10/19
今日考题
1.针对缺失值有哪些处理方法,实际工作中有哪些策略
针对缺失值总共就四种方法
1.isnull # 是NaN的标True
2.notnull # 和前一个刚好相反
3.dropna() # 删掉丢失数据
4.fillna() # 填充丢失数据
实际工作中如果丢失数据很少很少 比如占总数据的0.1%一下 就可以结合实际情况删掉
不然的话就要想办法去填充数据
比如性别可以通过mode众数填充
年龄通过mean平均值填充
一些容易受极值影响的数据比如收入用median中位数填充
2.MySQL中的连表操作有哪些各自有何特点,pandas中的数据合并有哪些
# SQL中联表有以下4种
1.inner join # 两表中没有的对应的数据就不展示
2.left join # 以左表为基准 对应数据 没有的null填充
3.right join # 以右表为基准 对应数据 没有的null填充
4.union # 两张表数据都要 对应不上null填充
# pandas联表
多了个纵向合并 关键字concat
pd.concat([df1,df2]) # 直接按着对应表头合并 对不上的表头就直接创建没有的数据NaN填充
横向联表就和SQL遵循的机制一样 关键字merge
pd.merge(left=df1, # 指定联表的左表
right=df2, # 指定联表的右表
how = 'inner', # 指定联表方式
left_on = 'id', # 指定左表连接的时候用的依据字段
right_on = 'id' # 指定右表连接的时候用的依据字段
)
3.简述你所知道的图表并概括各自擅长领域
# 饼图
用于直观的统计占比 比如高收入人群在人口中所占比例此类话题
# 条形图
可以很直观的展示出数据之间的差异 看到明显的比对
复习巩固
- pandas缺失数据处理
isnull、notnull、dropna、fillna
# 针对缺失数据除非占比非常少才有可能会被删除否则一般都是采取填充的形式
"""
在实际工作中针对缺失值的填充要结合实际情况 不同类型的数据应该采取不同的填充策略
eg:
年龄的缺失填充可以使用平均值(mean)
性别的缺失值填充可以使用众数(mod)
薪资的缺失值填充可以使用中位数(median)
"""
- 数据透视表
就通过三个参数规定以下表的 索引 表头 和里面数据
从而制作一张另外的表
- 分组与聚合
分组关键字:groupby
聚合关键字:aggregate
- 数据合并
数据的横向合并
将多张表按照一个共同的字段水平合并
pd.merge()
数据的纵向合并
将多张表按照字段一一对应纵向合并
pd.concat()
- 饼图绘制
# 主要用于展示有限数据项之间的占比情况
import matplotlib.pyplot as plt
plt.pie()
plt.show()
- 条形图绘制
# 1.图形弹出展示 %matplotlib
# 2.解决中文乱码 固定的代码
plt.bar()
.text(x,y,data)
内容概要
主体: 结束matplotlib收尾 数据清洗
- 水平条形图
- 交叉条形图
- 散点图与气泡图
- 热力图
- 箱线图
- 图形可视化其他模块补充
详细讲解
条形图绘制
昨天已经说过条形图是用以展示比较多的离散型变量的
垂直条形图昨天已经画过今天来试一下水平条形图
'''水平条形图一般会做个降序排列看起来观感会比较好 不然和垂直的不就一样了'''
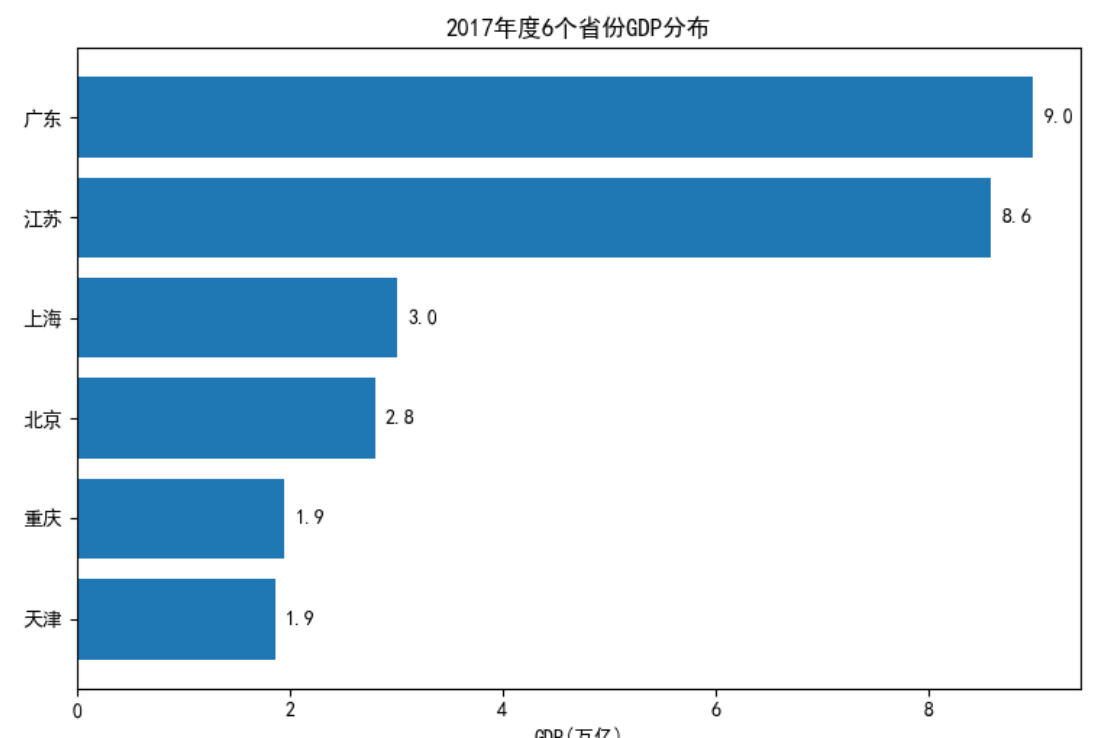
GDP.sort_values(by = 'GDP', inplace = True) # 对读入的数据做升序排序
# 绘图
plt.barh(y = range(GDP.shape[0]), # 指定条形图y轴的刻度值
width = GDP['GDP'], # 指定条形图x轴的数值
tick_label = GDP['Province']) # 指定条形图y轴的刻度标签
# 添加x轴的标签
plt.xlabel('GDP(万亿)')
# 添加条形图的标题
plt.title('2017年度6个省份GDP分布')
# 为每个条形图添加数值标签
for y,x in enumerate(GDP['GDP']):
plt.text(x+0.1,y,'%s' %round(x,1),va='center')
'''va和垂直里面用到ha除了单词不一样别的都一样'''
# 显示图形
plt.show()
上面两个柱状图都没有同比的一个比较出现那如果柱状图同比要做一个比较直观的比较话就需要用到
'''交叉条形图'''
# 先读取表文件
HuRun = pd.read_excel('HuRun.xlsx')
# 然后通过透视表功能 做个新的方便使用的表
HuRun_reshape = HuRun.pivot_table(index = 'City', columns='Year',
values='Counts').reset_index()
# 对数据集降序排序
HuRun_reshape.sort_values(by = 2016, ascending = False, inplace = True)
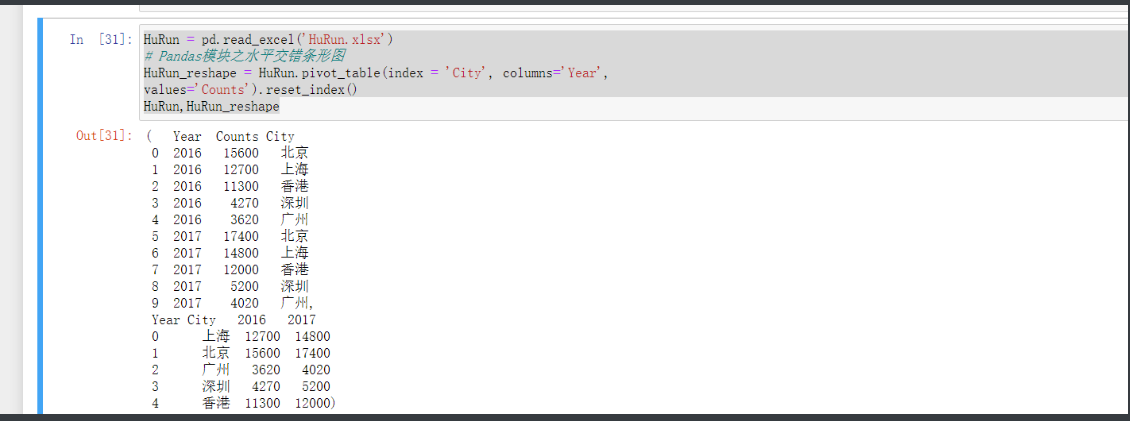
# 然后绘图
HuRun_reshape.plot(x = 'City',
y = [2016,2017],
kind = 'bar',
rot = 0, # 用于旋转x轴刻度标签的角度,0表示水平显示刻度标签
width = 0.8,
title = '近两年5个城市亿万资产家庭数比较')
# 添加y轴标签
plt.ylabel('亿万资产家庭数')
plt.xlabel('') # 通过指定空字符作为x轴标题可以将自带的城市去掉
plt.show()

直方图
直方图一般用来观察数据的分布形态,横坐标代表数值的均匀分段,纵坐标代表每个段内的观测数量(频数);
一般直方图都会与核密度图搭配使用,目的是更加清晰地掌握数据的分布特征;
'''直方图用来查看分布特征 和柱形图很像别搞混了'''
plt.hist(x, bins=10, normed=False, orientation='vertical', color=None, label=None)
x:指定要绘制直方图的数据。
bins:指定直方图条形的个数。
normed:是否将直方图的频数转换成频率
orientation:设置直方图的摆放方向,默认为垂直方向
color:设置直方图的填充色
edgecolor:设置直方图边框色
label:设置直方图的标签,可通过legend展示其图例
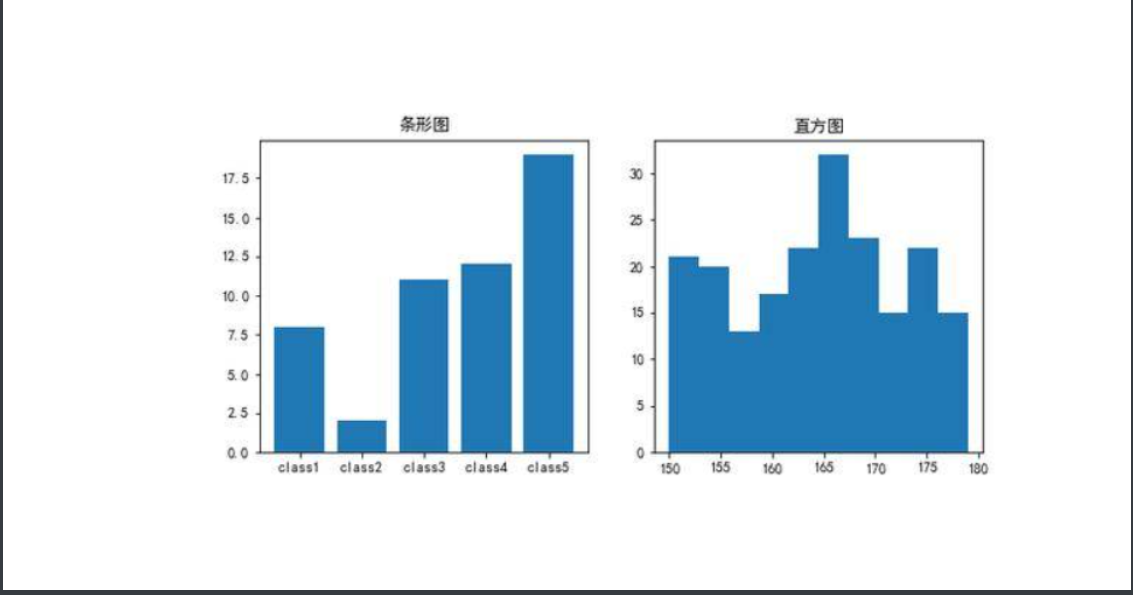
'''查看泰坦尼克号上乘客年龄分布'''
Titanic = pd.read_csv('titanic_train.csv') # 导入数据
# 检查年龄是否有缺失 如果数据中存在缺失值 将无法绘制直方图
Titanic.Age.isnull().sum
# 对于缺失的不如直接丢了 不然在查看分布的时候中间又会太多导致图像不准
Titanic.dropna(subset=['Age'], inplace=True)
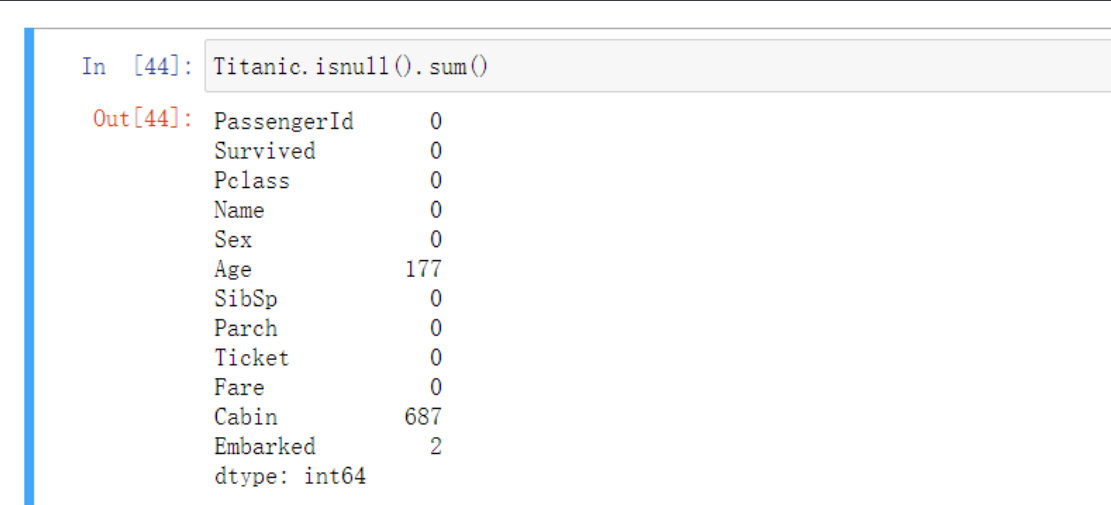
# 绘制直方图
plt.hist(x = Titanic['Age'], # 指定绘图数据
bins = 30) # 指定直方图中条块的个数
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('频数')
# 添加标题
plt.title('乘客年龄分布')
plt.show()
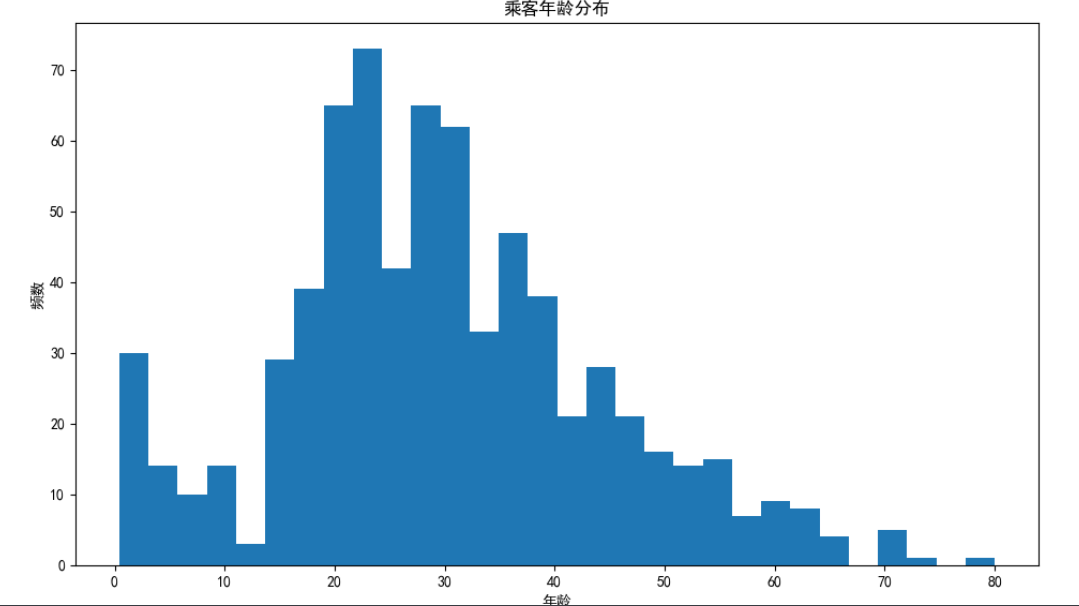
箱线图
箱线图是另一种体现数据分布的图形,通过该图可以得知数据的下须值(Q1-1.5IQR)、下四分位数(Q1)、中位数(Q2)、均值、上四分位(Q3)数和上须值(Q3+1.5IQR),更重要的是,箱线图还可以发现数据中的异常点;
'''
将所有数据看成一个长蛋糕
那下四分卫数 中位数 上四分位数 将长蛋糕均匀的切成了4份小蛋糕
下四分卫就是最下面的那一到
而切下来的那一块的量就是IQR
所以下须值也就是下四分位那刀的位置再向下挪1.5块小蛋糕的位置
'''
plt.boxplot(x, vert=None, whis=None, patch_artist=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None)
x:指定要绘制箱线图的数据
vert:是否需要将箱线图垂直摆放,默认垂直摆放
whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差
patch_artist:bool类型参数,是否填充箱体的颜色;默认为False
meanline:bool类型参数,是否用线的形式表示均值,默认为False
showmeans:bool类型参数,是否显示均值,默认为False
showcaps:bool类型参数,是否显示箱线图顶端和末端的两条线(即上下须),默认为True showbox:bool类型参数,是否显示箱线图的箱体,默认为True
showfliers:是否显示异常值,默认为True
boxprops:设置箱体的属性,如边框色,填充色等
labels:为箱线图添加标签,类似于图例的作用
filerprops:设置异常值的属性,如异常点的形状、大小、填充色等
medianprops:设置中位数的属性,如线的类型、粗细等
meanprops:设置均值的属性,如点的大小、颜色等
capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等
whiskerprops:设置须的属性,如颜色、粗细、线的类型等
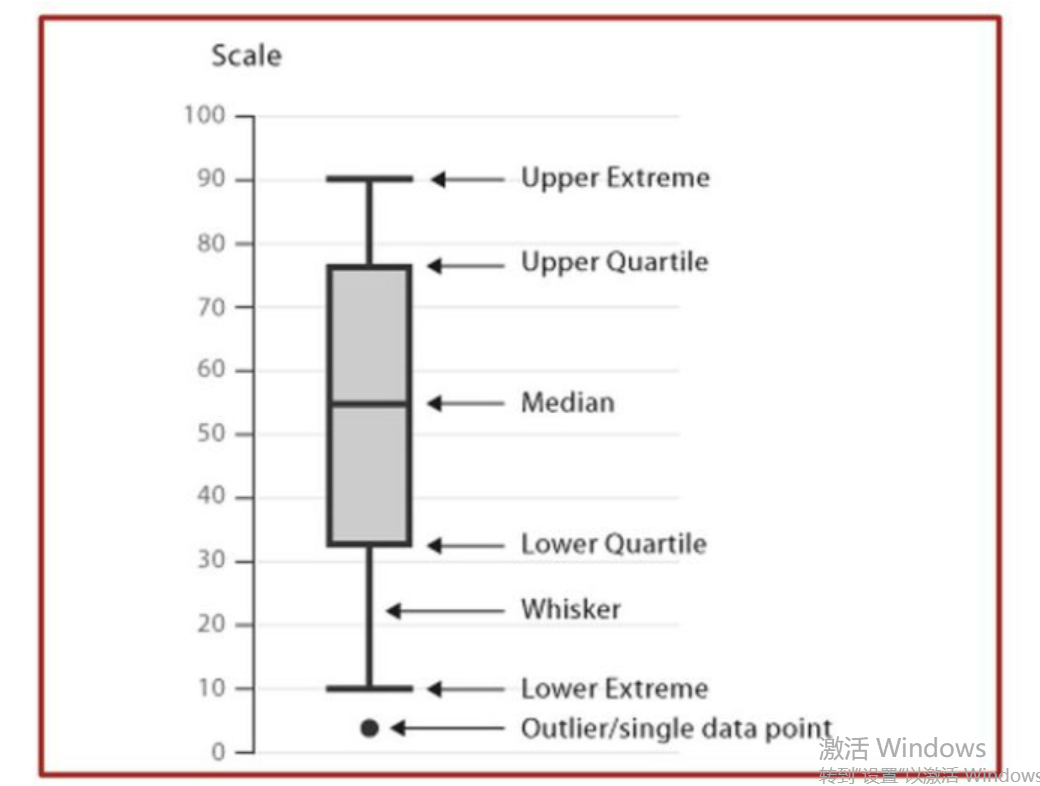
Sec_Buildings = pd.read_excel('sec_buildings.xlsx')
# 绘制箱线图
plt.boxplot(x = Sec_Buildings.price_unit, # 指定绘图数据
patch_artist=False, # 要求用自定义颜色填充盒形图,默认白色填充 这边简单一点就全用默认的
showmeans=True, # 以点的形式显示均值
labels = ['']) # 删除x轴的刻度标签,否则图形显示刻度标签为1
# 添加图形标题
plt.title('二手房单价分布的箱线图')
# 显示图形
plt.show()
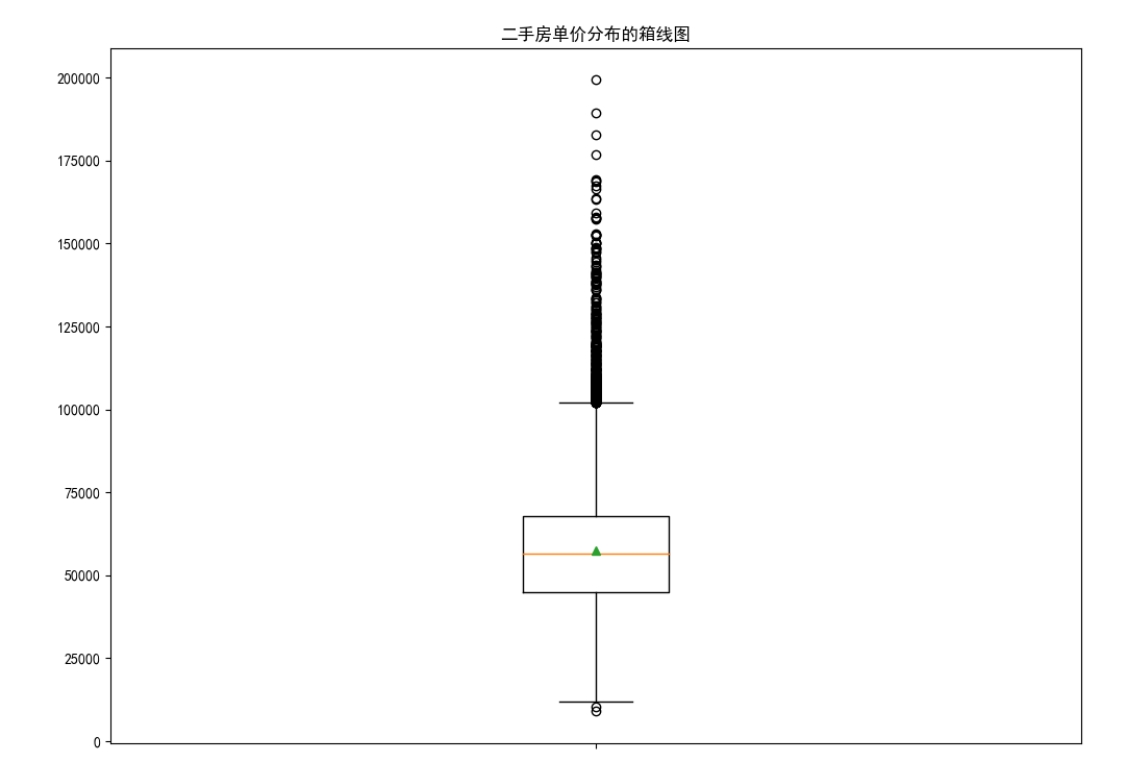
# 读入数据
Sec_Buildings = pd.read_excel('sec_buildings.xlsx')
# 绘制箱线图
plt.boxplot(x = Sec_Buildings.price_unit, # 指定绘图数据
patch_artist=True, # 这次用别的参数美化一下
showmeans=True, # 以点的形式显示均值
boxprops = {'color':'black','facecolor':'steelblue'},# 设置箱体属性,如边框色和填充色
# 设置异常点属性,如点的形状、填充色和点的大小
flierprops = {'marker':'o','markerfacecolor':'red', 'markersize':3,'markeredgecolor':'red'},
# 设置均值点的属性,如点的形状、填充色和点的大小
meanprops = {'marker':'D','markerfacecolor':'indianred', 'markersize':4},
# 设置中位数线的属性,如线的类型和颜色
medianprops = {'linestyle':'--','color':'orange'},
labels = [''] # 删除x轴的刻度标签,否则图形显示刻度标签为1
)
# 添加图形标题
plt.title('二手房单价分布的箱线图')
# 显示图形
plt.show()

折线图
对于时间序列数据而言,一般都会使用折线图反映数据背后的趋势。通常折线图的横坐标指代日期数据,纵坐标代表某个数值型变量,当然还可以使用第三个离散变量对折线图进行分组处理;
'''折线图就是用于时间不同情况下的比对'''
plt.plot(x, y, linestyle, linewidth, color, marker,markersize, markeredgecolor, markerfactcolor,markeredgewidth, label, alpha)
x:指定折线图的x轴数据
y:指定折线图的y轴数据
linestyle:指定折线的类型,可以是实线、虚线、点虚线、点点线等,默认为实线
linewidth:指定折线的宽度
marker:可以为折线图添加点,该参数是设置点的形状
markersize:设置点的大小
markeredgecolor:设置点的边框色
markerfactcolor:设置点的填充色
markeredgewidth:设置点的边框宽度
label:为折线图添加标签,类似于图例的作用

# 数据读取
wechat = pd.read_excel(r'wechat.xlsx')
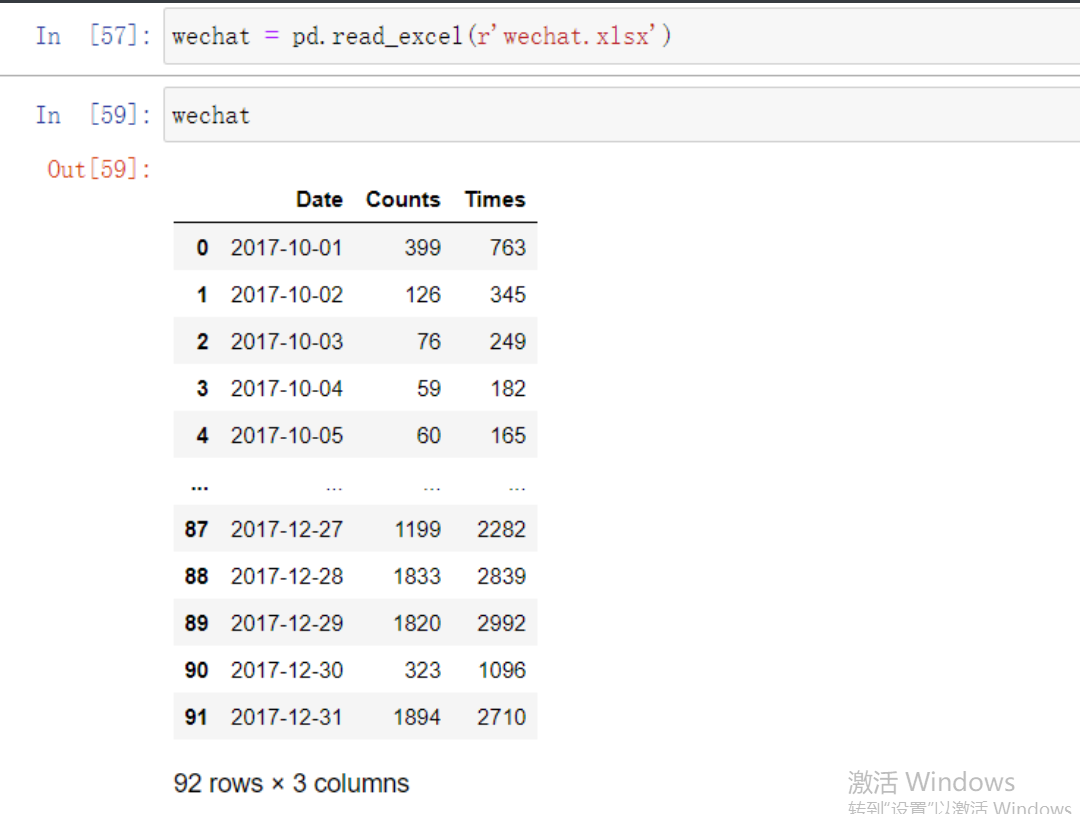
plt.plot(wechat.Date, # x轴数据
wechat.Counts) # y轴数据
'''这样一个最简单的折线图构造已经结束了'''
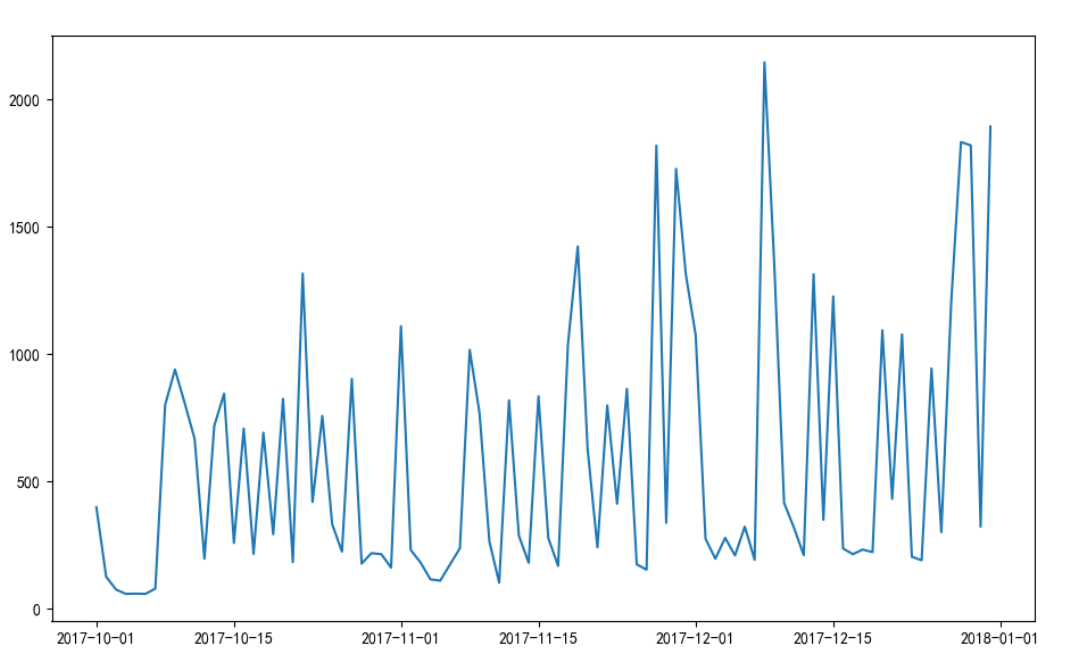
'''在后面加上这些略微美化'''
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
# 固定格式 管你看没看懂 看就完了
ax.xaxis.set_major_formatter(date_format)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
# 这部分格式固定只能硬记
ax.xaxis.set_major_locator(xlocator)
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数趋势')
# 显示图形
plt.show()
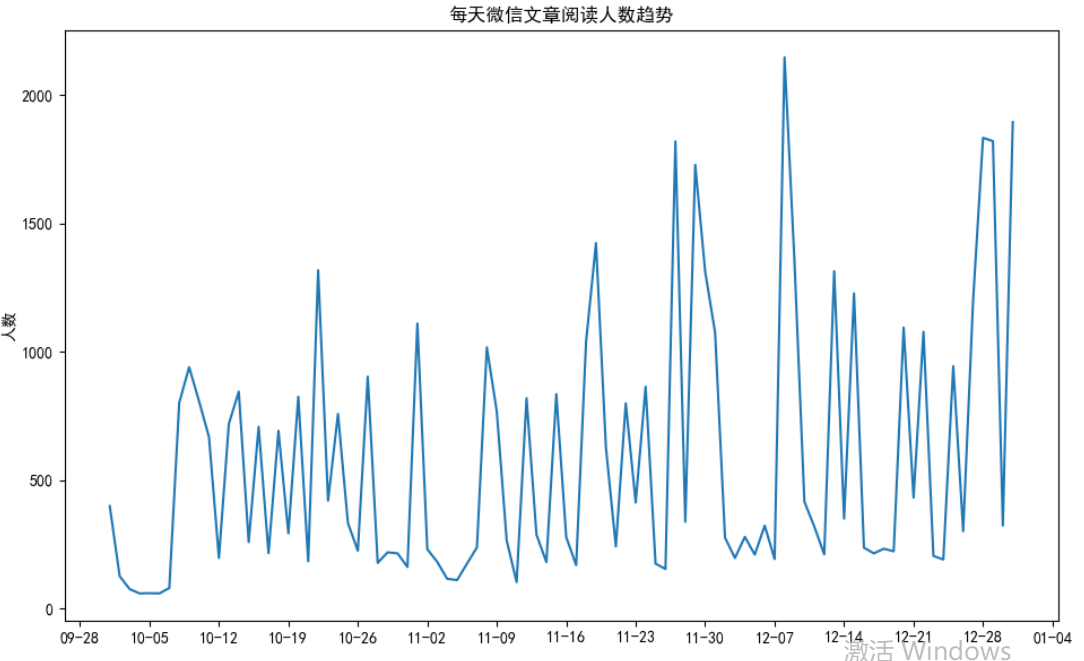
'''最后再往图里的颜色样式啥的改改'''
import matplotlib as mpl
plt.plot(wechat.Date, # x轴数据
wechat.Counts, # y轴数据
linestyle = '--', # 折线类型
linewidth = 1, # 折线宽度
color = 'blue', # 折线颜色
marker = 'o', # 折线图中添加圆点
markersize = 3, # 点的大小
markeredgecolor='black', # 点的边框色
markerfacecolor='brown') # 点的填充色
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数趋势')
# 显示图形
plt.show()
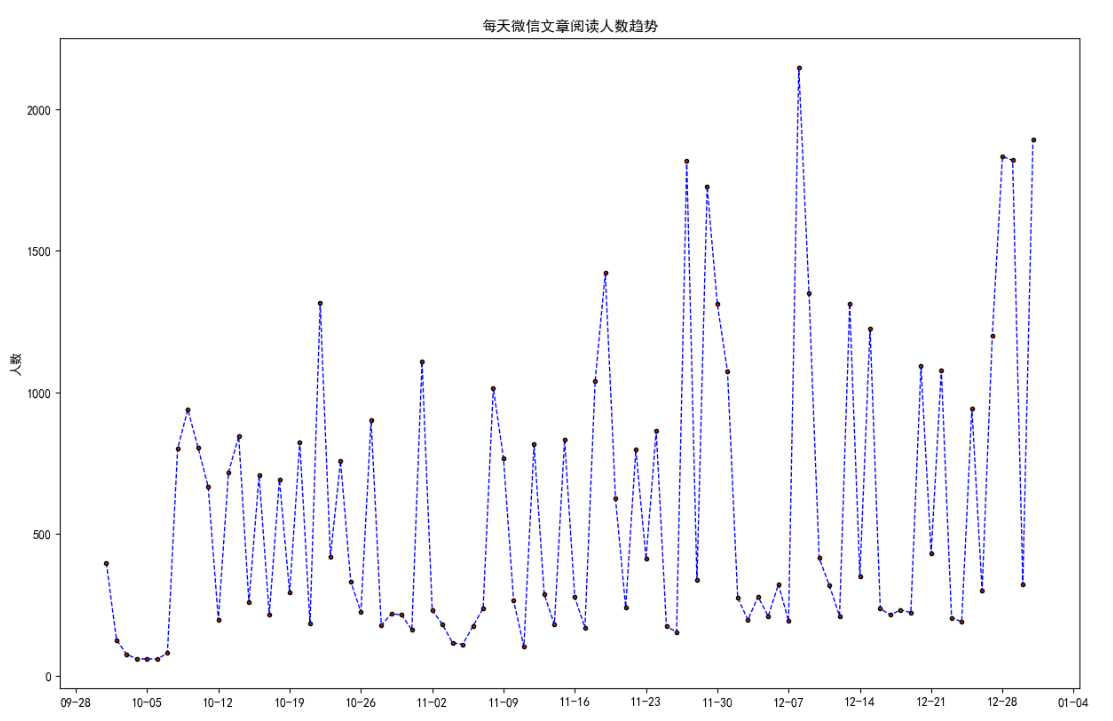
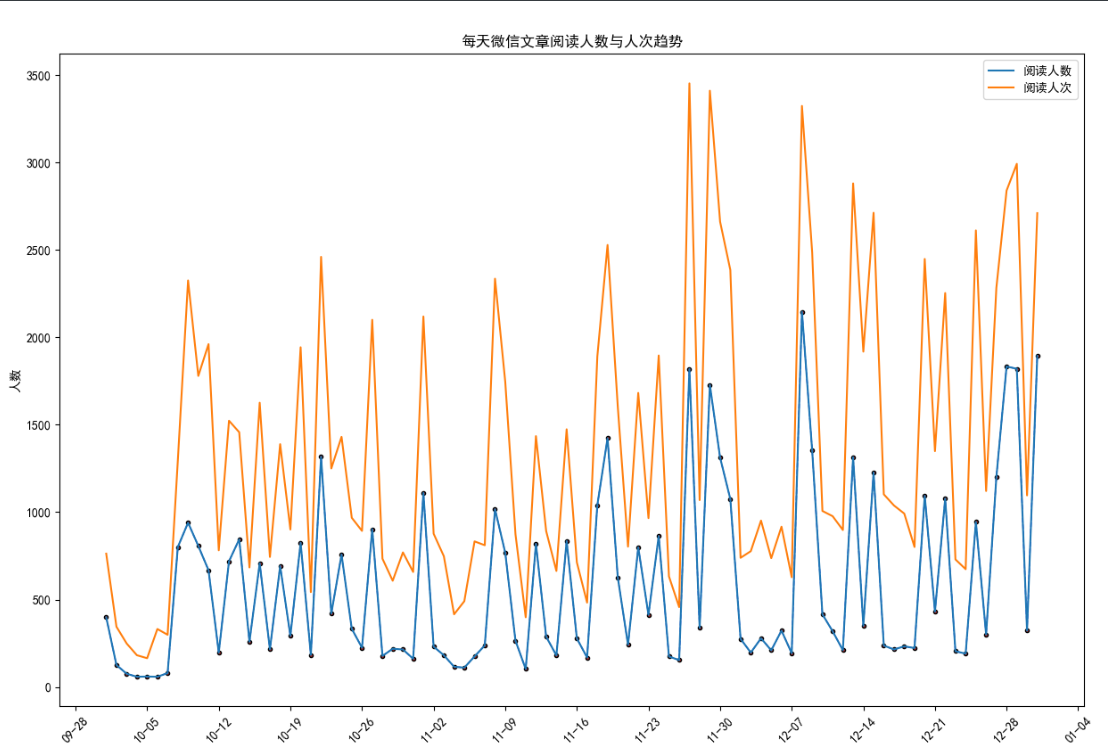
'''一张折线图的搞完了来看看两张的'''
# 绘制阅读人数折线图
plt.plot(wechat.Date, # x轴数据
wechat.Counts, # y轴数据
label = '阅读人数')
# 绘制阅读人次折线图
plt.plot(wechat.Date, # x轴数据
wechat.Times, # y轴数据
label = '阅读人次')
# 获取图的坐标信息
ax = plt.gca()
# 设置日期的显示格式
date_format = mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴显示多少个日期刻度
# xlocator = mpl.ticker.LinearLocator(10)
# 设置x轴每个刻度的间隔天数
xlocator = mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 为了避免x轴刻度标签的紧凑,将刻度标签旋转45度
plt.xticks(rotation=45) # 这个功能还挺好用的 让x轴一下子宽敞不少
# 添加y轴标签
plt.ylabel('人数')
# 添加图形标题
plt.title('每天微信文章阅读人数与人次趋势')
# 添加图例
plt.legend() # 就是显示哪个线代表哪个的
# 显示图形
plt.show()
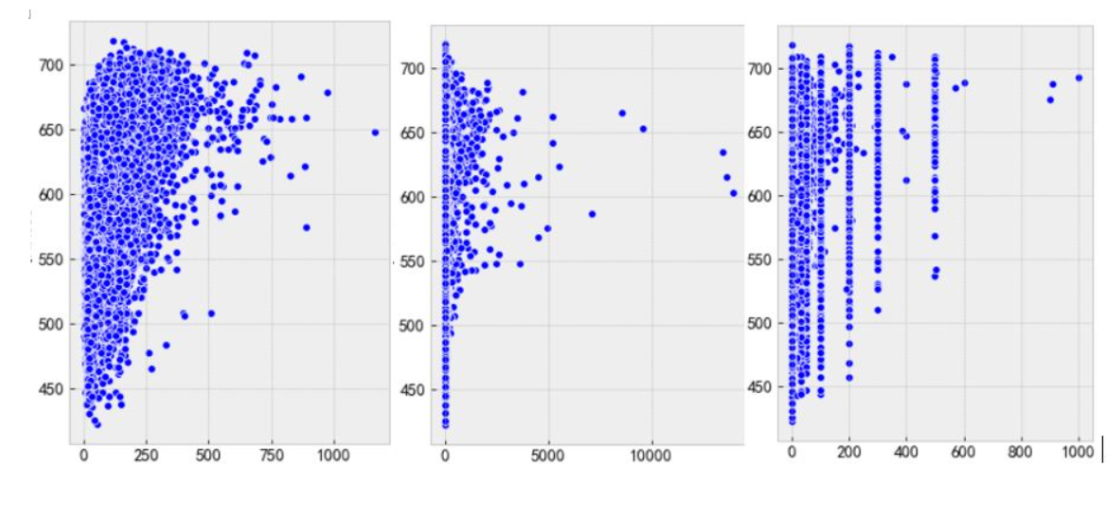
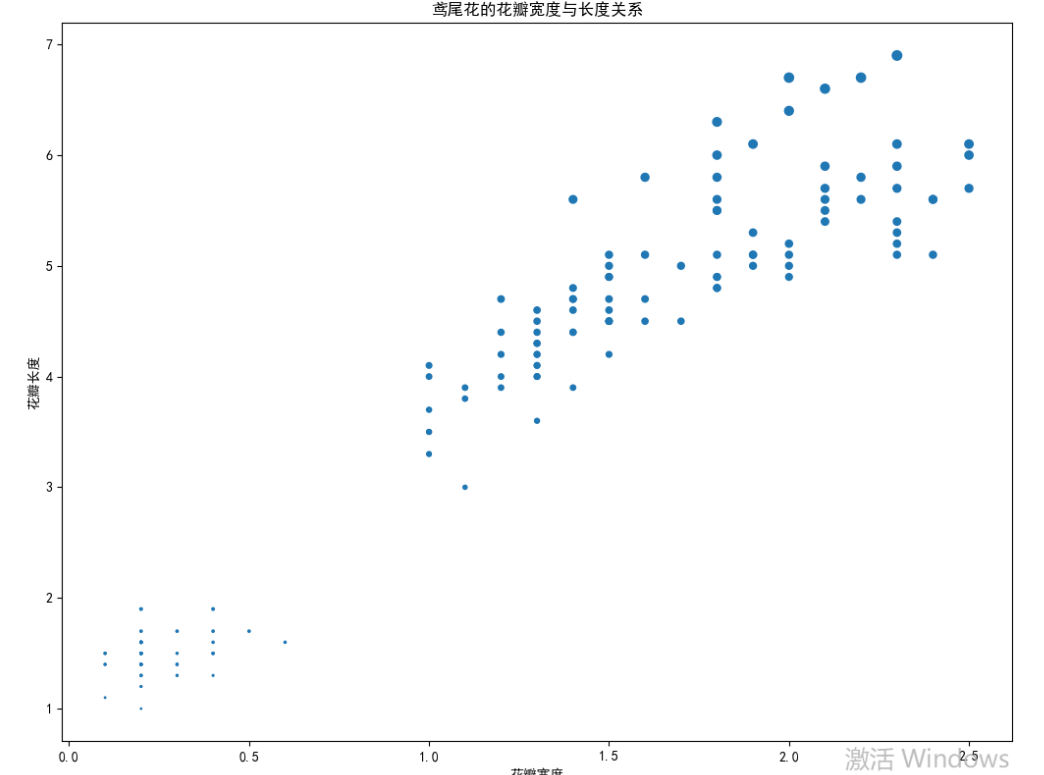
散点图
如果需要研究两个数值型变量之间是否存在某种关系,例如正向的线性关系,或者是趋势性的非线性关系,那么散点图将是最佳的选择;
'''一言以蔽之 就是查看数据之间是否具有'''
scatter(x, y, s=20, c=None, marker='o', alpha=None, linewidths=None, edgecolors=None)
x:指定散点图的x轴数据
y:指定散点图的y轴数据
s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制
c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小
marker:指定散点图点的形状,默认为空心圆
alpha:设置散点的透明度
linewidths:设置散点边界线的宽度
edgecolors:设置散点边界线的颜色
# 读数据
iris = pd.read_csv(r'iris.csv')
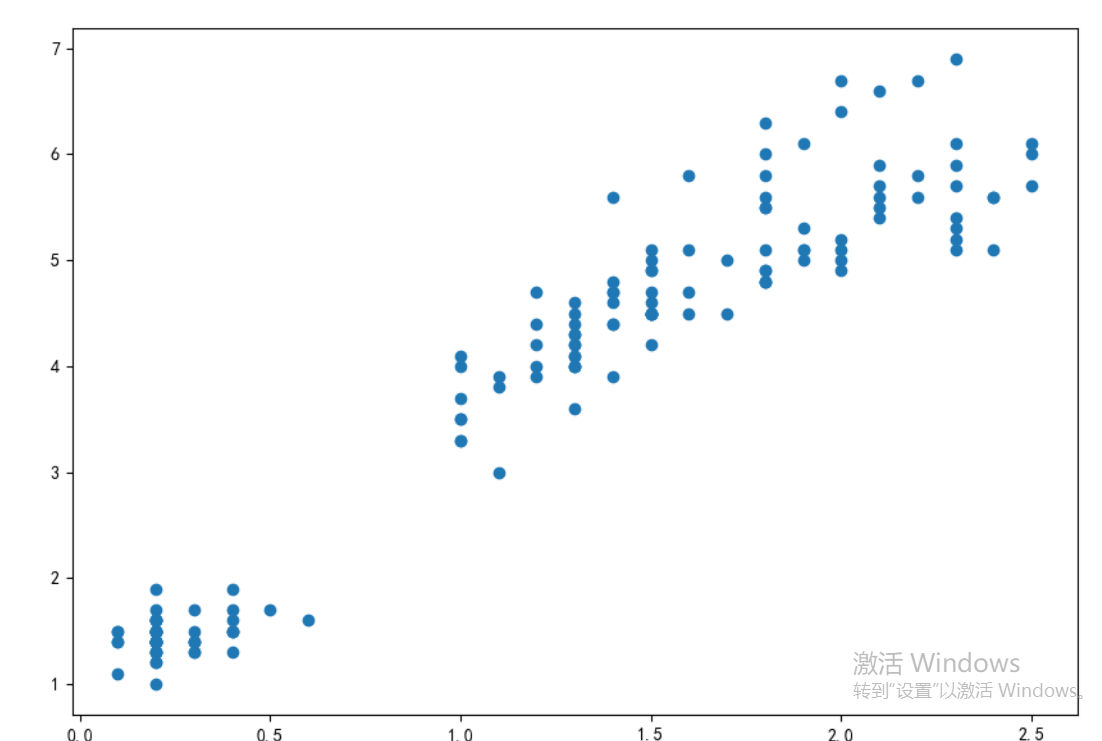
# 绘制散点图
plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据
y = iris.Petal_Length) # 指定散点图的y轴数据
plt.show()
'''主体结构就已经有了'''
'''然后再加上一些参数美化 花里胡哨的颜色也搞上'''
# 读入数据
iris = pd.read_csv(r'iris.csv')
# 绘制散点图
plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据
y = iris.Petal_Length, # 指定散点图的y轴数据
color = 'orange' # 指定散点图中点的颜色
)
# 添加x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
# 显示图形
plt.show()
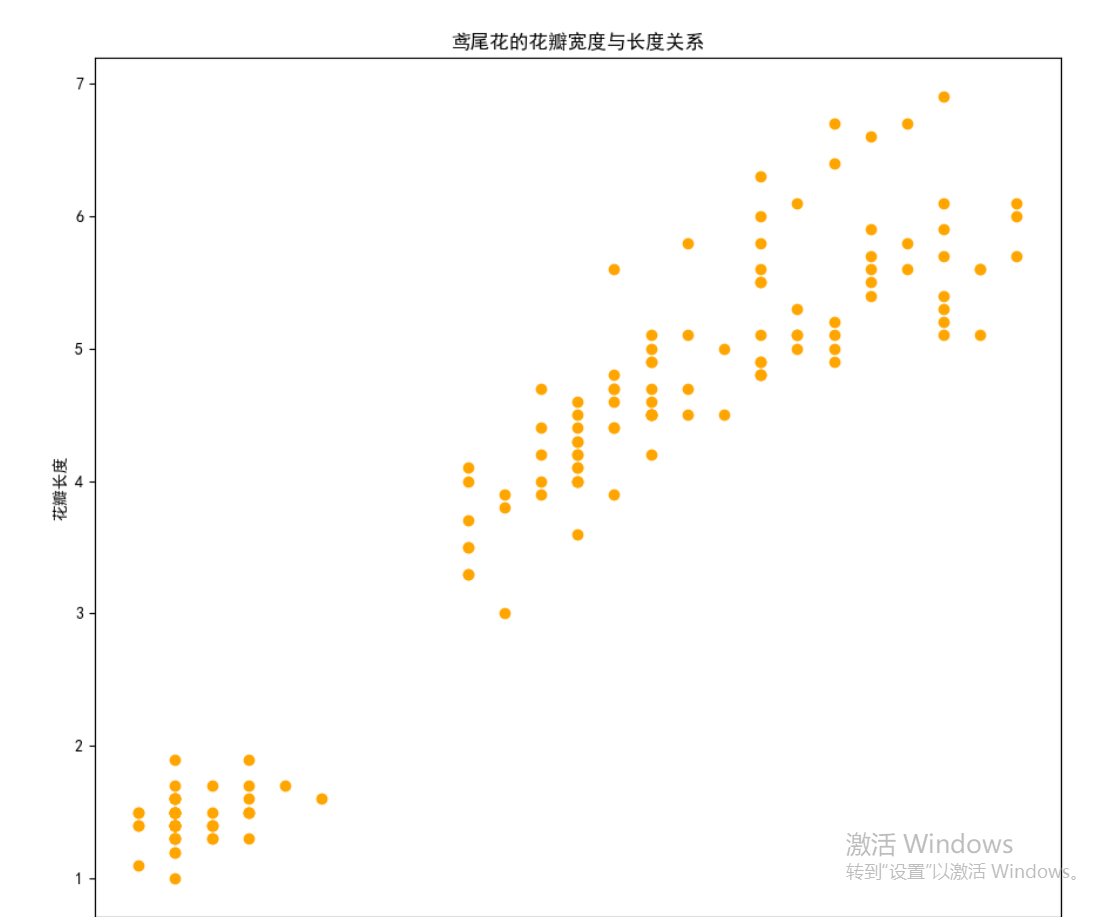
气泡图
# 气泡图一般数据量不会大
气泡图的实质就是通过第三个数值型变量控制每个散点的大小,点越大,代表的第三维数值越高,反之亦然;
气泡图的绘制,使用的仍然是scatter函数,区别在于函数的s参数被赋予了具体的数值型变量
'''也就是观察两者数据之间联系的时候还加上了另一个参数'''
就以前面的数据为例加入一个s参数
# 读入数据
iris = pd.read_csv(r'iris.csv')
# 绘制散点图
plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据
y = iris.Petal_Length, # 指定散点图的y轴数据
s = iris.Petal_Length**2
)
# 添加x轴和y轴标签
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
# 添加标题
plt.title('鸢尾花的花瓣宽度与长度关系')
# 显示图形
plt.show()
热力图
热力图也称为交叉填充表,图形最典型的用法就是实现列联表的可视化,即通过图形的方式展现两个离散变量之间的组合关系;
'''展示两个变量组合之后的关系'''
# matplotlib绘制热力图不太方便需要借助于seaborn模块
sns.heatmap(data, cmap=None, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor ='white)
data:指定绘制热力图的数据集
cmap:指定一个colormap对象,用于热力图的填充色
annot:指定一个bool类型的值或与data参数形状一样的数组,如果为True,就在热力图的每个单元上显示数值
fmt:指定单元格中数据的显示格式
annot_kws:有关单元格中数值标签的其他属性描述,如颜色、大小等
linewidths:指定每个单元格的边框宽度
linecolor:指定每个单元格的边框颜色
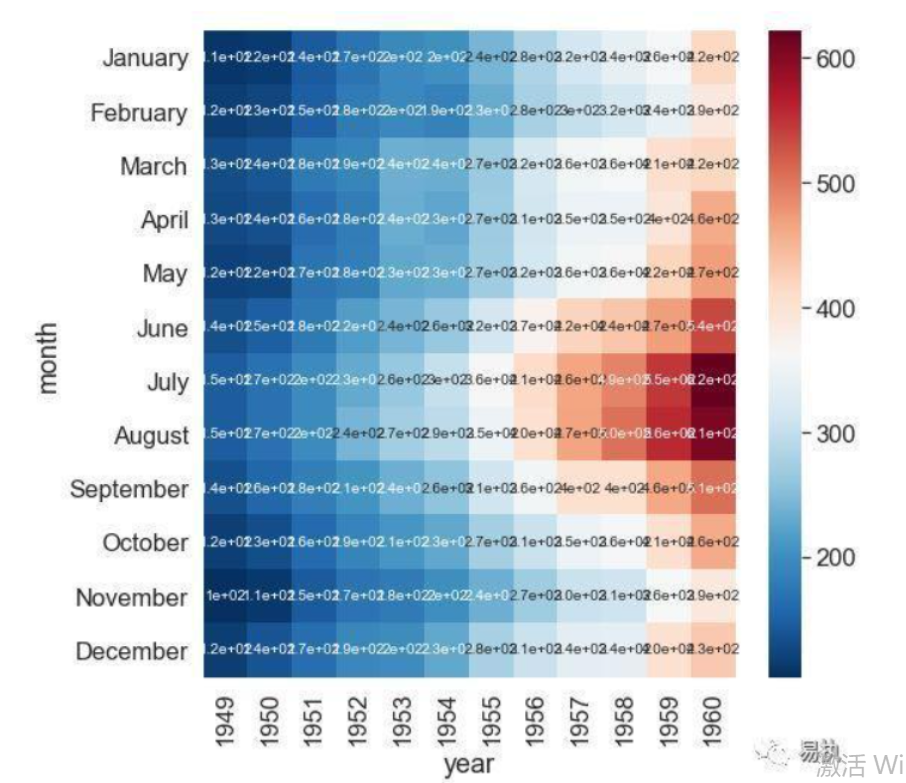
import numpy as np
import seaborn as sns
# 读取数据
Sales = pd.read_excel(r'Sales.xlsx')
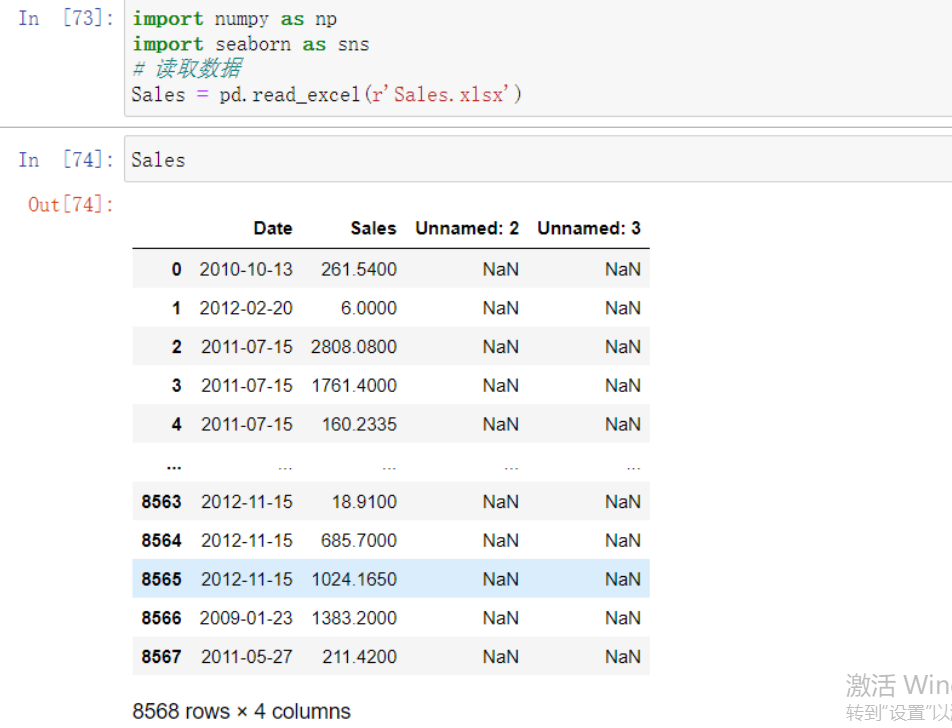
# 根据交易日期,衍生出年份和月份字段
Sales['year'] = Sales.Date.dt.year
Sales['month'] = Sales.Date.dt.month
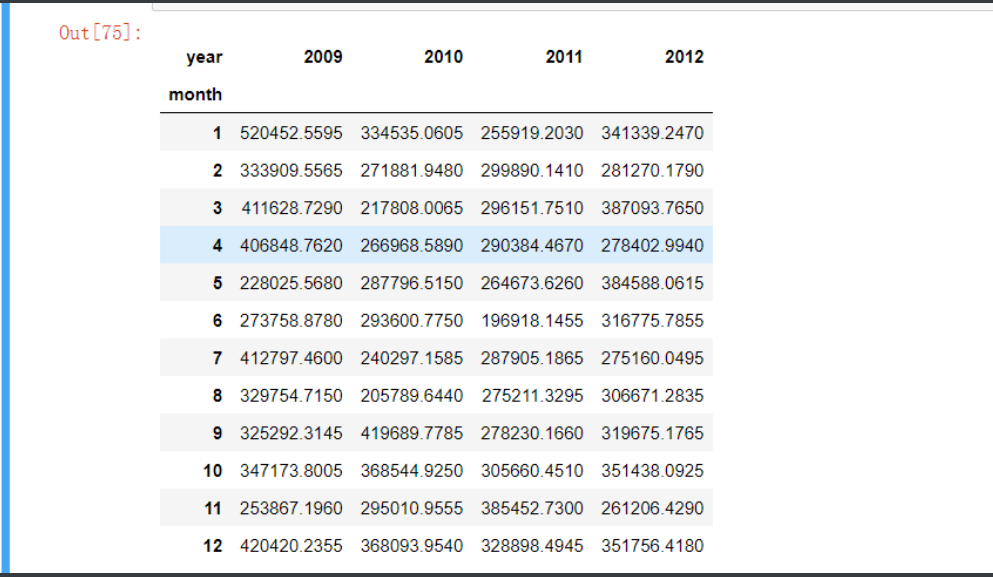
# 统计每年各月份的销售总额 绘制热力图之前 必须将数据转换为交叉表形式
Summary = Sales.pivot_table(index = 'month', columns = 'year', values = 'Sales', aggfunc = np.sum) # 数据透视
Summary
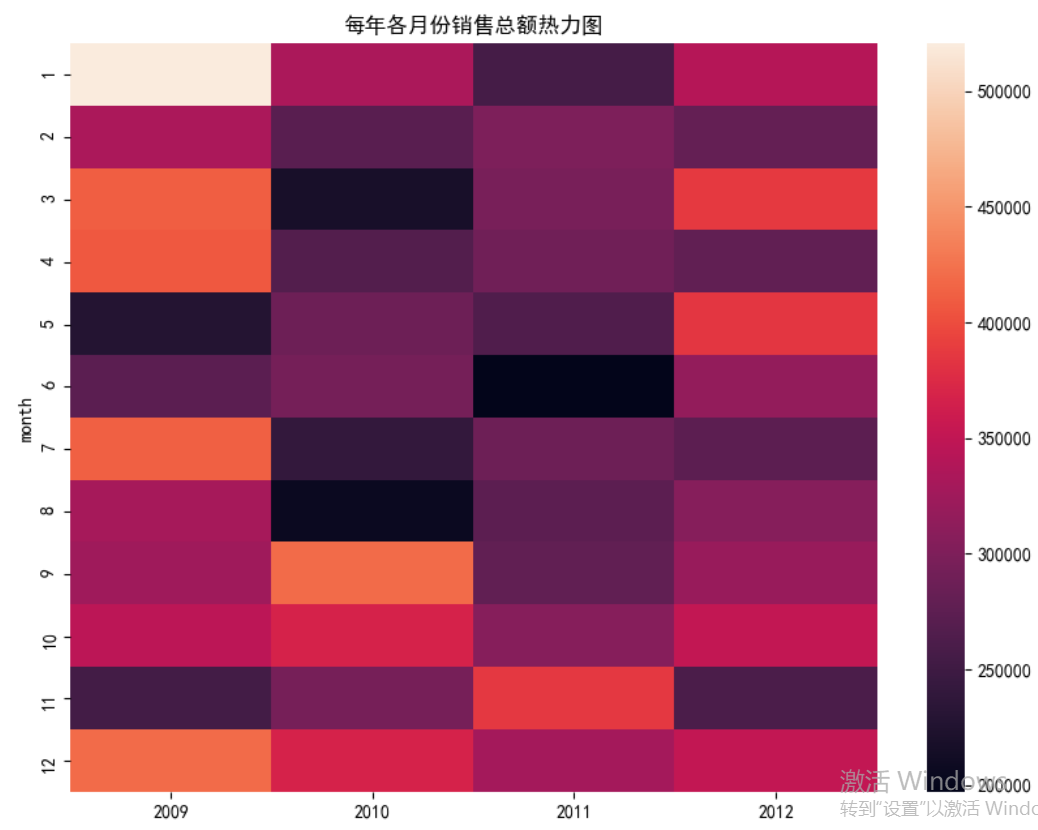
'''热力表就是这张虚拟表 展示一下 数据多的地方颜色加深'''
sns.heatmap(data = Summary) # 指定绘图数据
'''可以看到热力图的关键是在建表'''
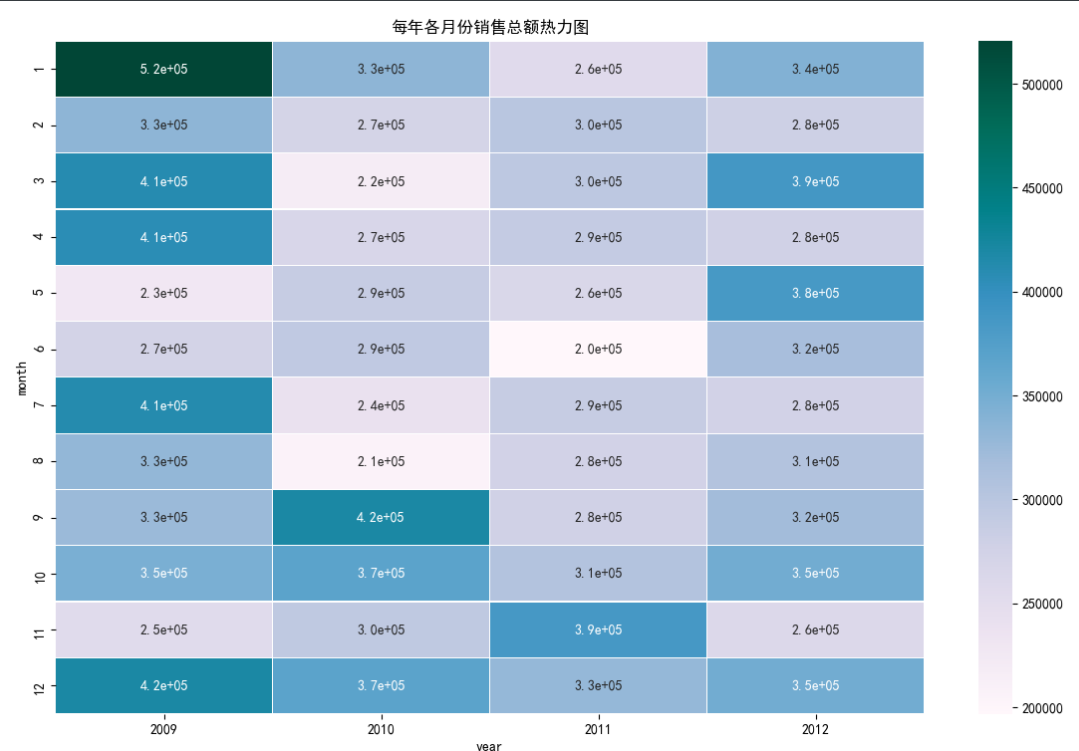
# 绘制热力图
sns.heatmap(data = Summary, # 指定绘图数据
cmap = 'PuBuGn', # 指定填充色
linewidths = .1, # 设置每个单元格边框的宽度
annot = True, # 显示数值
fmt = '.1e') # 以科学计算法显示数据
#添加标题
plt.title('每年各月份销售总额热力图')
# 显示图形
plt.show()
组合图
工作中往往会根据业务需求,将绘制的多个图形组合到一个大图框内,形成类似仪表板的效果;
plt.subplot2grid(shape, loc, rowspan=1, colspan=1, **kwargs)
shape:指定组合图的框架形状,以元组形式传递,如2×3的矩阵可以表示成(2,3)
loc:指定子图所在的位置,如shape中第一行第一列可以表示成(0,0)
rowspan:指定某个子图需要跨几行
colspan:指定某个子图需要跨几列
"""
# 设置大图框的长和高 plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0))
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1))
# 设置第三个子图的布局
ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2)
# 设置第四个子图的布局
ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2)
"""
# 读取数据
Prod_Trade = pd.read_excel(r'Prod_Trade.xlsx')
# 衍生出交易年份和月份字段
Prod_Trade['year'] = Prod_Trade.Date.dt.year
Prod_Trade['month'] = Prod_Trade.Date.dt.month
# 设置大图框
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0))
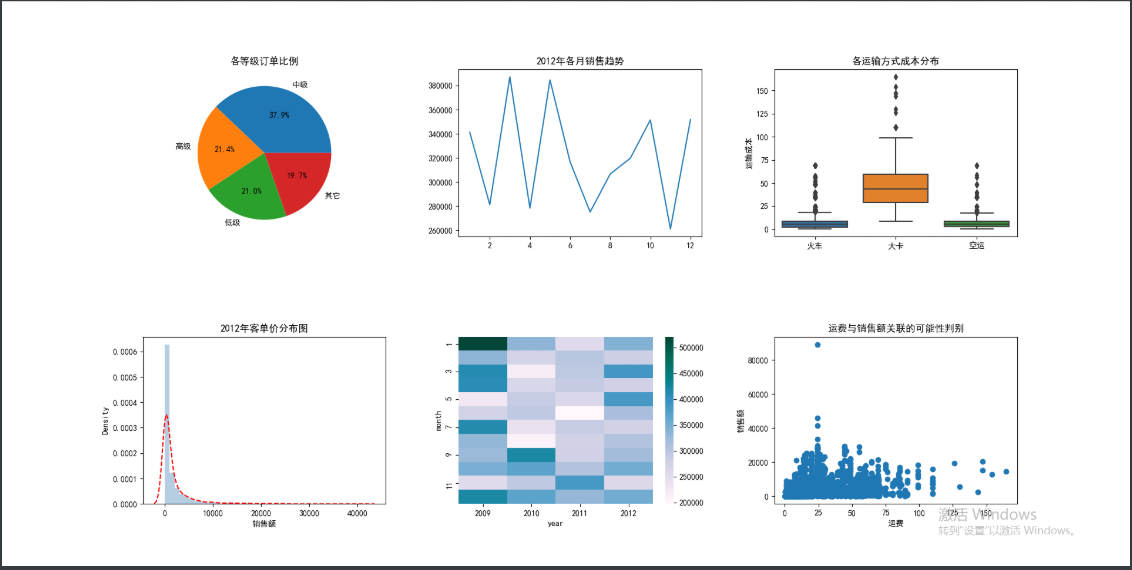
# 统计2012年各订单等级的数量
Class_Counts = Prod_Trade.Order_Class[Prod_Trade.year == 2012].value_counts()
# 这种也能达到所需要求但是获取到的是DF结构不方便后续操作所以还是用上面那种
# Class_Counts = Prod_Trade[Prod_Trade.year == 2012].groupby(by='Order_Class').aggregate({'Order_Class':np.size})
Class_Percent = Class_Counts/Class_Counts.sum() # 获取到各等级所占比例
# 绘制订单等级饼图
ax1.pie(x = Class_Percent.values, labels = Class_Percent.index, autopct = '%.1f%%')
# 添加标题
ax1.set_title('各等级订单比例')
# 接下来设置第二个子图布局
ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1))
# 统计2012年每月销售额
Month_Sales = Prod_Trade[Prod_Trade.year == 2012].groupby(by = 'month').aggregate({'Sales':np.sum})
# 绘制销售额趋势图
Month_Sales.plot(title = '2012年各月销售趋势', ax = ax2, legend = False)
# 删除x轴标签
ax2.set_xlabel('')
# 设置第三个子图的布局
ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2))
# 绘制各运输方式的成本箱线图
sns.boxplot(x = 'Transport', y = 'Trans_Cost', data = Prod_Trade, ax = ax3)
# 添加标题
ax3.set_title('各运输方式成本分布')
# 删除x轴标签
ax3.set_xlabel('')
# 修改y轴标签
ax3.set_ylabel('运输成本')
# 设置第四个子图的布局
ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0))
# 2012年客单价分布直方图
sns.distplot(Prod_Trade.Sales[Prod_Trade.year == 2012], bins = 40, norm_hist = True, ax = ax4, hist_kws = {'color':'steelblue'}, kde_kws=({'linestyle':'--', 'color':'red'}))
# 添加标题
ax4.set_title('2012年客单价分布图')
# 修改x轴标签
ax4.set_xlabel('销售额')
# 调整子图之间的水平间距和高度间距
plt.subplots_adjust(hspace=0.6, wspace=0.3)
# 图形显示
plt.show()
# 设置第五个子图的布局
ax5 = plt.subplot2grid(shape = (2,3), loc = (1,1))
# 搞热力图先整个模块
import numpy as np
import seaborn as sns
# 搞一张虚拟图的透视表
Summary = Prod_Trade.pivot_table(index = 'month', columns = 'year', values = 'Sales', aggfunc = np.sum)
# 表搞完搞图 不是想怎么玩怎么来
ax5 = sns.heatmap(data = Summary,
cmap = 'PuBuGn')
# 设置第六个子图的布局
ax6 = plt.subplot2grid(shape = (2,3), loc = (1,2))
ax6 = plt.scatter(x = Prod_Trade.Trans_Cost,
y = Prod_Trade.Sales)
plt.xlabel('运费')
plt.ylabel('销售额')
# 添加标题
plt.title('运费与销售额关联的可能性判别')
可视化相关模块
1.matplotlib
2.seaborn
3.highcharts
4.echarts # 比较重点
pyecharts # 可以通过python代码直接调用
5.ds.js
'''关键还是基础学好'''
echarts
# 堆叠柱状图
不仅希望知道不同系列各自的数值,还希望知道它们之和的变化,这时候通常使用堆积柱状图图来表现
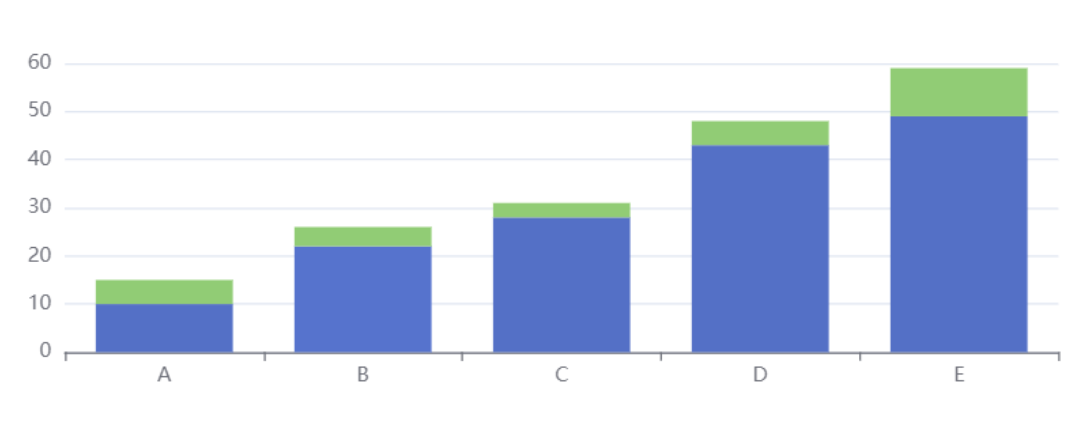
# 动态排序柱状图
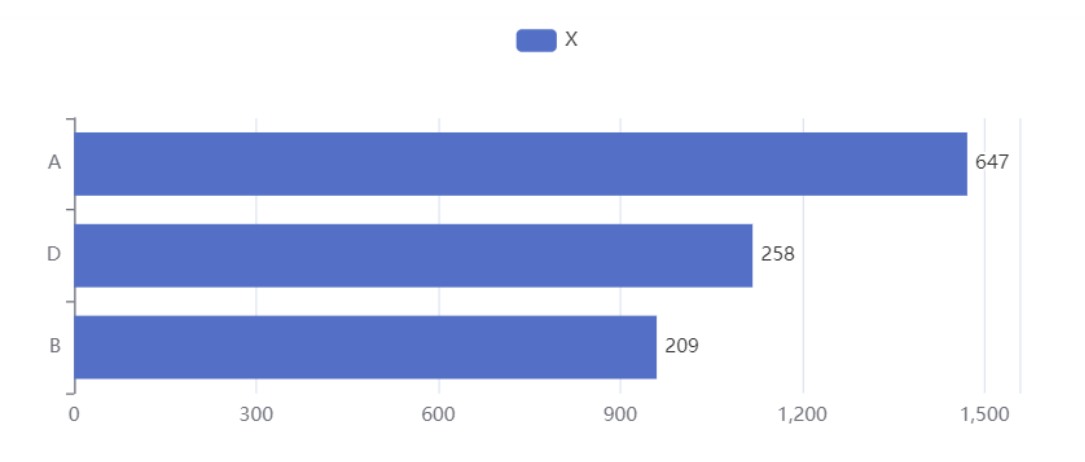
动态排序柱状图是一种展示随时间变化的数据排名变化的图表
下图中的柱状图是在动态变化的
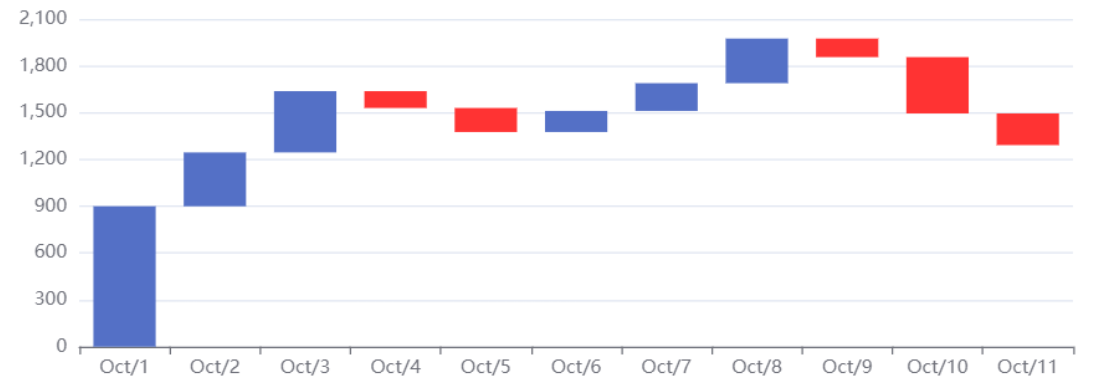
# 阶梯瀑布图
进阶版柱状图 可以将变化看的更清楚
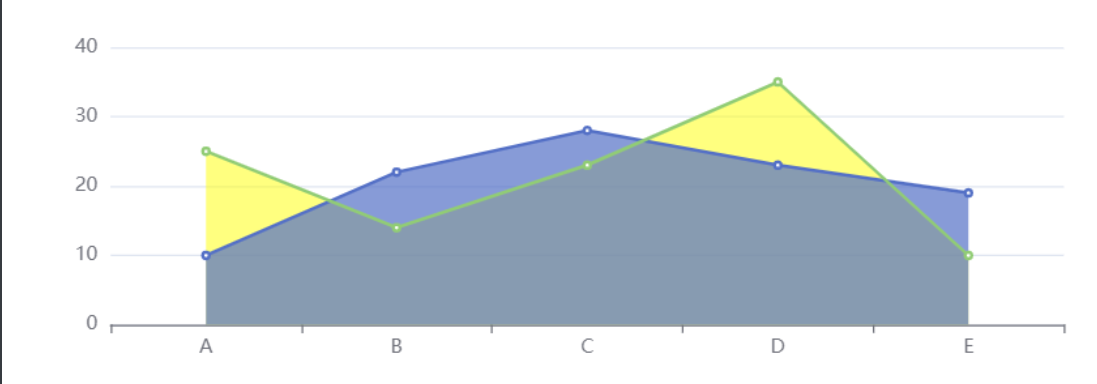
# 区域面积图
比普通的折线图,区域面积图的视觉效果更加饱满丰富
# 阶梯线图
阶梯线图能够很好地表达数据的突变
# 圆环图
中间空余的部分可以用来显示一些额外的文字等信息
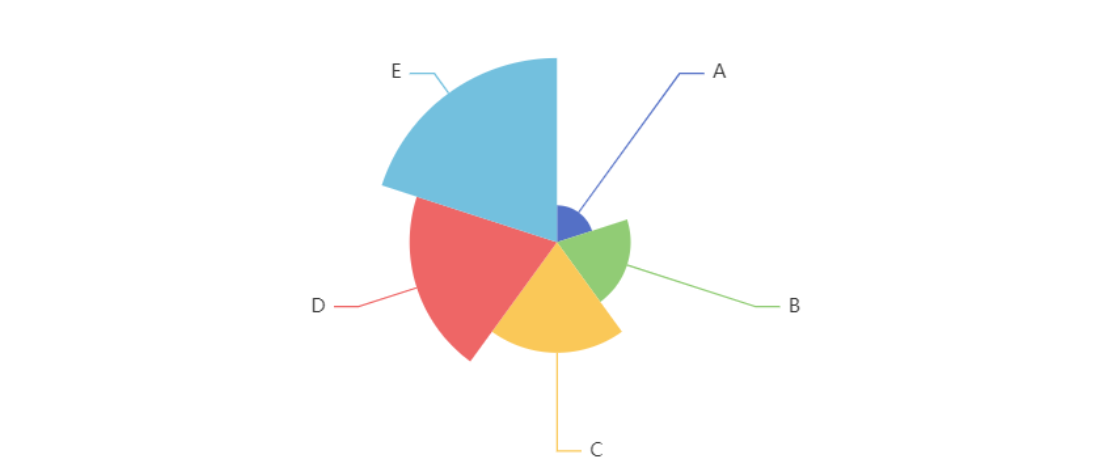
# 南丁格尔图(玫瑰图)
通常用弧度相同但半径不同的扇形表示各个类目 看起来好看特别一点