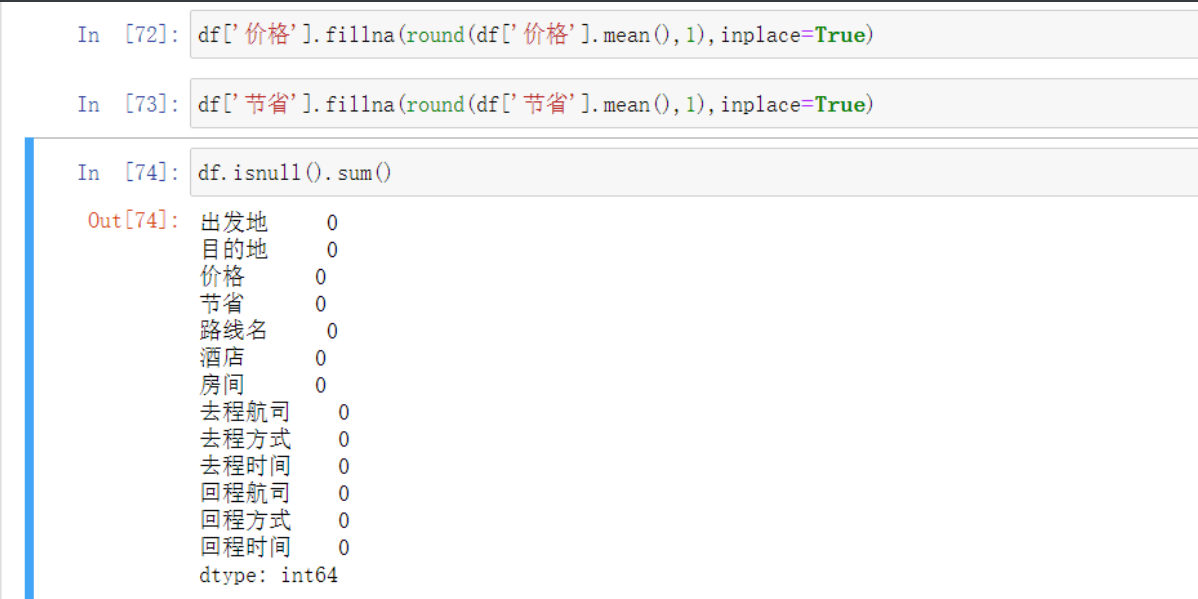
df['价格'].fillna(round(df['价格'].mean(),1),inplace=True) # 将结果填充 前两步合进来
# 同理节省数据也用填充掉 这次用中位数
df['节省'].fillna(round(df['节省'].mean(),1),inplace=True)
df.isnull().sum() # 然后来验证
新增列并填充
酒店类型
# 先把酒店类型变成列表筛选出来
[re.findall(' (.*?) ',i) for i in df['酒店'].values] # 列表生成式配合正则
# 然后加入新列表
df['酒店类型']=[re.findall(' (.*?) ',i) for i in df['酒店'].values]
'''原本就像试一下没想到一次性就成了'''

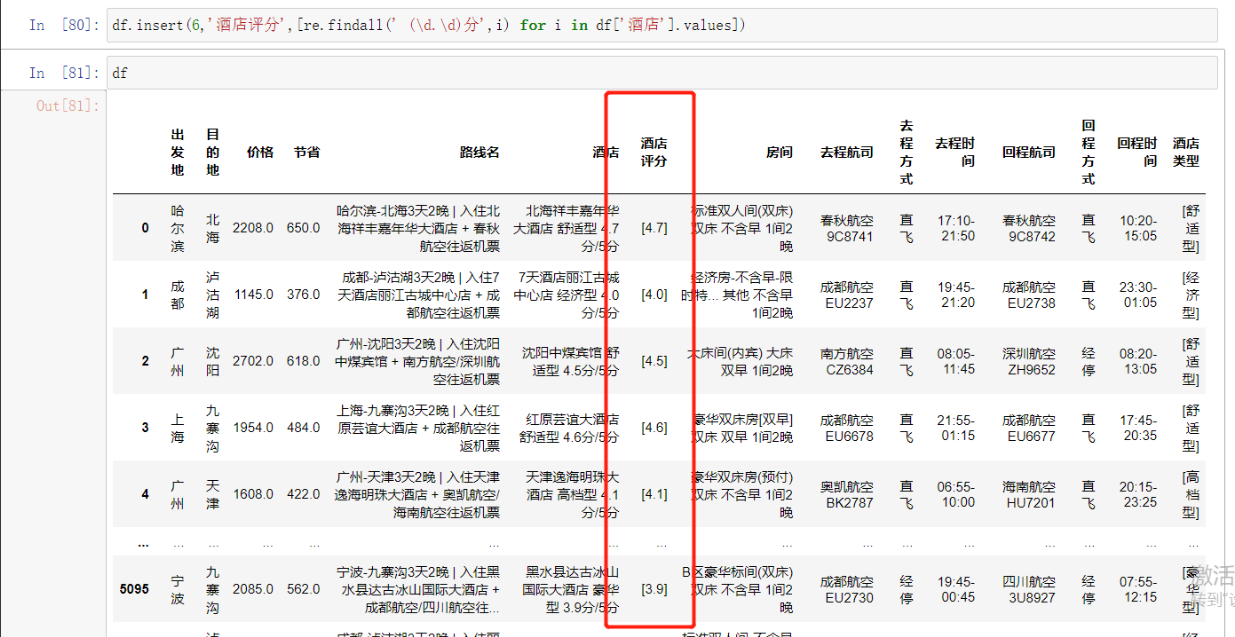
酒店评分
# 那不是跟简单 还是先筛选出要的字段改改就行了
[re.findall(' (\d.\d)分',i) for i in df['酒店'].values]
# 括号里面限定好数字加上括号简简单单直接搞定 不放心后面还加了个
# 这里用新办法
df.insert(6,'酒店评分',[re.findall(' (\d.\d)分',i) for i in df['酒店'].values])
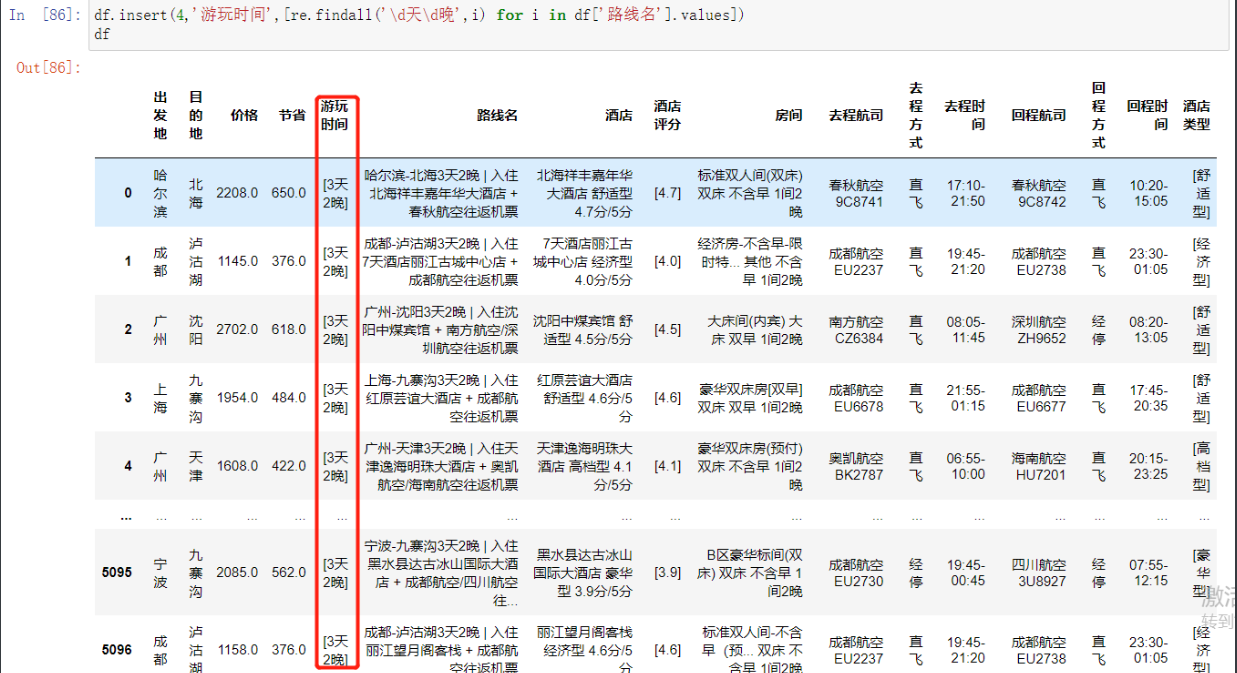
游玩时间
# 前两个做了这个就一通百通了 直接筛选所需内容
[re.findall('\d天\d晚',i) for i in df['路线名'].values]
# 然后也插入新列就好了
df.insert(4,'游玩时间',[re.findall('\d天\d晚',i) for i in df['路线名'].values])