
10/14
今日考题
1.聊聊numpy模块
python编程环境中对于数字并不敏感 所以会出现一些将数字精确度降低的情况
同时仅用python自带的方式计算会消耗大量的时间 在数据量巨大的时候时间会成倍上涨
numpy模块可以有效的解决以上两个问题 同时他也是诸多运算模块的基础
numpy一般import之后会起别名np
2.numpy如何创建数组又有何重要特性
np.array() 里面写所需数组一个中括号是一维数组最多3维
数组可以直接参与计算 计算过程中每个元素会一一进行计算
一维数组取值与列表的取值同理
在多维(二维)数组取值的时候可以将行列都看成列表进行取值
如果要选取全部行用:指代即可行列取值之间逗号隔开
3.查看提示信息的方式有哪些
通过输入文本之后加上问好运行可以查看方法
# 下一种比较常用方便
通过按住shift+tab可以调出方法的介绍再按一次tab出现详情
4.numpy中有哪些比较重要的函数
arrange() # 强化版range支持小数
linspace() # 等分
zeros() # 给形状创建全0数组
ones() # 给形状创建全1数组
empyt() # 给形状创建随机数组
eye() # 给一个边长创建方形数组
greater() # 大于
greater_equal() #大于等于
less() # 小于
not_equal # 不等于
round() # 四舍五入
sqrt() # 开根号
square() # 平方
exp() # e为底指数
power(,x) # x次方
log2() # 2为底对数
log10() # 10为底对数
log() # e为底对数
min(,axis) # 最小值
# axis 表示轴方向1是行 0是列
max() # 最大
mean() # 平均
median() #中位数
sum() # 求和
std() # 标准差
var() # 方差
.random. # 随机数系列
复习巩固
- 查看方法提示
在notebook中查看方法的提示信息有两种方式
1.问号执行
2.shift+tab
- numpy简介
numpy是专门用于科学计算的库 并且很多计算库都使用到了numpy
- numpy数组
# 一维数组
np.array([])
# 二维数组
np.array([[],[],[]])
# 三维数组
np.array([[[],[],[]]])
通过有几个不同的中括号 可以一眼看出是几维数组
"""
数据在参与计算的时候数组内的所有元素都会挨个对应参与运算
数据内元素的数据类型必须保持一致
"""
- numpy常见属性
T 转置
ndim 查看数组维数
dtype 查看数据内元素数据类型
shape 查看数据行列数(结果是一个元组)
- numpy常见方法
arrange() # 强化版range支持小数
linspace() # 等分
zeros() # 给形状创建全0数组
ones() # 给形状创建全1数组
empyt() # 给形状创建随机数组
eye() # 给一个边长创建方形数组
- numpy数据类型
1.由于numpy主要只用在科学计算 所以大部分都是数字类型
2.并且为了避免与python中数据类型关键字冲突有些类型后面加了下划线
布尔值 bool_...
整型 int_...
无符号整型 uint...
浮点型 float_...
复数 complex_...
- numpy运算符和函数
greater() # 大于
greater_equal() #大于等于
less() # 小于
not_equal # 不等于
round() # 四舍五入
sqrt() # 开根号
square() # 平方
exp() # e为底指数
power(,x) # x次方
log2() # 2为底对数
log10() # 10为底对数
log() # e为底对数
min(,axis) # 最小值
# axis 表示轴方向1是行 0是列
max() # 最大
mean() # 平均
median() #中位数
sum() # 求和
std() # 标准差
var() # 方差
- numpy随机数
numpy中也指代一个随机数子模块与python中的random模块有很多相似的功能
import random
random
import numpy as np
np.random
内容概要
主体pandas模块
- pandas简介
- 两大数据结构
Series (过渡)
DataFrame (重点)
- 两大数据结构详细方法
详细讲解
pandas模块
pandas是基于numpy构建的
pandas的出现,让Python一跃成为使用最广泛而且最强大的数据分析语言
pandas针对表格文件的操作有非常大的优势
尤其是数据量超过10万的 这种较多数据的时候
# pandas的主要功能
具备诸多功能的两大数据结构
Series、DataFrame 都是基于Numpy构建出来的
公司中使用频繁的是DataFrame,而Series是构成DataFrame的基础,即一个DataFrame可能由N个Series构成
集成时间序列功能
提供丰富的数学运算和操作(基于Numpy)
灵活处理缺失数据
导入模块
pip3 install pandas
# anaconda环境下
conda install pandas
'''anaconda已经自动帮助我们下载好了数据分析相关的模块,其实无需我们再下载'''

今日装逼小点
数据分析三剑客模块由于使用频率很高 所以在很多ipynb文件的开头都会提前导入
import numpy as np
import pandas as pd
# 顺便一提pandas翻译过来熊猫可以理解这个模块之于数据分析和熊猫一般重要

数据类型之Series
'''
Series是一种类似于一维数组对象
由数据和相关的标签(索引)组成
内部数据的类型一致 标签无所谓
'''
第一种:
pd.Series([4,5,6,7,8])
# 创建结果像是个表格会自带一个能用于索引的数列
第二种:
pd.Series([4,5,6,7,8],index=['a','b','c','d','e'])
# 这样就规定了用来索引的数列
第三种:
pd.Series({"a":1,"b":2})
# 直接索引对着数值一一传入
第四种:
pd.Series(0,index=['a','b','c'])
# 前面只给一个参数后面给索引 那所有索引对应的值就是前面给定的参数
缺失数据的概念
# 首先做个Series出来
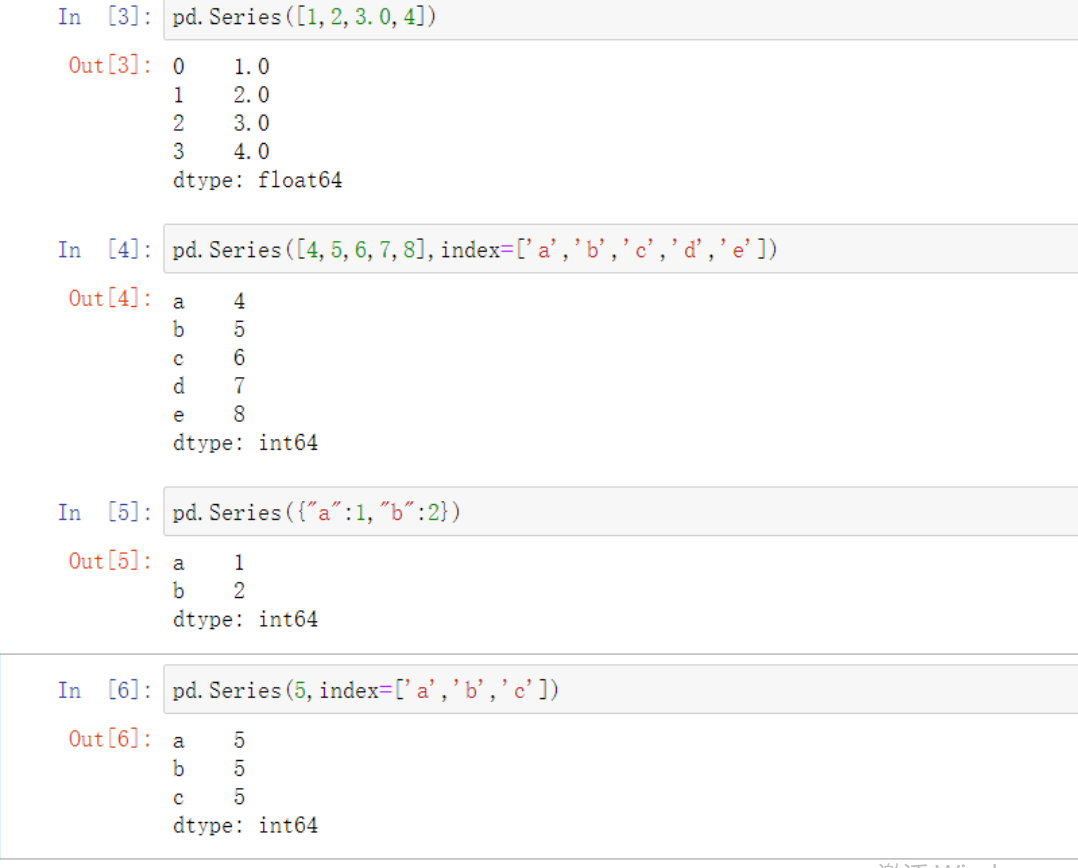
s = pd.Series([1,2,3,4],index=['yang','leo','ace','jason'])
# 定义新索引
n_s = {'yang','leo','ace','vivi'}
# 修改原索引
obj = pd.Series(s,index = n_s) # 这里前面放原ser 后面放新索引的字典
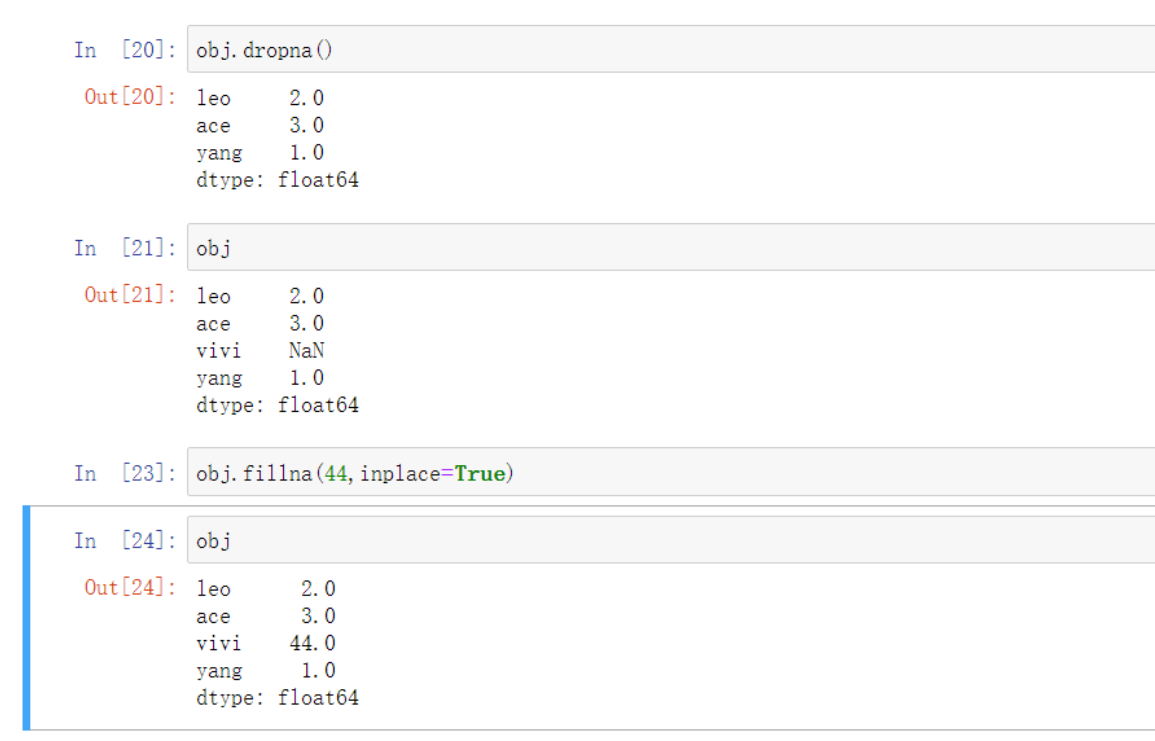
由于vivi之前没有这个索引所以会有个缺失值NaN
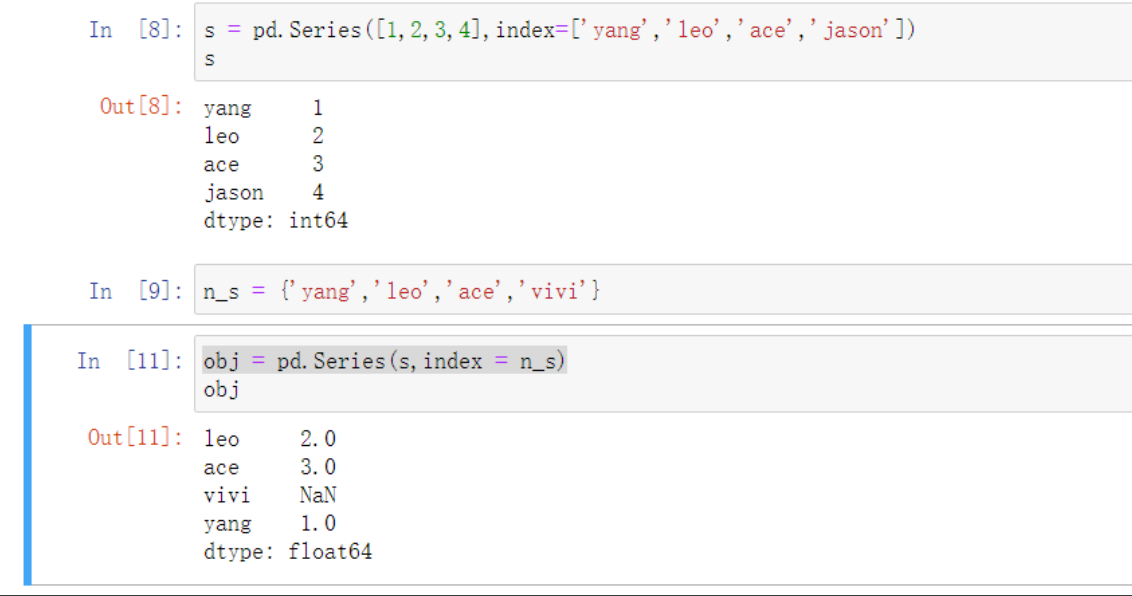
在数据处理中如果遇到NaN关键字那么意思就是缺失数据
并且NaN属于浮点型
pd.isnull() # 缺失的部分返回True 其余False
pd.notnull() # 缺失返回False 与上面相反
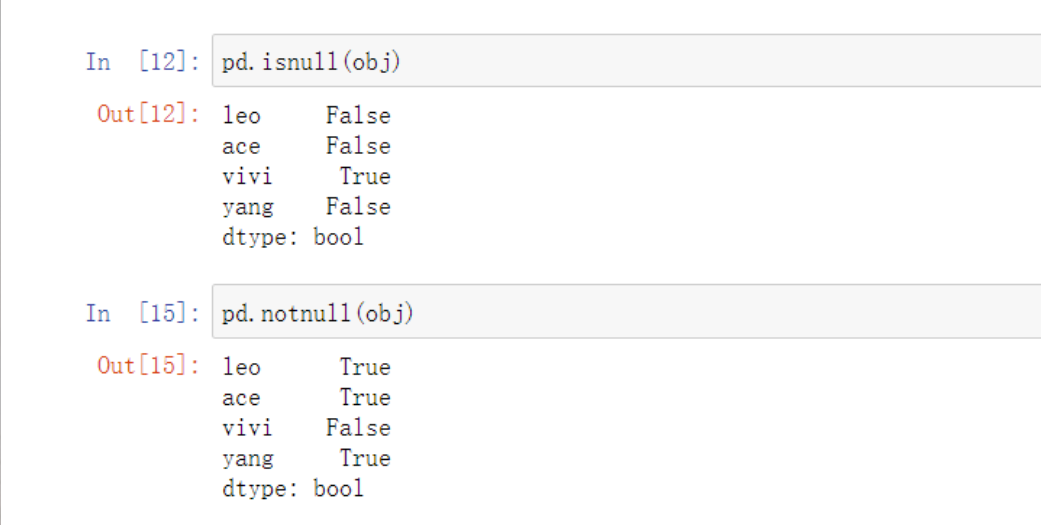
obj.dropna() # 过滤掉值为NaN的行
obj.fillna() # 填充缺失数据
前面要用已有的series来点出功能
数据修改
如何判断当前数据是否改变
1.如果执行操作之后有结果 说明原数据没有变 所以这个只是给你看一下
obj1.fillna(666)
2.如果执行操作之后没有结果说明原数据改变
obj1.fillna(666,inplace=True)
# inplace=True 该参数很多方法都有 意思就是直接改变原数据
布尔值索引
# 布尔值索引本质就是通过series对应着True的位置取出值
# 也可以说是 按照对应关系筛选出True对应的数据
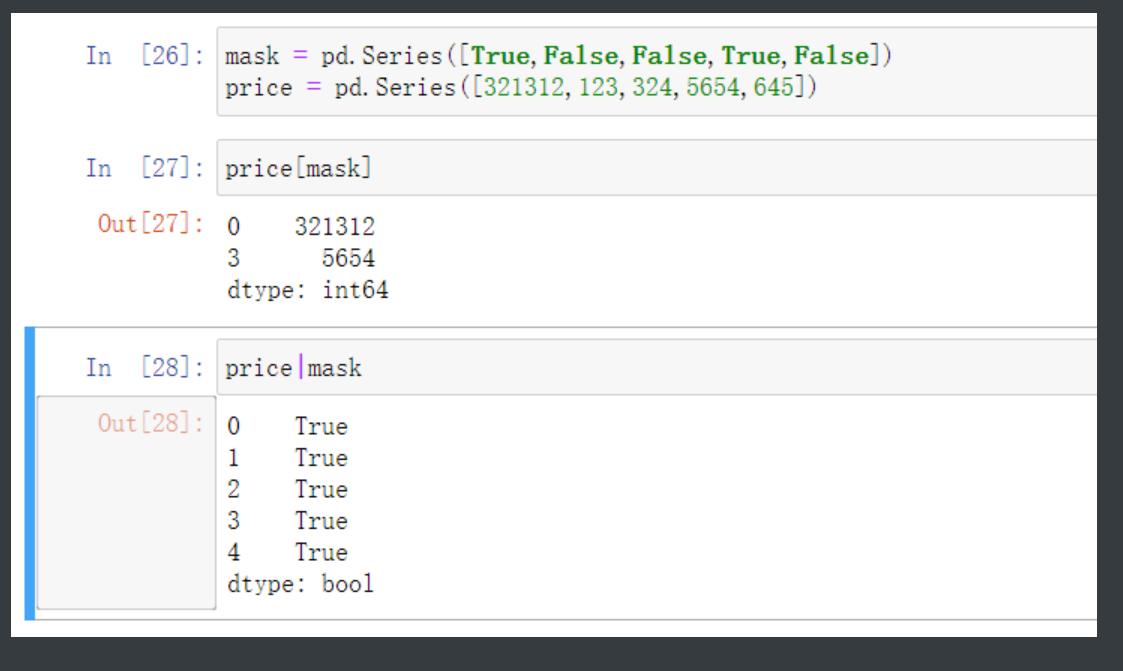
首先做个数据准备
mask = pd.Series([True,False,False,True,False])
price = pd.Series([321312,123,324,5654,645])
price[mask] # 取出对应True的元素
'''就和数组的逻辑索引一样arr[arr>5]
中括号里先是生成了对应结果的布尔值数组'''
price|mask # |就和正则里一样代表or 这里做个或的逻辑门运算结果显而易见price里面全是True结果肯定也全是True
小思考:
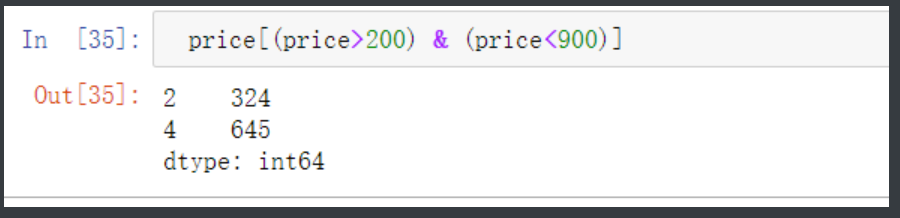
取到price大于200小于900
(price>200) & (price<900) # 通过与逻辑门拿到一个布尔值的series
price[(price>200) & (price<900)] # 通过布尔值索引直接拿
"""针对&符号链接的条件都必须要加括号"""
行索引\行标签
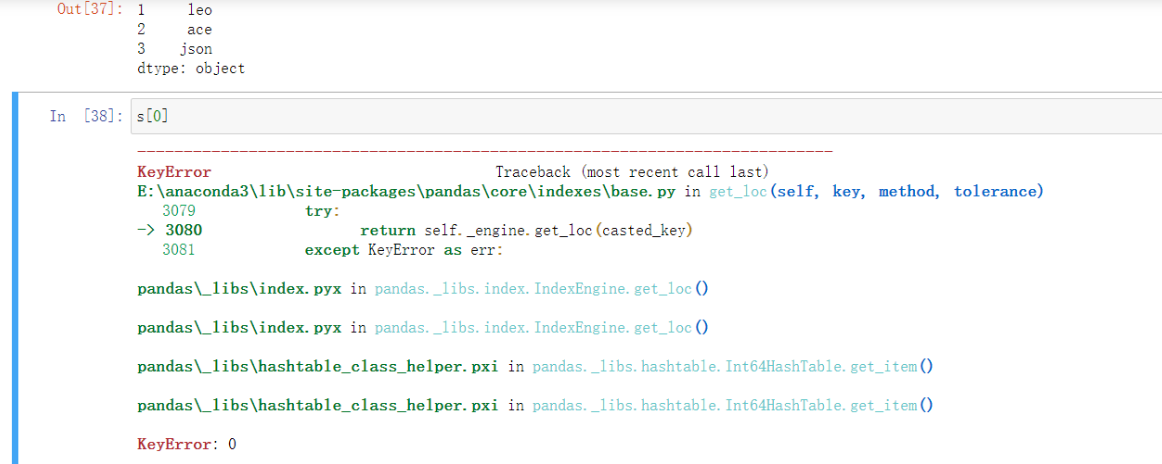
s = pd.Series({1:'leo',2:'ace',3:'json'}) # 做一个series
s[0] # 行索引就会和自己定义的标签混淆
针对上述情况就要用到
s.iloc[0] # iloc就是告诉程序我要用行索引
s.loc[1] # 这个就是告诉要用行标签取值
s.index # 获取行标签 就是左侧那个项

